

In the ever-evolving world of multimodal AI and computer vision, SceneXplain consistently pushes the boundaries. Today, we're thrilled to introduce a feature that promises to redefine the landscape of image captioning: Image-to-JSON. Let's delve into this innovation and understand its transformative potential.
tagSceneXplain's Image Captioning Ability
SceneXplain stands as a beacon in advanced image captioning and video summarization. Thanks to Jina AI's state-of-the-art multimodal algorithms, SceneXplain transcends traditional captioning, offering rich textual narratives from visuals. With an intuitive interface and a robust API, it's designed for both seasoned users and developers.

tagUnderstanding JSON Schema
Before delving into the Image-to-JSON feature, it's essential to understand JSON Schema.
JSON Schema is a vocabulary that allows you to annotate and validate JSON documents. Think of it as a blueprint for the structure of your JSON data. It defines the shape of your data, types of data values, and even the range of permissible values. With JSON Schema, you can tailor the data extraction process to your specific needs.
| a JSON file | the JSON Schema defines the right JSON |
|---|---|
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"courses": ["Math", "Science"]
}
|
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Full name of the person"
},
"age": {
"type": "number",
"description": "Age of the person"
},
"isStudent": {
"type": "boolean",
"description": "Indicates if the person is a student"
},
"courses": {
"type": "array",
"items": {
"type": "string"
},
"description": "List of courses the person is enrolled in"
}
},
"required": ["name", "age", "isStudent", "courses"]
}
|
tagThe Image-to-JSON Revolution
In traditional image captioning, the process has been linear: input an image and receive a text description. This approach, while effective, lacked the flexibility to extract specific data or focus on particular areas within an image. Enter SceneXplain's Image-to-JSON feature, our innovative solution to these limitations.

With Image-to-JSON, users upload an image and accompany it with a custom JSON Schema. The result? A structured JSON output tailored to capture specific information, whether it's in enums, lists, strings, booleans, or numbers.

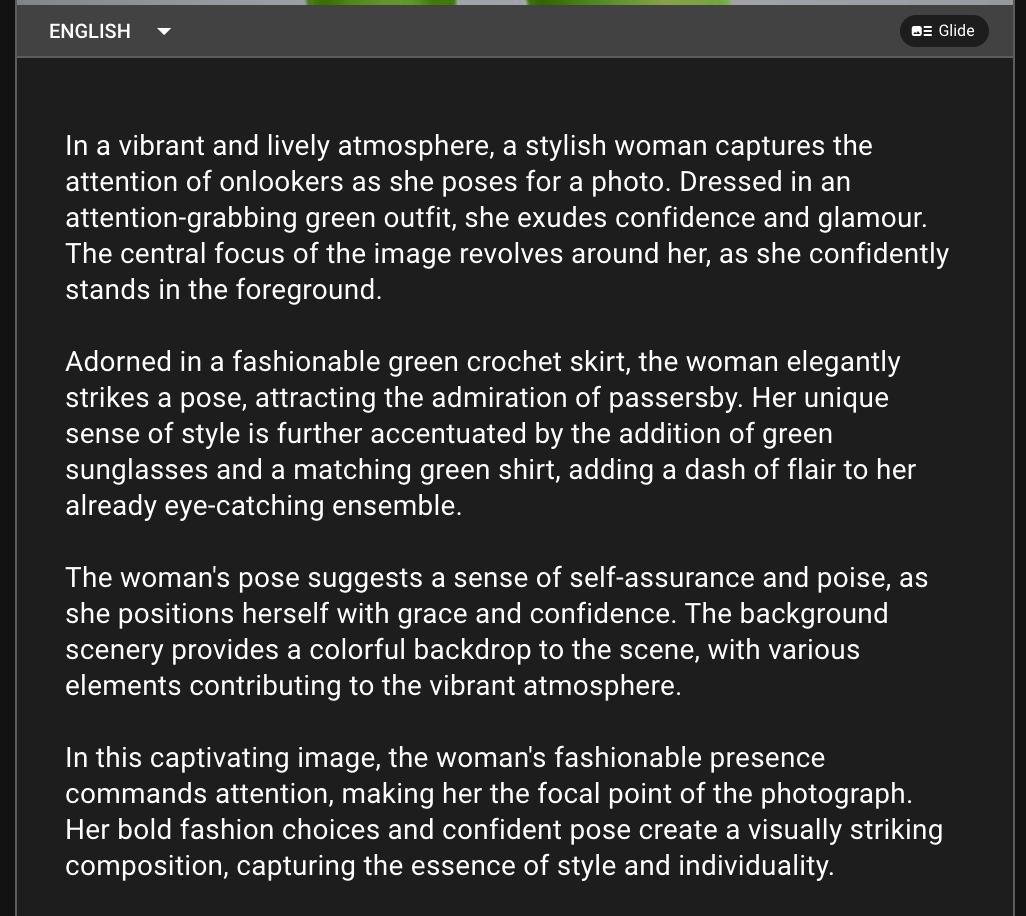
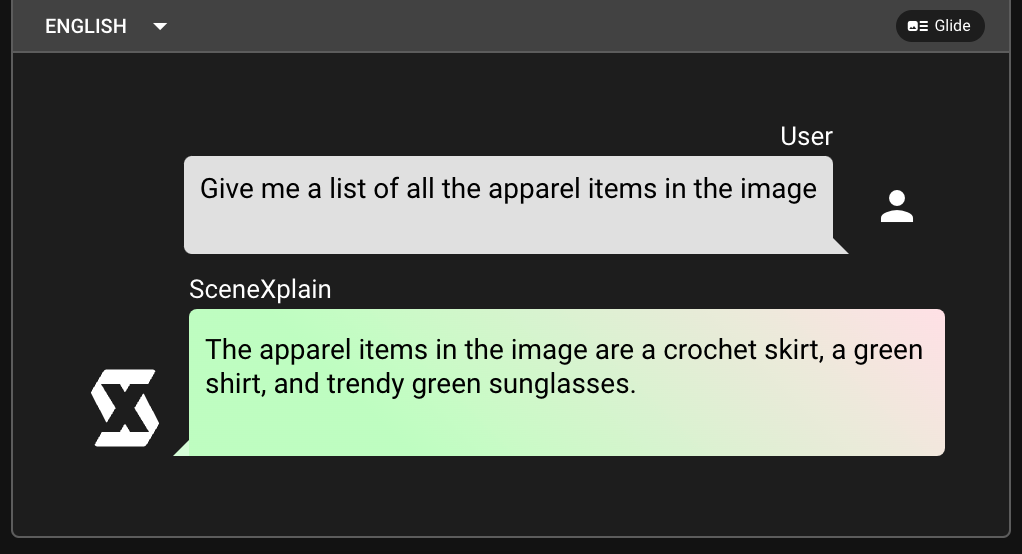
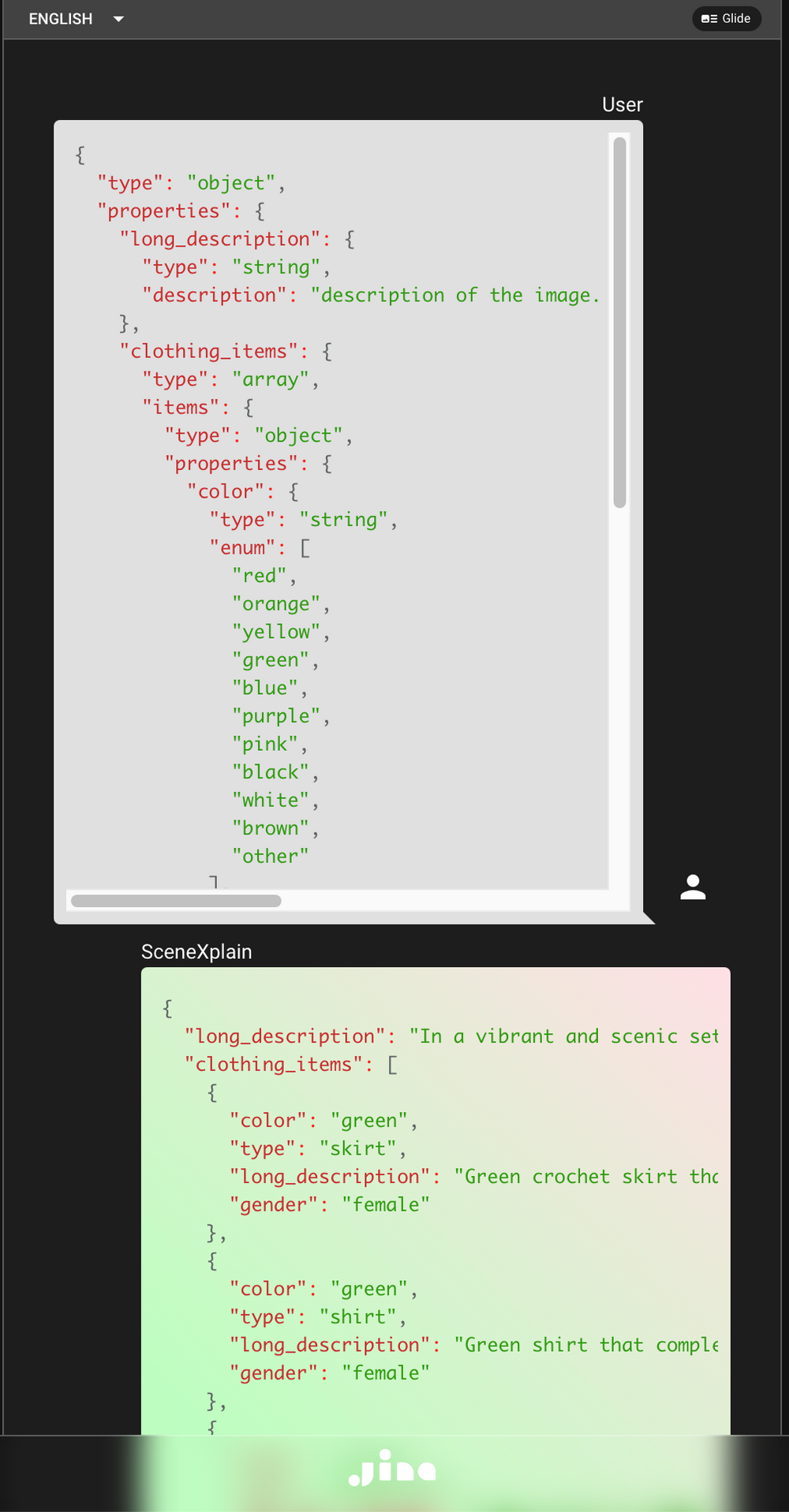
From Prompting to Structured Outputs
The concept of prompting, popularized by large language models (LLMs), involves guiding AI responses using specific questions or instructions. For example, prompting an LLM with "Describe the Eiffel Tower" yields a textual description. However, this output, while informative, is unstructured.
Image-to-JSON takes prompting to the next level. The description field in the JSON schema serves as an advanced prompt. Instead of just a textual response, SceneXplain processes the image and structures its output based on the provided schema. This ensures not just relevance but also precision and consistency in the format.
This structured approach is especially crucial for applications that demand consistent data formats. While free-form text outputs offer flexibility, they can be challenging to integrate into systems that require structured data. Image-to-JSON bridges this gap, combining the adaptability of prompting with the reliability of structured outputs.
In essence, SceneXplain's Image-to-JSON is a testament to the evolution of AI comprehension. It showcases how AI can be both versatile in understanding visuals and precise in delivering structured, actionable data.
tagHow to Use Image-to-JSON in SceneXplain
To harness this feature, users need to upload their image and define a corresponding JSON schema. To do this, click the dropdown button on the right of the input box and then select "Add JSON Schema".
