



In multilingual models, one of the key challenges is the “language gap” — a phenomenon where phrases with the same meaning in different languages are not as closely aligned or clustered as they should be. Ideally, a text in one language and its equivalent in another should have similar representations — i.e. embeddings that are very close to each other — allowing cross-lingual applications to operate identically on texts in different languages. However, models often subtly represent the language of a text, creating a “language gap” that leads to suboptimal cross-language performance.
In this post, we’ll explore this language gap and how it impacts performance in text embedding models. We’ve conducted experiments to assess semantic alignment for paraphrases in the same language and for translations across different language pairs, using our jina-xlm-roberta model and the latest jina-embeddings-v3. These experiments reveal how well phrases with similar or identical meanings cluster together under different training conditions.

We’ve also experimented with training techniques to improve cross-language semantic alignment, specifically the introduction of parallel multilingual data during contrastive learning. In this article, we’ll share our insights and results.
tagMultilingual Model Training Creates and Reduces the Language Gap
Training text embedding models typically involves a multi-stage process with two main parts:
- Masked Language Modeling (MLM): Pretraining typically involves very large quantities of text in which some of the tokens are randomly masked. The model is trained to predict these masked tokens. This procedure teaches the model the patterns of the language or languages in the training data, including selection dependencies between tokens that might arise from syntax, lexical semantics, and pragmatic real-world constraints.
- Contrastive Learning: After pre-training, the model is further trained with curated or semi-curated data to draw the embeddings of semantically similar texts closer together and (optionally) push dissimilar ones further apart. This training can use pairs, triplets, or even groups of texts whose semantic similarity is already known or at least reliably estimated. It may have several substages and there are a variety of training strategies for this part of the process, with new research published frequently and no clear consensus on the optimal approach.
To understand how the language gap arises and how it can be closed, we need to look at the role of both stages.
tagMasked Language Pretraining
Some of the cross-lingual ability of text embedding models is acquired during pre-training.
Cognate and borrowed words make it possible for the model to learn some cross-language semantic alignment from large quantities of text data. For example, the English word banana and the French word banane (and German Banane) are frequent and similar enough in spelling that an embedding model can learn that words that look like “banan-” have similar distribution patterns across languages. It can leverage that information to learn, to some degree, that other words that don’t look the same across languages also have similar meanings, and even figure out some how grammatical structures are translated.
However, this happens without explicit training.
We tested the jina-xlm-roberta model, the pre-trained backbone of jina-embeddings-v3, to see how well it learned cross-language equivalencies from masked language pre-training. We plotted two-dimensional UMAP sentence representations of a set of English sentences translated into German, Dutch, Simplified Chinese, and Japanese. The results are in the figure below:
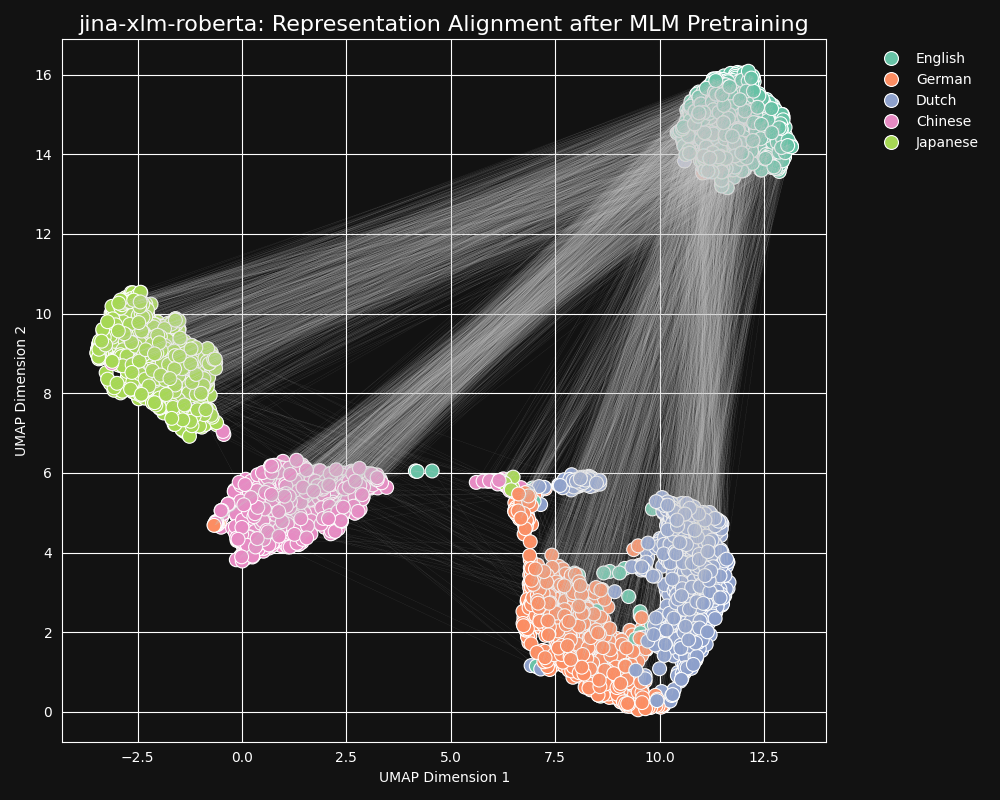
These sentences strongly tend to form language-specific clusters in the
jina-xlm-roberta embedding space, although you can see a few outliers in this projection that may be a side-effect of the two-dimensional projection.You can see that pretraining has very strongly clustered together embeddings of sentences in the same language. This is a projection into two dimensions of a distribution in a much higher dimensional space, so it is still possible that, for example, a German sentence that is a good translation of an English one might still be the German sentence whose embedding is closest to the embedding of its English source. But it does show that an embedding of an English sentence is likely closer to another English sentence than to a semantically identical or near identical German one.
Note also how German and Dutch form much closer clusters than other pairs of languages. This is not surprising for two relatively closely related languages. German and Dutch are similar enough that they are sometimes partially mutually comprehensible.
Japanese and Chinese also appear closer to each other than to other languages. Although not related to each other in the same way, written Japanese typically uses kanji (漢字), or hànzì in Chinese. Japanese shares most of these written characters with Chinese, and the two languages share many words written with one or several kanji/hànzì together. From the perspective of MLM, this is the same kind of visible similarity as between Dutch and German.
We can see this “language gap” in a simpler way by looking at just two languages with two sentences each:

Since MLM seems to naturally cluster texts by language, “my dog is blue” and “my cat is red” are clustered together, far away from their German counterparts. Unlike the “modality gap” discussed in a prior blog post, we believe this arises from superficial similarities and dissimilarities between languages: similar spellings, use of the same sequences of characters in print, and possibly similarities in morphology and syntactic structure — common word orders and common ways of constructing words.
In short, to whatever degree a model is learning cross-language equivalencies in MLM pre-training, it is not enough to overcome a strong bias toward clustering texts by language. It leaves a large language gap.
tagContrastive Learning
Ideally, we want an embedding model to be indifferent to language and only encode general meanings in its embeddings. In a model like that, we would see no clustering by language and have no language gap. Sentences in one language should be very close to good translations and far from other sentences that mean something else, even in the same language, like in the figure below:

MLM pre-training doesn’t accomplish that, so we use additional contrastive learning techniques to improve the semantic representation of texts in embeddings.
Contrastive learning involves using pairs of texts that are known to be similar or different in meaning, and triplets where one pair is known to be more similar than the other. Weights are adjusted during training to reflect this known relationship among text pairs and triplets.
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language, as shown in the UMAP projection of embeddings from jina-embeddings-v3.
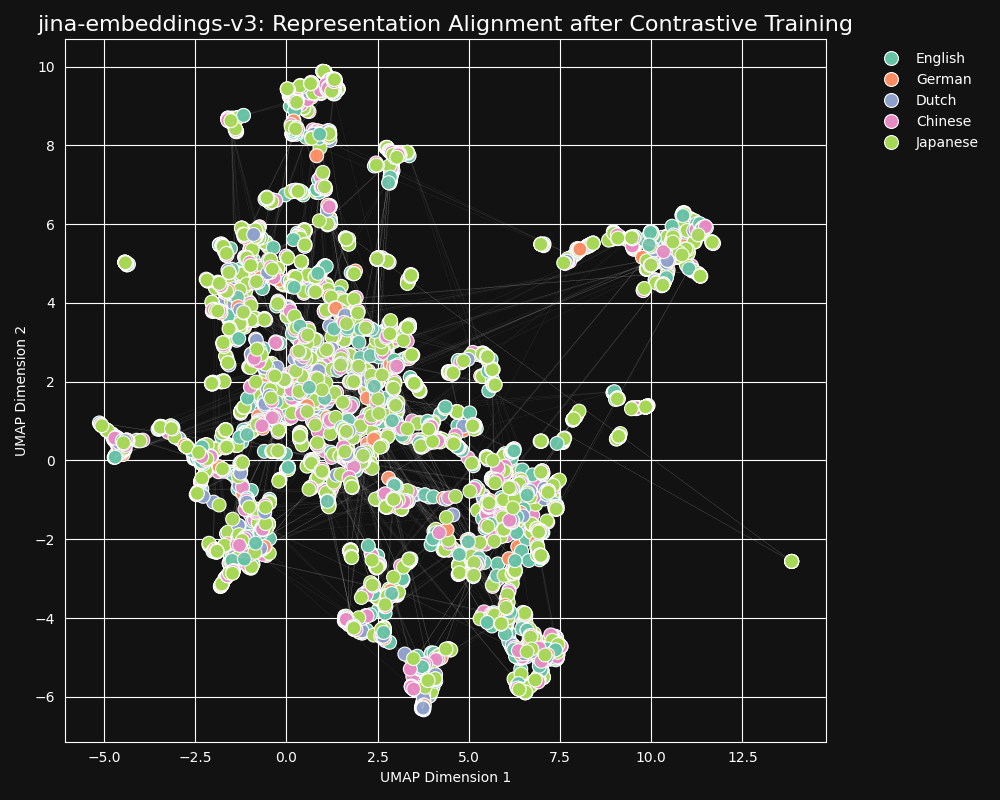
To confirm this, we measured the Spearman Correlation of the representations generated by jina-xlm-roberta and jina-embeddings-v3 on the STS17 dataset.
The table below shows the Spearman Correlation between semantic similarity rankings for translated texts in different languages. We take a set of English sentences and then measure the similarity of their embeddings to an embedding of a specific reference sentence and sort them in order from most similar to least. Then we translate all those sentences into another language and repeat the ranking process. In an ideal cross-language embedding model, the two ordered lists would be the same, and the Spearman Correlation would be 1.0.
The chart and table below show our results comparing English and the six other languages in the STS17 benchmark, using both jina-xlm-roberta and jina-embeddings-v3.
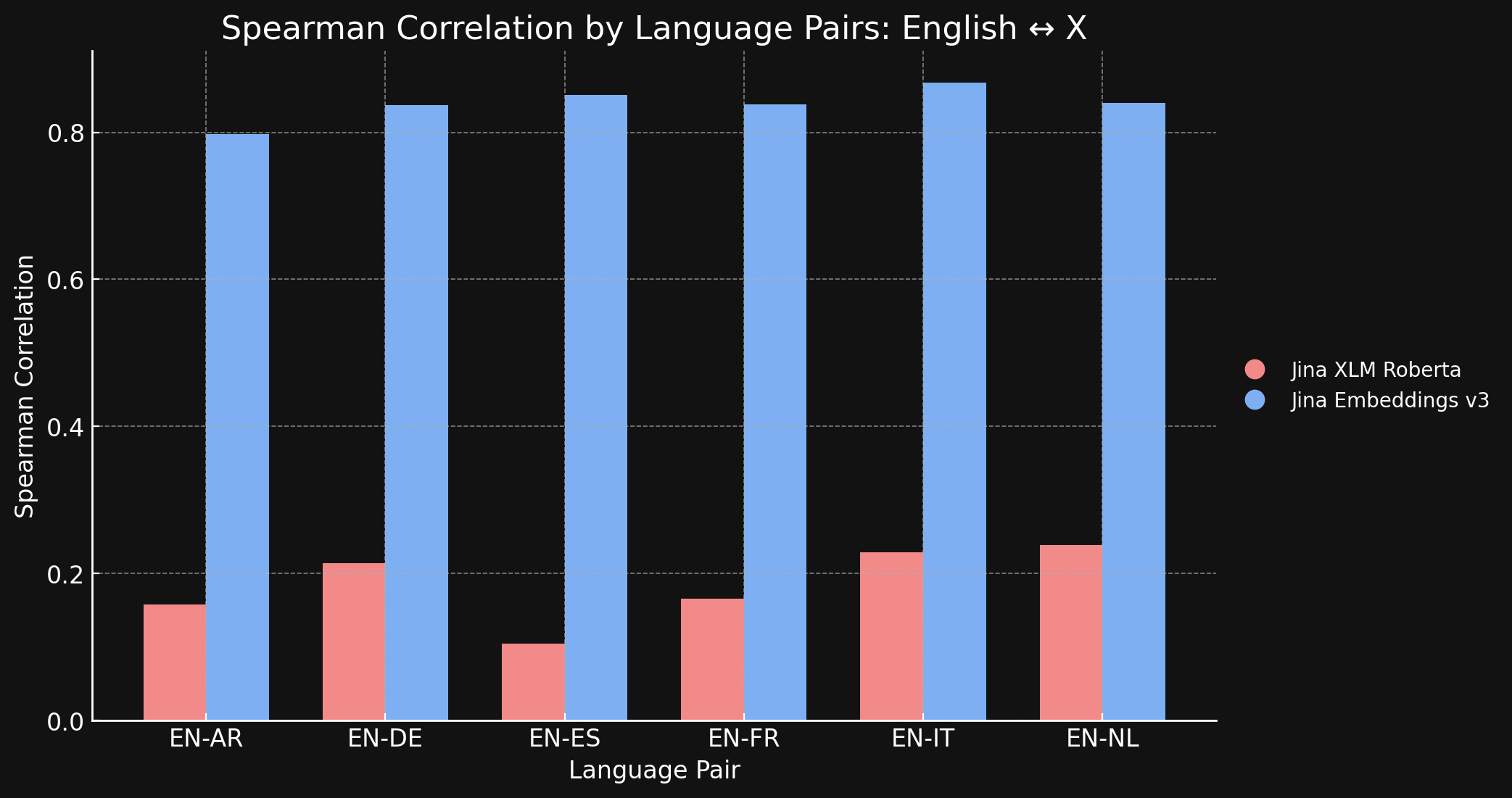
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
You can see here the massive difference contrastive learning makes, compared to the original pre-training. Despite having only 3% cross-language data in its training mix, the jina-embeddings-v3 model has learned enough cross-language semantics to nearly eliminate the language gap it acquired in pretraining.
tagEnglish vs. The World: Can Other Languages Keep Up in Alignment?
We trained jina-embeddings-v3 on 89 languages, with a particular focus on 30 very widely used written languages. Despite our efforts to build a large-scale multilingual training corpus, English still accounts for nearly half of the data we used in contrastive training. Other languages, including widely used global languages for which ample textual material is available, are still relatively underrepresented compared to the enormity of English data in the training set.
Given this predominance of English, are English representations more aligned than those of other languages? To explore this, we conducted a follow-up experiment.
We built a dataset, parallel-sentences, consisting of 1,000 English text pairs, an “anchor” and a “positive”, where the positive text is logically entailed by the anchor text.

For example, the first row of the table below. These sentences are not identical in meaning, but they have compatible meanings. They informatively describe the same situation.
We then translated these pairs into five languages using GPT-4o: German, Dutch, Chinese (Simplified), Chinese (Traditional), and Japanese. Finally, we inspected them manually to ensure quality.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
We then encoded each text pair with jina-embeddings-v3 and calculated the cosine similarity between them. The figure and table below show the distribution of cosine similarity scores for each language, and the average similarity:
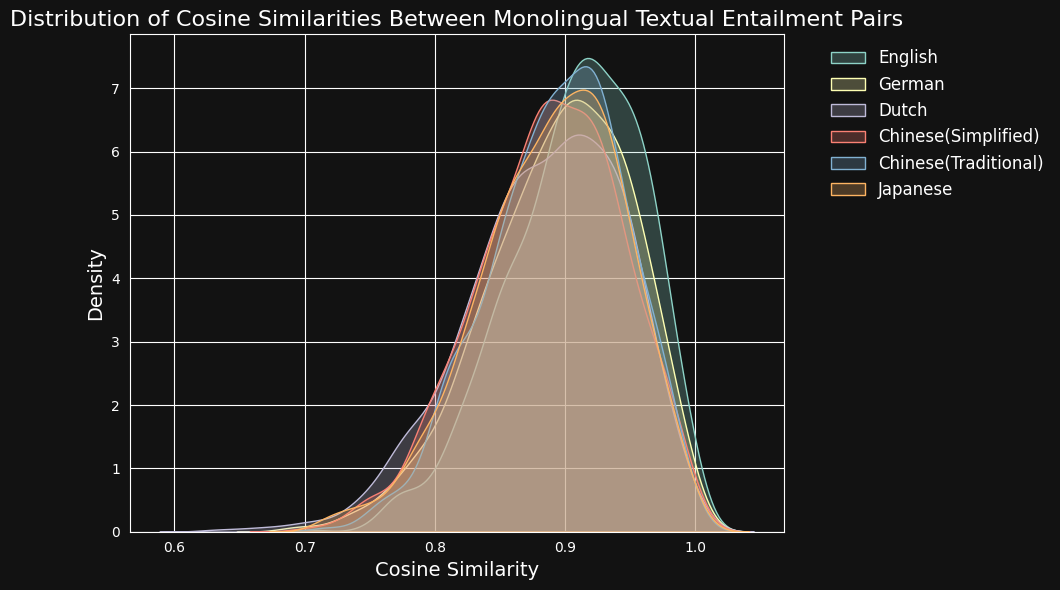
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
Despite the predominance of English in the training data, jina-embeddings-v3 recognizes semantic similarity in German, Dutch, Japanese, and both forms of Chinese about as well as it does in English.
tagBreaking Language Barriers: Cross-lingual Alignment Beyond English
Studies of cross-language representation alignment typically study language pairs that include English. This focus could, in theory, obscure what’s really going on. A model might just optimize to represent everything as close as possible to its English equivalent, without examining whether other language pairs are properly supported.
To explore this, we conducted some experiments using the parallel-sentences dataset, focusing on cross-lingual alignment beyond just English bilingual pairs.
The table below shows the distribution of cosine similarities between equivalent texts in different language pairs — texts that are translations of a common English source. Ideally, all pairs should have a cosine of 1 — i.e. identical semantic embeddings. In practice, this could never happen, but we would expect a good model to have very high cosine values for translation pairs.
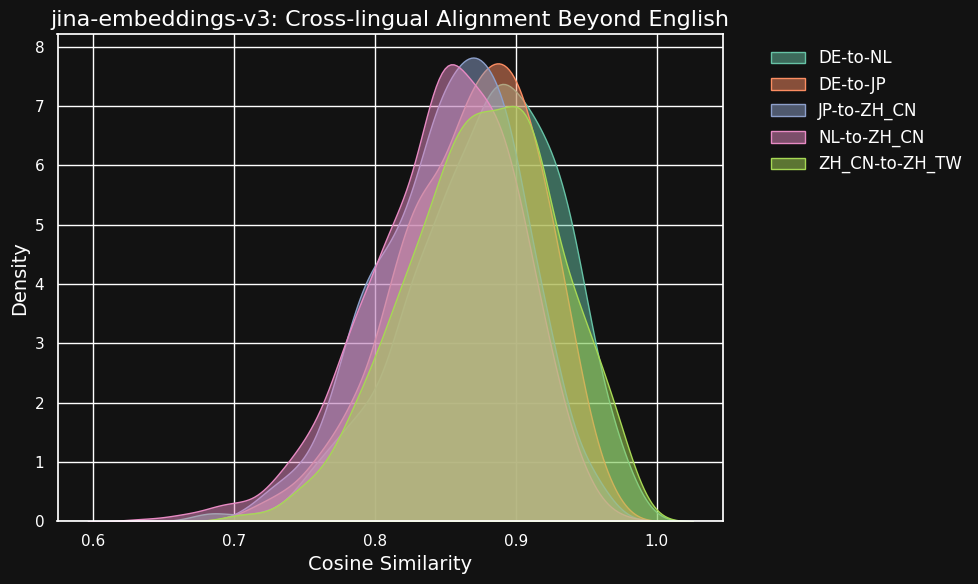
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
Although similarity scores between different languages are a little lower than for compatible texts in the same language, they are still very high. The cosine similarity of Dutch/German translations is nearly as high as between compatible texts in German.
This might not be surprising because German and Dutch are very similar languages. Similarly, the two varieties of Chinese tested here are not really two different languages, just somewhat stylistically different forms of the same language. But you can see that even very dissimilar language pairs like Dutch and Chinese or German and Japanese still show very strong similarity between semantically equivalent texts.
We considered the possibility that these very high similarity values might be a side-effect of using ChatGPT as a translator. To test this, we downloaded human-translated transcripts of TED Talks in English and German and checked if the aligned translated sentences would have the same high correlation.
The result was even stronger than for our machine-translated data, as you can see from the figure below.
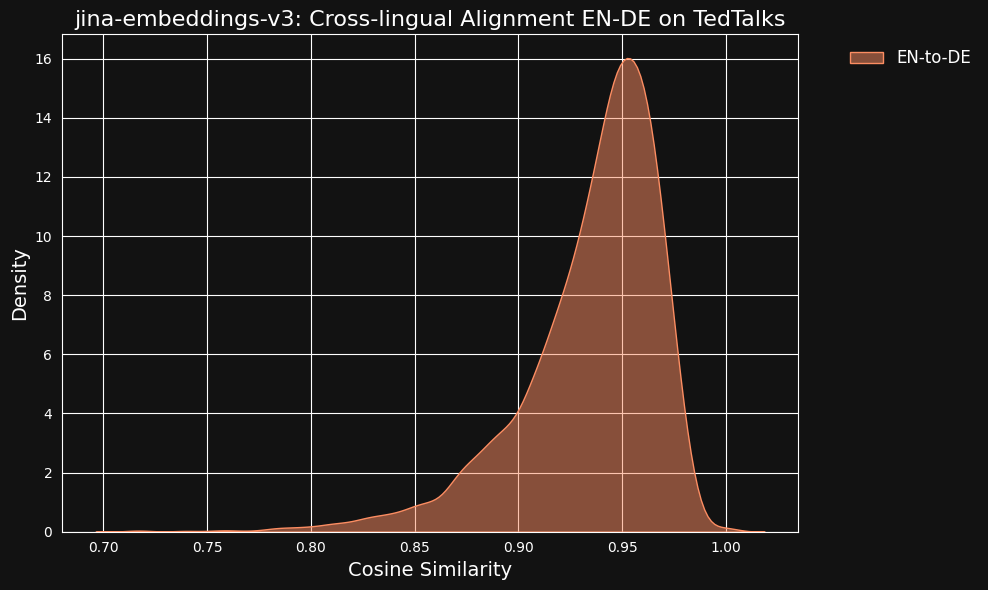
tagHow Much Does Cross-Language Data Contribute to Cross-Language Alignment?
The vanishing language gap and high level of cross-language performance seem disproportionate to the very small part of the training data that was explicitly cross-language. Only 3% of the contrastive training data specifically teaches the model how to make alignments between languages.
So we did a test to see if cross-language was making any contribution at all.
Completely retraining jina-embeddings-v3 without any cross-language data would be punitively expensive for a small experiment, so we downloaded the xlm-roberta-base model from Hugging Face and further trained it with contrastive learning, using a subset of the data we used to train jina-embeddings-v3. We specifically adjusted the amount of cross-language data to test two cases: One with no cross-language data, and one where 20% of pairs were cross-language. You can see the training meta-parameters in the table below:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
We then evaluated both models’ cross-lingual performance using the STS17 and STS22 benchmarks from the MTEB and the Spearman Correlation. We present the results below:
tagSTS17
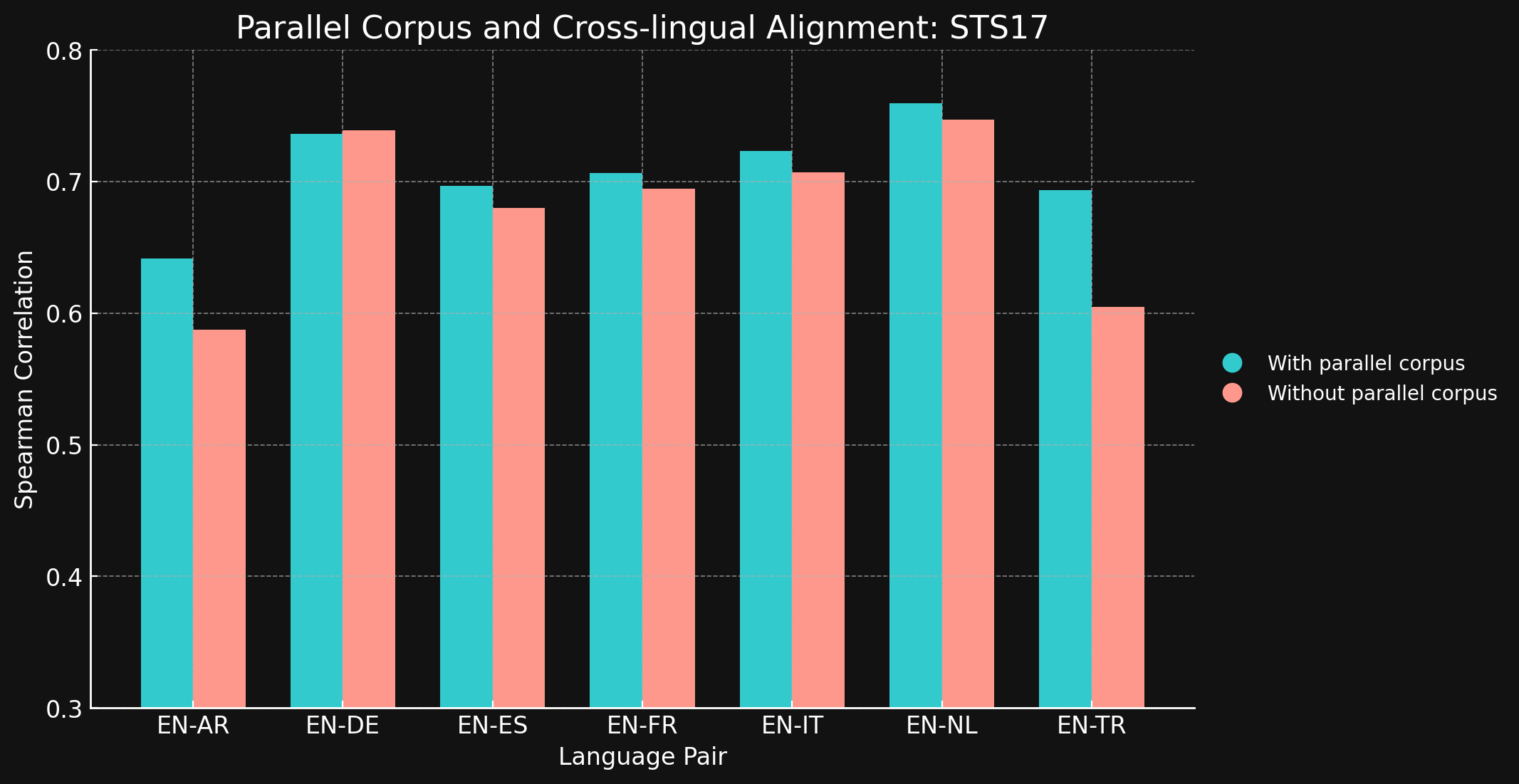
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
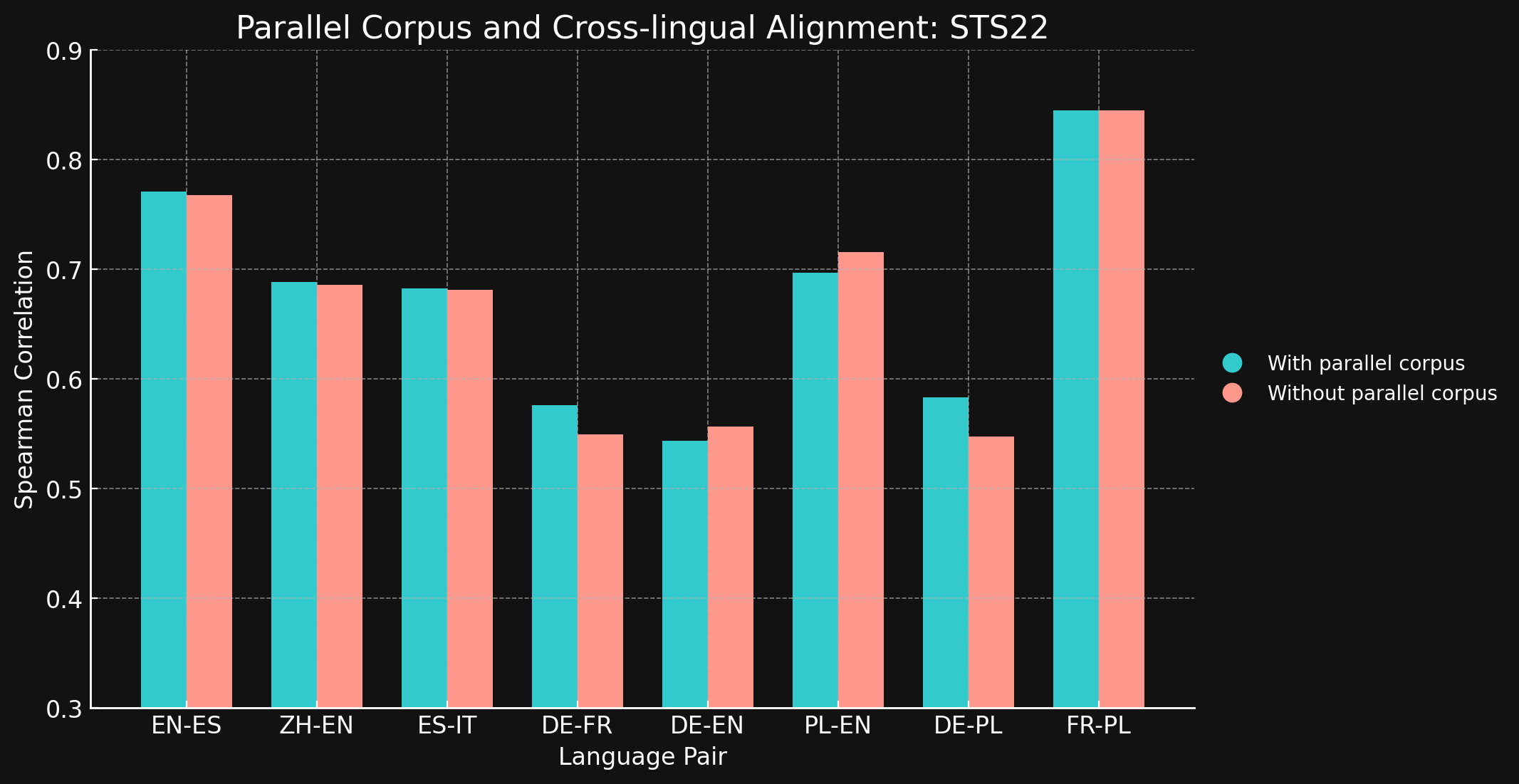
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
We were surprised to see that for most of the language pairs we tested, cross-lingual training data brought little to no improvement at all. It is difficult to be sure this would remain true for fully trained models with larger datasets, but it certainly offers evidence that explicit cross-language training does not add much.
However, note that STS17 includes English/Arabic and English/Turkish pairs. These are both much less well-represented languages in our training data. The XML-RoBERTa model we used was pre-trained with data that was 2.25% in Arabic and 2.32% in Turkish, far smaller than for the other languages we tested. The small contrastive learning dataset we used in this experiment was only 1.7% Arabic and 1.8% Turkish.
Those two language pairs are the only ones tested where training with cross-language data made a clear difference. We think explicit cross-language data is more effective for languages that are less well-represented in the training data but need to explore this area more before drawing a conclusion. The role and effectiveness of cross-language data in contrastive training is an area where Jina AI is doing active research.
tagConclusion
Conventional language pre-training methods, like Masked Language Modeling, leave a "language gap," where semantically similar texts in different languages fail to align as closely as they should. We’ve shown that Jina Embeddings’ contrastive learning regimen is very effective in reducing or even eliminating this gap.
The reasons why this works are not entirely clear. We use explicitly cross-language text pairs in contrastive training, but only in very small quantities, and it is unclear how much role they actually play in ensuring high-quality cross-language results. Our attempts to show a clear effect using more controlled conditions did not produce an unambiguous result.
However, it is clear that jina-embeddings-v3 has overcome the pre-training language gap, making it a powerful tool for multilingual applications. It is ready to use for any task requiring strong, identical performance across multiple languages.
You can use jina-embeddings-v3 via our Embeddings API (with one million free tokens) or via AWS or Azure. If you want to use it outside of those platforms or on-premises in your company, just keep in mind that it's licensed under CC BY-NC 4.0. Reach out to us if you’re interested in commercial use.





