


Last week I was in Gyeongju, Korea for the COLING2022 conference. COLING is the premier conference in computational linguistics held every two years.
The conference was very well organized, and the talks were very interesting. I learned a lot about the latest research in computational linguistics and NLP, such as automated writing evaluation and multi-hop question answering. I also had a chance to meet many old friends and make new ones at the Jina AI dinner event.





Dinner event hosted by Jina AI at COLING2022
In this article, I will review the multimodal AI-related work presented at COLING 2022. Despite being primarily an NLP conference, there were 26 presentations focused on multimodal AI, covering text-image, text-video, and text-speech domains. I would like to highlight three presentations that I found particularly interesting.
tagAre Visual-Linguistic Models Commonsense Knowledge Bases?

We have all seen the huge potential for pretrained language models (PTLMs) over the last few years. Models such as Transformer and GPT have been widely used in many downstream tasks due to their potential as a commonsense knowledge base. However, the text corpora used to train PTLMs can make them very biased, and this can make them inconsistent and not very robust. In this paper, Yang and Silberer suggest that text corpora alone may be insufficient for knowledge acquisition and raise important questions for visual-linguistic models like UNITER, VILBERT, and CLIP:
They address this problem with probing questions like this one:

tagWhich dimensions of commonsense do visual-linguistic models possess compared to text-only PTLMs?
Hsui-Yu shows that visual-linguistic (VL) models such as UNITER and VILBERT are better at part-whole, spatial, and desire dimensions but struggle with taxonomic, distinctness, and temporal dimension. In terms of spatial dimension, VL models consistently outperform RoBERTa by 8%. On non-visual related dimensions such as taxonomic and temporal, VL models underperform by 8%, which is understandable as taxonomy and temporality are rarely represented in images. When using real-world images for training VL, distinctness is also hard to learn because opposite concepts e.g. flood and drought, rarely come together in one picture.
tagDuring pretraining, does explicit visual information (i.e., images) benefit commonsense knowledge encoding?
When adding a BERT pretrained with image captions, the advantage of VL models becomes less significant, even on the spatial dimension. This shows that image captions can already provide a good proxy for visual information. The only dimension that VL models outperform is part-whole, with a tiny margin though.
tagDuring inference, is explicit visual observation (i.e., images) necessary for recalling commonsense knowledge?
The above experiments have not used the visual input during the zero-shot QA task, so a natural question is, will adding images help? The answer is no. Visual information just makes everything worse. In fact, experiments show that all dual-stream (textual + visual) models underperform compared to their text-only counterparts on part-whole, spatial, taxonomic, and distinctness dimensions. This suggests that the texts are the driving force for successful inference on purely linguistic tasks.
What I found interesting about this work is the demystifying of the multimodal model, showing that although state-of-the-art VL models do encode complementary knowledge types to pure language models, the way that they combine visual and textual signals is still very primitive and not human-like at all.
tagDual Capsule Attention Mask Network with Mutual Learning for Visual Question Answering
It is worth mentioning that the probing task from the last work is not a visual question-answering (VQA) task, though it contains QA pairs and images. A formal VQA task looks like the following:
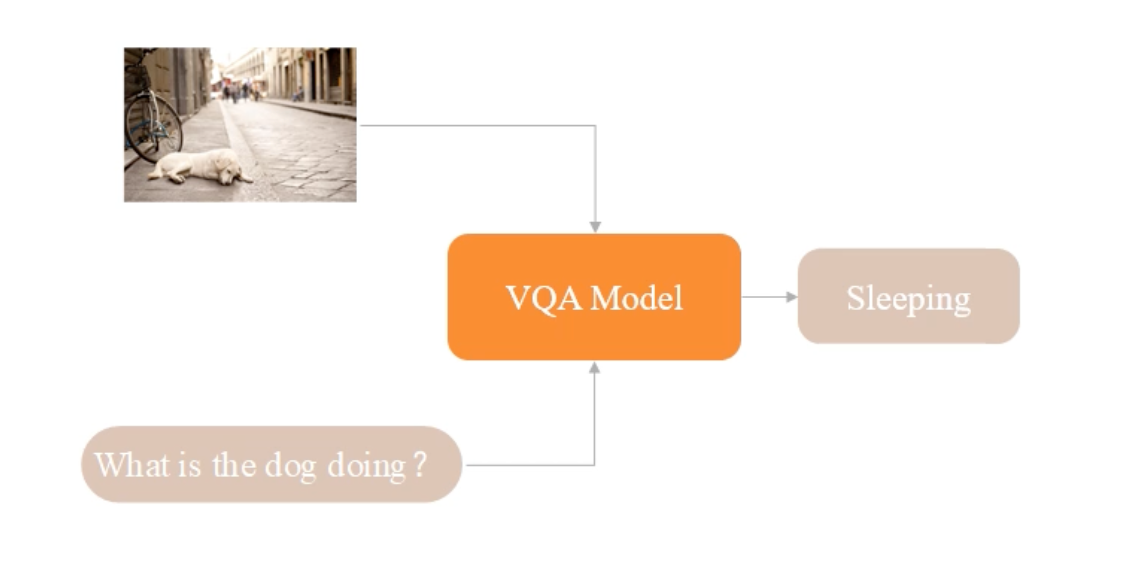

