



Since early 2021, CLIP-style models have been the backbone of multimodal AI. They work by embedding inputs from more than one kind of media into a common high-dimensional vector space, using different models for different modalities. These different models are co-trained with multimodal data. For CLIP-models, this means images with captions.
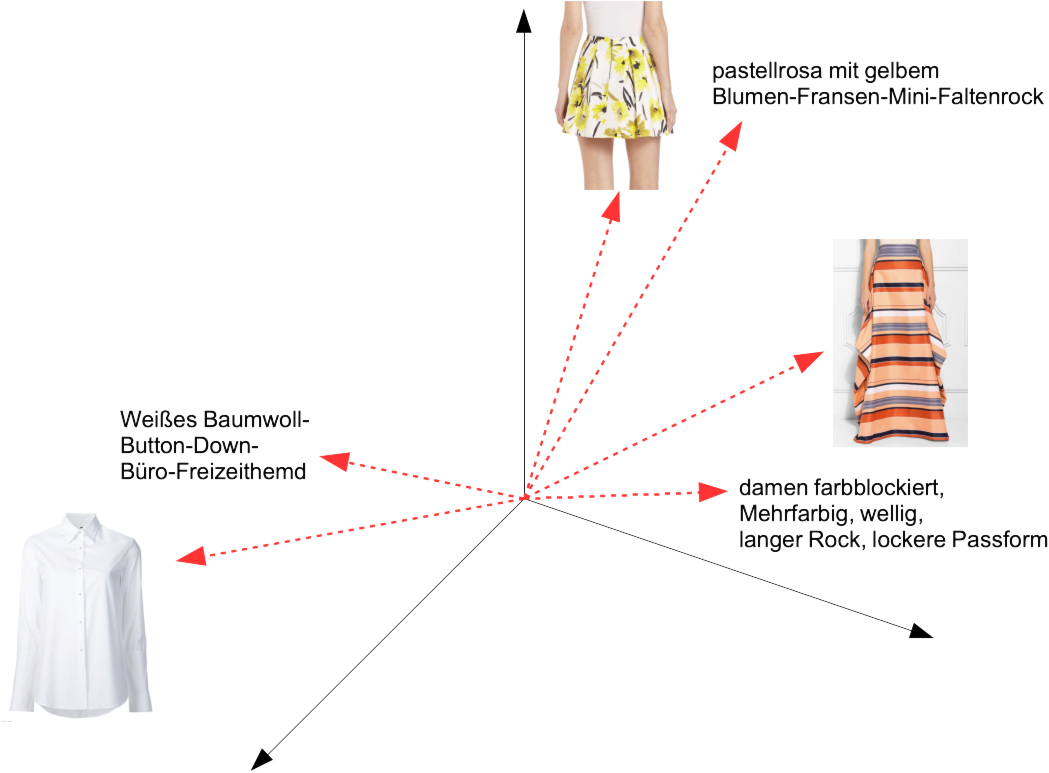
The result? A pair of models that embed images and texts close to each other if the text is descriptive of the image, or the image contains things that match the text. So if we have a picture of a skirt and the word “Rock” (German for “skirt”), they would be close together, while the word “Hemd” (German for “shirt”) would be closer to a picture of a shirt.

tagTowards multilingual CLIP
However, CLIP text models have mostly been trained on English data, and that’s a big problem: The world is full of people who don’t speak English.
Very recently, a few non-English and multilingual CLIP models have appeared, using various sources of training data. In this article, we’ll evaluate a multilingual CLIP model’s performance in a language other than English, and show how you can improve it even further using Jina AI’s Finetuner.
 jina-ai
jina-aiTo make this happen, we’re collaborating with Toloka, a leading provider of data procurement services for machine learning, to create a dataset of images with high-quality German-language descriptions written by humans.

tagHow does multilingual CLIP work?
Multilingual CLIP is any CLIP model trained with more than one language. So that could be English+French, German+English, or even Klingon+Elvish.
