

Search has never been easy for smaller enterprises. Operating a high-quality information retrieval system can be an expensive and demanding proposition. Many small businesses — even many large ones — accept mediocre performance from off-the-shelf software or outsource the problem to Google or some other service provider.
There are some good reasons for this. Information retrieval (IR) is not a simple application.
- Word matching is a fairly simple application, but if you sell shoes and your customer searches for trainers, but all you have is sneakers, you will quickly find that word matching is not a good way to do search.
- Even when words match, how would your search engine know if a request for a “face mask” is for a protective face covering against contagious disease or for a Halloween costume?
- If someone searches for surfing, what they expect is very different if you’re a travel agency than if you sell clothes.
Enterprise-level search solutions require a lot of tweaks for specific use cases, demanding a lot of expertise and understanding of how search solutions work. And those tweaks have to be regularly updated for new information and new products.
The AI-driven neural search revolution has changed a lot about IR, but so far, it hasn’t really done much to solve this problem. One recent paper tried to use an AI model trained on data from before 2017 with a set of documents about COVID-19, and the results were very poor. Neural search still requires domain adaptation: The model still has to learn your subject area, business model, and documents to work properly.
The great thing about machine learning is that it doesn’t need detailed or specific information about your use case. It just needs enough good examples to learn from. We’re going to show you how to use Jina AI’s Finetuner to learn from your existing search logs without any labeling and without even knowing which of your documents best matches the queries in your logs.
tagHow AI-driven information retrieval works
Information retrieval means identifying items in a database in response to a query. For example, when you put words into the input box of an internet search engine, you get back a set of URLs (and possibly other things) from the search engine’s database that, hopefully, are the ones most relevant to the words you put in.
IR as a field of applied computer science dates back to the earliest days of computers, and people have used many different algorithms and techniques to do the actual work of matching queries to digital data items (typically called documents, although they could be any kind of digital media, not just text). The most widely used model, the one most IR systems derive from, is called the vector space model, originally developed in the early 1960s at IBM.
This model is based on a very simple idea: Every document is represented by a unique vector (often called an embedding if it comes from an AI model) in some high-dimensional space and queries are translated into vectors (embeddings) in this same space. Query matches are those documents whose vectors are closest, or close enough, to the query vector. The problem of identifying those documents is just a question of measuring the distances between the two vectors, usually by measuring the angle between them:
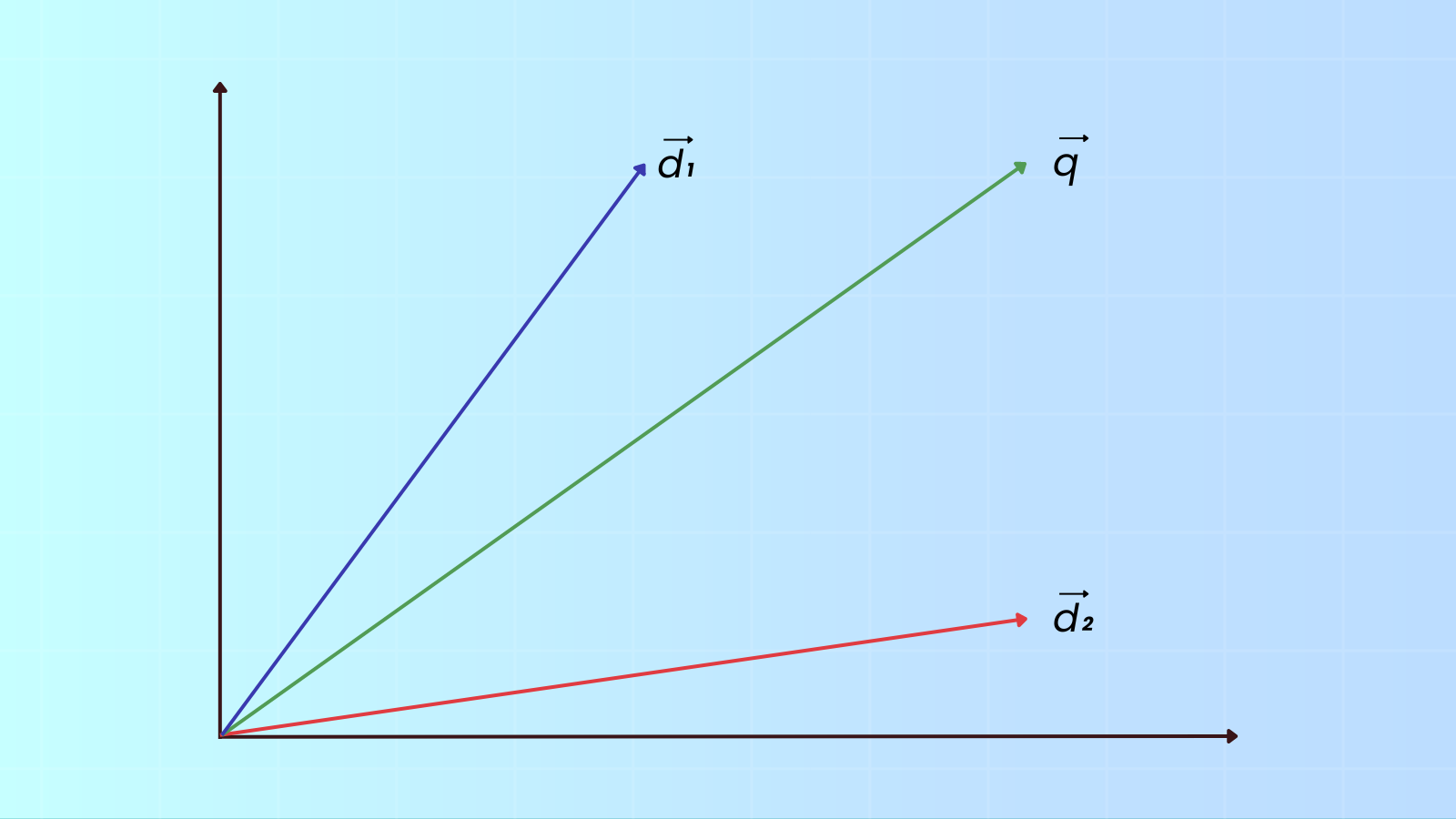
The problem is how you translate documents and queries into vectors.
Traditional vector-based information retrieval techniques like BM25 didn’t have AI models to make their vectors, but nowadays, models like SBERT do the same job directly: A neural network takes documents and queries as inputs and produces vectors as output. The fundamental problem, however, is the same: Queries and the documents that they match have to be close together in the output vector space. With traditional search technologies, you fiddle with the weights and inputs by hand to make that work. With an AI model, you use fine-tuning and make the computer do those adjustments based on examples.
tagSynthetic Training Data
If you’ve been operating an IR service — even a mediocre one — you already have the kind of data you need to adapt an AI model to your domain. Your search logs are full of user queries, and you have the documents that they need to match. That’s all you need. You don’t even need to know which queries match which results.
This works by creating synthetic training data from your queries and documents. There are five steps to the process:
- Collect your queries by extracting them from your search logs or whatever way you store them, along with whatever documents you are serving through your search system.
- Use a pre-trained text encoder model (for example, SBERT) to encode the queries and documents.
- Identify the best matching results for each query (by default, we use the 100 best matches) by calculating the distance between queries and documents.
- Use a cross-encoder to give a score to each query-result pair. We use a model trained on the MS-MARCO dataset specifically to score pairs of natural language questions and answers.
- Use the resulting data to fine-tune your AI model.
With Finetuner, you can do this with just two calls to the Jina AI Cloud.
tagFinetuner Synthesis
For the first step, you need your queries and documents. Extract them from your logs and archives by whatever means those systems require. Assemble them as DocArray objects, as lists, or in a CSV file. See the page Preparing Training Data in the Finetuner documentation for more on this subject.
Currently, Finetuner only supports queries and natural language documents in English.
You should have query data and documents in separate objects:
my_queries = <your query data>
my_documents = <your documents>The finetuner.synthesize function from Jina AI’s Finetuner performs the next three steps in a batch. You must specify your query and document data as arguments:
import finetuner
from finetuner.model import synthesis_model_en
synthesis_run = finetuner.synthesize(
query_data=my_queries,
corpus_data=my_documents,
models=synthesis_model_en,
)This does the entire data synthesis job, producing query-document pairs with scores. Once it’s done, your synthetic data is stored on Jina AI Cloud. You can see it by logging in there and going to the Storage section:
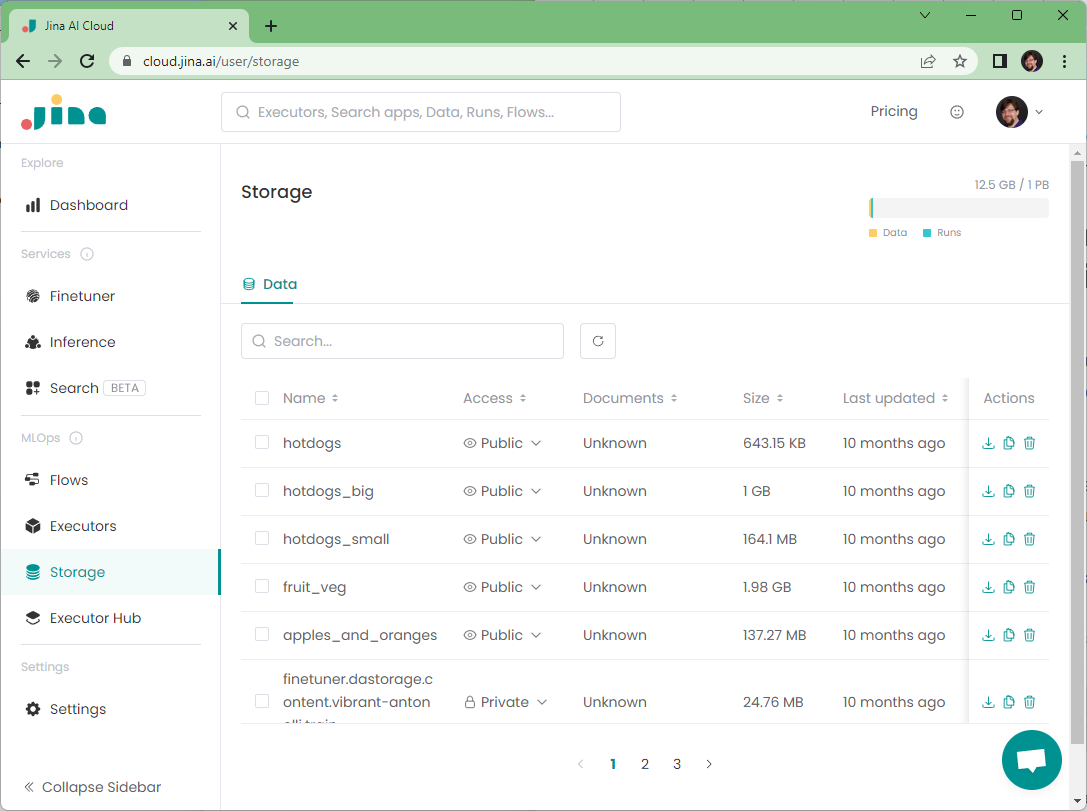
You can also get the dataset name of the synthetic training data from the train_data member of the synthesis run object:
train_data_name = synthesis_run.train_data
You can download the synthetic data from the Jina AI Cloud and inspect it or store it for future use:
train_data_name = synthesis_run.train_dataThen, run Finetuner on this new synthetic data:
train_data = DocumentArray.pull(train_data_name)
train_data.summary()Training will take some time, likely several hours, depending on the number of examples. See the Finetuner documentation for information on how to monitor the status of your Finetuner run. Once finished, you can now download your domain-adapted neural search model:
training_run.save_artifact('my_adapted_model')Using Finetuner means that adapting your AI-powered IR system to your domain is now as easy as collecting your logs. The process is quick and simple enough to run regularly when you update your website.
Keeping your IR system up-to-date with your products is critical for e-commerce businesses.
- It ensures that the most recent and relevant products or services are promptly visible to customers.
- It promotes customer satisfaction and retention, as clients can quickly find what they're searching for.
- Frequent updates help businesses remain agile in managing their inventories, especially when new products are launched or existing ones are discontinued.
- Regular model updates contribute to a smoother, more efficient user experience.
- It helps reduce the potential for AI models to make mistakes that could negatively impact customer trust.
Using Finetuner is an investment in customer satisfaction, business agility, and operational efficiency.
To learn more about data synthesis via Finetuner, see the documentation on the Finetuner website, including a notebook you can use to try it out yourself.
To learn more about Finetuner, we have a non-technical introduction on our website. You can also visit the Finetuner website or GitHub page and join us on the Finetuner announcements and support channels on our Discord community. We also provide personal assistance and support to customers via our Finetuner+ service to make the process of adapting and using AI in your business as smooth as possible.
tagGet in touch
Talk to us and keep the conversation going by joining the Jina AI Discord!






