



Last week, we released Jina Embeddings v3, a cutting-edge multilingual embedding model and a major upgrade over v2, which was published in October 2023. V3 features multilingual, task LoRA, better long-context support and Matryoshka learning. We highly recommend that existing users switch to v3 from v2. This migration guide covers the technical changes in v3 to make your transition as smooth as possible.
tagQuick Takeaways
- V3 is a new model, so you'll need to re-index all your documents when switching from v2. V3 embeddings can't be used to search v2 embeddings, and vice versa.
- V3 outperforms v2 96% of the time, with v2 occasionally matching or slightly exceeding v3 in English summarization tasks. Given v3's advanced features and multilingual support, it should be your go-to choice over v2 in most cases.
- V3 introduces three new API parameters:
task,dimensions, andlate_chunking. For the best understanding of these parameters, check out our blog post's section. - V3's default output is 1024-dimensional, compared to v2's 768. Thanks to Matryoshka learning, you can now choose arbitrary output dimensions in v3. The
dimensionsparameter lets you balance storage space and performance at the lowest cost by selecting your preferred embedding size. - If you have a project built on v2 API and only change the model name to jina-embeddings-v3, your project might fail because the default dimension is now 1024. You can set
dimensions=768if you want to keep the data structure or size the same as v2. However, even with the same dimensions, V3 and V2 embeddings are not interchangeable. - V2's bilingual models (
v2-base-de,v2-base-es,v2-base-zh) are obsolete - v3 is multilingual out of the box, supporting 89 languages. V3 also supports cross-lingual tasks to some extent. - However, v2's coding model jina-embeddings-v2-base-code remains our best for coding tasks. In our benchmark, v2 scores 0.7753, while v3's generic embedding (unset
task) scores 0.7537, and v3's unpublished code LoRA adapter scores 0.7564. This makes v2 about 2.8% better than v3 for coding tasks. - V3 API generates decent generic embeddings when
taskis unset. However, we strongly recommend settingtaskfor better quality, task-specific embeddings. - To mimic v2's behavior in v3, use
task="text-matching", not unsettask. But we highly recommend exploring different task options instead of usingtext-matchingas a one-size-fits-all solution. - If you're using v2 for information retrieval, switch to v3's retrieval task types (
retrieval.passageandretrieval.query) for better results. - If you're working on a completely new kind of task (which is very rare and we'd like to know more about your task), try
task=Noneas the starting point. - If you've been using the label rephrasing trick in v2 for zero-shot classification tasks, consider simply setting
task="classification"in v3 and trying without label rephrasing. This is because v3 has optimized embeddings for classification tasks, so in theory, label rephrasing isn't necessary anymore. - While both v2 and v3 support up to 8192 tokens in context length, v3 handles it much more effectively, as you can see in the benchmark below. This also provides a more solid foundation for applying "late chunking" in v3.

- V3 API adds "Late chunking", a cool feature to get contextual chunk embeddings by leveraging 8192-token length, leading to more relevant search results. Note that
late_chunkingis supported only by the API, not when running the model locally. - When
late_chunkingis enabled, the total number of tokens in theinputbatch is limited to 8192. This limit ensures the input fits within v3's context length in one shot, which is crucial for maintaining contextual chunk embeddings. - Speedwise, v3 should be faster than or at least match v2's speed, even though it has 3x larger parameter size. This is thanks to the FlashAttention2 implementation used in v3. However, not all GPUs support this, so v3 also works without FA2 – in which case it might be a bit slower than v2. Keep in mind that using v3 via our API may involve network latency, rate limits, and availability zone issues, so the latency there isn't an accurate reflection of v3's true performance.
- Unlike v2, v3 is under a source-available CC BY-NC 4.0 license. It's fine to use it commercially via our API, AWS, or Azure as listed below. Research and non-commercial use are also okay. For on-premises commercial use, contact our sales team for permission and licensing.


tagDeep Dive With Examples
tagOut with the Bilingual Models, in with the Multilingual
At the time of writing, Embeddings v3 stands as the top multilingual model and holds the second position on the MTEB English leaderboard for models under one billion parameters. It supports 89 languages, with exceptional performance in 30 of them, including Arabic, Bengali, Chinese, Danish, Dutch, English, Finnish, French, Georgian, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Latvian, Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Spanish, Swedish, Thai, Turkish, Ukrainian, Urdu, and Vietnamese.
If you've been using the English, English/German, English/Spanish, or English/Chinese v2 model, you can now simply switch to the single v3 model by just changing the model parameter and selecting your task type:
# v2 English-German
data = {
"model": "jina-embeddings-v2-base-de",
"input": [
"The Force will be with you. Always.",
"Die Macht wird mit dir sein. Immer.",
"The ability to destroy a planet is insignificant next to the power of the Force.",
"Die Fähigkeit, einen Planeten zu zerstören, ist nichts im Vergleich zur Macht der Macht."
]
}
# v3 multilingual
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.passage",
"input": [
"The Force will be with you. Always.",
"Die Macht wird mit dir sein. Immer.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tagTask Specific Embeddings
While Embeddings v2 provided a one-size-fits-all approach, v3 generates embeddings that are optimized depending on your specific use case. Each task type ensures the model focuses on extracting features relevant to the task at hand, thereby improving performance.
Let's look at how to migrate v2 code to v3 for each task. First we need a dataset and a query. Let's use a lightsaber repair knowledge base:
# naturally we'd use a bigger dataset in the real world, but this makes for a working example
knowledge_base = [
"Why is my lightsaber blade flickering? Blade flickering can indicate a low power cell or an unstable kyber crystal. Recharge the battery and check the crystal’s stability. If flickering persists, it may require a crystal recalibration or replacement.",
"Why is my blade dimmer than before? A dim blade could mean that the battery is low or there’s an issue with the power distribution. First, recharge the battery. If the issue persists, the LED may need to be replaced.",
"Can I change the blade color of my lightsaber? Many lightsabers allow blade color customization either by swapping out the kyber crystal or using the saber's control panel to change color settings. Refer to your model’s manual for specific instructions.",
"What should I do if my lightsaber overheats? Overheating can happen with prolonged use. Turn off the lightsaber and allow it to cool for at least 10 minutes. If it overheats frequently, it may indicate an internal issue that requires inspection by a technician.",
"How do I recharge my lightsaber? Connect the lightsaber to the provided charging cable via the port near the hilt. Ensure you use the official charger to avoid damage to the power cell and electronics.",
"Why does my lightsaber emit a strange noise? A strange noise may indicate a soundboard or speaker issue. Try turning the saber off and on again. If the problem persists, contact our support team for a possible soundboard replacement."
]
query = "lightsaber too dim"
For v2 there was only task (text-matching), thus for v2 we only need one example code block:
# v2 code
data = {
"model": "jina-embeddings-v2-base-en",
"normalized": True, # remove when migrating to v3
"input": knowledge_base
}
docs_response = requests.post(url, headers=headers, json=data)
data = {
"model": "jina-embeddings-v2-base-en",
"task": "text-matching"
"input": [query]
}
query_response = requests.post(url, headers=headers, json=data)
v3, on the other hand, offers task-specific embeddings for retrieval, separation, classification and text-matching:
Retrieval Embeddings
retrieval.passage
Used for embedding passages (documents) in search systems. Let's say we want to embed some our lightsaber knowledge base from above to store in a database for later retrieval:
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.passage", # "task" parameter is new in v3
"late_chunking": True,
"input": knowledge_base
}
response = requests.post(url, headers=headers, json=data)
retrieval.query
Used for creating embedding for queries that are optimized for retrieval. Now let's provide results for the same query we used above (lightsaber too dim):
data = {
"model": "jina-embeddings-v3",
"task": "retrieval.query",
"late_chunking": True,
"input": [query]
}
response = requests.post(url, headers=headers, json=data)
late_chunking in the v3 code snippets. There's more on that later in this migration guide.We can see the performance enhancement from asymmetric encoding (using retrieval.passage and retrieval.query instead of v2's text-matching). Let's compare querying a lightsaber technical support database with both models.