We’re going to look at a model that Open AI has trained with a broad multilingual dataset: The xlm-roberta-base-ViT-B-32 CLIP model, which uses the ViT-B/32image encoder, and the XLM-RoBERTa multilingual language model. Both of these are pre-trained:
ViT-B/32, using the ImageNet-21k datasetXLM-RoBERTa, using a multi-terabyte dataset of text from the Common Crawl, containing over 100 languages.
So, from the outset, multilingual CLIP is different because it uses a multilingual text encoder, but can (and generally does) use the same image encoders as monolingual models.
Open AI then co-trained the two encoders with the multilingual laion5b dataset, which contains 5.85 billion image-text pairs: 2.2 billion of these pairs are labelled in 100+ non-English languages, with the rest in English or containing text that can’t be nailed down to any one language (like place names or other proper nouns). These are taken from a sampling of images and their HTML alt-text in the Common Crawl web archive.

This dataset isn’t balanced in the sense that no-one has tried to ensure that data for one language is comparable in size or scope to the data for any other. English still dominates.
tagDeep dive of the tokenizer inside multilingual models
So, how is a multilingual text encoder different from a bog-standard monolingual one? One big difference is how it handles tokenization.
Text transformer models like XLM-RoBERTa all start by tokenizing input texts — breaking them up into smaller parts — and replacing each part with an input vector constructed as part of the initial training. These input vectors are strung together and passed to the model to create an embedding vector.
You might expect these smaller parts to match words, and sometimes they do. But looking for words by just checking for spaces and punctuation doesn’t capture the fact that call, calls, calling, and called are not four totally different words, just like small, smaller, and smallest, or annoy, annoyed, annoyingly. In practice, this entire class of model uses, at least partly, a technique called subword tokenization, which uses the statistical properties of sequences of characters to decide what units are the “right-size” for learning.
It’s not really based in any linguistic theory, but doing it this way has many advantages for machine learning. Think of the suffix -ed in English. You might expect that a “right-sized” statistical tokenizer would notice that many English words end in -ed, and break those words into two parts:
called → call -ed
asked → ask -ed
worked → work -ed
And this makes sense, most of the time. But not always:
weed → we -ed
bed → b -ed
seed → se -ed
Large language models are very robust, and they can learn that “weed” has a meaning different from “we” + “-ed”. Using this kind of tokenization, even new words that were never part of the pre-training data get a distinct representation for the model to learn.
Nonetheless, the more that the tokenization matches meaningful units of language, the faster and better the model learns.
Let’s take a concrete example. The image below is from the data provided by Toloka with the German caption “Leichte Damenjacke Frühling Herbst braun” (”Light women's jacket spring autumn brown”):

If we pass this German phrase to XLM-RoBERTa’s tokenizer, we get a very different result from when we pass it to a comparable tokenizer used for an English-only model:
multilingual-CLIP: leicht|e|Damen|jack|e|Frühling|Herbst|bra|un
english-only-CLIP: le|ich|te|dam|en|jac|ke|fr|ü|h|ling|her|bst|braun
The tokens found by the multilingual tokenizer much more closely match our intuitions about meaningful units in German, while the English-only-trained tokenizer produces almost random chunks. Yes, it is still possible for a large language model to learn from badly tokenized data, if it’s consistent, but it will be slower and/or less accurate.
In contrast, the English equivalent — a word-for-word translation — is clearly better tokenized by the English-only tokenizer, but is not so badly tokenized by the multilingual one:
multilingual-CLIP: light|women|'|s|ja|cket|spring|a|utum|n|brown
english-only-CLIP: light|women|'s|jacket|spring|autumn|brown
Even from the first step in the process of producing text embeddings, we can see that multilingual language models make a large difference in producing multilingual CLIP models.
tagMultilingual vs. monolingual CLIP on the search quality
Large language models are famously good at transfer learning. For example, if a monolingual English-only CLIP model has learned what “jacket” means, you can further train it, with very few additional examples, to know that the German word “Jacke” means the same thing. Then, it can carry all its knowledge about the English word “jacket” over to German.
It is possible that a model already trained on English could be retrained for German with less data than training a new German model from scratch.
Therefore, it’s worth asking: How much do we really gain using a model trained to be multilingual from the outset?
In this article, we will use the German fashion dataset provided by Toloka to:
- Compare the zero-shot performance (i.e. out-of-the-box, without fine-tuning) of the multilingual CLIP model
xlm-roberta-base-ViT-B-32and the English-only equivalentclip-vit-base-patch32. These two use the same image embedding model, but different text embedding models. - Attempt to improve both models by using a part of the German dataset to fine-tune them.
- Compare the fine-tuned models using the same metrics, so we can both contrast non-fine-tuned and fine-tuned models, and contrast the English-only and multilingual models after adaptation to the German data.
- Show how much advantage, if any, is gained from a multilingual CLIP model.
tagExperiment Setup
tagThe German Fashion12k dataset
We have collaborated with Toloka to curate a 12,000 item dataset of fashion images drawn from e-commerce websites, to which human annotators have added descriptive captions in German. Toloka has made the data available to the public on GitHub, but you can also download it from Jina directly in DocArray format by following the instructions in the next section.
The images are a subset of the xthan/fashion-200k dataset, and we have commissioned their human annotations via Toloka’s crowdsourcing platform. Annotations were made in two steps. First, Toloka passed the 12,000 images to annotators in their large international user community, who added descriptive captions.
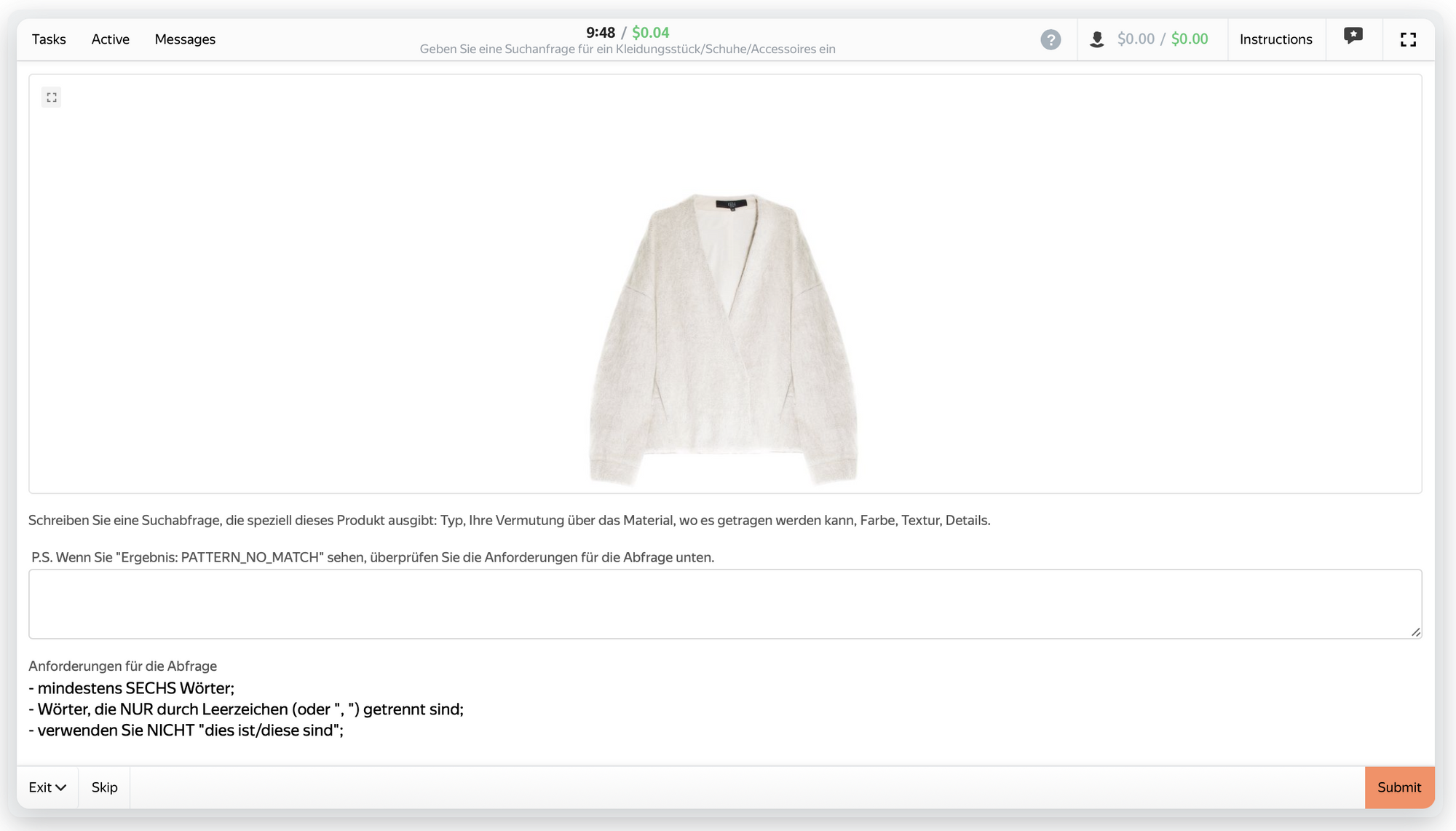
The app prompted users to write descriptions that follow a common pattern, partially enforced by a simple pattern matcher. Specifically:
Write a search query that would find this product: type, your guess about the material, where it might be worn, color, texture, details. […]
Requirements for the query:
· At least SIX words
· Words that are separated ONLY by spaces (or ", ")
· Do NOT use "this is/these are"
Then, in the second stage, other, randomly chosen users validated each description.
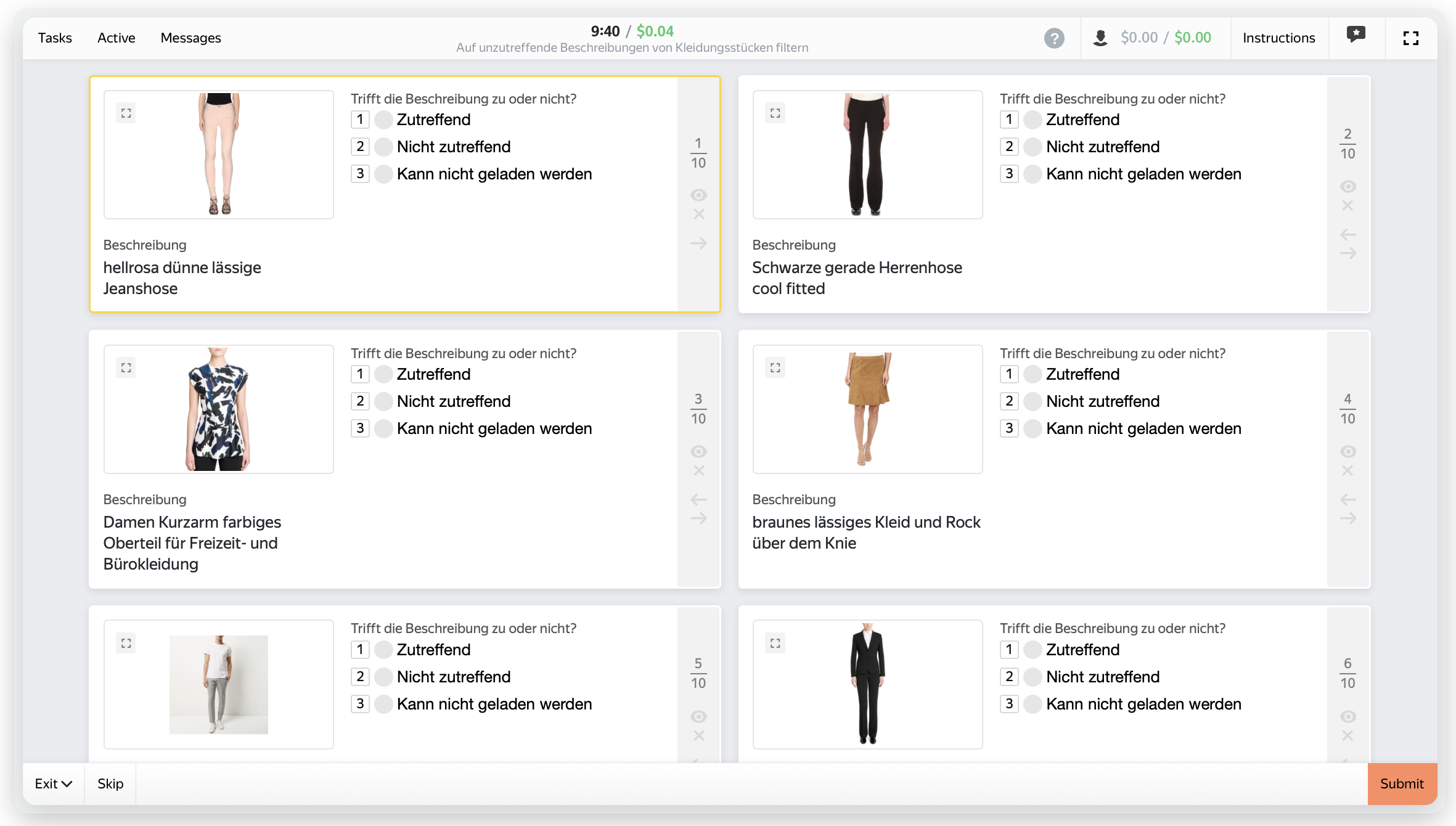
Some examples from the resulting dataset:
 Long winter jacket for women. |
 Large blazer-vest for women |
Of the 12,000 image-text pairs in the data from Toloka, we randomly selected 10,000 for training and held the remaining 2,000 out for evaluation. By coincidence, and because some clothes are similar enough in nature, there are a few duplicate descriptions. However, since there are 11,582 unique descriptions, we didn’t consider this an important factor in using this data.
tagDownload the dataset via DocArray