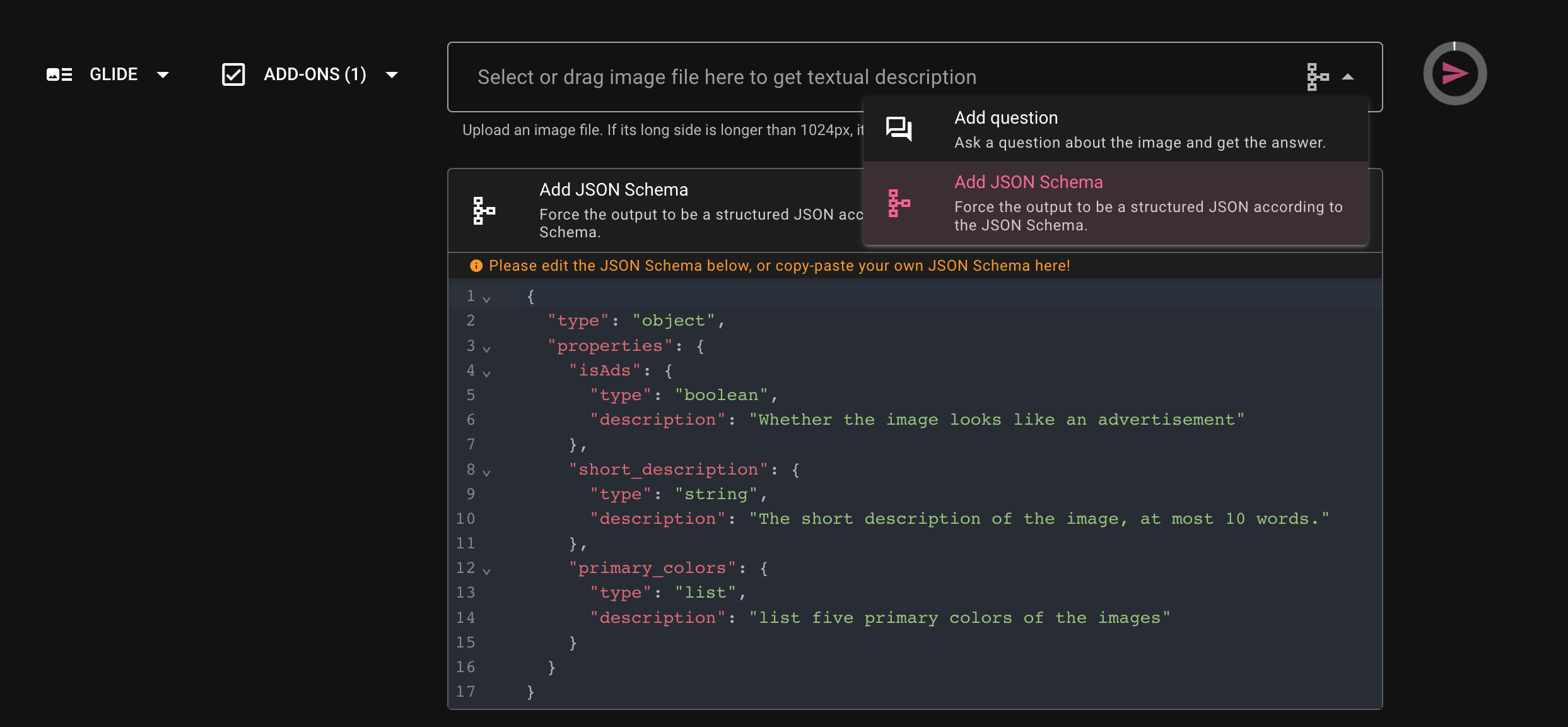
This schema comprises key-value pairs, with two essential keys:
type: This determines the result format, such as string, list, boolean, etc.description: This serves as a prompt, guiding the kind of information to extract from the image.
Let's explore this with increasingly complex examples:
Basic Inventory Check:
{
"type": "object",
"properties": {
"brands": {
"type": "list",
"description": "Identify brands on the shelf."
}
}
}
Season Identification:
{
"type": "object",
"properties": {
"season": {
"type": "string",
"enum": ["Spring", "Summer", "Autumn", "Winter"],
"description": "Determine the predominant season in the image."
