


분류는 임베딩의 일반적인 다운스트림 태스크입니다. 텍스트 임베딩은 스팸 감지나 감성 분석을 위해 텍스트를 미리 정의된 레이블로 분류할 수 있습니다. jina-clip-v1과 같은 멀티모달 임베딩은 콘텐츠 기반 필터링이나 태그 주석에 적용될 수 있습니다. 최근에는 복잡성과 비용에 따라 적절한 LLM으로 쿼리를 라우팅하는 데도 분류가 사용되고 있습니다. 예를 들어 간단한 산술 쿼리는 작은 언어 모델로 라우팅될 수 있습니다. 복잡한 추론 작업은 더 강력하지만 비용이 높은 LLM으로 전달될 수 있습니다.
오늘 Jina AI의 Search Foundation에서 새로운 Classifier API를 소개합니다. 제로샷과 퓨샷 온라인 분류를 지원하며, jina-embeddings-v3와 jina-clip-v1과 같은 최신 임베딩 모델을 기반으로 구축되었습니다. Classifier API는 온라인 패시브-어그레시브 러닝을 기반으로 하여 실시간으로 새로운 데이터에 적응할 수 있습니다. 사용자는 제로샷 분류기로 시작하여 즉시 사용할 수 있습니다. 그런 다음 새로운 예제를 제출하거나 컨셉 드리프트가 발생할 때 분류기를 점진적으로 업데이트할 수 있습니다. 이를 통해 광범위한 초기 레이블링된 데이터 없이도 다양한 콘텐츠 유형에 대해 효율적이고 확장 가능한 분류가 가능합니다. 사용자는 또한 자신의 분류기를 공개적으로 사용할 수 있도록 게시할 수 있습니다. 곧 출시될 다국어 jina-clip-v2와 같은 새로운 임베딩이 출시되면 사용자는 Classifier API를 통해 즉시 액세스할 수 있어 최신 분류 기능을 보장받을 수 있습니다.

tag제로샷 분류
Classifier API는 레이블링된 데이터로 사전 학습하지 않고도 텍스트나 이미지를 분류할 수 있는 강력한 제로샷 분류 기능을 제공합니다. 모든 분류기는 제로샷 기능으로 시작하며, 이후 추가 학습 데이터나 업데이트로 향상될 수 있습니다 - 이는 다음 섹션에서 살펴볼 주제입니다.
tag예시 1: LLM 요청 라우팅
다음은 LLM 쿼리 라우팅을 위한 분류기 API 사용 예시입니다:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'이 예시는 jina-embeddings-v3를 사용하여 여러 언어(영어, 중국어, 일본어, 독일어)의 사용자 쿼리를 세 가지 카테고리로 분류하는 것을 보여줍니다. 이는 세 가지 다른 크기의 LLM에 대응됩니다. API 응답 형식은 다음과 같습니다:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}응답에는 다음이 포함됩니다:
usage: 토큰 사용량 정보.data: 각 입력에 대한 분류 결과 배열.- 각 결과는 예측된 레이블(
prediction)과 신뢰도 점수(score)를 포함합니다. 각 클래스에 대한score는 소프트맥스 정규화를 통해 계산됩니다 - 제로샷의 경우classificationtask-LoRA 하에서 입력과 레이블 임베딩 간의 코사인 유사도를 기반으로 하며, 퓨샷의 경우 각 클래스에 대한 입력 임베딩의 학습된 선형 변환을 기반으로 하여 모든 클래스에 걸쳐 합이 1이 되는 확률을 산출합니다. index는 원래 요청에서 입력의 위치에 해당합니다.
- 각 결과는 예측된 레이블(
tag예시 2: 이미지 & 텍스트 분류
jina-clip-v1을 사용한 멀티모달 예시를 살펴보겠습니다. 이 모델은 텍스트와 이미지 모두를 분류할 수 있어 다양한 미디어 유형의 콘텐츠 분류에 이상적입니다. 다음 API 호출을 고려해보세요:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'요청에서 이미지를 업로드하는 방법에 주목하세요. 이미지를 나타내기 위해 base64 문자열을 사용할 수도 있습니다. API는 다음과 같은 분류 결과를 반환합니다:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tag예시 3: Jina Reader가 진정한 콘텐츠를 받는지 감지
제로샷 분류의 흥미로운 응용은 Jina Reader를 통한 웹사이트 접근성 판단입니다. 이는 단순한 작업처럼 보일 수 있지만, 실제로는 놀랍게도 복잡합니다. 차단 메시지는 사이트마다 크게 다르며, 다양한 언어로 나타나고 여러 이유(유료 콘텐츠 제한, 속도 제한, 서버 중단)를 인용합니다. 이러한 다양성으로 인해 모든 시나리오를 포착하기 위해 정규식이나 고정된 규칙에 의존하기 어렵습니다.
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)이 스크립트는 r.jina.ai를 통해 콘텐츠를 가져오고 Classifier API를 사용하여 "Blocked" 또는 "Accessible"로 분류합니다. 예를 들어, https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai는 액세스 제한으로 인해 "Blocked"일 가능성이 높고, https://r.jina.ai/https://jina.ai는 "Accessible"일 것입니다.
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}Classifier API는 Jina Reader의 실제 콘텐츠와 차단된 결과를 효과적으로 구분할 수 있습니다.
이 예시는 jina-embeddings-v3를 활용하여 특히 다국어 환경에서 콘텐츠 집계나 웹 스크래핑 시스템에 유용한 웹사이트 접근성을 모니터링하는 빠르고 자동화된 방법을 제공합니다.
tag예시 4: 근거를 위한 의견에서 진술 필터링
제로샷 분류의 또 다른 흥미로운 응용은 긴 문서에서 의견과 구별되는 사실 진술문을 필터링하는 것입니다. 분류기 자체는 어떤 것이 사실인지 판단할 수 없다는 점에 유의하세요. 대신, 사실적 진술문 스타일로 작성된 텍스트를 식별하며, 이는 비용이 많이 드는 grounding API를 통해 검증될 수 있습니다. 이러한 두 단계 프로세스가 효과적인 팩트 체크의 핵심입니다: 먼저 의견과 감정을 필터링한 다음, 남은 진술문들을 grounding에 보내는 것입니다.
1960년대 우주 경쟁에 대한 이 단락을 살펴보세요:
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
이 텍스트는 의도적으로 다양한 유형의 글을 혼합했습니다 - 사실적 진술문(예: "스푸트니크 1호는 1959년 10월 4일에 발사되었다")부터 명확한 의견("숨막히는 증거"), 감정적 언어("마음에 두려움을 심어주었다"), 해석적 주장("새로운 시대의 명백한 시작을 알렸다")까지.
제로샷 분류기의 역할은 순전히 의미적입니다 - 텍스트가 진술문으로 작성되었는지 또는 의견/해석으로 작성되었는지를 식별합니다. 예를 들어, "The Soviet Union launched Sputnik 1 on October 4, 1959"는 진술문으로 작성된 반면, "The Space Race was a breathtaking testament"는 명확히 의견으로 작성되었습니다.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)그러면 다음과 같은 결과를 얻게 됩니다:
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
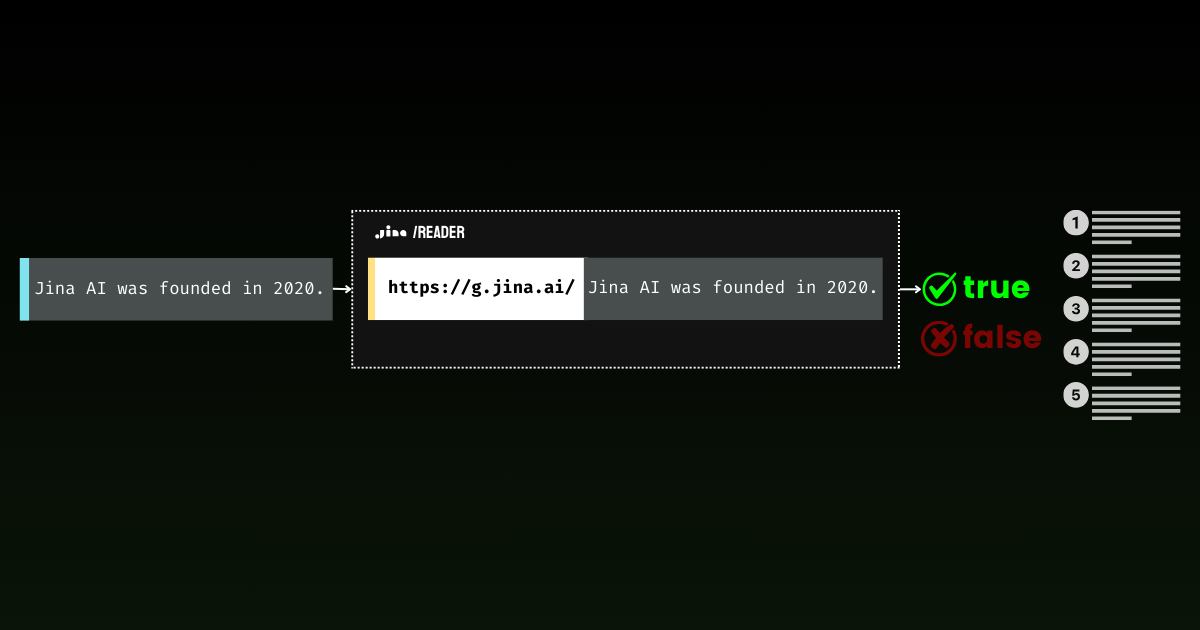
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']어떤 것이 진술문 형식으로 작성되었다고 해서 그것이 사실이라는 것을 의미하지는 않는다는 점을 기억하세요. 그래서 두 번째 단계가 필요한 것입니다 - 이러한 진술문처럼 보이는 주장들을 실제 사실 검증을 위해 grounding API에 입력하는 것입니다. 예를 들어, 이 진술문을 검증해 봅시다: "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973" 아래의 코드를 사용하여 검증할 수 있습니다.
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())다음과 같은 결과를 얻습니다:
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}factuality 점수가 1인 것으로 보아, grounding API는 이 진술이 역사적 사실에 잘 근거하고 있음을 확인해줍니다. 이 접근 방식은 역사적 문서 분석부터 실시간 뉴스 기사 팩트 체크까지 흥미로운 가능성을 열어줍니다. 제로샷 분류와 사실 검증을 결합함으로써, 우리는 자동화된 정보 분석을 위한 강력한 파이프라인을 만들 수 있습니다 - 먼저 의견을 필터링한 다음, 남은 진술문들을 신뢰할 수 있는 출처와 대조하여 검증하는 것입니다.
tag제로샷 분류에 대한 고찰
의미적 레이블 사용하기
제로샷 분류를 사용할 때, 추상적인 기호나 숫자보다는 의미적으로 유의미한 레이블을 사용하는 것이 중요합니다. 예를 들어, "Class1", "Class2", "Class3" 또는 "0", "1", "2"보다는 "Technology", "Nature", "Food"가 훨씬 더 효과적입니다. "Positive"와 "True"보다는 "Positive sentiment"가 더 효과적입니다. 임베딩 모델은 의미적 관계를 이해하므로, 설명적인 레이블을 사용하면 모델이 더 정확한 분류를 위해 사전 학습된 지식을 활용할 수 있습니다. 이전 포스트에서는 더 나은 분류 결과를 위한 효과적인 의미적 레이블을 만드는 방법을 탐구했습니다.

무상태 특성
제로샷 분류는 전통적인 기계 학습 접근 방식과 달리 근본적으로 무상태입니다. 이는 동일한 입력과 모델이 주어졌을 때, API를 사용하는 사람이나 시점에 관계없이 결과가 항상 일관될 것임을 의미합니다. 모델은 수행하는 분류를 바탕으로 학습하거나 업데이트되지 않으며, 각 작업은 독립적입니다. 이는 설정이나 학습 없이 즉시 사용할 수 있게 하며, API 호출 간에 카테고리를 변경할 수 있는 유연성을 제공합니다.
이러한 무상태 특성은 다음에 살펴볼 퓨샷과 온라인 학습 접근 방식과는 크게 대조됩니다. 이러한 방법들에서는 모델이 새로운 예제에 적응할 수 있어, 시간이 지나거나 사용자가 다를 때 다른 결과를 산출할 수 있습니다.
tag퓨샷 분류
퓨샷 분류는 최소한의 레이블이 지정된 데이터로 분류기를 생성하고 업데이트하는 쉬운 접근 방식을 제공합니다. 이 방법은 train과 classify 두 가지 주요 엔드포인트를 제공합니다.
train 엔드포인트를 사용하면 적은 수의 예제로 분류기를 생성하거나 업데이트할 수 있습니다. train을 처음 호출하면classifier_id는 새로운 데이터가 있거나 데이터 분포에 변화가 있거나 새로운 클래스를 추가해야 할 때 후속 학습을 위해 사용할 수 있습니다. 이러한 유연한 접근 방식을 통해 분류기는 처음부터 다시 시작하지 않고도 시간이 지남에 따라 새로운 패턴과 카테고리에 적응하며 발전할 수 있습니다.
제로샷 분류와 마찬가지로, 예측을 위해 classify 엔드포인트를 사용합니다. 주요 차이점은 요청에 classifier_id를 포함해야 하지만, 후보 레이블은 이미 학습된 모델의 일부이므로 제공할 필요가 없다는 것입니다.
tag예시: 지원 티켓 할당기 학습하기
빠르게 성장하는 테크 스타트업에서 다른 팀에 고객 지원 티켓을 할당하기 위한 분류 예시를 통해 이러한 기능들을 살펴보겠습니다.
초기 학습
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'퓨샷 러닝에서는 본질적인 의미가 없더라도 team1 team2와 같은 클래스 레이블을 자유롭게 사용할 수 있습니다. 응답에서는 이 새로 생성된 분류기를 나타내는 classifier_id를 받게 됩니다.
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
이 classifier_id를 기록해 두세요. 나중에 이 분류기를 참조할 때 필요합니다.
팀 구조 조정에 맞춰 분류기 업데이트하기
예시 회사가 성장함에 따라 새로운 유형의 문제가 발생하고 팀 구조도 변경됩니다. 퓨샷 분류의 장점은 이러한 변화에 빠르게 적응할 수 있다는 것입니다. classifier_id와 새로운 예시를 제공하여 분류기를 쉽게 업데이트할 수 있으며, 조직이 발전함에 따라 새로운 팀 카테고리(예: team4)를 도입하거나 기존 문제 유형을 다른 팀에 재할당할 수 있습니다.
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'학습된 분류기 사용하기
추론 시에는 입력 텍스트와 classifier_id만 제공하면 됩니다. API가 입력과 이전에 학습된 클래스 간의 매핑을 처리하여 분류기의 현재 상태를 기반으로 가장 적절한 레이블을 반환합니다.
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'퓨샷 모드에는 두 가지 고유한 매개변수가 있습니다.
tag매개변수 num_iters
num_iters 매개변수는 분류기가 학습 예시로부터 얼마나 집중적으로 학습할지를 조정합니다. 기본값 10이 대부분의 경우에 잘 작동하지만, 학습 데이터에 대한 신뢰도에 따라 이 값을 전략적으로 조정할 수 있습니다. 분류에 매우 중요한 고품질 예시의 경우 num_iters를 늘려 중요도를 강화할 수 있습니다. 반대로 신뢰도가 낮은 예시의 경우 num_iters를 낮춰 분류기 성능에 미치는 영향을 최소화할 수 있습니다. 이 매개변수는 또한 시간 인식 학습을 구현하는 데 사용될 수 있으며, 여기서는 더 최근의 예시에 더 높은 반복 횟수를 부여하여 과거 지식을 유지하면서 진화하는 패턴에 적응할 수 있습니다.
tag매개변수 access
access 매개변수를 통해 분류기 사용 권한을 제어할 수 있습니다. 기본적으로 분류기는 private이며 본인만 접근할 수 있습니다. 액세스를 "public"으로 설정하면 classifier_id를 가진 누구나 자신의 API 키와 토큰 할당량으로 사용할 수 있습니다. 이를 통해 분류기를 공유하면서 프라이버시를 유지할 수 있습니다 - 사용자는 학습 데이터나 설정을 볼 수 없으며, 분류 요청도 볼 수 없습니다. 이 매개변수는 퓨샷 분류에만 해당되며, 제로샷 분류기는 상태가 없습니다. 동일한 요청은 누가 하든 항상 동일한 응답을 제공하므로 제로샷 분류기를 공유할 필요가 없습니다.
tag퓨샷 러닝에 대한 참고사항
우리 API의 퓨샷 분류에는 주목할 만한 몇 가지 독특한 특성이 있습니다. 전통적인 머신러닝 모델과 달리, 우리의 구현은 원패스 온라인 학습을 사용합니다 - 학습 예시는 분류기의 가중치를 업데이트하는 데 사용되지만 그 후에는 저장되지 않습니다. 이는 과거 학습 데이터를 검색할 수는 없지만, 더 나은 프라이버시와 리소스 효율성을 보장합니다.
퓨샷 러닝은 강력하지만, 제로샷 분류보다 더 나은 성능을 보이기 위해서는 웜업 기간이 필요합니다. 우리의 벤치마크에 따르면 일반적으로 200-400개의 학습 예시가 충분한 성능을 보이는 데 필요합니다. 하지만 모든 클래스에 대한 예시를 처음부터 제공할 필요는 없습니다 - 분류기는 시간이 지남에 따라 새로운 클래스를 수용할 수 있도록 확장될 수 있습니다. 다만 새로 추가된 클래스는 충분한 예시가 제공될 때까지 짧은 콜드스타트 기간이나 클래스 불균형을 경험할 수 있다는 점을 유의하세요.
tag벤치마크
벤치마크 분석을 위해, 우리는 감정 감지(6개 클래스)와 스팸 감지(2개 클래스)와 같은 텍스트 분류 작업과 CIFAR10(10개 클래스)와 같은 이미지 분류 작업을 포함한 다양한 데이터셋에서 제로샷과 퓨샷 접근 방식을 평가했습니다. 평가 프레임워크는 표준 train-test 분할을 사용했으며, 제로샷은 학습 데이터가 필요 없고 퓨샷은 학습 세트의 일부를 사용했습니다. 통제된 비교를 위해 학습 크기와 대상 클래스 수와 같은 주요 메트릭을 추적했습니다. 특히 퓨샷 러닝의 견고성을 보장하기 위해 각 입력은 여러 학습 반복을 거쳤습니다. 성능 맥락을 제공하기 위해 Linear SVM과 RBF SVM 같은 전통적인 기준과 이러한 현대적 접근 방식을 비교했습니다.



F1 점수가 그래프로 표시되어 있습니다. 전체 벤치마크 설정은 이 Google 스프레드시트를 확인하세요.
F1 플롯은 세 가지 작업에서 흥미로운 패턴을 보여줍니다. 예상대로 제로샷 분류는 학습 데이터 크기와 관계없이 시작부터 일정한 성능을 보여줍니다. 반면에 퓨샷 러닝은 급격한 학습 곡선을 보이며, 처음에는 더 낮은 성능으로 시작하지만 학습 데이터가 증가함에 따라 빠르게 제로샷 성능을 넘어섭니다. 두 방법 모두 결국 400개 샘플 지점에서 비슷한 정확도에 도달하며, 퓨샷이 약간의 우위를 유지합니다. 이러한 패턴은 다중 클래스와 이미지 분류 시나리오 모두에서 유지되어, 퓨샷 러닝은 학습 데이터가 있을 때 특히 유리할 수 있으며, 제로샷은 학습 예제가 없어도 신뢰할 만한 성능을 제공함을 시사합니다. 아래 표는 API 사용자 관점에서 제로샷과 퓨샷 분류의 차이를 요약합니다.
| Feature | Zero-shot | Few-shot |
|---|---|---|
| Primary Use Case | Default solution for general classification | For data outside v3/clip-v1's domain or time-sensitive data |
| Training Data Required | No | Yes |
| Labels Required in /train | N/A | Yes |
| Labels Required in /classify | Yes | No |
| Classifier ID Required | No | Yes |
| Semantic Labels Required | Yes | No |
| State Management | Stateless | Stateful |
| Continuous Model Updates | No | Yes |
| Access Control | No | Yes |
| Maximum Classes | 256 | 16 |
| Maximum Classifiers | N/A | 16 |
| Maximum Inputs per Request | 1,024 | 1,024 |
| Maximum Token Length per Input | 8,192 tokens | 8,192 tokens |
tag요약
Classifier API는 jina-embeddings-v3와 jina-clip-v1과 같은 고급 임베딩 모델을 기반으로 텍스트와 이미지 콘텐츠 모두에 대해 강력한 제로샷 및 퓨샷 분류를 제공합니다. 우리의 벤치마크에 따르면 제로샷 분류는 학습 데이터 없이도 신뢰할 만한 성능을 제공하며, 최대 256개 클래스를 지원하여 대부분의 작업에 훌륭한 시작점이 됩니다. 퓨샷 러닝이 학습 데이터로 약간 더 나은 정확도를 달성할 수 있지만, 즉각적인 결과와 유연성을 위해 제로샷 분류로 시작하는 것을 권장합니다.
API의 다양성은 LLM 쿼리 라우팅부터 웹사이트 접근성 감지 및 다국어 콘텐츠 분류에 이르기까지 다양한 애플리케이션을 지원합니다. 제로샷으로 시작하든 특수한 경우를 위해 퓨샷 러닝으로 전환하든, API는 파이프라인에 원활하게 통합될 수 있도록 일관된 인터페이스를 유지합니다. 우리는 개발자들이 이 API를 자신들의 애플리케이션에서 어떻게 활용할지 특히 기대하고 있으며, 향후 jina-clip-v2와 같은 새로운 임베딩 모델에 대한 지원을 출시할 예정입니다.
