

LLMs are cool, but their input context windows are always so small. They’re getting bigger, but they’ll never be big enough for, say, a whole book, much less an encyclopedia, unless there is some breakthrough in AI model architectures.
RAG (Retrieval Augmented Generation) is a strategy that can compensate for this limitation, letting you use LLMs to respond to questions with answers that draw on relevant parts of documents or whole repositories of documents that are far too large to put entirely into the model’s input.
This article will show you how to use LlamaIndex, Jina Embeddings, and the Mixtral-8x7B-Instruct-v0.1 language model (hosted on HuggingFace) to build a complete RAG system. For more information on the Mixtral language model, see the Mistral AI website or the model card on HuggingFace.




You can also download a Jupyter Notebook with all the code in this article from GitHub, or run it directly on Colab.
You will need:
Since both the Jina Embeddings model and Mixtral are running remotely and are accessed via a web API, you won’t need any special hardware. You will need to install Python and meet the system requirements for LlamaIndex.
tagWhat is RAG and How Does it Work?
Retrieval Augmented Generation is a strategy that merges search with language generation. The way it works is that it uses an external information retrieval system to find documents that are likely to inform the answer to a user query. It then passes them, with the user’s request, to a text-generating language model, which produces a natural language response.
This allows you to use an LLM to answer questions and use information from documents and sets of documents that are much larger than its input context window. The LLM only sees a few pertinent parts of the document when responding to prompts. This also has the advantage of reducing (although not eliminating) inexplicable hallucinations.
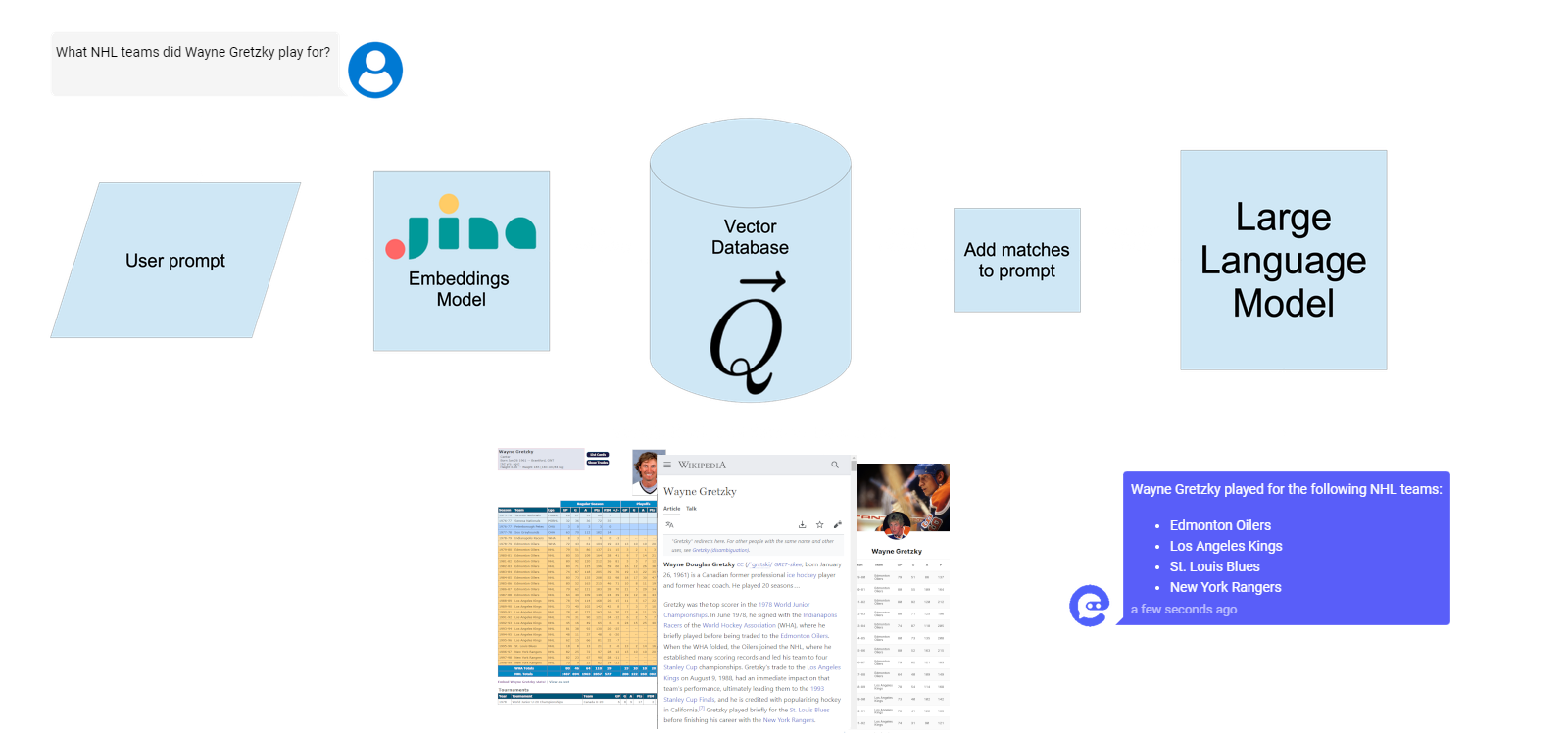
This strategy has some limitations:
- It is sensitive to the input context size supported by the LLM. The larger the context size, the more information you can give the LLM, yielding better and richer responses.
- It is sensitive to the quality of the results of the initial information retrieval. If your search engine gives it irrelevant or inaccurate results, the LLM may paste them together as best it can and give you garbage output. This can be caused by bad data (as the saying goes garbage in, garbage out) but can also be caused by a search system that does not return the most useful matches or does not rank them highly enough in the results.
