

Thanks to recent advances in deep neural networks, multimodal technologies have made possible advanced, intelligent processing of all kinds of unstructured data, including images, audio, video, PDFs, and 3D meshes. Multimodal deep learning allows for a more holistic understanding of data, as well as increased accuracy and efficiency.
Jina AI is the most advanced MLOps platform for building multimodal AI applications in the cloud. Users can translate their data and a few lines of code into a production-ready service without dealing with infrastructure complexity or scaling hassles.
But first, what is multimodal deep learning? And what are its applications?
tagWhat does "modal" mean?
The term “modal” is a reference to the human senses: sight, hearing, touch, taste, smell. We use it here to mean data modality. You can think of it as indicating the kind of data you're working with, like text, image, video, etc.
Sometimes people use the terms “multimodal” and “unstructured data” interchangeably because both terms describe data that lacks a meaningful internal structure. Multimodal data is data that uses multiple modalities, while unstructured data is a catch-all term that describes any type of data that doesn't have a readily machine-readable structure.
tagReal-world data is multimodal
In the early days of AI, research typically focused on one modality at a time. Some works dealt with written language, others with images, or speech. As a result, AI applications were almost always limited to a specific modality: A spam filter works with text. A photo classifier handles images. A speech recognizer deals with audio.
But real-world data is often multimodal. Video is usually accompanied by an audio track and may even have text subtitles. Social media posts, news articles, and any internet-published content routinely mix text with images, videos, and audio recordings. The need to manage and process this data is one factor motivating the development of multimodal AI.
tagMultimodal vs cross-modal
"Multimodal" and "cross-modal" are another two terms that are often confused for each other, but don't mean the same thing:
Multimodal deep learning is a relatively new field that is concerned with algorithms that learn from data of multiple modalities. For example, a human can use both sight and hearing to identify a person or object, and multimodal deep learning is concerned with developing similar abilities for computers.
Cross-modal deep learning is an approach to multimodal deep learning where information from one modality is used to improve performance in another. For example, if you see a picture of a bird, you might be able to identify it by its song when you hear it.
AI systems that are designed to work with multiple modalities are said to be “multimodal”. The term “cross-modality” is more accurate when referring narrowly to AI systems that integrate different modalities and use them together.
tagMultimodal deep learning applications
Multimodal deep learning has a broad array of potential uses. Among the applications already available:
- Automatically generating descriptions of images, like captioning for blind people.
- Searching for images that match text queries (e.g. “find me a picture of a blue dog”).
- Generative art system that create images from text descriptions (e.g. “make a picture of a blue dog”).
All these applications rely on two pillar technologies: search and creation.
tagNeural search
The core idea behind neural search is to leverage state-of-the-art neural network models to build every component of a search system. In short, neural search is deep neural network-powered information retrieval.
Below is an example of an embedding space generated by DocArray and used for content-based image retrieval.

Similar images are mapped together in the embedding space, and this property of the embedding space is what makes it useful for search applications. Searching for images that are most similar to some picture amounts to finding the closest images in this space, which you can easily do via the DocArray API:
db = ... # a DocumentArray of indexed images
queries = ... # a DocumentArray of query images
db.find(queries, limit=9)
for d in db:
for m in d.matches:
print(d.uri, m.uri, m.scores['cosine'].value)Neural search excels with multimodal data, because it can learn to map multiple modalities – for example, text and images – to the same embedding space. This enables neural search engines to search images using text queries and to search text documents using image queries.
Search without a search box
Mapping indexed items and queries of different modalities to a common embedding space opens up new application possibilities, including alternatives to the traditional search box. For example:
- A question-answering chatbot that maps user inquiries to the same embedding space as an FAQ, guidebook, or pre-existing written answers.
- Smart devices that use speech recognition and map user statements to available commands.
- Recommendation systems that look for nearest neighbors in an embedding space to directly identify items similar to the product a user has selected.
tagGenerative AI
Generative AI (sometimes called creative AI) uses neural network models to generate new content, such as images, videos, or texts. For example, OpenAI's GPT-3 can write new texts from a prompt. The system is trained on a large corpus of books, articles, and websites. Given a prompt, it constructs a text that seems most naturally to follow it based on the texts it's learned from before. People are using it to write stories and poems, and as generative prompts for their own work.
