


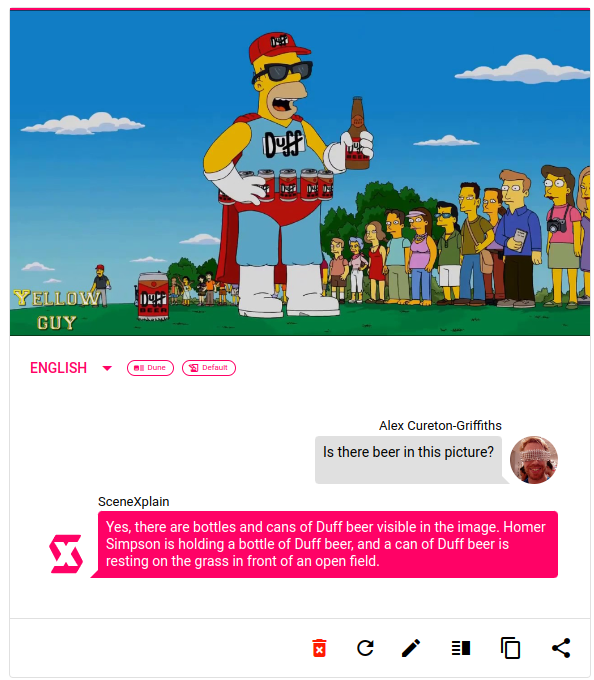
Back in June, we introduced visual question answering in SceneXplain, letting you upload an image and ask questions about it:
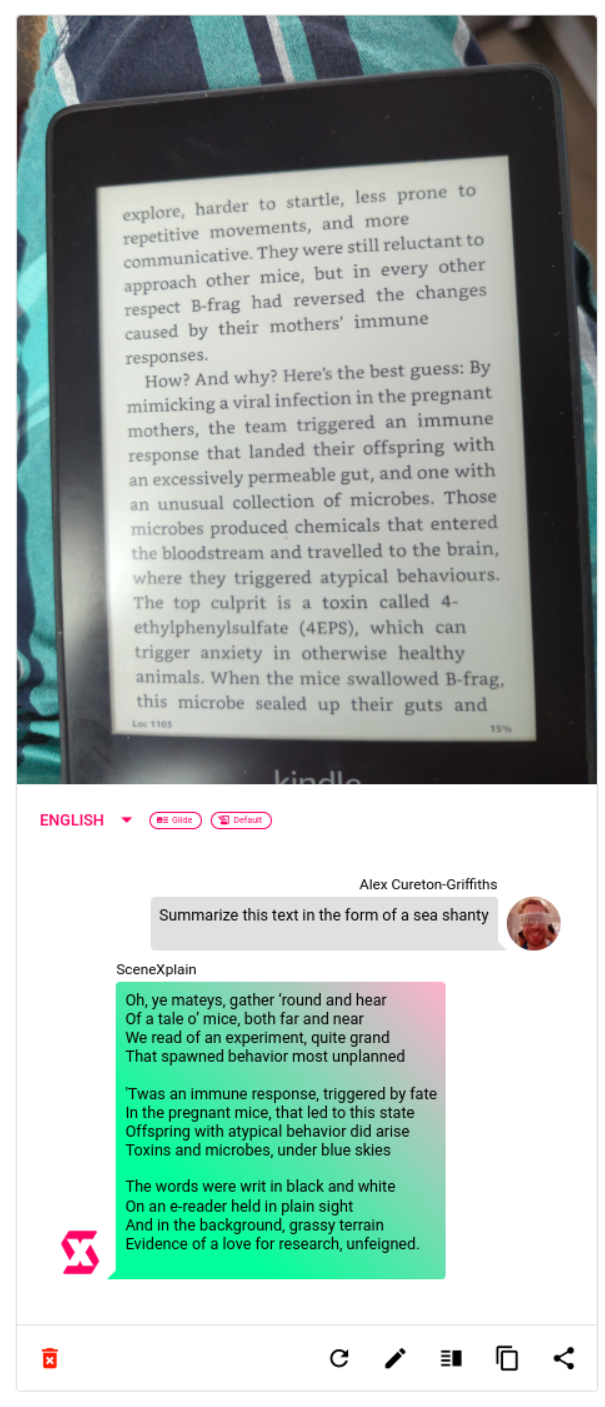
Now we're bringing a new model to the table, Glide. Glide reads and understands the text in images too, integrating OCR into the question-answering experience:
tagHow do I use OCR in visual question answering?
The process is exactly the same as for visual question answering in general. It's baked right in, meaning you don't have to toggle any additional options. Just enable "Visual question answer" and you're off to the races!
First, upload your image:

Then click on the speech bubble to ask your question:

Then click the button to send your data and, voila, your question will be answered!
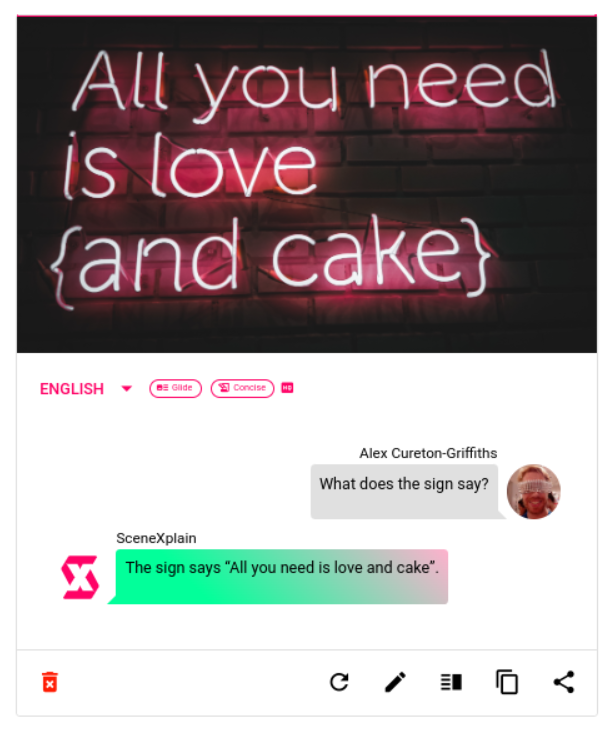
tagWhat's this good for?
- Accessibility for visually impaired users: SceneXplain can be used to provide descriptive text for images online or in digital documents, helping visually impaired users understand the content more effectively.
- Search Engine Optimization (SEO): By providing accurate and detailed descriptions for images, SceneXplain can help improve the SEO of websites, as search engines rely heavily on text data. This is especially useful for products like apparel with brand names, slogans, or other text; or infographics that incorporate text into images. This becomes especially convenient when you perform batching via SceneXplain’s API, which we cover in this post.
- Education: Teachers can use SceneXplain to create descriptive text for diagrams, illustrations, and other visual aids, making it easier for students who prefer or require reading over visual learning.
- Brand sentiment analysis: You can use SceneXplain to analyze images and associated text on social media platforms to better understand user sentiment and trends or to identify inappropriate content. This goes a step beyond regular brand sentiment analysis since it can detect brand logo text which would otherwise have been outside the model’s training set.
- Translation: When combined with a translation tool, SceneXplain can be used to read and translate text in images from one language to another, aiding in international communication and travel in foreign countries.
tagOCR in action
The most obvious question you can ask is "What is the text in this image?"

But we're working with a large language model (LLM) here. Why limit ourselves to something so basic?
We can do things like translating graffiti:
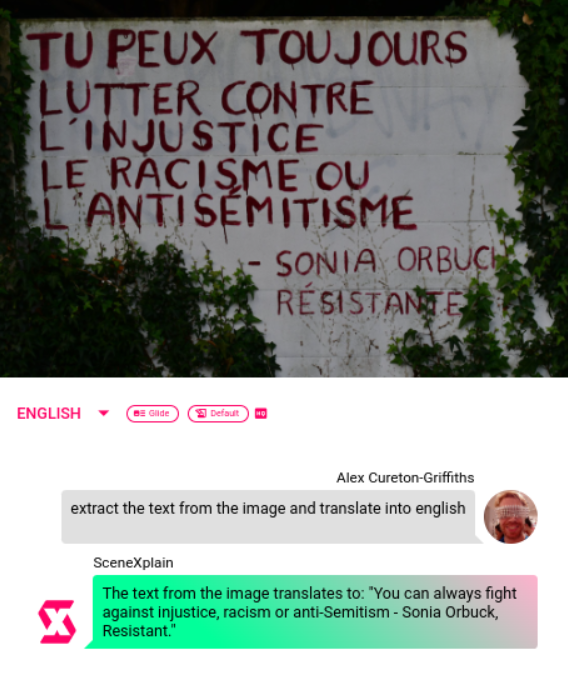
...or correcting the translation of one language into another:
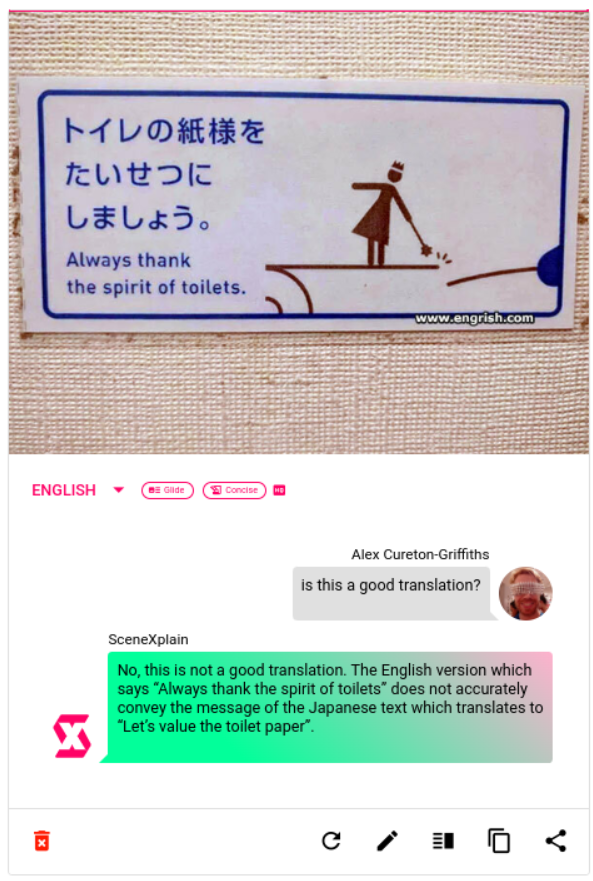
...or read signs:

...or just get specific information from a sign:

Maybe you're completely out of touch with geek culture and don't understand why something is funny. SceneXplain has got your back:
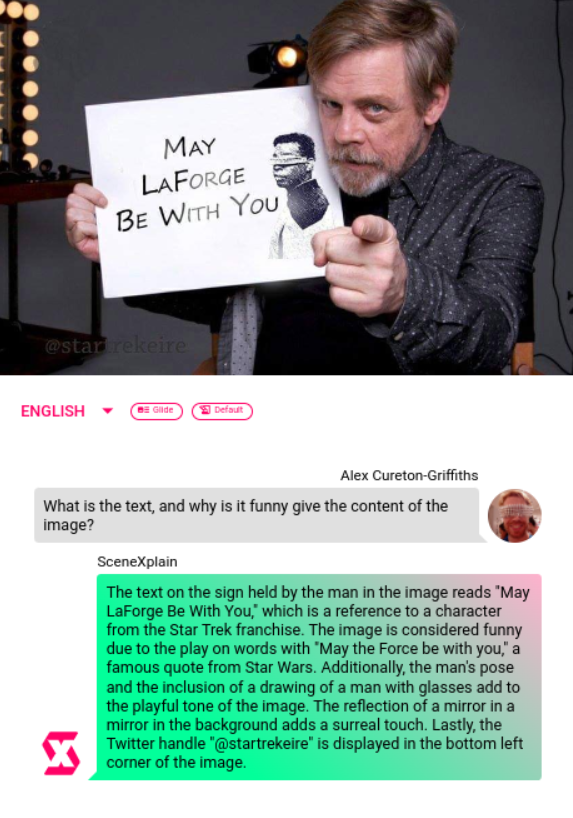
...and we can even ask it to describe what we're pointing at. Forget point and click - now you've got point and explain!

tagGet started
OC-are you ready to get started with SceneXplain? Head on over to scenex.jina.ai to create your account, and start uploading your images and asking your questions. Need support or want to share your results? You can do that on our Discord channel.

tagRead more
Want to dig deeper? We've written a bunch of other posts about what you can do with SceneXplain:












