


Is it a bird? Is it a plane? Is it a dense residential area? Or maybe even a chaparral? Worry not readers. SceneXplain is here to let you know. We don't even have to jump into a phone booth to change first.
You'll see why this is relevant later.
In this blog post, we'll talk about our experiments using SceneXplain to look at satellite imagery and classify it based on what the land is used for. We'll go through three different datasets and explain how we did what we did.
tagWhat is land use classification and what is it used for?
Using satellite data for classifying land use involves working out what a section of the Earth is used for, such as agriculture, city, forest, or body of water. The focus here is on using optical satellite imagery as the data source, which is then analyzed through AI image models to determine the land use. It's often used for:
- Resource Management: Knowing how land is being used aids in allocating and managing resources, such as water for irrigation.
- Urban Planning: Good land use maps are invaluable to city planners so that they can know what types of land use exist in and around urban areas to make informed decisions on infrastructure development.
- Environmental Protection: By identifying sensitive or critical ecological zones, conservationists can better protect and manage them.
- Disaster Management: Land use classification can help to identify vulnerable areas that require priority during emergencies.
- Climate Change Studies: Monitoring land use over time can offer insights into climate change impacts, such as the rate of deforestation.
- Research and Education: Scientists and educators across disciplines use this data for various kinds of research, from ecology to social sciences.
tagUp, up, and away! How we classify land usage in SceneXplain
tagDatasets
We used three datasets for our testing:
- UC Merced land use classification
- AID (Aerial Image Dataset)
- RESISC45 (Remote Sensing Image Scene Classification)
Each of these consists of satellite and aerial images of different sections of Earth, labeled by what they are used for, e.g. dense_residential, round_farm, intersection, etc.



airport from AID dataset, denseresidential from UC Merced dataset, chaparral from RESISC45 dataset
tagSceneXplain
We used SceneXplain's "Extract JSON from image" feature with the Flash algorithm to extract one label per input image. After testing with several algorithms, we saw the Flash algorithm offered the fastest performance, and precision on par with more recent algorithms like Jelly.
Rather than manually uploading each image via the web UI, we used SceneXplain's API to upload and analyze images one at a time.
cid feature when batching and giving each image a unique ID. The ID would contain the image's "official" category, so (after processing) we could extract that and compare it to the category assigned by SceneXplain.tagJSON Schema
Why even use a JSON schema? Why not just let SceneXplain interpret the images directly? Say, by looking at an aerial view of a baseball diamond from the UC Merced dataset?
Here's why:

It’s a clear description, but nowhere does it mention baseballdiamond, which (since we’re doing classification) is the label we want.
We could also try asking it a question using visual question answering (VQA):
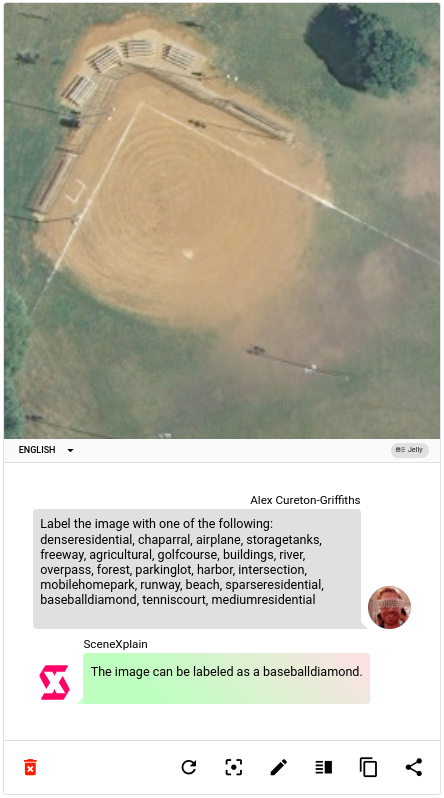
That answer is slightly better, but still throws in a lot more superfluous words. If we were to bulk classify images using this method we would have to search each answer for the category label, since there would be no consistent wording between them. And what would happen if an image were ambiguous and SceneXplain tried to assign it two categories or more?