The challenge of the VQA task is how to leverage fine-grained features with critical information to ensure that feature extraction emphasizes the objects related to the questions. Let's see two examples below:

In the left example, the fine-grained features with attention have the critical information required for the answer inference, which helps the model generate the correct answer by eliminating irrelevant factors that could interfere. In the right example, unattended coarse-grained features contain the richer semantic information needed for a correct answer.
Weidong et al. address that in their paper. They propose a dual capsule attention mask network (DCAMN) with mutual learning for VQA.
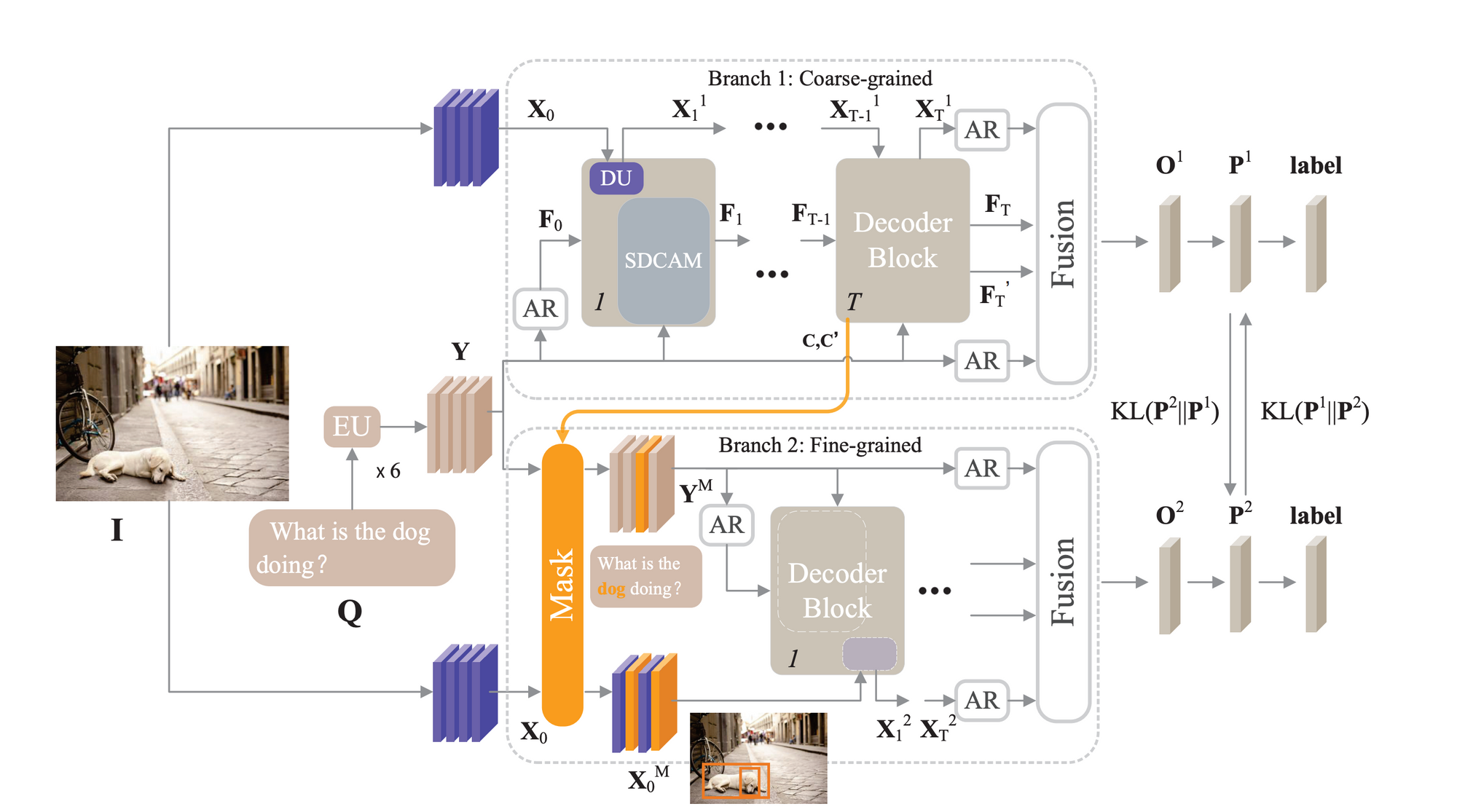
DCAMN can process features at different granularities, taking global information into account and focusing on critical information. Combining different perspectives and granularities can improve the generalization capability of the model and make more accurate predictions.
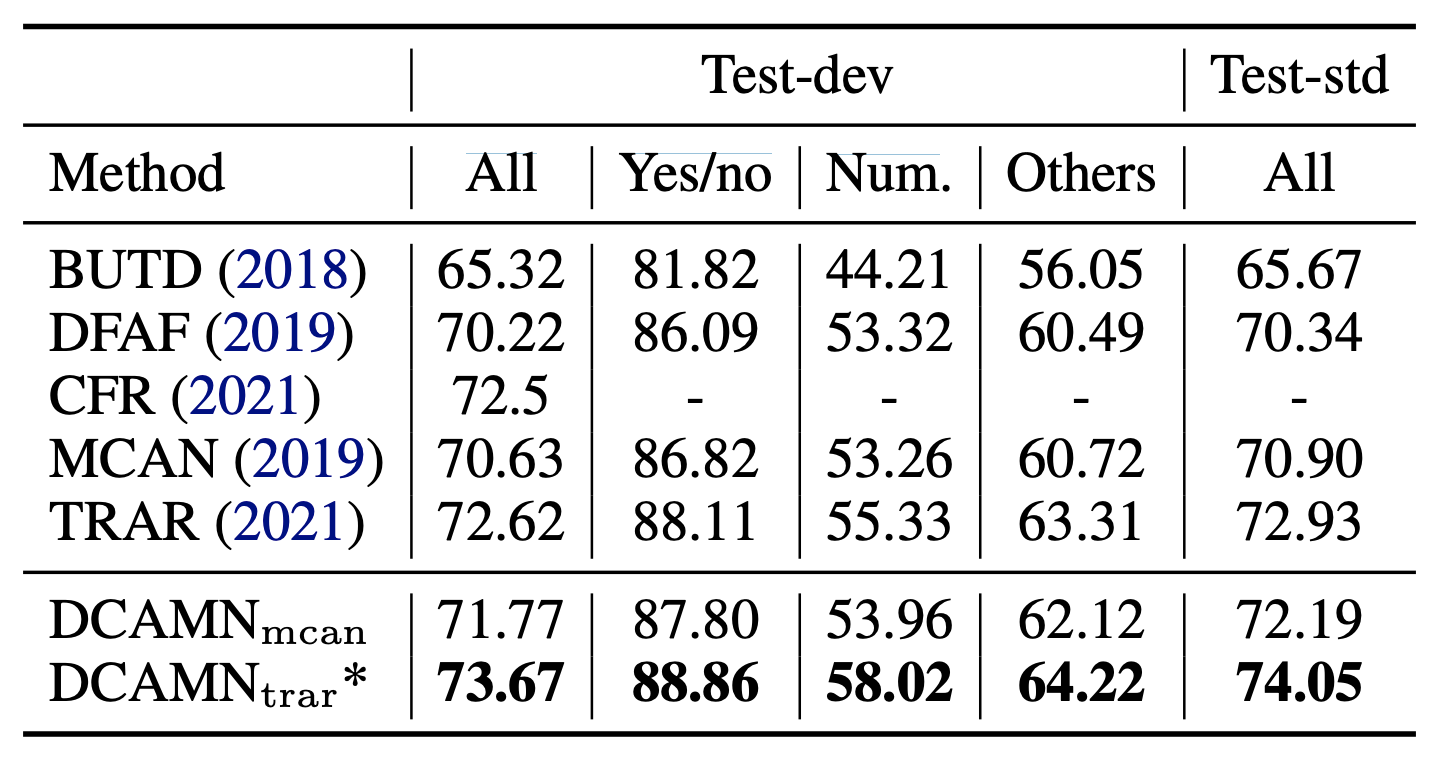
In addition, the proposed DCAMN can effectively fuse multimodal features and locate evidence, improving the interpretability of the network, as the picture below illustrates:


The attention mechanism and the model's interpretability are of particular interest for explainable multimodal AI.
tagIn-the-Wild Video Question Answering

As a temporal extension of Visual QA, Video QA plays an important role in the development of intelligent AI systems, as it enables the effective processing of modality and temporal information. In the example below, given a long-video and a question, a video QA system first aims to generate open-ended answers. Second, it retrieves visual support for a given question and answer, which is represented by a span.
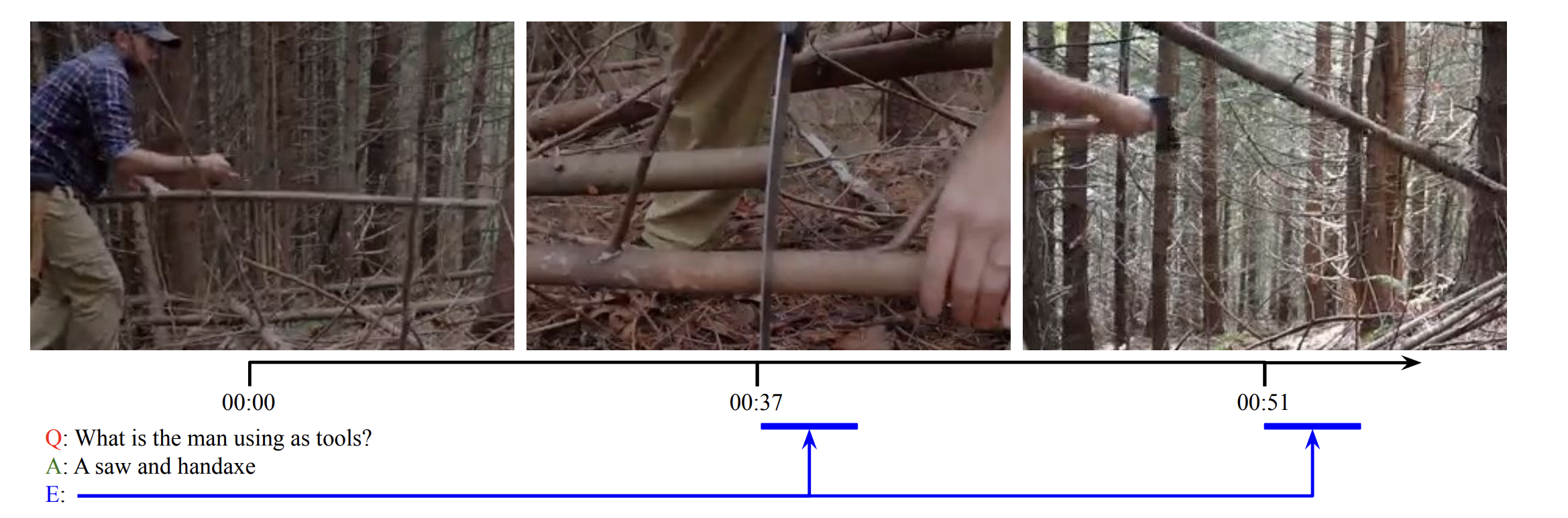
Much of the existing work on Video QA is based on the MovieQA (Tapaswi et al., 2016), and TVQA (Lei et al., 2018) datasets, which focus on common human activities in a multiple-choice setting. These datasets consist primarily of video from cooking videos or movies, making them very limited in domain.
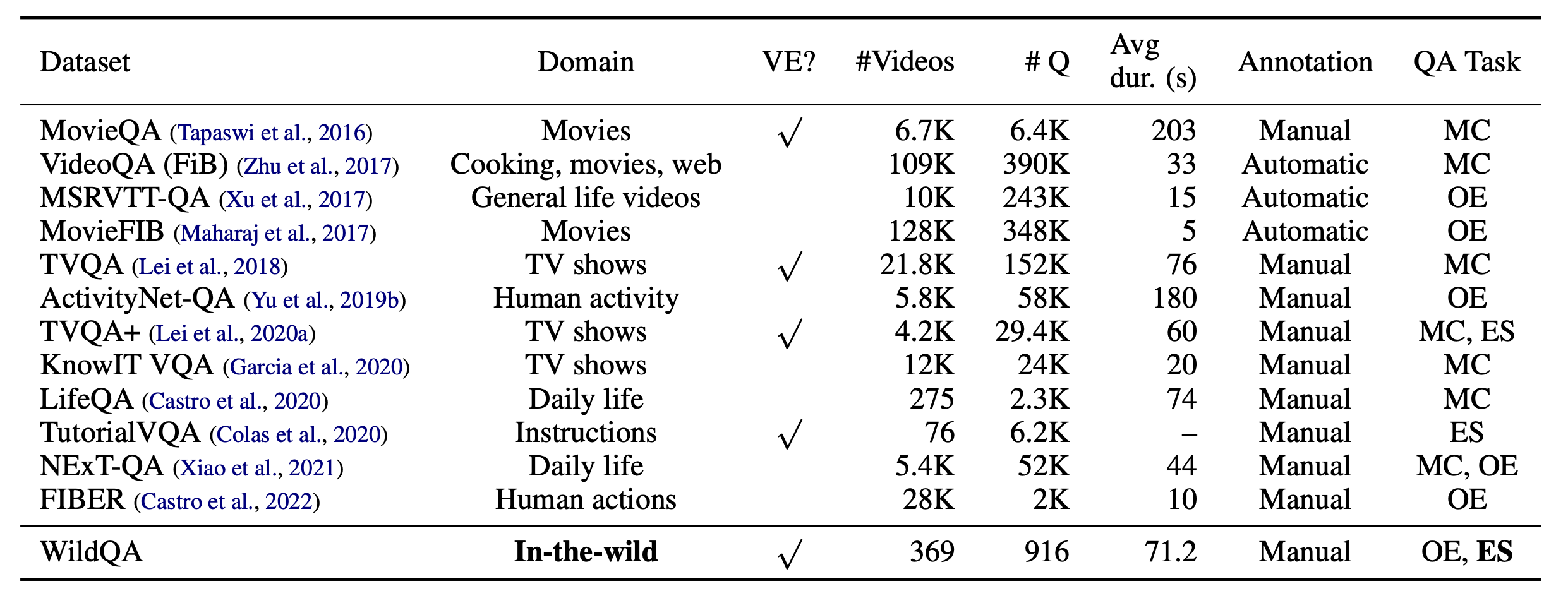
Santiago et al. propose the WildQA dataset and tasks that focus on scenes recorded in the outside world in an open-ended setting, like the example below:
Q1: What kinds of bodies of water are there? A1: There are rivers and streams. Evidence: 0:07 - 0:14
tagMulti-Task Learning of T5 Model with I3D Features
To solve WildQA, Santiago et al. concatenate the text features with the visual features and input the concatenated features to the T5 model. They extract I3D video features and take one feature per second.
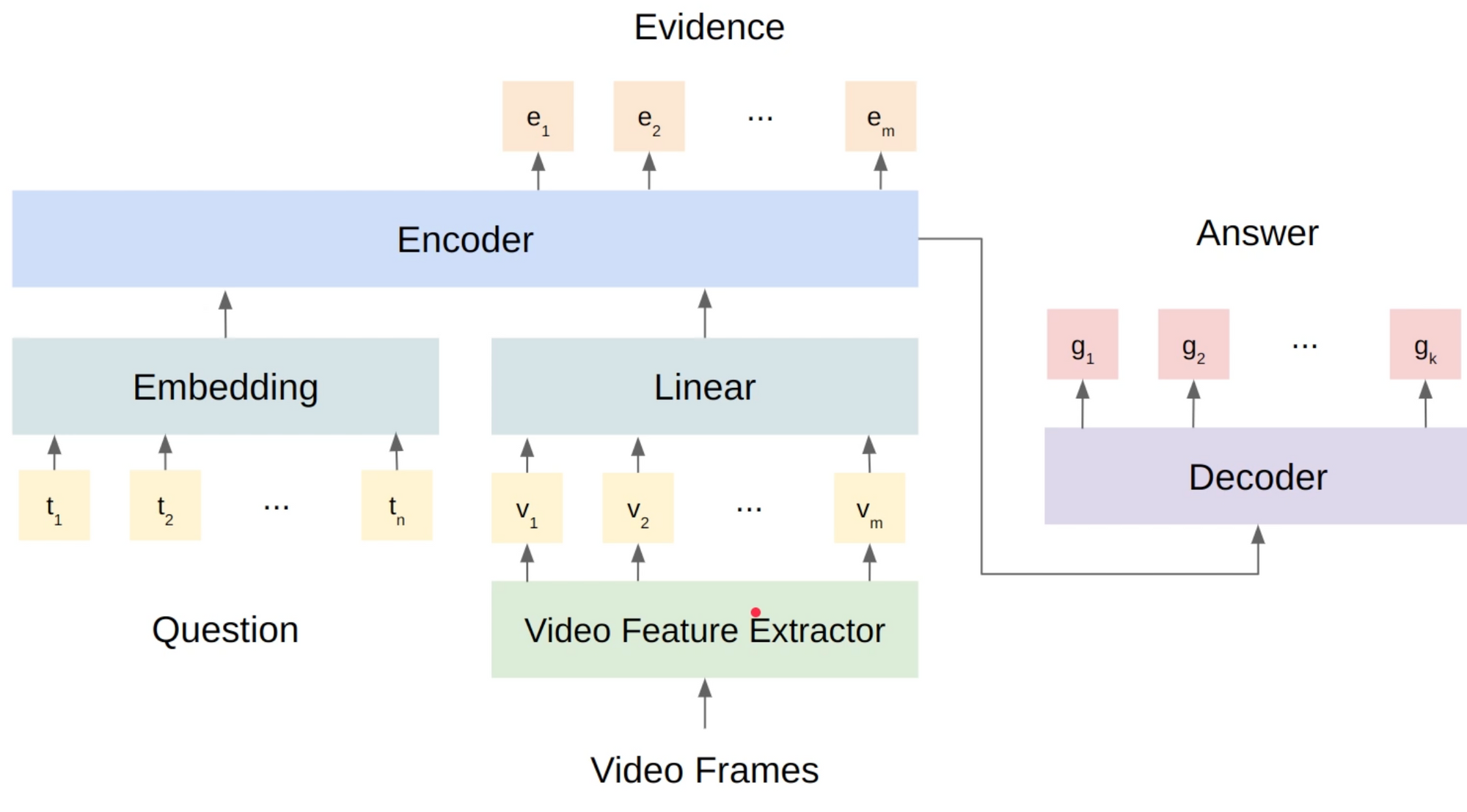
T5 encoder outputs a sequence of the encoded states. Santiago et al. treat the subsequence corresponding to the visual features as the encoded hidden sequence for the video frames. They then multiply the sequence with two vectors to get the maximum likelihood prediction of the start and the end of the evidence, respectively.