The German Fashion12k dataset is available for free use by the Jina AI community. After logging into Jina AI Cloud, you can download it directly in DocArray format:
train_data = DocumentArray.pull('DE-Fashion-Image-Text-Multimodal-train', show_progress=True)
eval_data = DocumentArray.pull('DE-Fashion-Image-Text-Multimodal-test', show_progress=True)
tagLoad the multilingual CLIP model
Because CLIP models are actually two different models that have been trained together, we have to load them as two models.
In this article, we will use the Finetuner interface. To use the xlm-roberta-base-ViT-B-32 CLIP model:
from finetuner import build_model
mCLIP_text_model = build_model(
name = 'xlm-roberta-base-ViT-B-32::laion5b_s13b_b90k',
select_model = 'clip-text',
)
mCLIP_vision_model = build_model(
name = 'xlm-roberta-base-ViT-B-32::laion5b_s13b_b90k',
select_model = 'clip-vision'
)
tagLoad the English CLIP model
For comparison, you can access the English-only ViT-B-32::openai CLIP model in the same way:
from finetuner import build_model
enCLIP_text_model = build_model(
name = 'ViT-B-32::openai',
select_model = 'clip-text',
)
enCLIP_vision_model = build_model(
name = 'ViT-B-32::openai',
select_model = 'clip-vision'
)
tagEvaluate the zero-shot performance
We measured the zero-shot performance of both the Multilingual CLIP model and the English-only one on German Fashion dataset, that is to say, how well they perform as downloaded, without additional training, on the 2,000 items we held out for evaluation.
We embed the text descriptions in the evaluation data, and used them to search for matches among the embedded images in the evaluation data, taking the 20 top matches for each text description. We took the results and performed a number of standard statistical tests on them, including Mean Reciprocal Rank (mRR), Mean Average Precision (mAP), Discounted Cumulative Gain (DCG), and the share of queries that return the exact image whose description matches the query (labeled “Hits”).
The performance results are:
| Metric | English CLIP score | Multilingual CLIP score |
|---|---|---|
| mRR | 0.037 | 0.319 |
| mAP | 0.036 | 0.319 |
| DCG | 0.072 | 0.451 |
| Hits | 0.148 | 0.677 |
Not very surprisingly, the English CLIP model performed extremely poorly on German data. Below are three examples from the evaluation set of queries in German, and the images it found to match:
 für Damen mit floralem Gürtel Black sequin midi skirt for women with floral belt |
 gestreifte Hose Green and dark blue striped pants |
 lockeres Hemd mit U-Ausschnitt Dark olive green scoop neck long sleeve loose fit shirt |
Obviously, even though German is a relatively small part of the training set of the multilingual model, that is more than enough to make a ten-fold difference in performance with German queries, improving the value of a CLIP model from basically none to mediocre.
tagImprove the search quality via fine-tuning
One of the main insights of large-model neural-network engineering is that it’s easier to start with models that are trained on general-purpose data and then further train them on domain-specific data, than it is to train models on domain-specific data from scratch. This process is called “fine-tuning” and it can provide very significant performance improvements over using models like CLIP as is.
Fine-tuning can be a tricky process, and gains are highly dependent on the domain and the dataset used for further training.
tagSpecify hyperparameters
Fine-tuning requires a selection of hyperparameters that require some understanding of deep learning processes, and a full discussion of hyperparameter selection is beyond the scope of this article. We used the following values, based on empirical practice working with CLIP models:
| Hyperparameter | Value |
|---|---|
| Learning rate | 1e-6 |
| Training epochs | 5 |
| Loss function | CLIPLoss |
These hyperparameters are part of the command below.
tagSpecify the evaluation data
We fine-tuned using the data split described previously: 10,000 items were used as training data, and 2,000 as evaluation data. In order to evaluate models at the end of each training epoch, we turned the evaluation data into a “query” and “index” dataset. The “query” data consists of the German text descriptions in the evaluation data, and the “index” data contains the images.
for doc in eval_data:
tag = doc.chunks[1].text
doc.chunks[0].tags['finetuner_label'] = tag
doc.chunks[1].tags['finetuner_label'] = tag
query_data = DocumentArray([doc.chunks[0] for doc in eval_data])
index_data = DocumentArray([doc.chunks[1] for doc in eval_data])
These are also passed to the fine-tuning command.
tagPut everything together in one call
Running the command below uploads the training and evaluation data and fine-tunes the xlm-roberta-base-ViT-B-32 model on Jina AI Cloud:
import finetuner
run = finetuner.fit(
model='xlm-roberta-base-ViT-B-32::laion5b_s13b_b90k',
train_data=toloka_train_data,
eval_data=toloka_eval_data,
epochs=5,
learning_rate=1e-6,
loss='CLIPLoss',
device='cuda',
callbacks=[
EvaluationCallback(
query_data=toloka_query_data,
index_data=toloka_index_data,
model='clip-text',
index_model='clip-vision'
),
WandBLogger(),
]
)
The fine-tuning process may take a considerable length of time, depending on the model and the amount of data. For this dataset and models, it took roughly half an hour. But once fine-tuning is complete, we can compare the different models' performance at querying.
tagQualitative study on fine-tuned models
For example, here are the top four results for the query “Spitzen-Midirock Teilfutter Schwarz” (”Lace midi skirt partial lining black”):
 |
 |
This kind of qualitative analysis gives us a sense for how fine-tuning improves the model’s performance. Before tuning, the model was able to return images of skirts that matched the description, but it also returned images of different items of clothing made of the same materials. It was insufficiently attentive to the most important part of the query.
