


Text embeddings are the backbone of AI language processing, powering text clustering, information retrieval, sentiment analysis, text-to-image processing, and information extraction, among other core tasks. But there’s a catch: Until now, text embedding models have been trained for very short text segments, typically a few hundred tokens at most. Jina Embeddings 1 models, based on the T5 models, are limited to 512 tokens. Tokens don’t quite match up to words one-to-one, but this means the largest texts that they can support are just a few short paragraphs.
But not anymore!
With Jina Embeddings 2 models, you can get high-quality embeddings from an open-source, Apache 2-licensed model with an input size of 8,192 tokens — more than sixteen times as much as Jina Embeddings 1 and the widely used SBERT models!
Read the Jina Embeddings 2 paper on arXiv
Few other embedding models offer input sizes exceeding 512 tokens, and at present, the only one that accepts over 8,000 tokens is neither open-source nor available for download. Jina Embeddings 2 models not only give you a larger input size than all other open-source models, but they also rival the performance of the closed-source alternative.
Check for yourself on the HuggingFace MTEB leaderboard.

tagHow Jina Embeddings 2 Supports Long Documents
Jina AI has implemented the ALiBi approach, the first embedding model to do so. ALiBi is an alternative to the positional encoding system first proposed in the famous “Attention is all you need” paper. This scheme makes it possible to train embedding models on short texts and still get high-quality results on longer texts.
For Jina Embeddings 2, Jina AI has taken the BERT architecture and grafted it into ALiBi.
ALiBi was originally proposed for text generators (like ChatGPT) that only care about dependencies on previous words. This means that the last tokens in the input matter more than earlier ones because a text generator’s task is to produce the next word after the input. This makes no sense for an embedding model that tries to create a representation of the whole text input, so Jina Embeddings 2 models implement a bi-directional version of ALiBi.
This architectural change, however, means that we can’t use the pre-training of the original BERT model and have to completely retrain the model from scratch.
tagEnglish-Only for Now, German and Chinese Soon
Although there are plenty of multilingual text embedding models out there, there are known issues with providing universal language support. Not all languages are equal when it comes to embedding quality, and recent research shows that models tend to be biased towards structures that parallel English ones, distorting embeddings.
In short, multilingual models have an “accent”, usually an English one due to the majority of English data in the training.
For superior language-specific performance, and more compact, easier-to-train models, Jina Embeddings are currently English-only. We’re planning German and Chinese models for the near future.
tagTraining Jina Embeddings 2 for Top Performance up to 8,192 Tokens
Using ALiBi means that even though Jina Embeddings 2 models support larger input sizes, the models don’t have to be trained with larger input data. The training learned for short sequences scales up to larger ones automatically.
Our training is similar to the way other embedding models are trained. We start with masked word pre-training using the circa 170 billion word English-only C4 dataset. Then, we do pairwise contrastive training. This means taking pairs of texts that are known to be similar or dissimilar and adjusting the weights of the embedding model so that similar inputs are closer together, and dissimilar ones are farther apart. We used a new corpus of text pairs, curated by Jina AI, based on the one used to train the Jina Embeddings 1 models.
Finally, we fine-tuned the model using text triplets and negative mining, with an in-house training dataset specially augmented with sentences of opposite grammatical polarity. Embedding models have typically had trouble with negative polarity sentences: A sentence like “The dog is in the car” will often have an embedding close to “The dog is outside the car,” even though these are naturally opposite in meaning.
We added a collection of positive and negative pairs like this to the training data, using the same methods employed for the Jina Embeddings 1 models to specifically improve performance on this kind of language.
tagThree Models To Better Fit Your Use Case
The Jina Embeddings 2 models come in three sizes, providing high-quality embeddings for users with different requirements and capabilities. All three support 8,192 input tokens.
jina-embeddings-v2-small-en: 33 million parameters, 512-dimension embeddings.- jina-embeddings-v2-base-en: 137 million parameters, 768-dimension embeddings.
jina-embeddings-v2-large-en: 435 million parameters, 1,024-dimension embeddings.
The jina-embeddings-v2-large-en model is not yet available to download but will be released in the immediate future.
tagBigger Inputs, Leaner Models, Peak Performance
We tested the Jina Embeddings 2 models against the MTEB benchmark suite and at the time of writing:
- jina-embeddings-v2-base-en scores roughly on par with the best models on most benchmarks, and generally better than similarly sized ones.
jina-embeddings-v2-small-enranks near the top for models with sizes under 100MB.
The jina-embeddings-v2-large-en model is not yet available for testing.
However, among models that take more than 512 tokens in input, there is only one that compares to the Jina Embeddings 2 models: OpenAI’s text-embedding-ada-002. This model is not publicly available and can only be accessed via a paid web-based API. Its size is unknown.
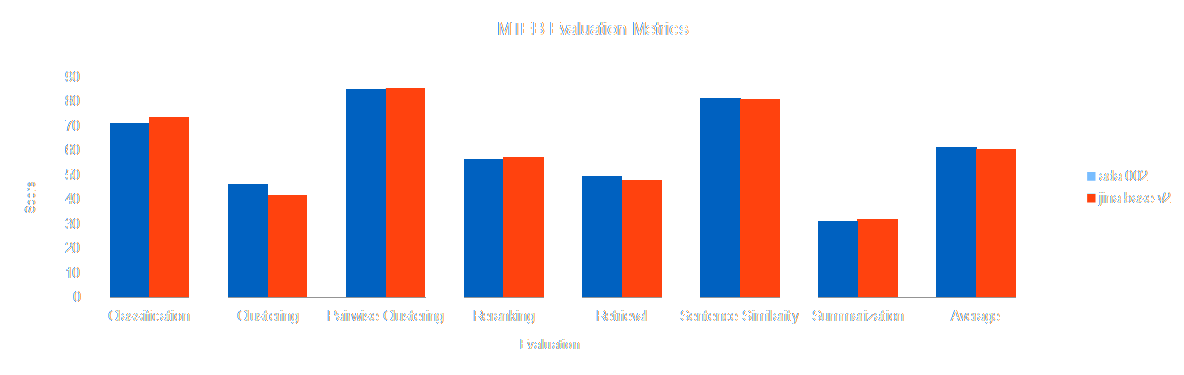
jina-embeddings-v2-base-en is comparable in performance with text-embedding-ada-002 on all benchmarks and even exceeds it in several tasks. Furthermore, the Jina Embeddings 2 models all produce smaller embedding vectors than text-embedding-ada-002 which produces 1,536-dimensional output, compared to 512, 768, and 1,024 dimensions for our three model sizes respectively. This means considerable savings in computing time and memory for applications. Storing shorter vectors takes less space in memory and storage, speeds up database retrieval, and calculating the distance between them is proportionately fast.
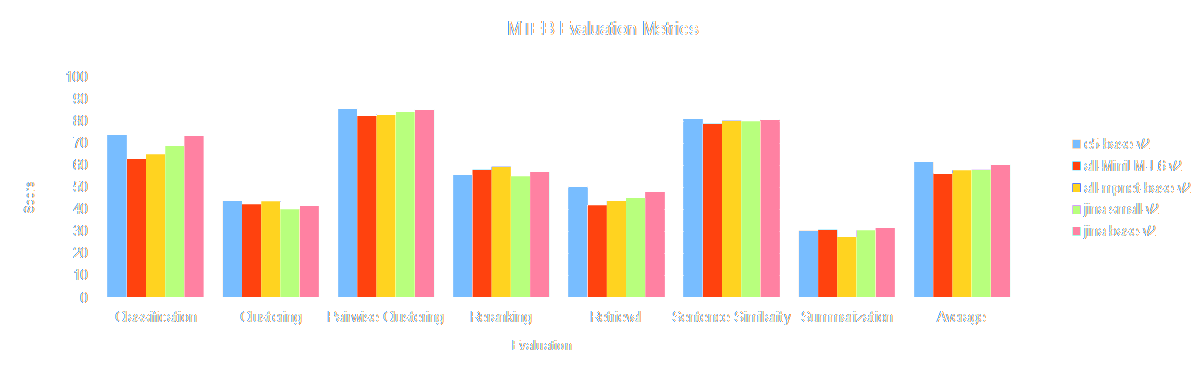
Jina AI’s base and small model compared to other leading embedding models
Furthermore, jina-embeddings-v2-small-en is the only model under 100MB that supports more than 512 input tokens.
Even if we set aside support for larger inputs, Jina Embeddings offers performance on par with the most common embedding foundation models, while remaining roughly the same size or even significantly smaller.
This gives Jina Embeddings 2 models an impressive advantage in terms of accessibility, economic use of computing power, and cost to users.
tagIntegration
Jina Embeddings 2 models are already integrated into:
More integrations are coming soon, both from Jina AI and our open-source user community.
tagTry It Out Yourself Right Now
Go to https://jina.ai/#enterprises to get an access key for Jina AI's online Embedding API with ten thousand free tokens for you to embed. You'll find the key on the upper right:
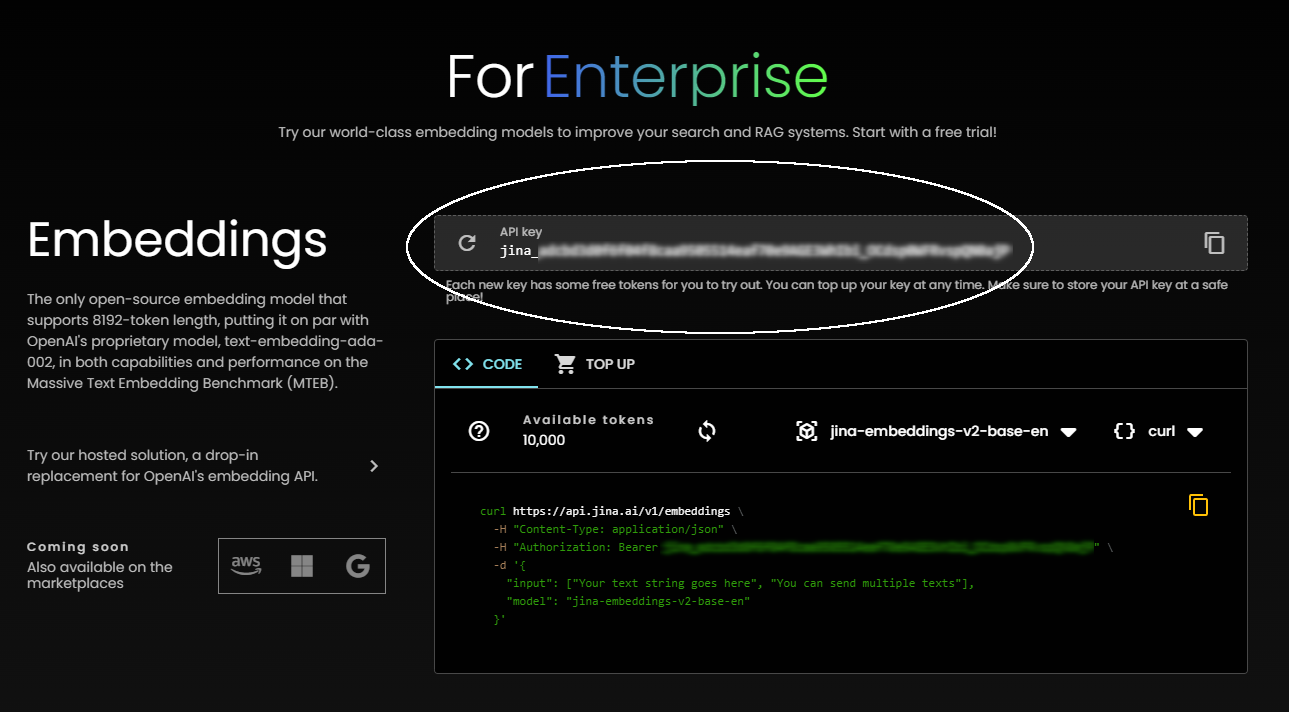
You can access Jina Embeddings 2 models hosted at Jina AI via any standard HTTP interface. Use the drop-down menus to select between the jina-embeddings-v2-base-en and jina-embeddings-v2-small-en models, and to get code snippets to use the Embeddings API.
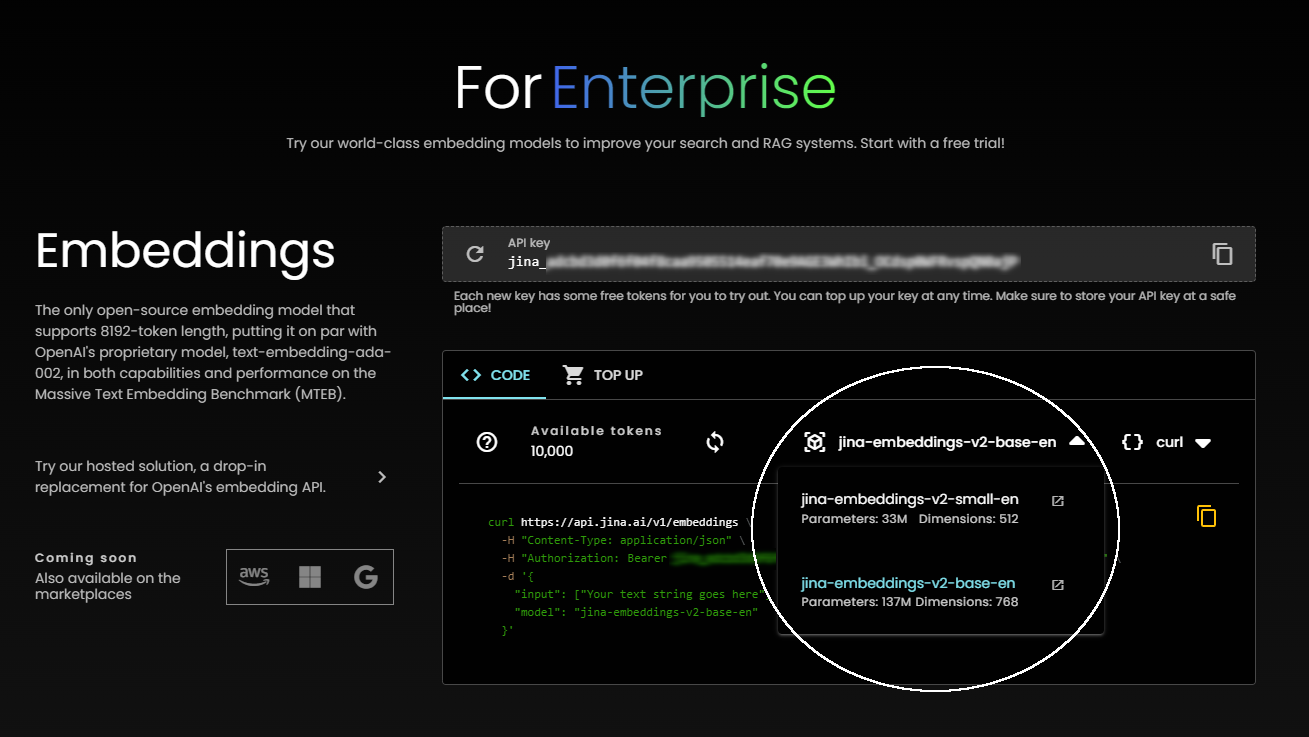
You can also get example code snippets in a variety of languages and frameworks to help integrate Jina Embeddings directly into your project:
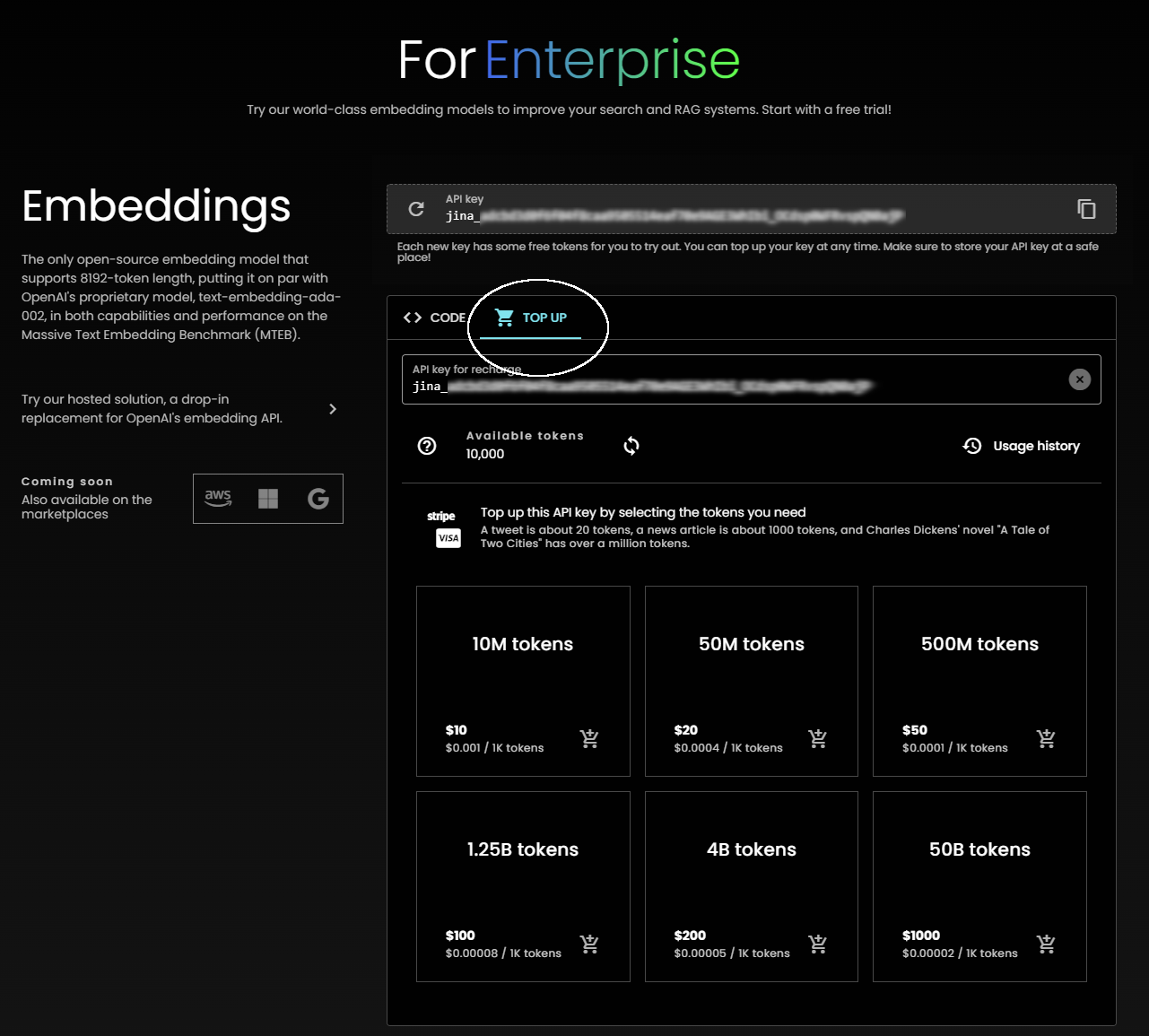
And if you need to add tokens to your API key, just click the "Top Up" tab.
tagFuture Jina Embeddings Models
Jina AI will be rolling out a larger model, jina-embeddings-v2-large-en, in the immediate future, which we expect to exceed the performance of the other Jina Embeddings 2 models and compete with the highest-scoring large embedding models.
In the near future, we are expanding our offerings to include German and Chinese embedding models, which we expect will match or exceed state-of-the-art performance in both languages.
These benchmark results prove the robustness of Jina AI’s contrastive training methodology, and we are always investigating improved model design and AI techniques. Our mission is to put more intelligence and higher performance into more compact open-access models that you can affordably access via our API, or easily run on your hardware and in your cloud instances.