The tasks of visual evidence selection and video question-answering can be jointly trained together by simply combining the two losses in a weighted-manner.
In the experiment, Santiago et al. propose multiple baselines including: randomly choosing answers from the dev set (i.e. Random); always predicting the most common answer in the dev set (i.e. Common); and retrieving the answers for the dev set question whose embedding has the highest cosine similarity to the test question (i.e. Closest).
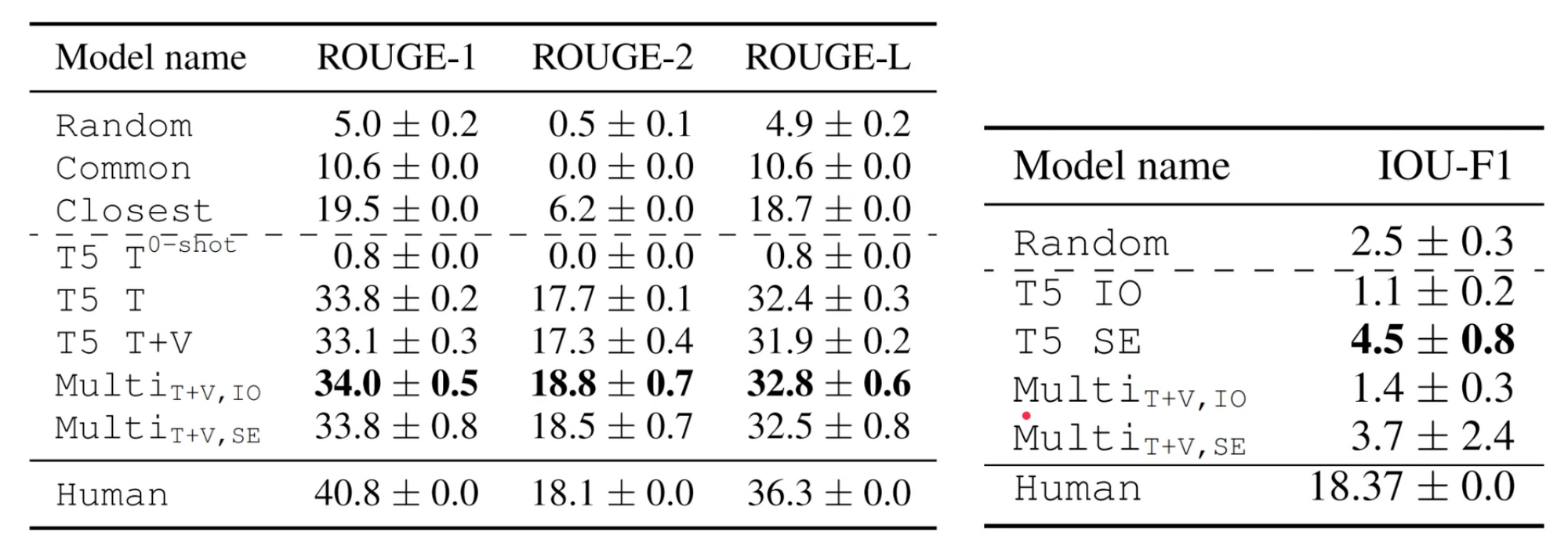
I noticed that introducing video information (T5 T+V) does not improve performance on video question-answering tasks, which confirms what Yang & Silberer said in their work. This may also due to the types of questions in WildQA, which do not match commonsense knowledge. In the video evidence selection task, the T5 model is not even better than the random baseline. Adding multi-task learning does not help. In general, we can conclude WildQA is a pretty challenging task with a significant gap between the state-of-the-art multimodal model and human.
tagOther Interesting Multimodal Research
tagMultimodal Social Media
There are multiple research projects focusing on multimodality in the social media. For example, the upswing of text and image sharing on social media platforms during mass emergency situations has led to numerous opportunities to gain timely access to valuable information that can help disaster relief authorities act more quickly and more efficiently.
Iustin et al. extend the FixMatch algorithm to a multimodal scenario and offer two extensions to the original approach relevant for text and multimodal datasets. They show that multimodal FixMatch can leverage inexpensive unlabeled data to improve performance on diaster classification tasks.

Extracting spatial information from social media and tweets has also received substantial attention recently. Zhaomin et al. propose BERT+VGG16 multimodal model to determine whether people are located in the places they mention in their tweets.

To better understand when the text and image are most beneficial, Zhaomin et al. perform a qualitative analysis of the errors made by the single-stream model, and how these errors are fixed by the dual-stream model.
Social media is a good place to conduct sentiment analysis. As a popular way to express emotion on social media, stickers & memes in posts can supplement missing sentiments and help identify sentiments precisely. Stickers and memes, despite being represented as images or simple gifs, have very different semantics from real-world photos. Feng et al. point out three challenges when working with stickers/memes:

- First, stickers may be inherently multimodal because they are embedded with texts. Same sticker with different sticker texts may vary significantly in sentiment.
- Second, stickers are highly varied in style, preventing the models from learning robust representations.
- Third, the way sentiment is fused together from text and stickers is complicated and sometimes inconsistent.
This work actually reminds me a popular Youtube video explaining Gen Z humor and their meme behaviors:
Was popular = Funny
Ironic = Funny
Make no sense = Funny
Unfunny = Funny
There's nothing that Gen-Zers like more than changing and hating things. So perhaps our models on sentiment analysis have become obsolete?
tagText-Gestures Multimodal
Communication is a multimodal process. Information from verbal and non-verbal modalities are mixed into one channel. It has been revealed from a long history of empirical studies that speakers’ expression in the visual modality, including gestures, body poses, eye contacts and other types of non-verbal behaviors, play critical roles in face-to-face communication, because they add subtle information that is hard to convey in verbal language.
Yang etc. consider gestures as non-verbal communication and prove that non-verbal communication also conforms to the principle of entropy rate constancy (ERC). Under this assumption, communication in any form (written or spoken) should optimize the rate of information transmission rate by keeping the overall entropy rate constant.

This means that the information encoded in hand gestures, albeit subtle, is actually organized in a rational way that enhances the decoding/understanding of information from a receiver’s perspective.
Artem etc. consider human gestures together with their corresponding utterances. They explore a multimodal approach to learning gesture embeddings through contrastive learning, and attempt to predict psycholinguistic categories and the language of the speaker from their gesture embeddings.

tagText-Image Multimodal, but via Topic Modelling
Perhaps the most surprising work to me is from Elaine et al., who present a novel neural multilingual and multimodal topic model that takes advantage of pretrained document and image embeddings to abstract the complexities between languages and modalities. Their work is based on the contextualized topic model, a family of topic models that uses contextualized document embeddings as input.

It surprises me that after more than 12 years, Latent Dirichlet Allocation (LDA) models still show up in top conferences like COLING. After reading through the paper, I found a lot of adoption has been made over the last few years to make the original LDA more "deep". In fact, it is now called neural topic models (NTMs), which refers to a class of topic models that use neural networks to estimate the parameters of the topic-word and document-topic distributions.
tagSummary
There has been some great work on multimodal AI presented at COLING this year. It is clear that this is a subject that is only going to continue to grow in importance, as I pointed out in the blog post below.

Multimodal AI allows machines to better understand the world around them by processing data from multiple modalities (e.g. text, images, audio). This is an important step towards true artificial general intelligence, as it allows machines to more closely approximate the way humans process information.








