


分類は埋め込みの一般的なダウンストリームタスクです。テキスト埋め込みは、スパム検出や感情分析のためにテキストを事前定義されたラベルに分類できます。jina-clip-v1のようなマルチモーダル埋め込みは、コンテンツベースのフィルタリングやタグ付けに適用できます。最近では、複雑さとコストに基づいて適切なLLMにクエリをルーティングする際にも分類が使用されています。たとえば、単純な算術クエリは小規模な言語モデルにルーティングされ、複雑な推論タスクはより強力だが高コストなLLMに転送されます。
本日、Jina AI の Search Foundation の新しいClassifier APIを紹介します。ゼロショットとフューショットのオンライン分類をサポートし、jina-embeddings-v3やjina-clip-v1などの最新の埋め込みモデルを基盤としています。Classifier APIはオンラインパッシブアグレッシブ学習に基づいており、リアルタイムで新しいデータに適応することができます。ユーザーはゼロショット分類器から始めて即座に使用を開始できます。その後、新しい例を提出したり、コンセプトドリフトが発生した場合に、分類器を段階的に更新することができます。これにより、大量の初期ラベル付きデータなしに、様々なコンテンツタイプに対して効率的でスケーラブルな分類が可能になります。ユーザーは自分の分類器を公開して公共利用に供することもできます。今後リリース予定の多言語対応jina-clip-v2などの新しい埋め込みがリリースされた際には、ユーザーは Classifier API を通じて即座にアクセスでき、最新の分類機能を確保できます。

tagゼロショット分類
Classifier API は強力なゼロショット分類機能を提供し、ラベル付きデータによる事前学習なしでテキストや画像を分類することができます。すべての分類器はゼロショット機能から始まり、後で追加の学習データやアップデートで強化することができます - これについては次のセクションで説明します。
tag例 1:LLM リクエストのルーティング
以下は、LLM クエリのルーティングに Classifier API を使用する例です:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'この例では、jina-embeddings-v3を使用して、複数の言語(英語、中国語、日本語、ドイツ語)のユーザークエリを3つのカテゴリに分類し、3つの異なるサイズのLLMに対応させています。API のレスポンス形式は以下の通りです:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}レスポンスには以下が含まれます:
usage:トークン使用量に関する情報。data:各入力に対する分類結果の配列。- 各結果には予測されたラベル(
prediction)と信頼度スコア(score)が含まれます。各クラスのscoreはソフトマックス正規化により計算されます - ゼロショットの場合はclassificationタスク-LoRAの下での入力とラベルの埋め込み間のコサイン類似度に基づき、フューショットの場合は各クラスの入力埋め込みの学習済み線形変換に基づいており、すべてのクラスにわたって確率の合計が1になります。 indexは元のリクエストにおける入力の位置に対応します。
- 各結果には予測されたラベル(
tag例 2:画像とテキストの分類
jina-clip-v1を使用したマルチモーダルの例を見てみましょう。このモデルはテキストと画像の両方を分類できるため、様々なメディアタイプのコンテンツ分類に理想的です。以下のような API 呼び出しを考えてみましょう:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'リクエストで画像をアップロードする方法に注目してください。画像を表現するためにbase64文字列を使用することもできます。API は以下のような分類結果を返します:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tag例 3:Jina Reader が本物のコンテンツを取得しているかの検出
ゼロショット分類の興味深い応用として、Jina Readerを通じたウェブサイトのアクセシビリティ判定があります。一見単純なタスクに見えますが、実際には非常に複雑です。ブロックメッセージはサイトごとに大きく異なり、様々な言語で表示され、異なる理由(ペイウォール、レート制限、サーバーダウンなど)を引用します。この多様性により、正規表現や固定ルールですべてのシナリオを捕捉することは困難です。
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)このスクリプトはr.jina.aiを通じてコンテンツを取得し、Classifier API を使用して"Blocked"または"Accessible"に分類します。たとえば、https://r.jina.ai/https://www.crunchbase.com/organization/jina-aiはアクセス制限により"Blocked"に分類される可能性が高く、一方https://r.jina.ai/https://jina.aiは"Accessible"となるはずです。
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}Classifier API は Jina Reader からの本物のコンテンツとブロックされた結果を効果的に区別できます。
この例ではjina-embeddings-v3を活用し、特に多言語環境でのコンテンツ集約やウェブスクレイピングシステムに有用な、ウェブサイトのアクセシビリティを監視する迅速な自動化された方法を提供します。
tag例 4:グラウンディングのための意見からの事実の抽出
ゼロショット分類のもう一つの興味深い応用例は、長文の中から意見から事実のような主張をフィルタリングすることです。分類器自体は、何かが事実かどうかを判定することはできないことに注意してください。代わりに、事実の形式で書かれたテキストを識別し、それを検証用の grounding API(通常かなり高価です)で確認することができます。この2段階のプロセスが効果的な事実確認の鍵となります:まず意見や感情をフィルタリングし、残った文章を grounding に送ります。
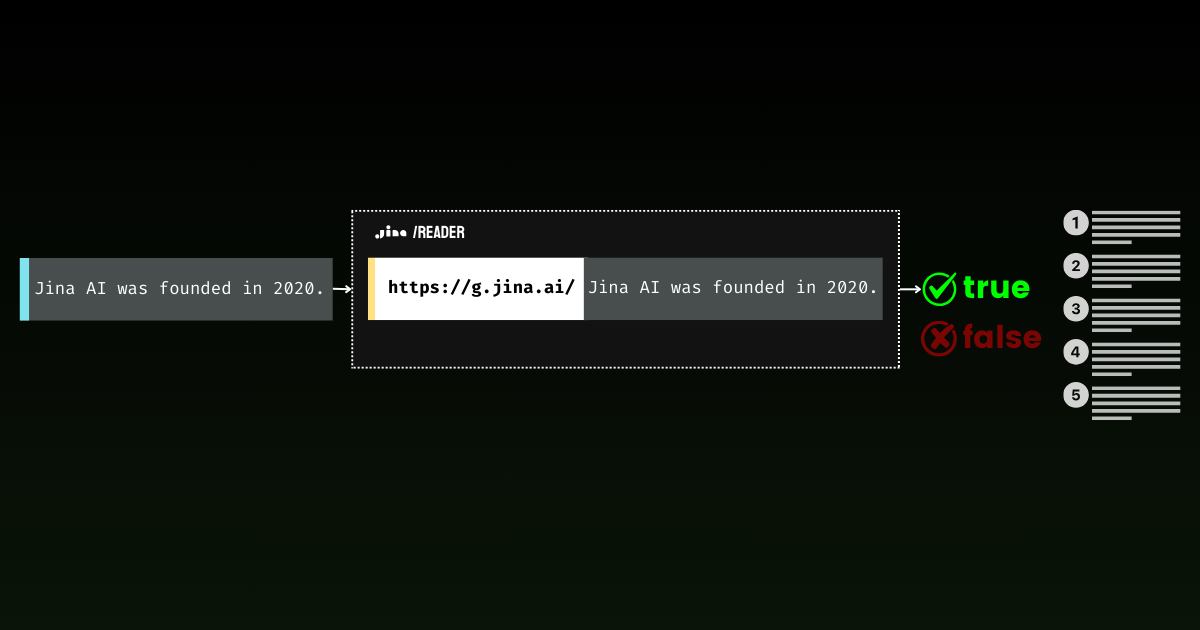
1960年代の宇宙開発競争についての以下のパラグラフを考えてみましょう:
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
このテキストは意図的に異なる種類の文章を混ぜ合わせています - 事実のような主張(「スプートニク 1 号は 1959 年 10 月 4 日に打ち上げられた」など)から、明確な意見(「人間の創意工夫の息をのむような証」)、感情的な表現(「何百万人の心に恐怖を抱かせた」)、解釈的な主張(「新時代の疑う余地のない始まりを示す」)まで。
ゼロショット分類器の役割は純粋に意味的です - テキストが事実として書かれているか、意見や解釈として書かれているかを識別します。例えば、"The Soviet Union launched Sputnik 1 on October 4, 1959" は事実として書かれていますが、"The Space Race was a breathtaking testament" は明らかに意見として書かれています。
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)結果は以下のようになります:
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']事実として書かれているからといって、それが真実であるとは限らないことを覚えておいてください。そのため、2番目のステップ - これらの事実のような主張を grounding API に送って実際の事実検証を行う必要があります。例えば、以下の文を検証してみましょう:"NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973"。以下のコードで検証します。
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())結果は以下のようになります:
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}事実性スコア 1 で、grounding API はこの声明が歴史的事実に十分裏付けられていることを確認しています。このアプローチは、歴史的文書の分析からニュース記事のリアルタイムな事実確認まで、魅力的な可能性を開きます。ゼロショット分類と事実検証を組み合わせることで、自動化された情報分析のための強力なパイプラインを作成します - まず意見をフィルタリングし、残りの声明を信頼できるソースで検証します。
tagゼロショット分類に関する注意点
セマンティックラベルの使用
ゼロショット分類を扱う際は、抽象的な記号や数字ではなく、意味的に有意義なラベルを使用することが重要です。例えば、"Class1"、"Class2"、"Class3" や "0"、"1"、"2" よりも、"Technology"、"Nature"、"Food" の方がはるかに効果的です。"Positive" や "True" よりも "Positive sentiment" の方が効果的です。埋め込みモデルは意味的な関係を理解するので、説明的なラベルを使用することで、より正確な分類のために事前学習された知識を活用することができます。以前の投稿では、より良い分類結果を得るための効果的なセマンティックラベルの作成方法について詳しく説明しています。

ステートレスな性質
ゼロショット分類は、従来の機械学習アプローチとは異なり、根本的にステートレスです。これは、同じ入力とモデルが与えられた場合、API を使用する人や時期に関係なく、結果は常に一貫することを意味します。モデルは実行した分類に基づいて学習や更新を行いません。各タスクは独立しています。これにより、セットアップやトレーニングなしで即座に使用でき、API 呼び出し間でカテゴリを変更する柔軟性が得られます。
このステートレスな性質は、次に説明するフューショットやオンライン学習アプローチとは大きく異なります。これらの手法では、モデルは新しい例に適応でき、時間の経過やユーザー間で異なる結果が得られる可能性があります。
tagフューショット分類
フューショット分類は、最小限のラベル付きデータで分類器を作成・更新する簡単なアプローチを提供します。この方法は、train と classify の 2 つの主要なエンドポイントを提供します。
train エンドポイントでは、少数の例で分類器を作成または更新できます。train への最初の呼び出しはclassifier_id を使用することで、新しいデータがある場合やデータ分布の変化、または新しいクラスを追加する必要がある場合に、後続のトレーニングに使用できます。この柔軟なアプローチにより、分類器は時間とともに進化し、新しいパターンやカテゴリーに適応することができ、一からやり直す必要がありません。
ゼロショット分類と同様に、予測には classify エンドポイントを使用します。主な違いは、リクエストに classifier_id を含める必要がありますが、候補ラベルは訓練済みモデルの一部としてすでに含まれているため、提供する必要がありません。
tag例:サポートチケット割り当てシステムの訓練
急成長中のテックスタートアップで、カスタマーサポートチケットを異なるチームに割り当てる分類の例を見てみましょう。
初期トレーニング
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'フューショット学習では、意味的な意味を持たなくても、クラスラベルとして team1 team2 を自由に使用できます。レスポンスでは、この新しく作成された分類器を表す classifier_id が得られます。
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
この classifier_id をメモしておいてください。後でこの分類器を参照する際に必要になります。
チーム再編成に合わせた分類器の更新
例の会社が成長するにつれ、新しいタイプの問題が発生し、チーム構造も変化します。フューショット分類の素晴らしい点は、これらの変更に素早く適応できることです。classifier_id と新しい例を提供することで、新しいチームカテゴリー(例:team4)を導入したり、組織の進化に合わせて既存の問題タイプを異なるチームに再割り当てしたりすることが簡単にできます。
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'訓練済み分類器の使用
推論時には、入力テキストと classifier_id を提供するだけです。API は入力と以前に訓練したクラス間のマッピングを処理し、分類器の現在の状態に基づいて最も適切なラベルを返します。
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'フューショットモードには 2 つの固有のパラメータがあります。
tagパラメータ num_iters
num_iters パラメータは、分類器が訓練例からどの程度集中的に学習するかを調整します。デフォルト値の 10 はほとんどの場合うまく機能しますが、訓練データへの信頼度に基づいてこの値を戦略的に調整できます。分類に重要な高品質な例の場合は num_iters を増やして重要性を強化し、信頼性の低い例の場合は num_iters を下げて分類器のパフォーマンスへの影響を最小限に抑えます。このパラメータは、より最近の例に高い反復回数を設定することで、進化するパターンに適応しながら過去の知識を維持する時間認識学習を実装するためにも使用できます。
tagパラメータ access
access パラメータを使用すると、分類器を使用できる人を制御できます。デフォルトでは、分類器はプライベートで、あなただけがアクセスできます。アクセスを "public" に設定すると、classifier_id を持っている人なら誰でも、自分の API キーとトークンクォータを使用してそれを使用できます。これにより、プライバシーを維持しながら分類器を共有できます - ユーザーはあなたの訓練データや設定を見ることができず、あなたも彼らの分類リクエストを見ることができません。このパラメータはフューショット分類にのみ関連し、ゼロショット分類器はステートレスです。ゼロショット分類器を共有する必要はありません。なぜなら、誰がリクエストを行っても、同一のリクエストは常に同じレスポンスを生成するからです。
tagフューショット学習に関する注意点
当社の API のフューショット分類には、注目すべきユニークな特徴があります。従来の機械学習モデルとは異なり、当社の実装では 1 パスのオンライン学習を使用しています - 訓練例は分類器の重みを更新するために処理されますが、その後は保存されません。これは過去の訓練データを取得できないことを意味しますが、プライバシーとリソースの効率性が向上します。
フューショット学習は強力ですが、ゼロショット分類のパフォーマンスを上回るためにはウォームアップ期間が必要です。当社のベンチマークでは、通常 200-400 の訓練例で優れたパフォーマンスを実現するのに十分なデータが得られることを示しています。ただし、すべてのクラスの例を最初から提供する必要はありません - 分類器は時間とともに新しいクラスに対応できるように拡張できます。ただし、新しく追加されたクラスは、十分な例が提供されるまでの間、短期的なコールドスタート期間やクラスの不均衡を経験する可能性があることに注意してください。
tagベンチマーク
当社のベンチマーク分析では、感情検出(6 クラス)やスパム検出(2 クラス)などのテキスト分類タスク、CIFAR10(10 クラス)などの画像分類タスクにわたって、ゼロショットとフューショットのアプローチを評価しました。評価フレームワークは標準的な訓練-テスト分割を使用し、ゼロショットは訓練データを必要とせず、フューショットは訓練セットの一部を使用しました。制御された比較を可能にするため、訓練サイズと対象クラス数などの主要な指標を追跡しました。特にフューショット学習の堅牢性を確保するため、各入力は複数の訓練反復を経ました。これらの現代的なアプローチを、線形 SVM や RBF SVM などの従来のベースラインと比較し、そのパフォーマンスの文脈を提供しました。



F1 スコアがプロットされています。ベンチマークの詳細な設定については、この Google スプレッドシートをご確認ください。
F1 プロットは 3 つのタスクにおいて興味深いパターンを示しています。予想通り、ゼロショット分類は、トレーニングデータのサイズに関係なく、最初から一定のパフォーマンスを示しています。対照的に、フューショット学習は急激な学習曲線を示し、最初は低い性能から始まりますが、トレーニングデータが増えるにつれてゼロショットのパフォーマンスを素早く上回ります。両方の手法は最終的に400 サンプル付近で同程度の精度に達しますが、フューショットがわずかに優位を保っています。このパターンはマルチクラス分類と画像分類の両方のシナリオで当てはまり、フューショット学習はトレーニングデータが利用可能な場合に特に有利である一方、ゼロショットはトレーニング例がなくても信頼性の高いパフォーマンスを提供できることを示唆しています。以下の表は、API ユーザーの観点からゼロショットとフューショット分類の違いをまとめたものです。
| Feature | Zero-shot | Few-shot |
|---|---|---|
| Primary Use Case | Default solution for general classification | For data outside v3/clip-v1's domain or time-sensitive data |
| Training Data Required | No | Yes |
| Labels Required in /train | N/A | Yes |
| Labels Required in /classify | Yes | No |
| Classifier ID Required | No | Yes |
| Semantic Labels Required | Yes | No |
| State Management | Stateless | Stateful |
| Continuous Model Updates | No | Yes |
| Access Control | No | Yes |
| Maximum Classes | 256 | 16 |
| Maximum Classifiers | N/A | 16 |
| Maximum Inputs per Request | 1,024 | 1,024 |
| Maximum Token Length per Input | 8,192 tokens | 8,192 tokens |
tagまとめ
Classifier API は、jina-embeddings-v3 や jina-clip-v1 のような高度な埋め込みモデルを活用して、テキストと画像コンテンツの両方に対して強力なゼロショットおよびフューショット分類を提供します。ベンチマークによると、ゼロショット分類はトレーニングデータなしで信頼性の高いパフォーマンスを提供し、最大 256 クラスをサポートするため、ほとんどのタスクの優れた出発点となります。フューショット学習はトレーニングデータでわずかに良い精度を達成できますが、即座に結果が得られ柔軟性があるため、まずはゼロショット分類から始めることをお勧めします。
この API の汎用性により、LLM クエリのルーティングからウェブサイトのアクセシビリティ検出、多言語コンテンツの分類まで、さまざまなアプリケーションをサポートします。ゼロショットから始めるか、特殊なケースでフューショット学習に移行するかに関わらず、API はパイプラインへのシームレスな統合のために一貫したインターフェースを維持します。開発者の皆様がこの API をどのように活用されるのかを見るのが特に楽しみで、将来的には jina-clip-v2 のような新しい埋め込みモデルのサポートも展開していく予定です。