OpenAI’s DALL·E creates novel images from textual prompts. Below is an example of DALL·E creating images from the text prompt "an oil painting of a humanoid robot playing chess in the style of Matisse". This code specifically accesses DALL·E Flow, a complete text-to-image system built on top of Jina and hosted on Jina AI Cloud.
server_url = 'grpc://dalle-flow.jina.ai:51005'
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'
from docarray import Document
doc = Document(text=prompt).post(server_url, parameters={'num_images': 8})
da = doc.matches
da.plot_image_sprites(fig_size=(10, 10), show_index=True)
Generative AI has a great deal of potential. It may revolutionize how we interact with machines by creating:
- More personalized experiences during computer-human interaction.
- Realistic 3D images and videos of people and objects, which can be used in movies, video games, and other visual media.
- Natural-sounding dialogue for video games or other interactive media.
- New designs for products, which can be used in manufacturing and other industries.
- New and innovative marketing materials.
tagMultimodal relationships
The way multimodal deep learning connects information in different modalities is equally central to generative AI and to neural search.
Let’s see the following illustration, where we represent the cat dog human ape texts and images into one embedding space:
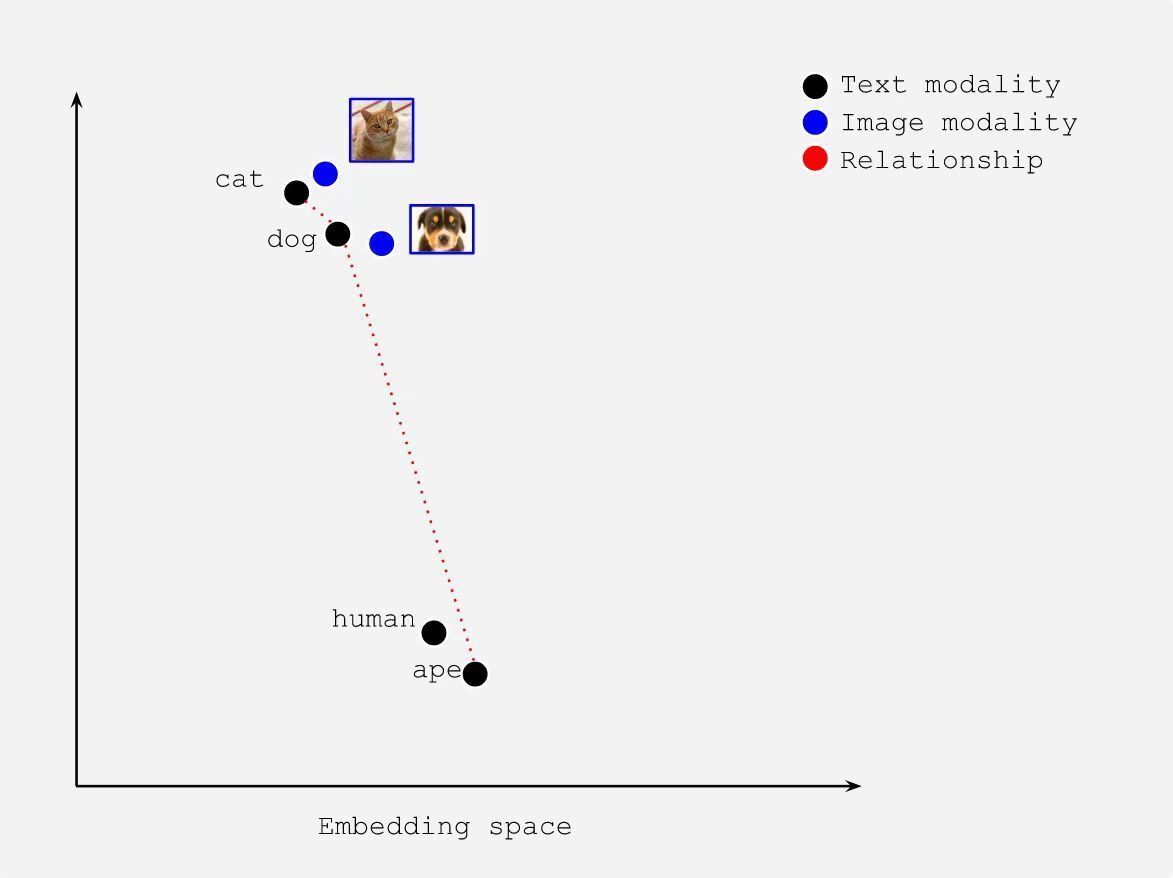
The placement of these items in a single embedding space encodes relational information about their referents:
- The text embedding of
catis closer todog(same modality); - The text embedding of
humanis closer toape(same modality); - The text embedding of
catis farther fromhuman(same modality); - The text embedding of
catis closer to the image embedding ofcat(different modalities); - The image embedding of
catis closer to the image embedding ofdog(same modalities); - etc.
