



In today's rapidly evolving business landscape, enterprises face many challenges. From managing large volumes of unstructured data to delivering personalized customer experiences, businesses need advanced solutions to stay ahead of the curve. Machine learning (ML) has emerged as a powerful tool for addressing these challenges by automating repetitive tasks, processing data efficiently, and generating insights from multimedia content.
However, implementing ML solutions has traditionally been plagued by roadblocks such as costly and time-consuming MLOps steps and the need to distinguish between public and custom neural network models. This is where Jina AI's Inference steps in, offering a comprehensive solution to streamline access to curated, state-of-the-art ML models.

tagWhat is Inference?
Inference is a secure, scalable cloud platform that allows enterprises to harness the power of highly curated ML models without the complexities of traditional ML implementation. Jina AI's team of experts researches and selects the best models for various tasks, including text embedding, image embedding, image captioning, super-resolution, visual reasoning, visual question answering, and neural search, ensuring top performance and cost-efficiency for your business needs.
The upcoming release of Inference will also include support for text generation, further expanding its capabilities.
In this article, we're going to work through the technical and academic innovations that our team has leveraged to be able to provide models-as-a-service, which is at least as performant, and most cases more, in terms of queries-per-second, while being significantly more affordable compared to alternatives on the market.
tagThe Art of Model Curation
Jina AI's model curation process involves an in-depth evaluation and comparison of state-of-the-art models, drafting efficient architectures for splitting and hosting models to achieve fast and cost-effective inference, and validating performance and reliability before making them available to the public. By entrusting us with the curation process, businesses can focus on leveraging these robust ML solutions to enhance identified tasks to be automated using machine learning.
tagThe Science of Model Deployment
Jina Executors encapsulate specific functionalities and enable the construction of scalable and efficient inference systems. They are responsible for performing specific tasks within the pipeline, called a Jina Flow.
Generally, the following is the way to wrap a model using a Jina Executor:
from jina import Executor, requests
class MyModelExecutor(Executor):
def __init__(self):
super().__init__()
# Initialize your model here
@requests
def encode(self, *args, **kwargs):
# Implement your model's encoding logic here
# Use `self.model` to access your model
# Process inputs and generate outputs
outputs = ...
return outputs tagMemory Limits
Usually, calling init() will load the whole model into memory. However, dealing with large models, such as generative models, can consume excessive resources. This poses a challenge, particularly when using consumer-grade GPUs with limited VRAM capacity.
For example, BLIP2 (blip2-flan-t5-xl) takes more than 15GB just to load the model into memory. For some consumer-grade GPUs, such as the RTX 3080, that's all the VRAM they have. The risk of out-of-memory errors is very high when performing inference.

A possible compromise is half-precision, i.e., using 16-bit floating point number representation instead of 32-bit. However, this can severely impair the performance of the model.
Below are two examples comparing image-captioning performance with 16-bit (left column) and 32-bit (right column) versions of BLIP2:

The qualitative difference should be quite clear: Using the bigger model results in more accurate and concise captions.
tagSplitting Models across Executors
A practical solution to overcome resource limitations is to split the model into different parts. For instance, the BLIP2 model consists of an image encoder, a query former, and a language model decoder, each of which could, in principle, have its own Executor.
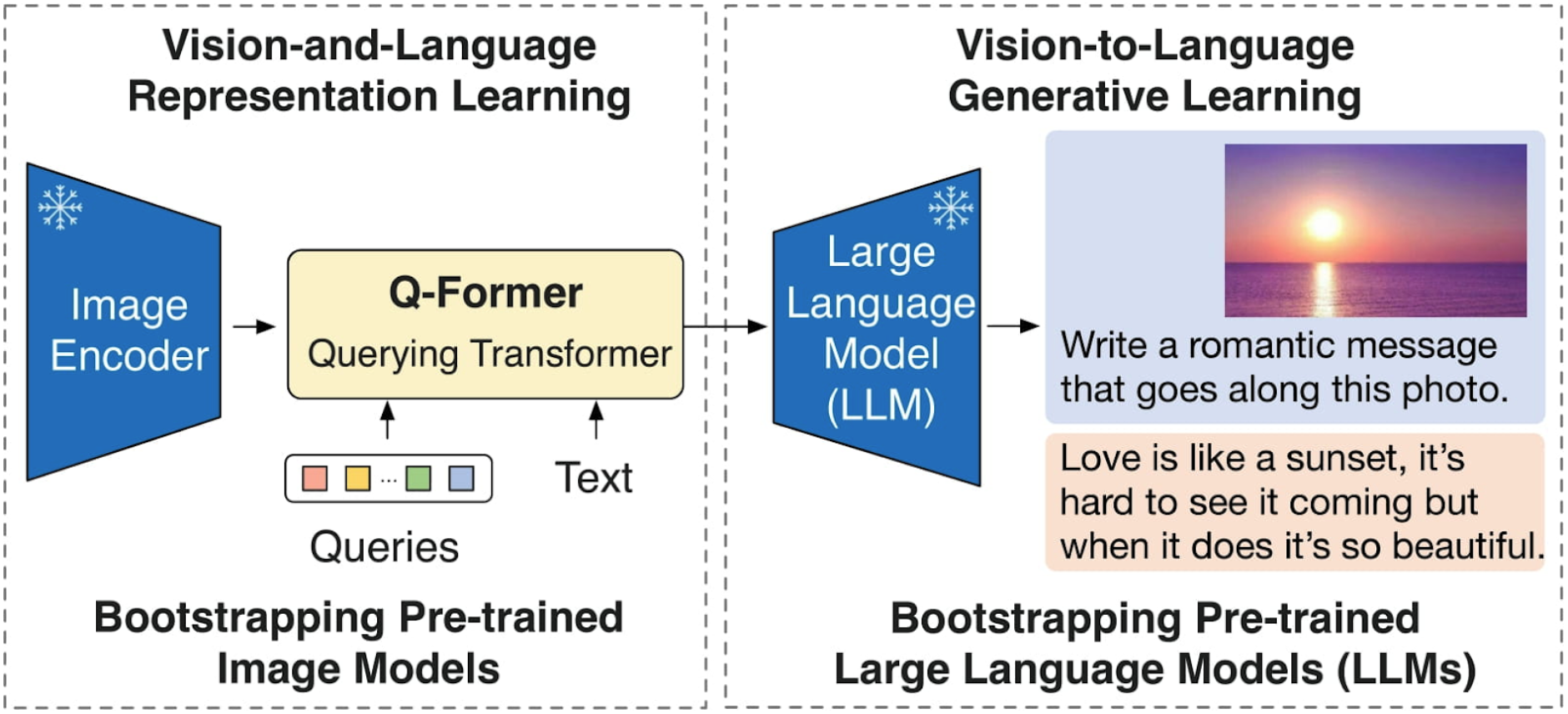
With BLIP2, we can intuitively split the model into two Executors. Call them QFormerEncoder and LMDecoder.
QFormerEncoder (the image encoder plus the query former) extracts image features, while LMDecoder (the language model decoder) generates the output based on image features and a text prompt if one is provided. There is no coupling between these two Executors, so we can load and run them entirely asynchronously from each other.
Splitting models into multiple Executors addresses resource constraints and improves scalability. In the case of QFormerEncoder and LMDecoder, their processing times can differ significantly, so there is less idle runtime if they are disconnected from each other. By adjusting replica counts, we can achieve a high level of workload balance. For example, if the QFormerEncoder can process 12 documents per second, while the LMDecoder can only process 6, setting the replica count of LMDecoder to 2 for every replica of QFormerEncoder will ensure balanced processing and guarantee a processing speed of 12 queries per second for each QFormerEncoder.
tagInference vs. The Rest
Jina AI stands out from other machine learning models-as-a-service providers in terms of cost-effectiveness, comprehensive enterprise support, and model curation. By choosing Inference from Jina AI, your business gains access to the best ML solutions without breaking the bank.
For comparison, consider the following table:
| Provider | Models | Performance | Cost / API call |
|---|---|---|---|
| Cohere | Curated models for - Embedding, Generation, and Classification | No information available publicly | ~ US$ 0.002 |
| Replicate | Non-curated list of models for - Embedding, Generation, Classification, Captioning … | 2 seconds per image caption with BLIP2 | ~ US$ 0.005 |
| Jina AI | Curated models for - Embedding, Captioning, Reasoning, Upscaling, (Generation) | 0.5 seconds per image caption with BLIP2 | US$ 0.0001 |
tagGet Started with Inference Today
In this article, we learned how businesses can benefit from using models-as-a-service, such as Jina AI's Inference, to automate repetitive tasks with machine learning and accelerate their growth. Jina's technological innovations make it possible to offer this service for a highly competitive price, especially for bulk commercial use cases.
Beginning your AI journey with Inference is simple, thanks to its easy integration, comprehensive documentation, and dedicated support team. Unlock the power of AI to enhance your business operations and stay ahead of the competition by signing up for Inference on Jina AI Cloud.
tagGet in Touch
Talk to us and keep the conversation going by joining the Jina AI Discord!








