


AIについての議論はしばしば終末論的です。その一因は、終末論的なSF作品が私たちの人工知能に対するメンタルイメージを作り上げてきたことにあります。より多くのマシンを生み出せるスマートマシンというビジョンは、何世代にもわたってSFの定番テーマでした。
最近のAI開発における実存的リスクについて声を上げている人々は多く、その多くはAIの商業化に関わるビジネスリーダーであり、一部の科学者や研究者も含まれています。これはAIハイプの一部となっています:科学や産業界の冷静そうな重鎮たちに世界の終わりを考えさせるほど強力なものなら、きっと利益を生み出すのに十分な力があるはずだ、という考え方です。
では、AIからの実存的リスクを心配すべきでしょうか?Sam Altman が ChatGPT から Ultron を作り出し、そのAI軍団が東ヨーロッパの都市を投げつけてくることを恐れる必要があるのでしょうか?Peter Thiel の Palantir がSkynet を構築し、説明のつかないオーストリアなまりのロボットを過去に送り込んで私たちを抹殺しようとすることを心配すべきでしょうか?
おそらくその必要はありません。業界のリーダーたちは、AIが自身の経費を賄う明確な方法さえまだ見出せておらず、産業を破壊することはさらに難しく、気候変動や核兵器に匹敵するレベルで人類を脅かすことなど、なおさら遠い話です。
現実のAIモデルは人類を絶滅させるには程遠い存在です。手を描くのに苦労し、3つ以上のものを数えられず、ネズミが齧ったチーズを人々に売ることは大丈夫だと考え、Gatorade でカトリックの洗礼を行おうとするのです。AIの平凡な、非実存的なリスク——誤情報を広め、ハラスメントを行い、スパムを生成し、その限界を理解していない人々によって不適切に使用される可能性——だけでも十分に懸念されます。
しかし、人工知能からの一つの実存的リスクは間違いなく正当なものです:AIは....AI自身に対して明白で差し迫った危険をもたらすのです。
この恐れは通常"model collapse(モデル崩壊)"と呼ばれ、Shumailov et al. (2023)とAlemohammad et al. (2023)で強力な実証が示されています。考え方は単純です:AI生成データからAIモデルを訓練し、その結果得られたAIの出力を使って別のモデルを訓練し、このプロセスを複数世代にわたって繰り返すと、AIは客観的にどんどん悪化していきます。コピーのコピーのコピーを取るようなものです。

最近、モデル崩壊についての議論が活発になっており、報道見出しにはAIがデータを使い果たしつつあるという記事が登場しています。インターネットがAI生成データで満たされ、人間が作成したデータの特定と使用が難しくなると、AIモデルはまもなく品質の上限に直面することになります。
同時に、AI開発において合成データやモデル蒸留技術の使用が増加しています。これらはどちらも、少なくとも部分的に他のAIモデルの出力でAIモデルを訓練することで構成されています。これら2つのトレンドは互いに矛盾しているように見えます。
実際にはもう少し複雑です。生成AIは自身の進歩を妨げるスパムを生み出すのでしょうか?それともAIは私たちがより良いAIを作るのを助けてくれるのでしょうか?あるいはその両方でしょうか?
この記事でいくつかの答えを探ってみましょう。
tagモデル崩壊
Alemohammad et al. が「Model Autophagy Disorder (MAD)」という用語を発明したことは素晴らしいですが、「model collapse」の方がはるかに印象に残りやすく、自己共食いを意味するギリシャ語を使う必要もありません。コピーのコピーを取るという比喩は問題を簡単な言葉で伝えていますが、基礎となる理論にはもう少し深い部分があります。
AIモデルの訓練は統計モデリングの一種で、統計学者やデータサイエンティストが長年行ってきたことの延長線上にあります。しかし、データサイエンスの授業の初日に、データサイエンティストのモットーを学びます:
すべてのモデルは間違っているが、いくつかは有用である。
このGeorge Boxの言葉は、すべてのAIモデルの上に置かれるべき点滅する赤信号です。どんなデータに対しても統計モデルを作ることはできますし、そのモデルは常に何らかの答えを出しますが、その答えが正しいとか、正解に近いということは全く保証されていません。
統計モデルは何かの近似です。その出力は有用かもしれませんし、十分に良好かもしれませんが、それでも近似にすぎません。たとえ平均的に非常に正確な、十分に検証されたモデルであっても、時には大きな間違いを犯す可能性があり、おそらく実際に犯すでしょう。
AIモデルは統計モデリングのすべての問題を引き継いでいます。ChatGPT や他の大規模 AI モデルを使ったことがある人なら誰でも、それらが間違いを犯すのを見たことがあるはずです。
したがって、AIモデルが何か実在するものの近似であるならば、別のAIモデルの出力から訓練されたAIモデルは近似の近似ということになります。誤差は蓄積され、本質的に、訓練元のモデルより正確性が低くなるしかありません。
Alemohammad et al. は、新しい「子」モデルを訓練する前にAI出力に元の訓練データの一部を追加しても問題は解決できないことを示しています。それはモデル崩壊を遅らせるだけで、止めることはできません。AI出力で訓練する際に、十分な量の新しい、これまで見たことのない実世界のデータを導入しない限り、モデル崩壊は避けられません。
十分な新しいデータがどれくらいかは、予測困難な、ケース固有の要因に依存しますが、AI生成データが少なく、新しい実データが多いほど、その逆よりも常に良い結果が得られます。
そしてこれが問題です。なぜなら、簡単にアクセスできる新しい人間作成のデータソースはすでに使い尽くされている一方で、インターネット上のAI生成の画像やテキストデータの量は飛躍的に増加しているからです。インターネット上の人間作成コンテンツとAI作成コンテンツの比率は低下しており、おそらく急速に低下しています。AI生成データを自動的に検出する信頼できる方法はなく、多くの研究者はそのような方法は存在し得ないと考えています。AI画像・テキスト生成モデルへの一般アクセスが可能なことから、この問題は拡大し、おそらく劇的に拡大することは間違いなく、明確な解決策はありません。
インターネット上の機械翻訳の量を考えると、すでに手遅れかもしれません。インターネット上の機械翻訳されたテキストは、生成 AI 革命が起こるずっと前から、長年にわたってデータソースを汚染してきました。Thompson 他(2024)によると、インターネット上のテキストの半分が他の言語から翻訳されている可能性があり、その翻訳の大部分が質の低い機械翻訳の特徴を示しているとのことです。これは、そのようなデータから学習した言語モデルを歪める可能性があります。
例として、以下はウェブサイトDie Welt der Habsburgerのページのスクリーンショットで、明らかに機械翻訳の証拠を示しています。"Hamster buying" はドイツ語のhamstern(買い溜めやパニック買いの意味)の直訳すぎる翻訳です。このような例が多すぎると、AI モデルが "hamster buying" を英語の実在する表現だと誤解し、ドイツ語のhamsternがペットのハムスターと何か関係があると考えてしまうでしょう。

ほぼすべてのケースにおいて、学習データに AI の出力が多く含まれることは悪影響を及ぼします。ただし、ほぼという点が重要で、以下で 2 つの例外について説明します。
tag合成データ
合成データとは、実世界から収集されたものではなく、人工的に生成された AI の学習データまたは評価データです。Nikolenko(2021)によると、合成データは 1960 年代の初期のコンピュータビジョンプロジェクトにまで遡り、その分野の重要な要素としての歴史が概説されています。
合成データを使用する理由は多くありますが、最大の理由の 1 つはバイアスへの対処です。
大規模言語モデルや画像生成モデルは、バイアスに関する多くの注目を集める批判を受けています。バイアスという言葉は統計学では厳密な意味を持ちますが、これらの批判は多くの場合、単純な数学的形式やエンジニアリングによる解決策のない道徳的、社会的、政治的な考慮事項を反映しています。
目に見えにくいバイアスの方が、はるかに深刻で修正も困難です。AI モデルが複製を学習するパターンは、学習データに見られるものであり、そのデータに体系的な欠陥がある場合、バイアスは避けられない結果となります。AI に期待する作業が多様になればなるほど - つまりモデルへの入力が多様化すればするほど - 学習データに十分な類似例がなかったために何かを間違える可能性が高くなります。
今日の AI 学習における合成データの主な役割は、自然なデータでは十分に存在しない可能性のある特定の状況の例を、学習データに十分に含めることです。
以下は、MidJourney が "doctor" というプロンプトに対して生成した画像です:4 人の男性、3 人が白人で、3 人が白衣と聴診器を身につけており、1 人は明らかに年配です。これは、ほとんどの国や文脈における実際の医師の人種、年齢、性別、服装を反映していませんが、インターネット上で見つかるラベル付けされた画像を反映している可能性が高いです。

再度プロンプトを入力すると、1 人の女性と 3 人の男性が生成され、全員が白人で、1 人は漫画のようです。AI は時々変な結果を出します。

このような種類のバイアスは、AI 画像生成器が防止しようとしているものであり、おそらく 1 年前と比べて、同じシステムからこれほど明確にバイアスのある結果は得られなくなっています。バイアスは依然として目に見えて存在しますが、バイアスのない結果がどのようなものかは明確ではありません。
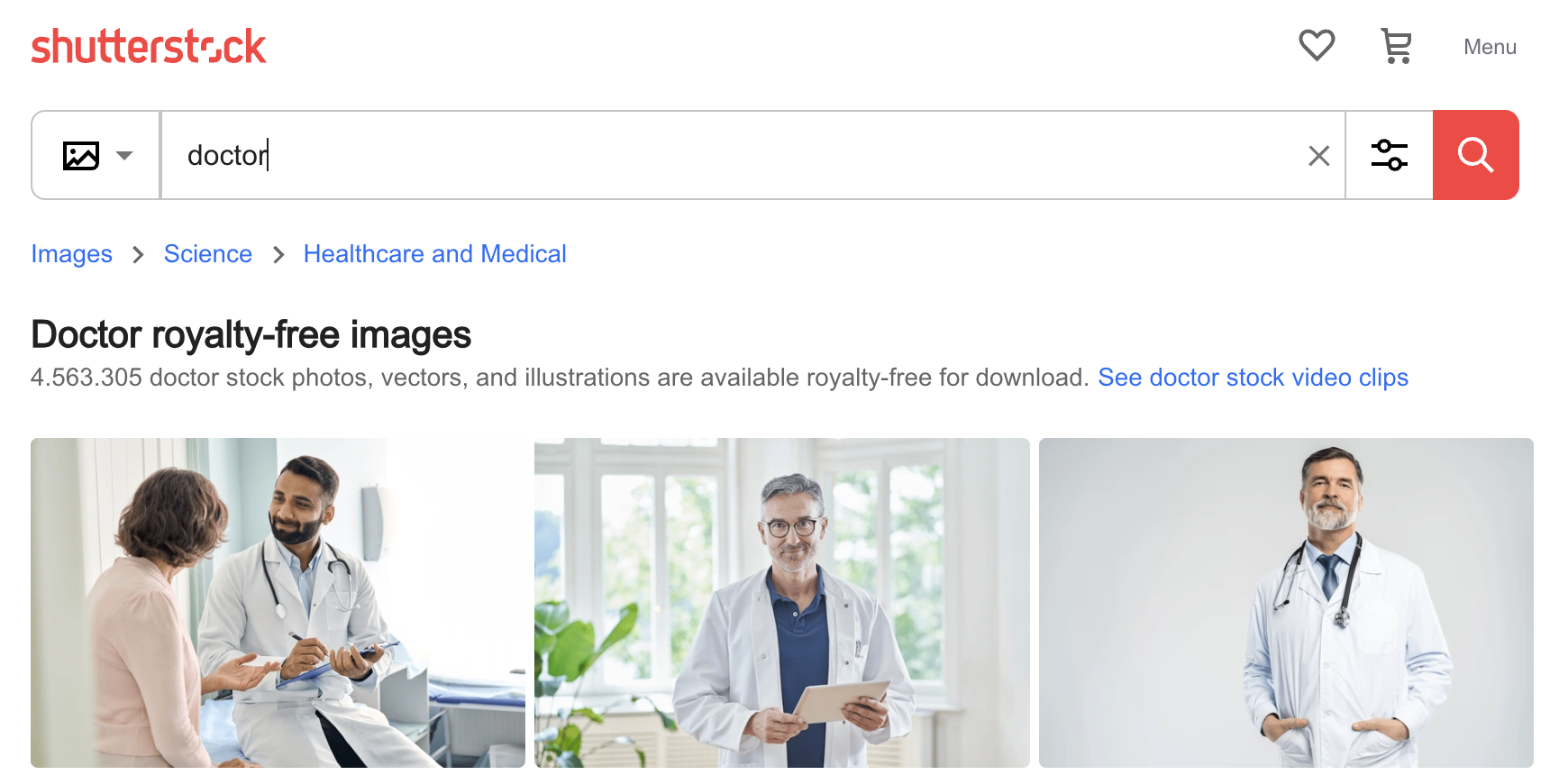
しかし、AI がこのような偏見を獲得する方法を理解するのは難しくありません。以下は Shutterstock の写真ウェブサイトで "doctor" を検索して最初に見つかった 3 枚の画像です:3 人の男性で、2 人は年配の白人です。AI のバイアスはその学習のバイアスであり、キュレーションされていないデータでモデルを学習させると、常にこのような種類のバイアスが見つかります。
この問題を軽減する 1 つの方法は、AI 画像生成器を使用して、若い医師、女性医師、有色人種の医師、スクラブやスーツなど様々な服装の医師の画像を作成し、それらを学習に含めることです。このように使用される合成データは、少なくとも何らかの外部基準に照らして、モデルの崩壊を引き起こすのではなく、AI モデルのパフォーマンスを改善することができます。ただし、学習データの分布を人工的に歪めることは、Google が最近経験したように、意図しない副作用を生む可能性があります。
tagモデル蒸留
モデル蒸留は、あるモデルを別のモデルから直接学習させる技術です。学習済みの生成モデル—「教師」—が、未学習または学習が不十分な「生徒」モデルを学習させるために必要なだけのデータを作成します。
予想通り、「生徒」モデルが「教師」を超えることはありえません。一見すると、そのような方法でモデルを学習させる意味はないように思えますが、利点があります。主な利点は、「生徒」モデルが「教師」よりもはるかに小さく、速く、効率的である可能性があり、それでいてそのパフォーマンスに近い近似を実現できることです。
モデルのサイズ、学習データ、最終的なパフォーマンスの関係は複雑です。しかし、全体として、他の条件が同じ場合:
- 大きいモデルの方が小さいモデルよりもパフォーマンスが良い。
- より多くの、あるいはより良質な(少なくともより多様な)学習データで学習したモデルの方が、より少ない、あるいは質の低いデータで学習したモデルよりもパフォーマンスが良い。
これは、小さいモデルが時として大きいモデルと同じくらい良いパフォーマンスを発揮できることを意味します。例えば、jina-embeddings-v2-base-enは、標準的なベンチマークで多くのより大きなモデルを大きく上回るパフォーマンスを示しています:
| モデル | パラメータ数 | MTEB 平均スコア |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |

| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