We can compare v2 (without task) and v3's retrieval.passage and retrieval.query tasks. Given the query "lightsaber too dim", v2 returns the following matches in order from best to worst according to cosine similarity:
| Document | Cosine Similarity |
|---|---|
| What should I do if my lightsaber overheats? Overheating can happen with prolonged use. Turn off the lightsaber and allow it to cool for at least 10 minutes. If it overheats frequently, it may indicate an internal issue that requires inspection by a technician. | 0.8176 |
| Why does my lightsaber emit a strange noise? A strange noise may indicate a soundboard or speaker issue. Try turning the saber off and on again. If the problem persists, contact our support team for a possible soundboard replacement. | 0.8018 |
| Why is my blade dimmer than before? A dim blade could mean that the battery is low or there’s an issue with the power distribution. First, recharge the battery. If the issue persists, the LED may need to be replaced. | 0.7984 |
| Why is my lightsaber blade flickering? Blade flickering can indicate a low power cell or an unstable kyber crystal. Recharge the battery and check the crystal’s stability. If flickering persists, it may require a crystal recalibration or replacement. | 0.7862 |
| Can I change the blade color of my lightsaber? Many lightsabers allow blade color customization either by swapping out the kyber crystal or using the saber's control panel to change color settings. Refer to your model’s manual for specific instructions. | 0.7440 |
Whereas v3 (using retrieval.passage and retrieval.query tasks) returns results that reference the appearance of the lightsaber's blade, which are more relevant to the query:
| Document | Cosine Similarity |
|---|---|
| Why is my blade dimmer than before? A dim blade could mean that the battery is low or there’s an issue with the power distribution. First, recharge the battery. If the issue persists, the LED may need to be replaced. | 0.6546 |
| Can I change the blade color of my lightsaber? Many lightsabers allow blade color customization either by swapping out the kyber crystal or using the saber's control panel to change color settings. Refer to your model’s manual for specific instructions. | 0.6515 |
| What should I do if my lightsaber overheats? Overheating can happen with prolonged use. Turn off the lightsaber and allow it to cool for at least 10 minutes. If it overheats frequently, it may indicate an internal issue that requires inspection by a technician. | 0.6347 |
| How do I recharge my lightsaber? Connect the lightsaber to the provided charging cable via the port near the hilt. Ensure you use the official charger to avoid damage to the power cell and electronics. | 0.6282 |
| Why does my lightsaber emit a strange noise? A strange noise may indicate a soundboard or speaker issue. Try turning the saber off and on again. If the problem persists, contact our support team for a possible soundboard replacement. | 0.6275 |
v3 goes well beyond retrieval, and offers several other task-specific embeddings:
Separation Embeddings
Optimized for separation (e.g. clustering and reranking) tasks, useful for organizing and visualizing large corpora. Let's say we want to separate Star Wars characters from classic Disney characters:
data = {
"model": "jina-embeddings-v3",
"task": "separation",
"late_chunking": True,
"input": [
"Darth Vader",
"Luke Skywalker",
"Mickey Mouse",
"Donald Duck"
]
}
response = requests.post(url, headers=headers, json=data)
Classification Embeddings
Optimized for text classification tasks like sentiment analysis or document categorization. In this example we can classify statements into positive and negative movie reviews via sentiment analysis:
data = {
"model": "jina-embeddings-v3",
"task": "classification",
"late_chunking": True,
"input": [
"Star Wars is a groundbreaking masterpiece that completely transformed cinema and redefined the sci-fi genre forever!",
"The breathtaking visuals, unforgettable characters, and legendary storytelling of Star Wars make it an unrivaled cultural phenomenon.",
"Star Wars is an overhyped disaster, riddled with shallow characters and devoid of any meaningful plot!",
"The entire Star Wars saga is nothing but a tedious, cliché-ridden spectacle that relies solely on special effects to distract from its utter lack of substance."
]
}
response = requests.post(url, headers=headers, json=data)
Text Matching Embeddings
Focused on semantic similarity tasks, such as sentence similarity or deduplication. This helps weed out duplicates (and near duplicates) from our Star Wars lines:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"late_chunking": True,
"input": [
"Luke, I am your father.",
"No, I am your father.",
"Fear leads to anger, anger leads to hate, hate leads to the dark side.",
"Fear leads to anger. Anger leads to hate. Hate leads to suffering."
]
}
response = requests.post(url, headers=headers, json=data)
tagBetter Context Encoding with Late Chunking
v3's late_chunking parameter controls whether the model processes the entire document before splitting it into chunks, preserving more context across long texts. From a user perspective, the input and output formats remain the same, but the embedding values will reflect the full document context rather than being computed independently for each chunk.
- When using
late_chunking=True, the total number of tokens (summed across all chunks ininput) per request is restricted to 8192, the maximum context length allowed for v3. - When using
late_chunking=False, this token limit does not apply, and the total tokens are only restricted by the rate limit of the Embedding API.
To enable late chunking, pass late_chunking=True in your API calls.
You can see the advantage of late chunking by searching through a chat history:
history = [
"Sita, have you decided where you'd like to go for dinner this Saturday for your birthday?",
"I'm not sure. I'm not too familiar with the restaurants in this area.",
"We could always check out some recommendations online.",
"That sounds great. Let's do that!",
"What type of food are you in the mood for on your special day?",
"I really love Mexican or Italian cuisine.",
"How about this place, Bella Italia? It looks nice.",
"Oh, I’ve heard of that! Everyone says it's fantastic!",
"Shall we go ahead and book a table there then?",
"Yes, I think that would be a perfect choice! Let's call and reserve a spot."
]
If we ask What's a good restaurant? with Embeddings v2, the results are not very relevant:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.7675 |
| I really love Mexican or Italian cuisine. | 0.7561 |
| How about this place, Bella Italia? It looks nice. | 0.7268 |
| What type of food are you in the mood for on your special day? | 0.7217 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.7186 |
With v3 and no late chunking, we get similar results:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.4005 |
| I really love Mexican or Italian cuisine. | 0.3752 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.3330 |
| How about this place, Bella Italia? It looks nice. | 0.3143 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.2615 |
However, we see a marked performance improvement when using v3 and late chunking, with the most relevant result (a good restaurant) at the top:
| Document | Cosine Similarity |
|---|---|
| How about this place, Bella Italia? It looks nice. | 0.5061 |
| Oh, I’ve heard of that! Everyone says it's fantastic! | 0.4498 |
| I really love Mexican or Italian cuisine. | 0.4373 |
| What type of food are you in the mood for on your special day? | 0.4355 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.4328 |
As you can see, even though the top match doesn't mention the word "restaurant" at all, late chunking preserves its original context and presents it as the correct top answer. It encodes "restaurant" into the restaurant name "Bella Italia" because it sees its meaning in the larger text.
tagBalance Efficiency and Performance with Matryoshka Embeddings
The dimensions parameter in Embeddings v3 gives you the ability to balance storage efficiency with performance at minimal cost. v3's Matryoshka embeddings let you truncate the vectors produced by the model, reducing the dimensions as much as you need while retaining useful information. Smaller embeddings are ideal for saving space in vector databases and improving retrieval speed. You can estimate the performance impact based on how much the dimensions are reduced:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 1024 by default
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tagFAQ
tagI'm Already Chunking My Documents Before Generating Embeddings. Does Late Chunking Offer Any Advantage Over My Own System?
Late chunking offers advantages over pre-chunking because it processes the entire document first, preserving important contextual relationships across the text before splitting it into chunks. This results in more contextually rich embeddings, which can improve retrieval accuracy, especially in complex or lengthy documents. Additionally, late chunking can help deliver more relevant responses during search or retrieval, as the model has a holistic understanding of the document before segmenting it. This leads to better overall performance compared to pre-chunking, where chunks are treated independently without full context.
tagWhy Is v2 Better at Pair Classification Than v3, and Should I Be Concerned?
The reason v2-base-(zh/es/de) models appear to perform better at Pair Classification (PC) is primarily due to how the average score is calculated. In v2, only Chinese is considered for PC performance, where embeddings-v2-base-zh model excels, leading to a higher average score. Benchmarks of v3 include four languages: Chinese, French, Polish, and Russian. As a result, its overall score appears lower when compared to v2's Chinese-only score. However, v3 still matches or outperforms models like multilingual-e5 across all languages for PC tasks. This broader scope explains the perceived difference, and the performance drop should not be a concern, especially for multilingual applications where v3 remains highly competitive.
tagDoes v3 Really Outperform the v2 Bilingual Models' Specific Languages?
When comparing v3 to the v2 bilingual models, the performance difference depends on the specific languages and tasks.
The v2 bilingual models were highly optimized for their respective languages. As a result, in benchmarks specific to those languages, like Pair Classification (PC) in Chinese, v2 might show superior results. This is because embeddings-v2-base-zh's design was tailored specifically for that language, allowing it to excel in that narrow scope.
However, v3 is designed for broader multilingual support, handling 89 languages and being optimized for a variety of tasks with task-specific LoRA adapters. This means that while v3 might not always outperform v2 in every single task for a specific language (like PC for Chinese), it tends to perform better overall when evaluated across multiple languages or on more complex, task-specific scenarios like retrieval and classification.
For multilingual tasks or when working across several languages, v3 offers a more balanced and comprehensive solution, leveraging better generalization across languages. However, for very language-specific tasks where the bilingual model was finely tuned, v2 might retain an edge.
In practice, the right model depends on the specific needs of your task. If you are working only with a particular language and v2 was optimized for it, you may still see competitive results with v2. But for more generalized or multilingual applications, v3 is likely the better choice due to its versatility and broader optimization.
tagWhy Is v2 Better at Summarization than v3, and Do I Need to Worry About This?
v2-base-en performs better at summarization (SM) because its architecture was optimized for tasks like semantic similarity, which is closely related to summarization. In contrast, v3 is designed to support a broader array of tasks, particularly in retrieval and classification tasks, and is more suited to complex and multilingual scenarios.
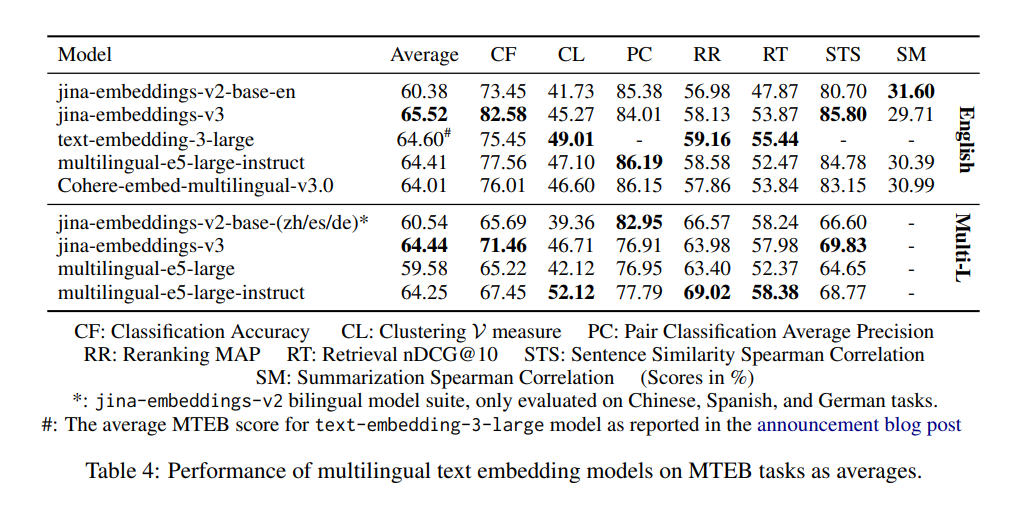
However, this performance difference in SM should not be a concern for most users. The SM evaluation is based on just one summarization task, SummEval, which primarily measures semantic similarity. This task alone is not very informative or representative of the model’s broader capabilities. Since v3 excels in other critical areas like retrieval, it’s likely that the summarization difference won’t significantly impact your real-world use cases.
