

AI 모델을 이해하는 데는 많은 장벽이 있으며, 일부는 상당히 큰 장벽으로 AI 프로세스 구현에 방해가 될 수 있습니다. 하지만 많은 사람들이 처음 마주치는 것은 토큰을 이야기할 때 무엇을 의미하는지 이해하는 것입니다.

AI 언어 모델을 선택할 때 가장 중요한 실용적 매개변수 중 하나는 컨텍스트 윈도우의 크기—최대 입력 텍스트 크기—입니다. 이는 단어나 문자 또는 다른 자동으로 인식 가능한 단위가 아닌 토큰으로 표시됩니다.
또한 임베딩 서비스는 일반적으로 "토큰당" 계산되므로, 토큰은 청구서를 이해하는 데 중요합니다.
토큰이 무엇인지 명확하지 않다면 이는 매우 혼란스러울 수 있습니다.
하지만 현대 AI의 모든 혼란스러운 측면 중에서 토큰은 아마도 가장 덜 복잡할 것입니다. 이 글에서는 토큰화가 무엇이고, 무엇을 하며, 왜 이런 방식으로 하는지를 명확히 설명하고자 합니다.
tag요약
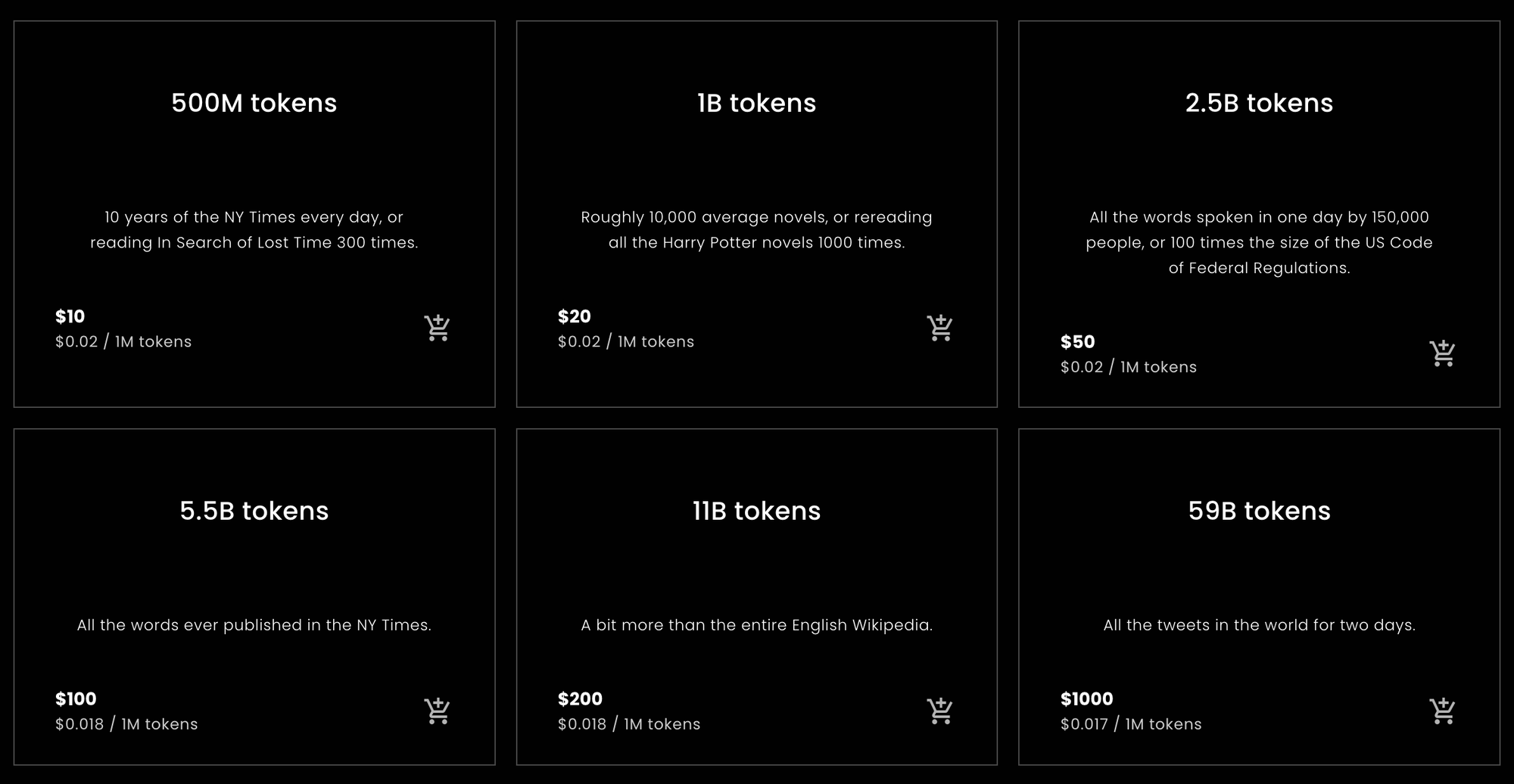
Jina Embeddings에서 얼마나 많은 토큰을 구매해야 할지, 또는 얼마나 많은 토큰이 필요할지 빠르게 알고 싶은 분들을 위한 통계입니다.
tag영어 단어당 토큰
이 글의 후반부에서 설명할 경험적 테스트 동안, 다양한 영어 텍스트는 Jina Embeddings 영어 전용 모델을 사용할 때 단어보다 약 10% 더 많은 토큰으로 변환되었습니다. 이 결과는 꽤 안정적이었습니다.
Jina Embeddings v2 모델은 8192 토큰의 컨텍스트 윈도우를 가지고 있습니다. 이는 Jina 모델에 7,400단어보다 긴 영어 텍스트를 전달하면 잘릴 가능성이 높다는 것을 의미합니다.
tag중국어 문자당 토큰
중국어의 경우 결과가 더 가변적입니다. 텍스트 유형에 따라 중국어 문자(汉字) 당 0.6에서 0.75 토큰의 비율로 변동됩니다. 중국어용 Jina Embeddings v2에 입력된 영어 텍스트는 영어용 Jina Embeddings v2와 거의 동일한 수의 토큰을 생성합니다: 단어 수보다 약 10% 더 많습니다.
tag독일어 단어당 토큰
독일어의 단어-토큰 비율은 영어보다는 가변적이지만 중국어보다는 덜합니다. 텍스트 장르에 따라 평균적으로 단어보다 20%에서 30% 더 많은 토큰이 생성됩니다. 독일어와 영어용 Jina Embeddings v2에 영어 텍스트를 입력하면 영어 전용 및 중국어/영어 모델보다 약간 더 많은 토큰을 사용합니다: 단어보다 12%에서 15% 더 많은 토큰이 사용됩니다.
tag주의사항
이것들은 단순한 계산이지만 대부분의 자연어 텍스트와 사용자에게 대략적으로 맞을 것입니다. 궁극적으로 우리가 약속할 수 있는 것은 토큰 수가 항상 텍스트의 문자 수에 2를 더한 것보다 많지 않다는 것뿐입니다. 실제로는 항상 그보다 훨씬 적을 것이지만, 특정 수를 미리 약속할 수는 없습니다.
이는 통계적으로 단순한 계산에 기반한 추정치입니다. 특정 요청이 얼마나 많은 토큰을 사용할지 보장하지 않습니다.
Jina Embeddings에 대해 얼마나 많은 토큰을 구매해야 하는지에 대한 조언만 필요하다면 여기에서 멈추셔도 됩니다. Jina AI가 아닌 다른 회사의 임베딩 모델은 Jina 모델이 가진 토큰-단어 및 토큰-중국어 문자 비율과 동일하지 않을 수 있지만, 전반적으로 크게 다르지는 않을 것입니다.
이유를 이해하고 싶다면, 이 글의 나머지 부분은 언어 모델을 위한 토큰화에 대해 더 깊이 있게 다룹니다.
tag단어, 토큰, 숫자
토큰화는 현대 AI 모델이 존재하기 전부터 자연어 처리의 일부였습니다.
컴퓨터의 모든 것이 단순히 숫자일 뿐이라고 말하는 것은 진부한 표현이지만, 대체로 사실입니다. 하지만 언어는 본질적으로 단순한 숫자들의 집합이 아닙니다. 그것은 음파로 이루어진 음성일 수도 있고, 종이 위의 표시일 수도 있으며, 인쇄된 텍스트의 이미지나 수화를 사용하는 누군가의 영상일 수도 있습니다. 하지만 대부분의 경우, 컴퓨터로 자연어를 처리한다고 할 때는 문자의 시퀀스로 구성된 텍스트를 의미합니다: 글자(a, b, c 등), 숫자(0, 1, 2…), 구두점, 그리고 공백이 다양한 언어와 텍스트 인코딩으로 되어 있습니다.
컴퓨터 엔지니어들은 이를 "문자열"이라고 부릅니다.
AI 언어 모델은 숫자의 시퀀스를 입력으로 받습니다. 예를 들어, 다음과 같은 문장을 작성할 수 있습니다:
What is today's weather in Berlin?
하지만 토큰화 후에 AI 모델은 다음과 같은 입력을 받습니다:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
토큰화는 입력 문자열을 AI 모델이 이해할 수 있는 특정 숫자 시퀀스로 변환하는 과정입니다.
토큰당 요금을 부과하는 웹 API를 통해 AI 모델을 사용할 때, 각 요청은 위와 같은 숫자 시퀀스로 변환됩니다. 요청의 토큰 수는 그 숫자 시퀀스의 길이입니다. 따라서 영어용 Jina Embeddings v2에 "What is today's weather in Berlin?"의 임베딩을 요청하면 11개의 토큰이 소요됩니다. 이는 AI 모델에 전달하기 전에 해당 문장을 11개의 숫자 시퀀스로 변환했기 때문입니다.
Transformer 아키텍처를 기반으로 한 AI 모델은 토큰으로 측정되는 고정 크기의 컨텍스트 윈도우를 가지고 있습니다. 때로는 이를 "입력 윈도우", "컨텍스트 크기" 또는 "시퀀스 길이"(특히 Hugging Face MTEB 리더보드에서)라고 부릅니다. 이는 모델이 한 번에 볼 수 있는 최대 텍스트 크기를 의미합니다.
따라서 임베딩 모델을 사용하려면 이것이 허용되는 최대 입력 크기입니다.
Jina Embeddings v2 모델은 모두 8,192 토큰의 컨텍스트 윈도우를 가지고 있습니다. 다른 모델들은 다른(일반적으로 더 작은) 컨텍스트 윈도우를 가질 것입니다. 이는 얼마나 많은 텍스트를 입력하든 해당 Jina Embeddings 모델과 연관된 토크나이저가 이를 8,192 토큰 이하로 변환해야 한다는 것을 의미합니다.
tag언어를 숫자로 매핑하기
토큰의 논리를 설명하는 가장 간단한 방법은 다음과 같습니다:
자연어 모델의 경우, 토큰이 대표하는 문자열의 부분은 단어, 단어의 일부, 또는 구두점입니다. 공백은 일반적으로 토크나이저 출력에서 명시적인 표현을 갖지 않습니다.
토큰화는 자연어 처리에서 텍스트 분할이라고 불리는 기술 그룹의 일부이며, 토큰화를 수행하는 모듈은 매우 논리적으로 토크나이저라고 불립니다.
토큰화가 어떻게 작동하는지 보여주기 위해, 가장 작은 영어용 Jina Embeddings v2 모델인 jina-embeddings-v2-small-en을 사용하여 몇 가지 문장을 토큰화해 보겠습니다. Jina Embeddings의 다른 영어 전용 모델 — jina-embeddings-v2-base-en — 은 동일한 토크나이저를 사용하므로, 이 글에서 사용하지 않을 추가 메가바이트의 AI 모델을 다운로드할 필요가 없습니다.
먼저, Python 환경이나 노트북에 transformers 모듈을 설치하세요.-U 플래그를 사용하여 최신 버전으로 업그레이드하세요. 이 모델은 일부 이전 버전과는 작동하지 않습니다:
pip install -U transformers
그런 다음, AutoModel.from_pretrained를 사용하여 jina-embeddings-v2-small-en을 다운로드하세요:
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
문자열을 토큰화하려면 모델의 tokenizer 멤버 객체의 encode 메서드를 사용하세요:
model.tokenizer.encode("What is today's weather in Berlin?")
결과는 숫자 리스트입니다:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
이러한 숫자를 다시 문자열 형태로 변환하려면 tokenizer 객체의 convert_ids_to_tokens 메서드를 사용하세요:
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
결과는 문자열 리스트입니다:
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
모델의 토크나이저는 다음과 같은 특징이 있습니다:
- 시작 부분에
[CLS]를 추가하고 끝에[SEP]를 추가합니다. 이는 기술적인 이유로 필요하며 모든 임베딩 요청에는 텍스트가 사용하는 토큰 외에 두 개의 추가 토큰이 필요하다는 것을 의미합니다. - 단어에서 구두점을 분리하여 "Berlin?"을
berlin과?로, "today's"를today,',s로 나눕니다. - 모든 것을 소문자로 변환합니다. 모든 모델이 이렇게 하는 것은 아니지만, 영어를 사용할 때 학습에 도움이 될 수 있습니다. 대소문자가 다른 의미를 가지는 언어에서는 덜 유용할 수 있습니다.
다른 프로그램의 다양한 단어 계산 알고리즘은 이 문장의 단어를 다르게 계산할 수 있습니다. OpenOffice는 이를 6개의 단어로 계산합니다. 유니코드 텍스트 분할 알고리즘(Unicode Standard Annex #29)은 7개의 단어로 계산합니다. 다른 소프트웨어는 구두점과 "'s"와 같은 접어를 처리하는 방식에 따라 다른 숫자를 산출할 수 있습니다.
이 모델의 토크나이저는 6-7개의 단어에 대해 9개의 토큰을 생성하며, 여기에 모든 요청에 필요한 두 개의 추가 토큰이 포함됩니다.
이제 베를린보다 덜 일반적인 지명으로 시도해 보겠습니다:
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
결과:
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
"Kinshasa"라는 이름은 세 개의 토큰으로 나뉩니다: kin, ##sha, ##sa. ##는 이 토큰이 단어의 시작이 아님을 나타냅니다.
토크나이저에 완전히 낯선 것을 입력하면 단어 수에 비해 토큰 수가 더욱 증가합니다:
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
3개의 단어가 [CLS]와 [SEP] 토큰 외에 8개의 토큰이 됩니다.
독일어의 토큰화도 비슷합니다. Jina Embeddings v2 for German 모델을 사용하여 "What is today's weather in Berlin?"의 독일어 번역을 영어 모델과 동일한 방식으로 토큰화할 수 있습니다.
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
결과:
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
이 토크나이저는 영어 버전과 약간 다른데, <s>와 </s>가 [CLS]와 [SEP]를 대체하지만 같은 기능을 합니다. 또한 독일어에서는 대소문자가 영어와는 다른 의미를 가지기 때문에 텍스트의 대소문자가 정규화되지 않고 작성된 대로 유지됩니다.
(이 설명을 단순화하기 위해 단어 시작을 나타내는 특수 문자를 제거했습니다.)
이제 신문 기사에서 가져온 더 복잡한 문장을 시도해 보겠습니다:
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)토큰화된 결과:
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
여기서 볼 수 있듯이 많은 독일어 단어가 작은 조각으로 나뉘었고, 반드시 독일어 문법에 따라 나뉘지는 않았습니다. 결과적으로 단어 카운터에서는 하나의 단어로 계산되는 긴 독일어 단어가 Jina의 AI 모델에서는 여러 개의 토큰이 될 수 있습니다.
이제 중국어로 "What is today's weather in Berlin?"을 번역하여 같은 작업을 해보겠습니다:
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
토큰화된 결과:
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
중국어에서는 일반적으로 문자 텍스트에 단어 구분이 없지만, Jina Embeddings 토크나이저는 자주 여러 중국어 문자를 함께 결합합니다:
| Token string | Pinyin | Meaning |
|---|---|---|
| 柏林 | Bólín | Berlin |
| 今天的 | jīntiān de | today's |
| 天气 | tiānqì | weather |
| 怎么样 | zěnmeyàng | how |
홍콩 신문에서 가져온 더 복잡한 문장을 사용해 보겠습니다:
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(번역: "새 규정이 시행된 첫날, 이 기자는 오후 5시 퇴근 시간에 주강신도시역에서 출발하여 공항 방면으로 향하는 광저우 지하철 3호선에 도착했다.")
결과:
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
이러한 토큰들은 중국어 사전(词典)의 특정 단어와 매핑되지 않습니다. 예를 들어, "啟程" - qǐchéng (출발하다, 떠나다)은 일반적으로 하나의 단어로 분류되지만, 여기서는 두 개의 구성 문자로 분리되어 있습니다. 마찬가지로, "在下班"은 보통 두 단어로 인식되며, "在" - zài (~에서, ~동안)와 "下班" - xiàbān (퇴근 시간)으로 나뉘어야 하지만, 토크나이저는 여기서 "在下"와 "班" 사이를 분리했습니다.
세 가지 언어 모두에서, 토크나이저가 텍스트를 나누는 위치는 사람이 읽을 때 나누는 논리적인 위치와 직접적인 관련이 없습니다.
이는 Jina Embeddings 모델만의 특징이 아닙니다. 이러한 토크나이징 접근 방식은 AI 모델 개발에서 거의 보편적입니다. 두 개의 서로 다른 AI 모델이 동일한 토크나이저를 가지고 있지 않을 수 있지만, 현재 개발 상태에서는 거의 모든 모델이 이러한 종류의 동작을 하는 토크나이저를 사용할 것입니다.
다음 섹션에서는 토크나이제이션에 사용되는 구체적인 알고리즘과 그 뒤에 있는 논리에 대해 논의할 것입니다.
tag왜 토크나이즈를 하는가? 그리고 왜 이런 방식인가?
AI 언어 모델은 텍스트 시퀀스를 나타내는 숫자 시퀀스를 입력으로 받지만, 기본 신경망을 실행하고 임베딩을 생성하기 전에 더 많은 일이 일어납니다. 작은 텍스트 시퀀스를 나타내는 숫자 리스트가 제시되면, 모델은 각 숫자에 대한 고유한 벡터를 저장하는 내부 사전에서 각 숫자를 찾습니다. 그런 다음 이들을 결합하여 신경망의 입력이 됩니다.
이는 토크나이저가 우리가 제공하는 모든 입력 텍스트를 모델의 토큰 벡터 사전에 있는 토큰으로 변환할 수 있어야 한다는 것을 의미합니다. 만약 우리가 기존 사전에서 토큰을 가져온다면, 철자가 틀린 단어나 희귀한 고유 명사 또는 외국어를 처음 만났을 때 전체 모델이 멈출 것입니다. 그 입력을 처리할 수 없게 됩니다.
자연어 처리에서 이것을 어휘 외(OOV) 문제라고 하며, 모든 텍스트 유형과 모든 언어에서 만연합니다. OOV 문제를 해결하기 위한 몇 가지 전략이 있습니다:
- 무시하기. 사전에 없는 모든 것을 "알 수 없음" 토큰으로 대체합니다.
- 우회하기. 텍스트 시퀀스를 벡터에 매핑하는 사전 대신, 개별 문자를 벡터에 매핑하는 사전을 사용합니다. 영어는 대부분 26개의 문자만 사용하므로, 이는 어떤 사전보다 더 작고 OOV 문제에 더 강건해야 합니다.
- 텍스트에서 자주 나타나는 부분 시퀀스를 찾아 사전에 넣고, 나머지는 문자(단일 문자 토큰)를 사용합니다.
첫 번째 전략은 많은 중요한 정보가 손실된다는 것을 의미합니다. 사전에 없는 형태로 데이터가 있다면 모델은 그것에 대해 배울 수조차 없습니다. 일반 텍스트에서 가장 큰 사전에도 없는 것들이 많이 있습니다.
두 번째 전략은 가능하며, 연구자들이 조사해 왔습니다. 하지만 이는 모델이 더 많은 입력을 받아들이고 더 많이 학습해야 한다는 것을 의미합니다. 이는 세 번째 전략보다 더 나은 결과를 보여준 적이 없는 훨씬 더 큰 모델과 훨씬 더 많은 훈련 데이터가 필요하다는 것을 의미합니다.
AI 언어 모델은 거의 모두 어떤 형태로든 세 번째 전략을 구현합니다. 대부분은 Wordpiece 알고리즘 [Schuster and Nakajima 2012]의 변형이나 Byte-Pair Encoding(BPE)이라고 하는 유사한 기술을 사용합니다. [Gage 1994, Senrich et al. 2016] 이러한 알고리즘들은 언어에 구애받지 않습니다. 즉, 가능한 문자의 포괄적인 목록 외에는 어떤 지식도 없이 모든 문자 언어에 대해 동일하게 작동합니다. 이들은 Google의 BERT와 같이 인터넷 스크래핑에서 얻은 모든 입력 - 수백 개의 언어와 컴퓨터 프로그램과 같은 인간 언어가 아닌 텍스트 - 을 받아들이는 다국어 모델을 위해 설계되어 복잡한 언어학 없이도 훈련될 수 있었습니다.
일부 연구는 더 언어 특화적이고 언어를 인식하는 토크나이저를 사용하면 상당한 개선이 있다는 것을 보여줍니다. [Rust et al. 2021] 하지만 그러한 방식으로 토크나이저를 구축하는 데는 시간과 비용, 전문 지식이 필요합니다. BPE나 Wordpiece와 같은 보편적 전략을 구현하는 것이 훨씬 더 저렴하고 쉽습니다.
하지만 결과적으로, 특정 텍스트가 몇 개의 토큰을 나타내는지 알 수 있는 유일한 방법은 토크나이저를 통해 실행한 다음 출력되는 토큰의 수를 세는 것뿐입니다. 텍스트의 가장 작은 가능한 부분 시퀀스가 한 글자이기 때문에, 토큰의 수가 문자 수(공백 제외)에 2를 더한 것보다 크지 않을 것이라고 확신할 수 있습니다.
좋은 추정치를 얻으려면 우리의 토크나이저에 많은 텍스트를 던져서 입력한 단어나 문자 수와 비교하여 평균적으로 얼마나 많은 토큰이 나오는지 경험적으로 계산해야 합니다. 다음 섹션에서는 현재 사용 가능한 모든 Jina Embeddings v2 모델에 대해 그리 체계적이지 않은 경험적 측정을 수행할 것입니다.
tag토큰 출력 크기의 경험적 추정
영어와 독일어의 경우, Unicode 텍스트 분할 알고리즘(Unicode Standard Annex #29)을 사용하여 텍스트의 단어 수를 계산했습니다. 이 알고리즘은 더블클릭으로 텍스트 조각을 선택할 때 널리 사용됩니다. 이는 보편적인 객관적 단어 카운터에 가장 가까운 것입니다.
Python에서 이 텍스트 분할기를 구현하는 polyglot 라이브러리를 설치했습니다:
pip install -U polyglot
텍스트의 단어 수를 얻으려면 다음과 같은 코드 조각을 사용할 수 있습니다:
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
결과는 7이 되어야 합니다.
토큰 수를 얻기 위해, 텍스트의 세그먼트를 아래 설명된 대로 다양한 Jina Embeddings 모델의 토크나이저에 전달했고, 매번 반환된 토큰 수에서 2를 뺐습니다.
tag영어
(jina-embeddings-v2-small-en과 jina-embeddings-v2-base-en)
평균을 계산하기 위해, 라이프치히 대학이 호스팅하는 여러 언어와 구성의 자유롭게 다운로드 가능한 코퍼스 모음인 Wortschatz Leipzig에서 두 개의 영어 텍스트 코퍼스를 다운로드했습니다:
- 2020년 영어 뉴스 데이터의 백만 문장 코퍼스(
eng_news_2020_1M) - 2016년 영어 위키피디아 데이터의 백만 문장 코퍼스(
eng_wikipedia_2016_1M)
둘 다 그들의 영어 다운로드 페이지에서 찾을 수 있습니다.
다양성을 위해, Project Gutenberg에서 빅토르 위고의 레 미제라블의 Hapgood 번역과 1611년에 영어로 번역된 King James Version 성경의 사본도 다운로드했습니다.
네 텍스트 모두에 대해, polyglot에 구현된 Unicode 분할기를 사용하여 단어를 세고, 그런 다음 jina-embeddings-v2-small-en이 만든 토큰을 세었으며, 각 토크나이제이션 요청에서 두 개의 토큰을 뺐습니다. 결과는 다음과 같습니다:
| 텍스트 | 단어 수 (Unicode 분할기) | 토큰 수 (Jina Embeddings v2 영어 버전) | 토큰과 단어의 비율 (소수점 3자리) |
|---|---|---|---|
eng_news_2020_1M | 22,825,712 | 25,270,581 | 1.107 |
eng_wikipedia_2016_1M | 24,243,607 | 26,813,877 | 1.106 |
les_miserables_en | 688,911 | 764,121 | 1.109 |
kjv_bible | 1,007,651 | 1,099,335 | 1.091 |
정확한 숫자를 사용했다고 해서 이것이 정확한 결과라는 의미는 아닙니다. 이렇게 다양한 장르의 문서들이 모두 단어 수보다 9%에서 11% 더 많은 토큰을 가진다는 것은 Unicode 분할기로 측정했을 때 단어보다 약 10% 더 많은 토큰을 예상할 수 있다는 것을 나타냅니다. 워드 프로세서는 종종 구두점을 세지 않지만 Unicode 분할기는 세기 때문에, 오피스 소프트웨어의 단어 수와 반드시 일치할 것이라고 기대할 수는 없습니다.
tag독일어
(jina-embeddings-v2-base-de)
Wortschatz Leipzig의 독일어 페이지에서 세 개의 코퍼스를 다운로드했습니다:
deu_mixed-typical_2011_1M— 2011년 기준 다양한 장르의 텍스트가 균형있게 섞인 백만 문장.deu_newscrawl-public_2019_1M— 2019년의 뉴스 텍스트 백만 문장.deu_wikipedia_2021_1M— 2021년 독일어 위키피디아에서 추출한 백만 문장.
그리고 다양성을 위해 Deutsches Textarchiv에서 칼 마르크스의 자본론 3권도 다운로드했습니다.
그런 다음 영어와 동일한 절차를 따랐습니다:
| 텍스트 | 단어 수 (Unicode 분할기) | 토큰 수 (Jina Embeddings v2 독일어 및 영어용) | 토큰 대 단어 비율 (소수점 3자리) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7,924,024 | 9,772,652 | 1.234 |
deu_newscrawl-public_2019_1M | 17,949,120 | 21,711,555 | 1.210 |
deu_wikipedia_2021_1M | 17,999,482 | 22,654,901 | 1.259 |
marx_kapital | 784,336 | 1,011,377 | 1.289 |
이 결과는 영어 전용 모델보다 더 큰 편차를 보이지만, 독일어 텍스트는 평균적으로 단어보다 20%에서 30% 더 많은 토큰을 생성할 것이라는 것을 시사합니다.
영어 텍스트는 독일어-영어 토크나이저로 처리할 때 영어 전용 토크나이저보다 더 많은 토큰을 생성합니다:
| 텍스트 | 단어 수 (Unicode 분할기) | 토큰 수 (Jina Embeddings v2 독일어 및 영어용) | 토큰 대 단어 비율 (소수점 3자리) |
|---|---|---|---|
eng_news_2020_1M | 24243607 | 27758535 | 1.145 |
eng_wikipedia_2016_1M | 22825712 | 25566921 | 1.120 |
이중 언어(독일어/영어) 모델로 영어 텍스트를 임베딩할 때는 영어 전용 모델보다 12%에서 15% 더 많은 토큰이 필요할 것으로 예상해야 합니다.
tag중국어
(jina-embeddings-v2-base-zh)
중국어는 일반적으로 공백 없이 작성되며 20세기 이전에는 "단어"의 전통적인 개념이 없었습니다. 따라서 중국어 텍스트의 크기는 일반적으로 문자 수(字数)로 측정됩니다. 그래서 Unicode 분할기를 사용하는 대신, 모든 공백을 제거한 후 문자 길이를 측정했습니다.
Wortschatz Leipzig의 중국어 코퍼스 페이지에서 세 개의 코퍼스를 다운로드했습니다:
zho_wikipedia_2018_1M— 2018년에 추출한 중국어 위키피디아의 백만 문장.zho_news_2007-2009_1M— 2007년부터 2009년 사이에 수집된 중국어 뉴스 출처의 백만 문장.zho-trad_newscrawl_2011_1M— 전통적인 한자(繁體字)만을 사용하는 뉴스 출처의 백만 문장.
또한 다양성을 위해 루쉰(魯迅)이 1920년대 초에 쓴 중편소설 아Q정전(阿Q正傳)도 사용했습니다. Project Gutenberg에서 번체자 버전을 다운로드했습니다.
| 텍스트 | 문자 수 (字数) | 토큰 수 (Jina Embeddings v2 중국어 및 영어용) | 토큰 대 문자 비율 (소수점 3자리) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45,116,182 | 29,193,028 | 0.647 |
zho_news_2007-2009_1M | 44,295,314 | 28,108,090 | 0.635 |
zho-trad_newscrawl_2011_1M | 54,585,819 | 40,290,982 | 0.738 |
Ah_Q | 41,268 | 25,346 | 0.614 |
토큰-문자 비율의 이러한 차이는 예상치 못한 것이며, 특히 번체자 코퍼스의 이상치는 추가 조사가 필요합니다. 그럼에도 불구하고, 중국어의 경우 텍스트의 문자 수보다 더 적은 토큰이 필요하다는 결론을 내릴 수 있습니다. 콘텐츠에 따라 25%에서 40% 정도 더 적은 토큰이 필요할 것으로 예상됩니다.
중국어와 영어를 위한 Jina Embeddings v2에서 영어 텍스트는 영어 전용 모델에서와 거의 동일한 수의 토큰을 생성했습니다:
| Text | Word count (Unicode Segmenter) | Token count (Jina Embeddings v2 for Chinese and English) | Ratio of tokens to words (to 3 decimal places) |
|---|---|---|---|
eng_news_2020_1M | 24,243,607 | 26,890,176 | 1.109 |
eng_wikipedia_2016_1M | 22,825,712 | 25,060,352 | 1.097 |
tag토큰을 진지하게 다루기
토큰은 AI 언어 모델의 중요한 구조이며, 이 분야의 연구는 현재 진행 중입니다.
AI 모델이 혁신적임이 입증된 영역 중 하나는 노이즈가 있는 데이터에 대해 매우 강건하다는 점입니다. 특정 모델이 최적의 토큰화 전략을 사용하지 않더라도, 네트워크가 충분히 크고, 충분한 데이터가 있으며, 적절히 훈련된다면 불완전한 입력에서도 올바른 작업을 학습할 수 있습니다.
결과적으로 다른 영역에 비해 토큰화 개선에는 상대적으로 적은 노력이 투입되지만, 이는 변할 수 있습니다.
Jina Embeddings와 같은 API를 통해 임베딩을 사용하는 사용자로서, 특정 작업에 정확히 몇 개의 토큰이 필요한지 알 수 없으며 정확한 숫자를 얻기 위해서는 직접 테스트를 해봐야 할 수 있습니다. 하지만 여기서 제공된 추정치 — 영어의 경우 단어 수의 약 110%, 독일어의 경우 단어 수의 약 125%, 중국어의 경우 문자 수의 약 70% — 는 기본적인 예산 책정에 충분할 것입니다.