High-quality embeddings are key to making RAG work because they reduce the impact of these limitations.
First, a small context size for an LLM means it’s extra important to find the most relevant information, because you cannot add very much to the user’s prompt. Second, how informative the answer is depends on how informative the input is. If the search results displayed to the LLM are irrelevant or poorly informative, that will be reflected in the result.
AI-generated embeddings are, on the whole, the best way to find and rank query results in general.
tagBuild a Full RAG Chatbot
We will create and install a full RAG system using the LlamaIndex framework for working with LLMs. This system uses Jina Embeddings to index document elements and store them in LlamaIndex’ built-in vector store and search engine. Then, it uses the newly released Mixtral Instruct model to construct natural language answers.
The approach in the article will also work with OpenAI’s GPT models and Meta’s Llama2, with some adaptation of the code and possibly the prompt. For more details, read the LlamaIndex documentation.
This section involves a lot of code to copy and paste, and it will only get a very high-level explanation. You may prefer to download the accompanying notebook or run this code on Google Colab.
tagGetting Started
First, install LlamaIndex, including dependencies specific for handling LLMs and Jina AI embeddings:
pip install llama-index
pip install llama-index-llms-openai
pip install llama-index-embeddings-jinaai
pip install llama-index-llms-huggingface
pip install "huggingface_hub[inference]"Next, make sure that you have a Jina API key and a HuggingFace Inference API token.

In Python, set up your secret key values like this:
jinaai_api_key = "<your Jina Embeddings API key>"
hf_inference_api_key: str = '<your HuggingFace Inference API token>'
tagConnect Jina Embeddings
LlamaIndex provides built-in support for the Jina Embeddings API. To use it, you only need to initialize the JinaEmbedding object with your API key and model name. For this example, we will use jina-embeddings-v2-base-en.
from llama_index.embeddings.jinaai import JinaEmbedding
jina_embedding_model = JinaEmbedding(
api_key=jinaai_api_key,
model="jina-embeddings-v2-base-en",
)
tagConnect Mixtral LLM
We will also need to load the Mixtral-8x7B-Instruct-v0.1 model. We will wrap it in a subclass of llama_index.llms.CustomLLM to make it compatible with LlamaIndex.
The important elements are the class parameters:
model_name: str = "mistralai/Mixtral-8x7B-Instruct-v0.1"
api_key: str = hf_inference_api_key
context_window: int = 4096
num_output: int = 512
The parameter model_name is the name of the model on HuggingFace, in this case, mistralai/Mixtral-8x7B-Instruct-v0.1, which is also the path part of the URL for its model card on HuggingFace. For api_key, you need to use your HuggingFace Inference API token. Then, specify the input context size the model supports (context_window), in this case, 4096 tokens, and the maximum output size in tokens (num_output), 512.
The code below sets up the LLM object in the LlamaIndex framework:
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
mixtral_llm = HuggingFaceInferenceAPI(
model_name="mistralai/Mixtral-8x7B-Instruct-v0.1",
token=hf_inference_api_key
)tagPrepare a Text for RAG
Next, we will download a document and break it into pieces.
For this exercise, the text we’ll use is Computers on the Farm, published by the US Department of Agriculture in 1982 and available via the Gutenberg Project. This 10,000-word booklet is full of useful information for the farmer considering buying a home computer for farm operations 40 years ago.
Naturally, its advice is perhaps less helpful today.
However, it serves as a good example because it is much longer than the input context size of Mixtral LLMs or Jina Embeddings v2.


The code below will strip the Gutenberg Project header and footer from the text, correct the MS DOS-style linebreaks to conventional ones, and split the text on the headers.
import urllib.request
from typing import List
from llama_index.core.readers import StringIterableReader
from llama_index.core.schema import Document
def load_gutenberg(target_url: str) -> List[Document]:
ret: List[str] = []
buff: str = ""
reject: bool = True
for raw_line in urllib.request.urlopen(target_url):
line = raw_line.decode("utf-8")
stripped_line = line.strip()
if reject:
if stripped_line.startswith("*** START OF THE PROJECT GUTENBERG EBOOK"):
reject = False
continue
else:
if stripped_line.startswith("*** END OF THE PROJECT GUTENBERG EBOOK"):
reject = True
continue
if stripped_line:
if stripped_line.startswith('=') and stripped_line.endswith('='):
ret.append(buff)
buff = ""
buff += stripped_line[1:len(stripped_line)-1] + "\n\n"
else:
buff += line.replace('\r', '')
if buff.strip():
ret.append(buff)
return StringIterableReader().load_data(ret)
docs = load_gutenberg("https://www.gutenberg.org/cache/epub/59316/pg59316.txt")
# check that we loaded
assert len(docs) == 58The result is a collection of 58 small documents.
The code below does the following:
- Create a
ServiceContextobject that holds both the Mixtral LLM and the Jina Embeddings connection. We will use this here and later to create the full RAG system. - Get an embedding for each small document using the Jina Embeddings API.
- Store the documents and embeddings in LlamaIndex’s built-in in-memory vector store
VectorStoreIndex.
from llama_index.core import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(
llm=mixtral_llm, embed_model=jina_embedding_model
)
index = VectorStoreIndex.from_documents(
documents=docs, service_context=service_context
)
tagPrepare a Prompt
Next, we will create a custom prompt template. This prompt specifically asks the LLM not to use information outside of the context information retrieved from the vector database and to specifically say “No information” when the context does not have any information that answers the user’s request.
from llama_index.core import PromptTemplate
qa_prompt_tmpl = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query. Please be brief, concise, and complete.\n"
"If the context information does not contain an answer to the query, "
"respond with \"No information\"."
"Query: {query_str}\n"
"Answer: "
)
qa_prompt = PromptTemplate(qa_prompt_tmpl)
Then, we assemble the query engine using the prompt.
The key parameter to look at here is similarity_top_k=2 in VectorIndexRetriever. This tells the RAG system to put only the best two search matches into the context sent to the LLM.
We can set this to a larger value if we’re confident it will fit into the input context size of the LLM, so this factor is partly model-dependent and partly data-dependent.
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core import get_response_synthesizer
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer(
service_context=service_context,
text_qa_template=qa_prompt,
response_mode="compact",
)
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
tagAsking the RAG Engine Questions
Now you can ask questions and receive answers based on the text.
result = query_engine.query("How is a computer useful on a farm?")
print(result.response)
Result:
A computer can be useful on a farm by supplementing the calculator,
typewriter, and file cabinet. It can help with repetitive analyses,
data storage, and management decisions. It can also send and receive
written or graphic messages by telephone. Additionally, a computer
program for a farm operation could make recordkeeping and analysis
easier and improve management abilities. However, the improvements
in efficiency and cost-effectiveness might be hard to measure in
dollars.
You can ask questions that have an answer from the text that the LLM would never have produced on its own:
result = query_engine.query("How much memory does a computer need?")
print(result.response)
Result:
48K or 64K of memory is needed for most agricultural programs. The
amount of memory needed depends on the software program and
recordkeeping requirements.
And you can ask questions that have no answer in the text:
result = query_engine.query("Who is buried in Grant's tomb?")
print(result.response)
Result:
No information. The context information does not provide any details
about Grant's tomb.
tagChecking the RAG Retrieval
You may want to check to see what texts were retrieved for a specific query. For example:
result = query_engine.query("What is the address of AgriData Resources?")
print(result.response)
Result:
205 West Highland Ave. Milwaukee, WI 53203
To check the retrieval phase, we have to use the retriever object we created above:
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
You can rerun the retrieval and then inspect the documents:
retrieved_texts = retriever.retrieve("What is the address of AgriData Resources?")
for i, rt in enumerate(retrieved_texts):
print(f"Text {i+1}:\n\n{rt.text}\n\n")
Result:
Text 1:
3. AgriData Network
AgriData is a private information and computing network specializing in
agriculture. It offers immediate access to more than 10,000 pages of
continuously updated business, financial, marketing, weather, and price
information, as well as analyses and recommendations from its own and
other reporters, analysts, economists, meteorologists, and researchers.
It offers several different services, including an online computing
service that allows users to access a library of microcomputer software
programs that can be transferred to the user's microcomputer; an
agricultural production technology service offering data bases from 40
land-grant universities and from agricultural, chemical, fertilizer,
equipment, seed, and feed companies; an "electronic yellow pages," or
product service directory for farmers; and electronic mail.
ADDRESS: AgriData Resources, Inc.
205 West Highland Ave.
Milwaukee, WI 53203
Text 2:
2. AGRICOIA
AGRICOIA is an online information service produced by the National
Agricultural Library (NAD of USDA), and is available commercially from
a number of sources (including DIALOG and Bibliographic Retrieval
Services). It provides comprehensive access to information on published
literature pertaining to agriculture.
AGRICOIA is the catalog and index for NAL and covers materials
published since 1970. It includes about 1.5 million citations.
AGRICOIA contains citations to worldwide published books, serial
titles, and journal articles on agriculture and related subjects. In
addition to bibliographic citations of published literature, the system
offers information through several specialized subfiles; these subfiles
include brucellosis (BRU), environmental impact statements covering
1977 and 1978 (ENV), and the Food and Nutrition Information Center,
which emphasizes human nutrition research and education and food
technology (FNC).
Librarians are the main users of this system.
ADDRESS: To find out more about AGRICOIA, contact:
Educational Resources Staff
National Agricultural Library
Room 1402
Beltsville, MD 20705
tagMaking RAG Work For You
With Jina Embeddings, LlamaIndex, and Mixtral LLM, you can make your own RAG system that can answer questions about long documents, respond to requests based on a manual or FAQ, or just behave in funny or useful ways, based on a large document context.
And you can do all this without complex AI operations engineering or even training your models.
Jina AI is committed to helping you make the most of emerging AI technology. In our coming articles, we delve deep into the practical issues of using embedding models, like discussing ways of chucking documents for use in RAG and search applications. We will also have more integration tutorials and practical advice for text pre-processing and data curation.
Learn more from the Jina Embeddings and LlamaIndex websites, or reach out to us at [email protected] to discuss how Jina AI’s experience can help your business.
For more information about Jina AI’s offerings, check out the Jina AI website or join our community on Discord.