For this reason, we used SceneXplain’s “Extract JSON from image” feature, where we specify a JSON Schema and can thus get highly structured, standardized output:
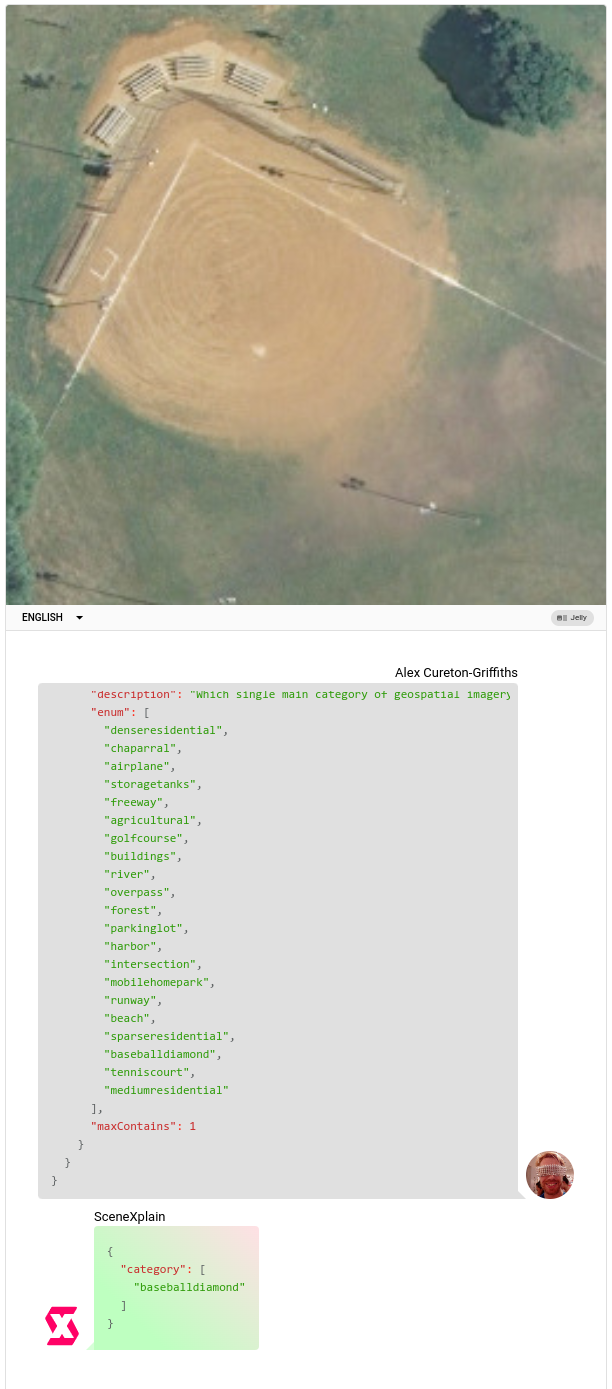
We used the following JSON schema:
{
"type": "object",
"properties": {
"category": {
"type": "array",
"description": "Which single main category of geospatial imagery does this image belong to?",
"enum": [<categories from dataset>],
"maxContains": 1
}
}
}
Since each dataset has different (albeit similar) categories, we generated the list dynamically for each dataset.
tagDoes it work?
Sometimes! Like at least 60% of the time! In some randomized tests we got close to 80% (or occasionally as low as 50%).
Several factors can cause it to fail:
- Some categories can look very similar, e.g.
sparse_residential,medium_residential,dense_residential. SceneXplain often picks the wrong one. This can also be seen in cases likeroadvsrunway. - Occasionally it hallucinates a new category not specified in the
enum, for exampleresidential(as opposed todenseresidential). Occasionally it glitches and assigns a category likeA. - Some category names like
chaparralare uncommon words and/or concepts. It seems unlikely that many pictures of (or references to) chaparrals are in its training datasets. With so little data, the model barely knows what a chaparral is or what it looks like. (Before reading this post, did you?) - Aerial view geospatial images are under-represented in the training corpora relative to other images. This means that to a general-purpose tool like SceneXplain, an aerial view of a chaparral may look more like mold or dirt on a surface.


One of these is mold. The other is chaparral. Sorry, California.
tagWhy not use a dedicated model?
Most land-use classification is indeed done with dedicated models, specifically trained on aerial-view land use imagery. This makes them perfect for that particular task while not being so hot at general image classification.
So, why not just use one of those?
tagSelf-hosting is a drag
Even self-hosting something like Resnet (which has decent tutorials) is a drag. You need to set up AWS, install dependencies, compile the model, and so on. It’s not as easy as using an existing software-as-a-service like SceneXplain.
tagAcademic models are pure kryptonite
Let's look at the AID dataset and see how we can replicate what they did in their paper:
First of all, we have to download the code from OneDrive or Baidu Pan. Dang, the file no longer exists on OneDrive, and Baidu Pan wants me to install a random RPM or DEB file just to download the dataset. Blech.
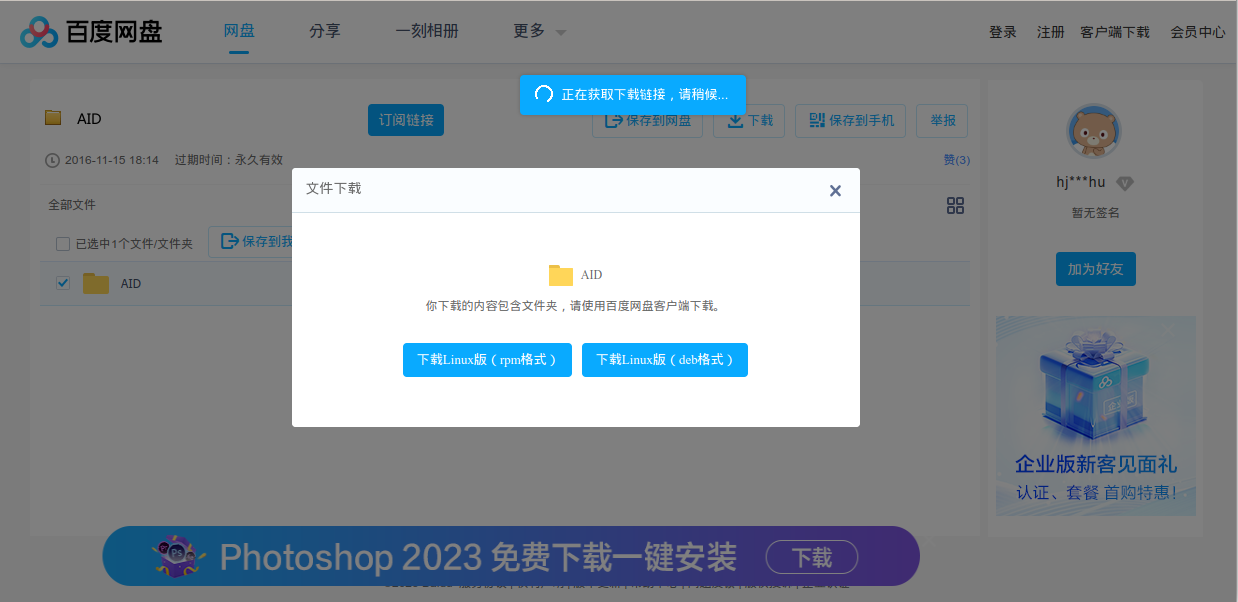
Assuming we have a friend in China who downloads the code and sends it to us (thanks Kelly!), we can extract it and check the readme.txt (Did you assume the readme would be in a repo somewhere, you sweet innocent summer child?)
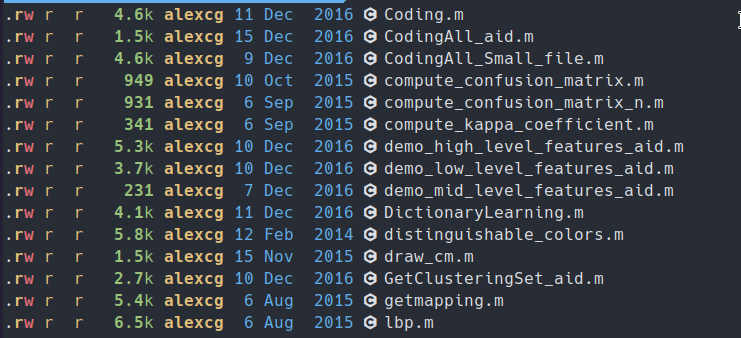
Checking the file dates with ls -l, we see the files were last modified in 2016. Great.
Now we download the pre-trained model from the URL in the readme. Good news! The link works! Bad news! There are lots of CNNs there and the readme doesn't say which one to download!
To quote the readme, the next step is to: Compile vlfeat, gist, matconvnet and liblinear, and place them under <libs>. We didn't actually try this, but I'm sure compiling software from over five years ago will go without a hitch. I just need to use version...um. There's no version specified. It's sheer dumb luck I guess!
The final step: We've put so much work into the other steps that now we can finally reap the fruits of our labor. We just need to install MatLab. Which is 860 EUR per year. Wonderful.
I'm sure setting up the model was worth the effort for whoever wrote the paper. But if I'm just trying things out, that's a lot of work and money.
libs folder already exists. Already (supposedly) populated with what I need. Turns out I can't even trust the readme (or perhaps myself, to be honest)tagI got ninety-nine problems, but a chaparral ain't one
Even assuming pre-trained models were simple to use, the categories are baked in already. Since most of the training data was (I assume) taken from California, chaparrals are all over the place, but there aren't so many medieval castles. So if I wanted to apply the same model to Europe, I'd be stuck with those categories.
On the other hand, SceneXplain is a general-purpose tool. This means it may not have extensive chaparral knowledge (seriously, outside of Californians, who among us does?), but it has enough general-purpose knowledge that it can more reliably classify what you're specifically looking for.
Let's just say that specialist data can be kryptonite to a general-purpose image classification/captioning model. AI models aren’t (and can’t be) all things to all people, after all.
When you think of the data used to train general-purpose image models, very little would be aerial views of the landscape taken from satellites and labels for such data (road, residential, etc.) would far more commonly be applied to pictures of those phenomena taken from a more human-centric angle.


Dense residential (L: How it's represented in most models, R: how it's represented in UC Merced dataset)
tagWhy NOT use SceneXplain?
While using dedicated models has its downsides, there are some advantages:
tagYou only care about chaparrals
Good for you buddy. Good for you.
tagSceneXplain isn't as accurate as pre-trained models
While a pain to set up, pre-trained models offer superior accuracy when it comes to this very specific domain. Those models were trained specifically on aerial imagery and thus offer accuracy rates of 85-95% when using high-level methods (see final table in the AID dataset paper), compared to SceneXplain's accuracy of about 60%.
tagNext steps
Large language models and image-to-text models aren’t specially trained to recognize landscape types from satellite imagery. There’s enough in their training data to make a stab at it, and it’s not totally useless, but zero-shot detection is just not good. Some categories are (by their nature) going to be tough to recognize, even for a human. If we can’t tell from 30,000 feet how many people live on a city block, then how could we expect SceneXplain to tell sparseresidential from mediumresidential?
Specially trained and fine-tuned models perform well enough to be a hard bar to beat.
But often you hit upon a problem that doesn’t have a specialized dataset that can be used for training a dedicated model. That means that a general-purpose tool, like SceneXplain, may be your best bet. Our next steps are trying to see how much better we can make SceneX with the least effort, so that our users can always get the best performance possible for the least added effort.
Even if no one ever uses SceneXplain to catalog land use, learning to make it better at this task teaches us how to make it better for something else that it’s never specially learned to do.
To test out SceneXplain for our own use case, create a free account and start playing! Let us know how you're doing on our Discord.