After fine-tuning, this query consistently returns skirts, and all four results match the description. That is not to say that every query returns only correct matches, but that on direct inspection we can see that it has a far better understanding of what the query is asking for.
tagQuantitative study on fine-tuned models
To make more concrete comparisons, we need to evaluate our models in a more formal way over a collection of test items. We did this by a passing it test queries drawn from the evaluation data. The model then returned a set of results on which we did the same standard statistical tests we did for zero-shot evaluation.
Here are the results for the Multilingual CLIP model, using the same measure of the top 20 results of each query:
| Metric | Zero-shot Multilingual CLIP score |
Fine-tuned Multilingual CLIP score |
|---|---|---|
| mRR | 0.319 | 0.418 |
| mAP | 0.319 | 0.417 |
| DCG | 0.451 | 0.569 |
| Hits | 0.677 | 0.775 |
The results show that fine-tuning has a significant effect in improving results for Multilingual CLIP, although not a spectacular one.
tagCan English CLIP benefit from German data?
We also decided to check if the English-only CLIP model would get better if we fine-tuned it with German data. It might catch up in performance with a pre-trained multilingual model, if given a chance. The results were interesting. We include the Multilingual CLIP results in this table for comparison:
| Metric | Zero-shot English CLIP score |
Fine-tuned English CLIP score |
Zero-shot Multilingual CLIP score |
Fine-tuned Multilingual CLIP score |
|---|---|---|---|---|
| mRR | 0.037 | 0.190 | 0.319 | 0.418 |
| mAP | 0.036 | 0.190 | 0.319 | 0.417 |
| DCG | 0.072 | 0.315 | 0.451 | 0.569 |
| Hits | 0.148 | 0.554 | 0.677 | 0.775 |
Using German training data, we were able to bring a vast improvement to the English-only CLIP model, although not enough to bring it up to even with the zero-shot level of the Multilingual CLIP model. Mean average precision for the English-only model jumped 420%, compared to 31% for Multilingual CLIP, although the overall performance of the monolingual model was still much worse.
tagDoes more labeled data improve the search quality?
We also ran multiple fine-tuning experiments with differing amounts of training data, on both the Multilingual and English-only CLIP models, to see how effective using more data was.

In both, we see that most of the gain comes from the first few thousand items of training data, with gain coming more slowly after initially fast learning. This confirms a conclusion Jina AI has already published.
Adding additional data may still improve results, but much more slowly. And in the case of fine-tuning the English-only CLIP model to handle German queries, we see performance improvement maximizes at less than 10,000 new items of data. It seems unlikely that we could train the English-only CLIP model to ever equal the Multilingual CLIP on German data, at least not using these kinds of methods.
tagConclusion
What lessons can we take from all this?
tagMultilingual CLIP is the first choice for non-English queries
The Multilingual CLIP model, trained from scratch with multilingual data, outperforms comparable English-only CLIP models by a very large margin on the German data we used. The same conclusion will likely apply for other non-English languages.
Even in an unfair competition, where we fine-tuned the English model and vastly improved its performance on German data, the Multilingual CLIP model without further training outperformed it by a large margin.
tagFine-tuning improves search quality with little data
We were shocked to see the English-only model improve its handling of German so much, and we see that we could have gotten nearly the same result using half as much data. The basic assumptions that go into fine-tuning are clearly very robust if they can teach German to an English model with only a few thousand examples.
On the other hand, we struggled to improve the performance of Multilingual CLIP, even with a fairly large quantity of high quality human-annotated training data. Although Finetuner makes a clear difference, you very rapidly reach upper bounds of how much you can improve a model that’s already pretty good.

tagTrouble-free fine-tuning using Finetuner
Finetuner is easy enough to use that we could construct and perform all the experiments in this article in a few days. Although it does take some understanding of deep learning to make the best configuration choices, Finetuner greatly reduces the boring labor of running and paying attention to large-scale neural network models to mere parameter setting.