It's clear how this information is used in information retrieval, but generative AI also uses the same information. Instead of looking for nearest neighbors among a set of stored text or images, it constructs a text or image that has an embedding close to the prompt.
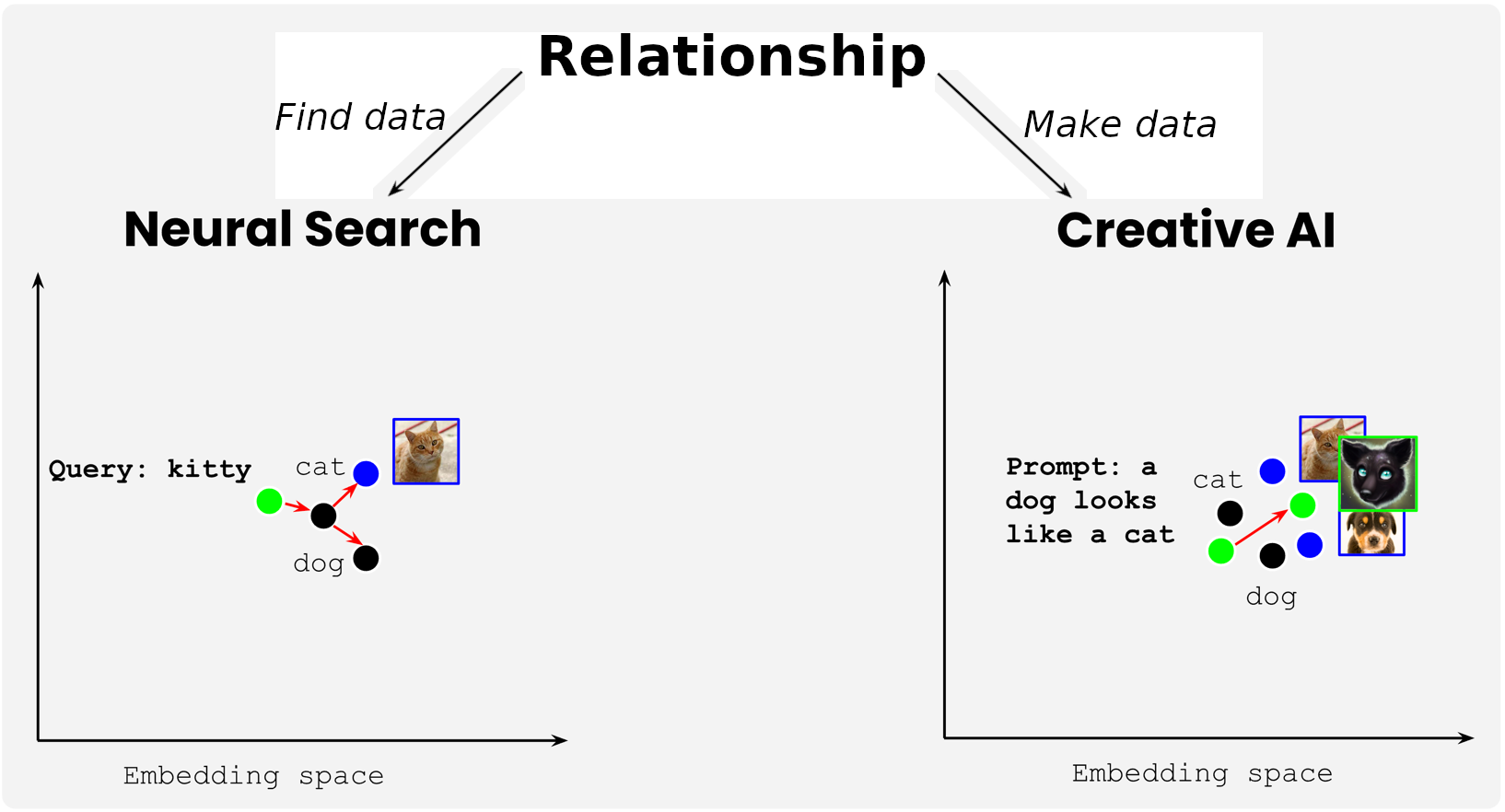
In summary, the key to multimodal deep learning is understanding the way it relates different modalities. With this relationship in place, you can use it to search for existing data – i.e. neural search – or use it to make new data, which is generative AI. To learn more about multimodal deep learning, read the post below:






