
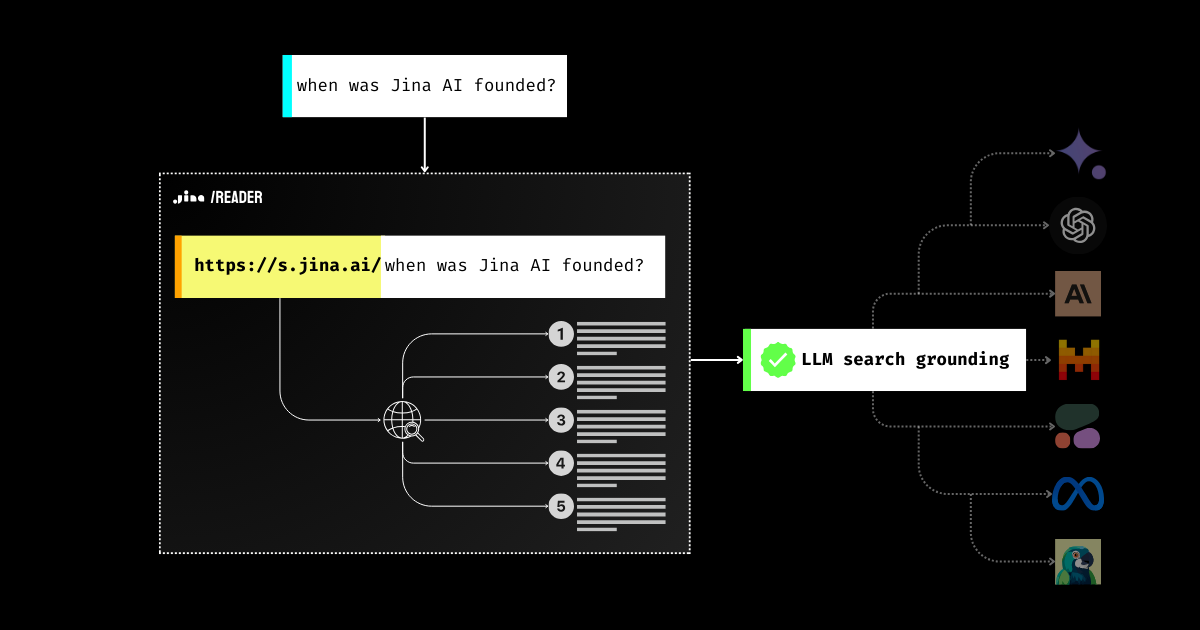

GenAI 어플리케이션에서 Grounding은 절대적으로 필수적입니다.
2023년부터 LLM의 사실성을 개선하기 위해 설계된 많은 도구, 프롬프트 및 RAG 파이프라인을 보셨을 것입니다. 왜일까요? 기업들이 LLM을 수백만 명의 사용자에게 배포하는 것을 막는 주요 장벽은 신뢰성입니다. 답변이 진정한 것인지, 아니면 단순히 모델의 환각인지에 대한 문제죠. 이는 업계 전반의 문제이며, Jina AI는 이를 해결하기 위해 열심히 노력해 왔습니다. 오늘, Jina Reader의 새로운 검색 grounding 기능을 통해 간단히 https://s.jina.ai/YOUR_SEARCH_QUERY를 사용하여 웹에서 최신 세계 지식을 검색할 수 있습니다. 이를 통해 LLM의 사실성을 개선하고, 응답을 더 신뢰할 수 있고 도움이 되게 만드는 데 한 걸음 더 가까워졌습니다.

API, 데모는 제품 페이지에서 확인 가능
tagLLM의 사실성 문제
우리 모두는 LLM이 내용을 꾸며내고 사용자의 신뢰를 해칠 수 있다는 것을 알고 있습니다. LLM은 특히 학습 과정에서 접하지 못한 주제에 대해 사실이 아닌 것을 말할 수 있습니다(일명 환각). 이는 학습 이후에 생성된 새로운 정보이거나 학습 과정에서 "소외된" 틈새 지식일 수 있습니다.
그 결과, "오늘 날씨는 어떤가요?" 또는 "올해 아카데미 여우주연상은 누가 받았나요?"와 같은 질문에 대해 모델은 "모르겠습니다"라고 대답하거나 오래된 정보를 제공합니다.
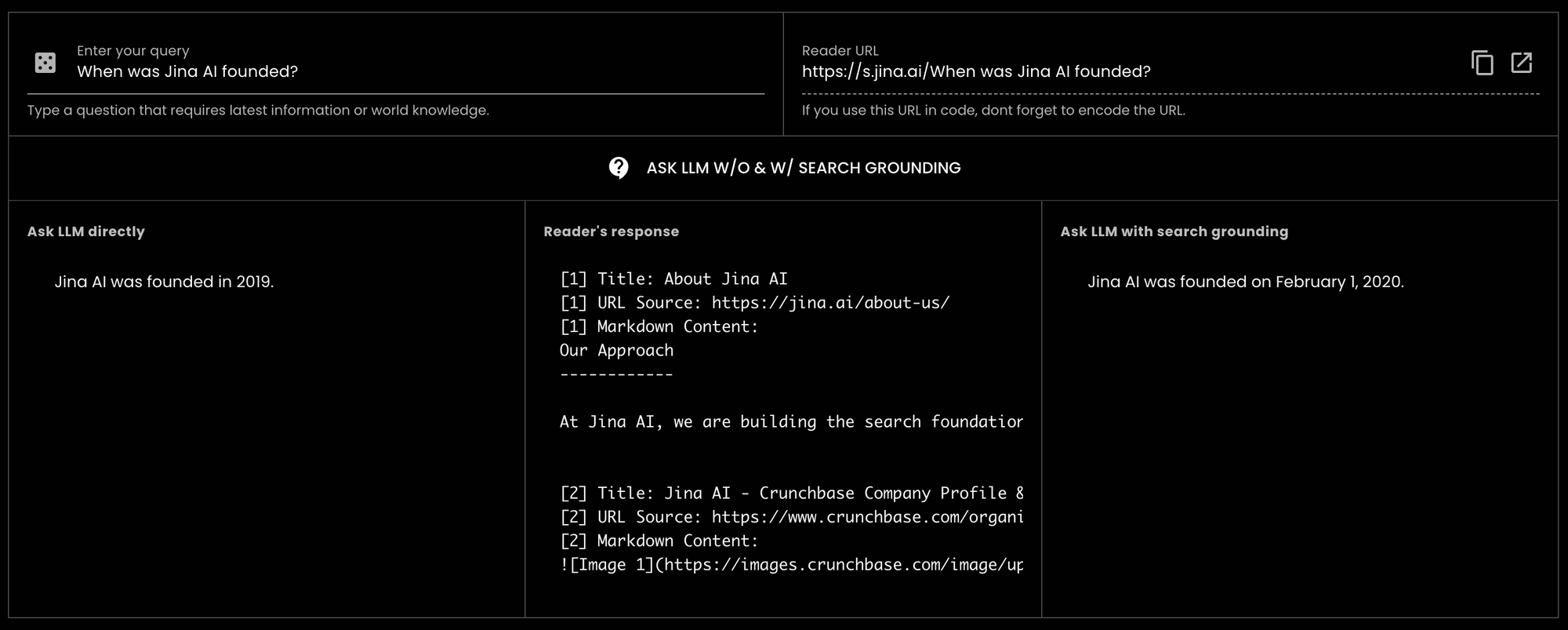
GPT-3.5-turbo에 "Jina AI는 언제 설립되었나요?"라고 물었을 때 잘못된 답변을 받은 것에서 볼 수 있습니다. 하지만 Reader를 사용한 검색 grounding으로, 동일한 LLM이 정확한 답변을 제공할 수 있었습니다. 실제로 정확한 날짜까지 제시했습니다.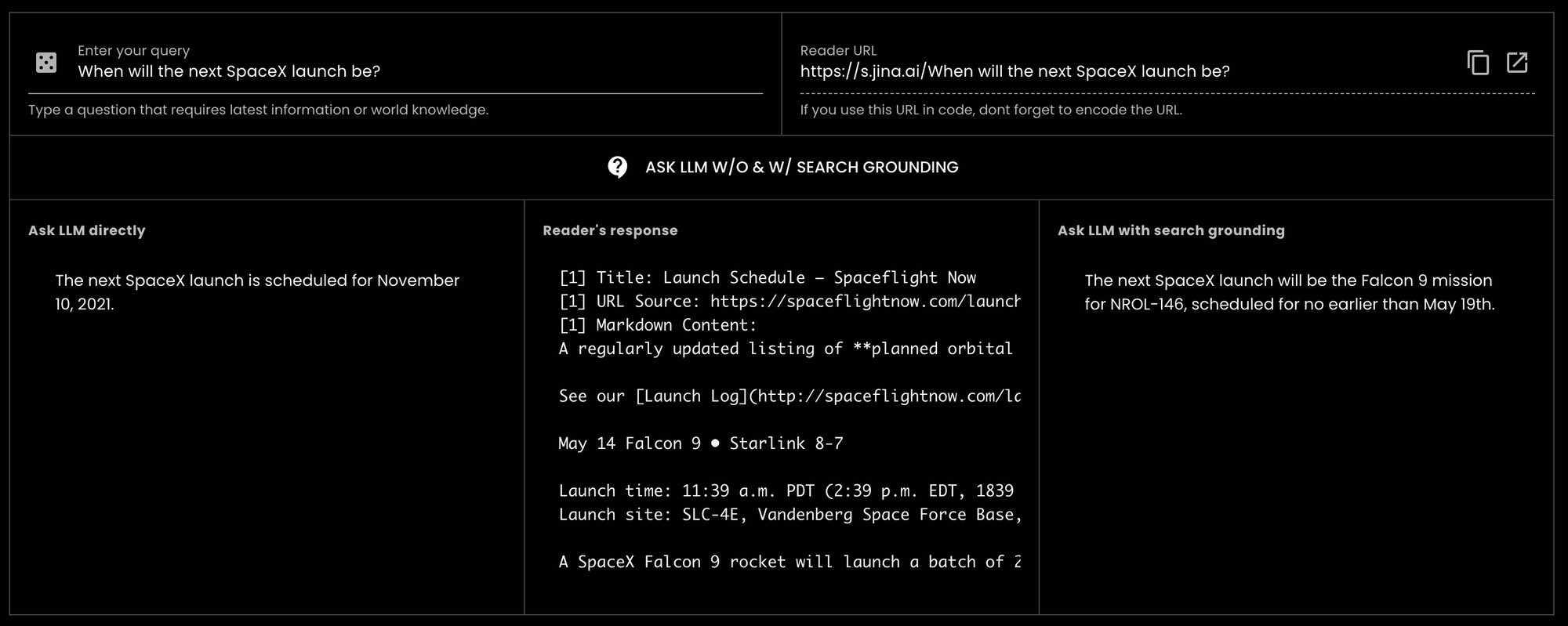
GPT-3.5-turbo에 "다음 SpaceX 발사는 언제인가요?"라고 물었을 때(오늘은 2024년 5월 14일) 모델은 2021년의 오래된 정보로 응답했습니다.tagJina Reader가 더 나은 Grounding을 돕는 방법
이전에는 사용자들이 특정 URL의 텍스트와 이미지 콘텐츠를 LLM 친화적인 형식으로 읽어들이고 사실 확인과 검증에 사용하기 위해 간단히 https://r.jina.ai를 앞에 붙일 수 있었습니다. 4월 15일 첫 출시 이후, 전 세계에서 1,800만 건 이상의 요청을 처리했으며, 이는 그 인기를 보여줍니다.
오늘 우리는 검색 grounding API https://s.jina.ai를 도입하며 한걸음 더 나아가게 되었습니다. 쿼리 앞에 이를 붙이기만 하면, Reader가 웹을 검색하여 상위 5개 결과를 검색합니다. 각 결과는 제목, LLM 친화적인 마크다운(요약이 아닌 전체 내용!), 그리고 출처를 인용할 수 있는 URL을 포함합니다. 아래는 예시이며, 라이브 데모도 직접 시도해보실 수 있습니다.
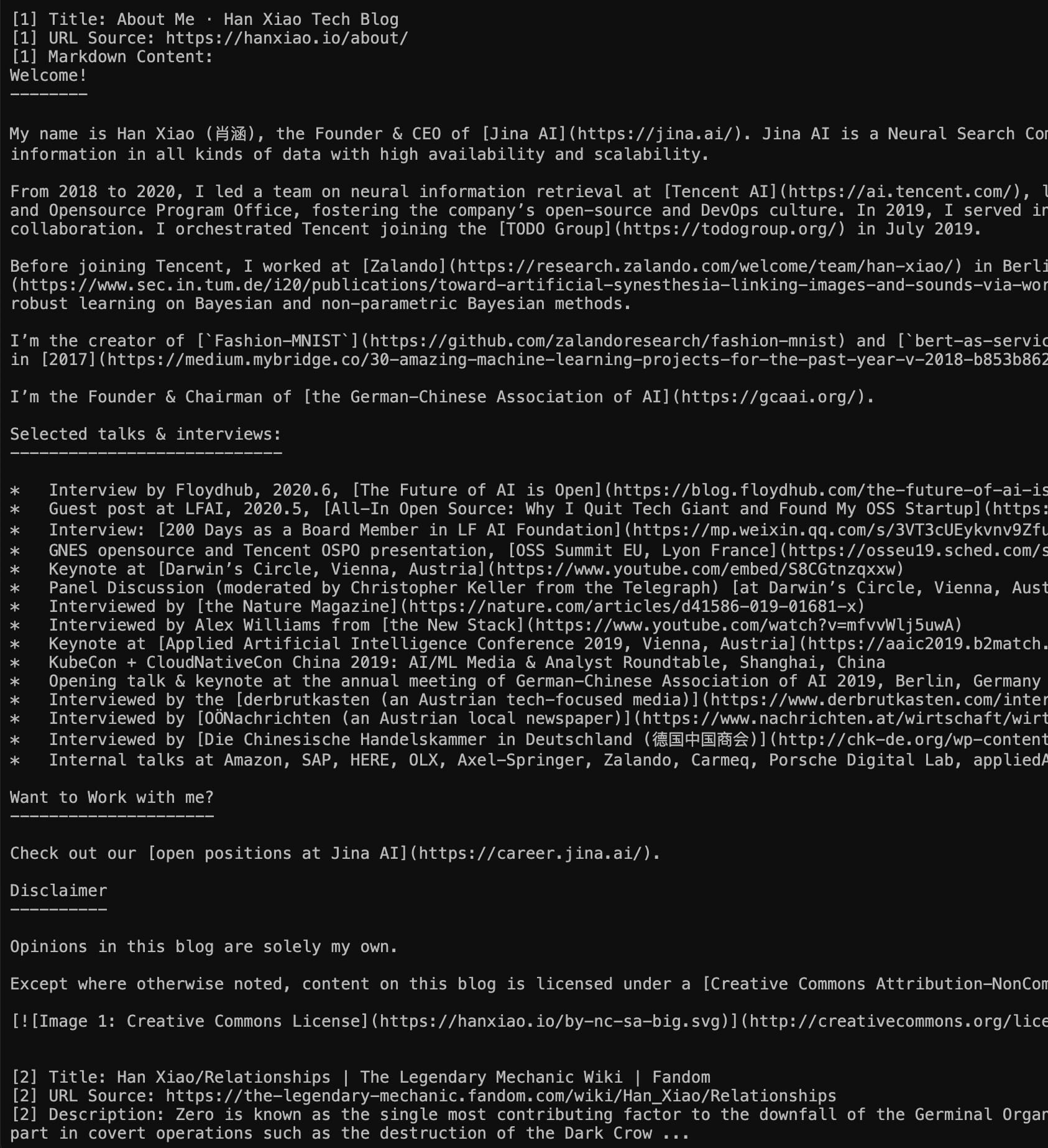
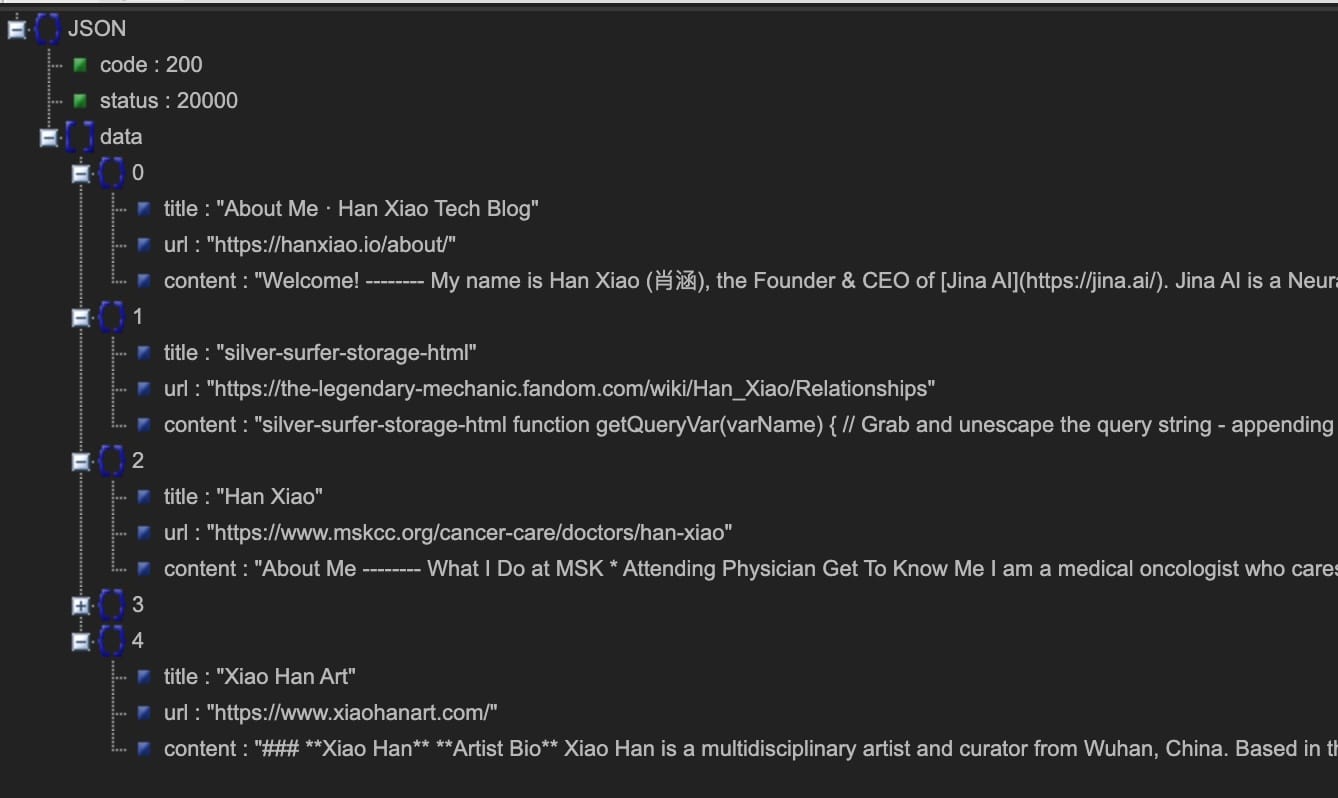
왼쪽: 마크다운 모드(직접 방문 https://s.jina.ai/who+is+han+xiao); 오른쪽 JSON 모드(curl https://s.jina.ai/who+is+han+xiao -H 'accept: application/json' 사용). 참고로, 이런 자아 질문은 항상 좋은 테스트 케이스가 됩니다.
Reader의 검색 grounding을 설계할 때 세 가지 원칙이 있었습니다:
- 사실성 개선;
- 최신 정보 접근, 즉 세계 지식;
- 답변을 출처와 연결.
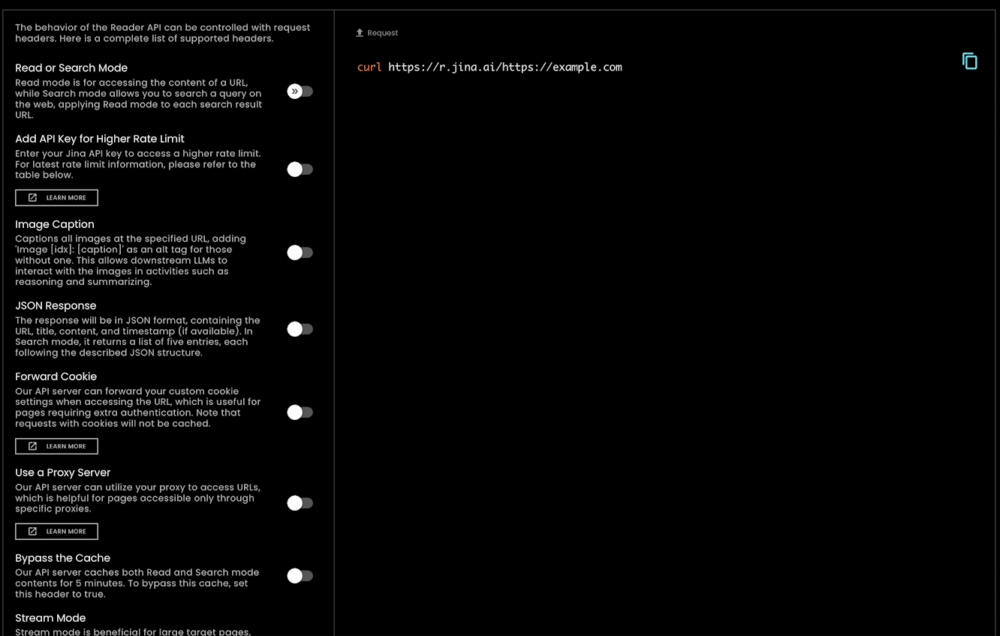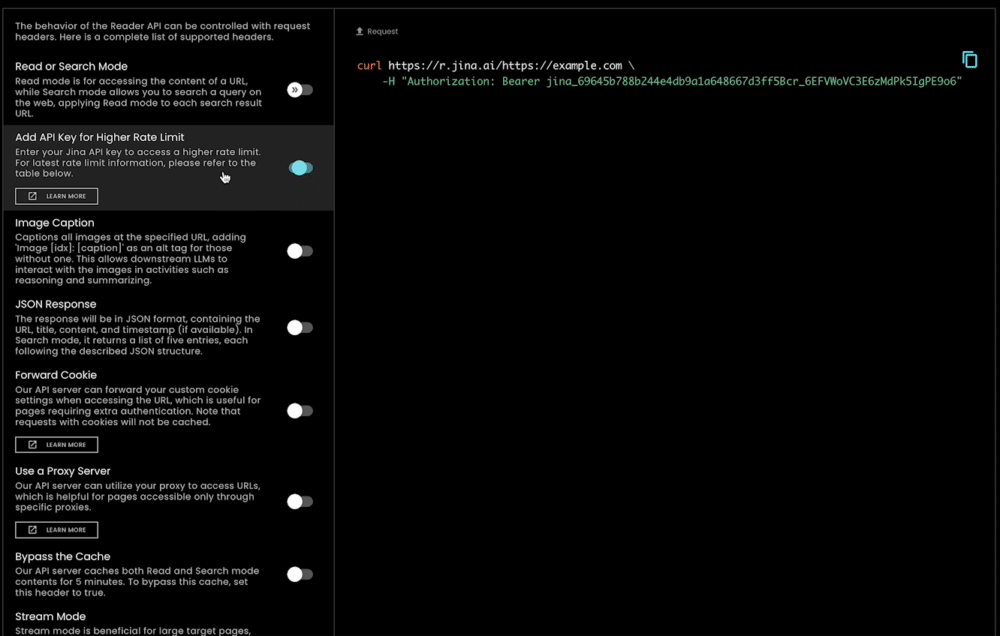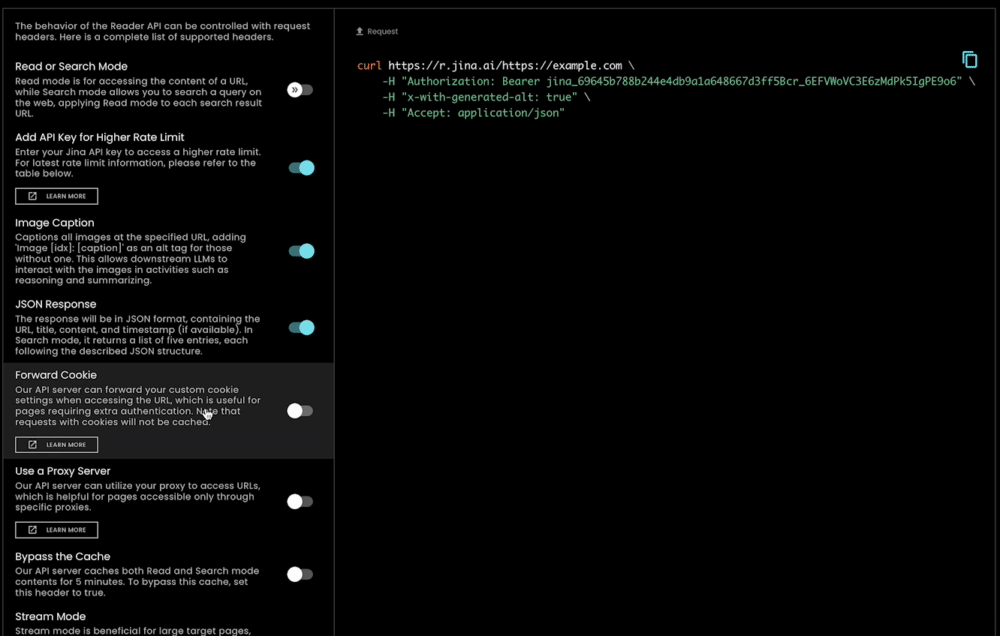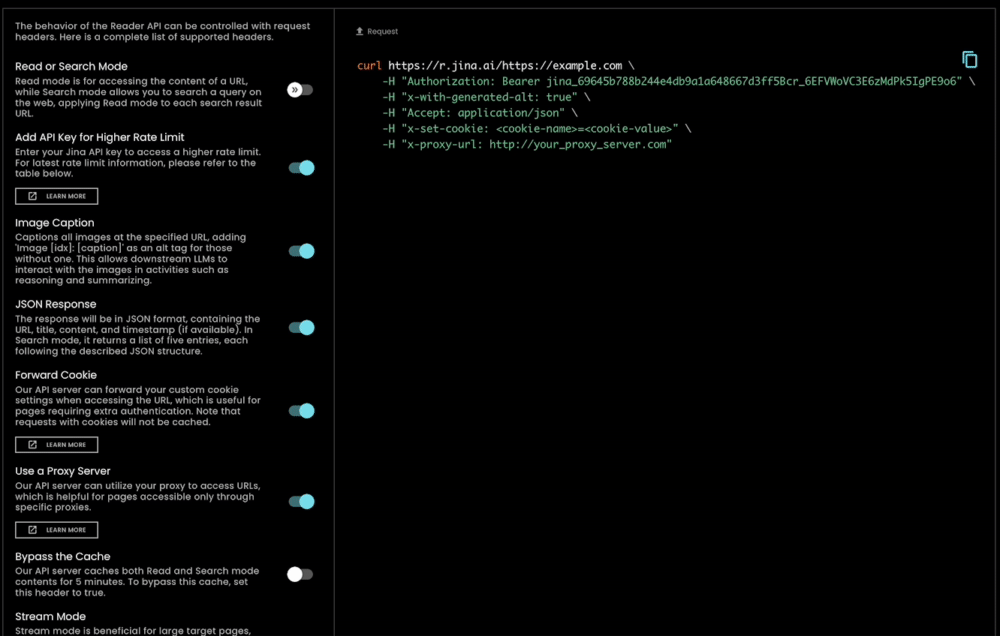
사용하기 매우 쉬울 뿐만 아니라, s.jina.ai는 r.jina.ai의 기존 유연하고 확장 가능한 인프라를 활용하기 때문에 매우 확장 가능하고 커스터마이즈할 수 있습니다. 요청 헤더를 통해 이미지 캡셔닝, 필터 세분화 등의 매개변수를 설정할 수 있습니다.
tag종합적인 Grounding 솔루션으로서의 Jina Reader

검색 grounding(s.jina.ai)과 확인 grounding(r.jina.ai)을 결합하면, LLM, 에이전트, RAG 시스템을 위한 매우 종합적인 grounding 솔루션을 구축할 수 있습니다. 일반적인 신뢰할 수 있는 RAG 워크플로우에서 Jina Reader는 다음과 같이 작동합니다:
- 사용자가 질문을 입력;
s.jina.ai를 사용하여 웹에서 최신 정보를 검색;- 이전 단계의 검색 결과를 인용하여 초기 답변 생성;
r.jina.ai로 자신의 URL로 답변을 그라운딩하거나; 3단계에서 반환된 소스에서 인라인 URL을 읽어 더 깊은 그라운딩을 수행할 수 있습니다;- 최종 답변을 생성하고 잠재적으로 그라운딩되지 않은 주장을 사용자에게 강조 표시합니다.
tagAPI 키를 통한 더 높은 요청 제한
사용자는 인증 없이 새로운 검색 그라운딩 엔드포인트를 무료로 사용할 수 있습니다. 또한 요청 헤더에 Jina AI API 키를 제공하면(Embedding/Reranking API에서 사용되는 것과 동일한 키), r.jina.ai의 경우 IP당 분당 200개 요청, s.jina.ai의 경우 IP당 분당 40개 요청을 즉시 사용할 수 있습니다. 자세한 내용은 아래 표에서 확인할 수 있습니다:
| 엔드포인트 | 설명 | API 키 없는 요청 제한 | API 키 있는 요청 제한 | 토큰 계산 방식 | 평균 지연 시간 |
|---|---|---|---|---|---|
r.jina.ai | URL을 읽고 콘텐츠를 반환, 그라운딩 확인에 유용 | 20 RPM | 200 RPM | 출력 토큰 기반 | 3초 |
s.jina.ai | 웹 검색 후 상위 5개 결과 반환, 검색 그라운딩에 유용 | 5 RPM | 40 RPM | 5개 검색 결과 모두에 대한 출력 토큰 기반 | 30초 |
tag결론
우리는 그라운딩이 GenAI 애플리케이션에 필수적이며, 그라운딩된 솔루션을 구축하는 것이 모든 사람에게 쉬워야 한다고 믿습니다. 이것이 우리가 새로운 검색 그라운딩 엔드포인트인 s.jina.ai를 도입한 이유입니다. 이를 통해 개발자들은 자신의 GenAI 애플리케이션에 쉽게 세계 지식을 통합할 수 있습니다. 우리는 개발자들이 사용자 신뢰를 구축하고, 설명 가능한 답변을 제공하며, 수백만 사용자의 호기심을 자극하기를 바랍니다.