}
}
}
Detailed Landscape Analysis:
{
"type": "object",
"properties": {
"flora": {
"type": "list",
"description": "List all visible plant species."
},
"fauna": {
"type": "list",
"description": "List all visible animal species."
},
"timeOfDay": {
"type": "string",
"enum": ["Morning", "Afternoon", "Evening", "Night"],
"description": "Identify the time of day."
}
}
}
tagSome Examples
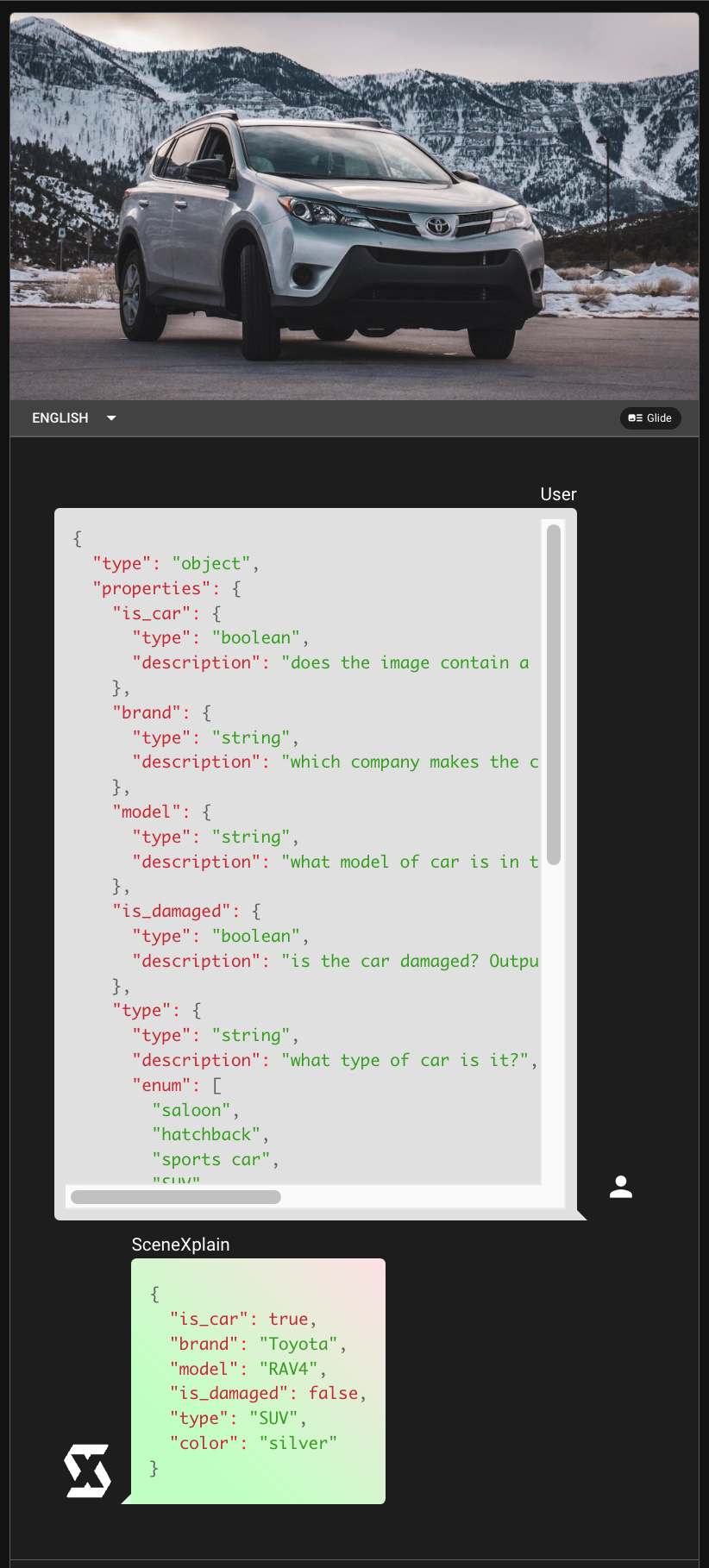
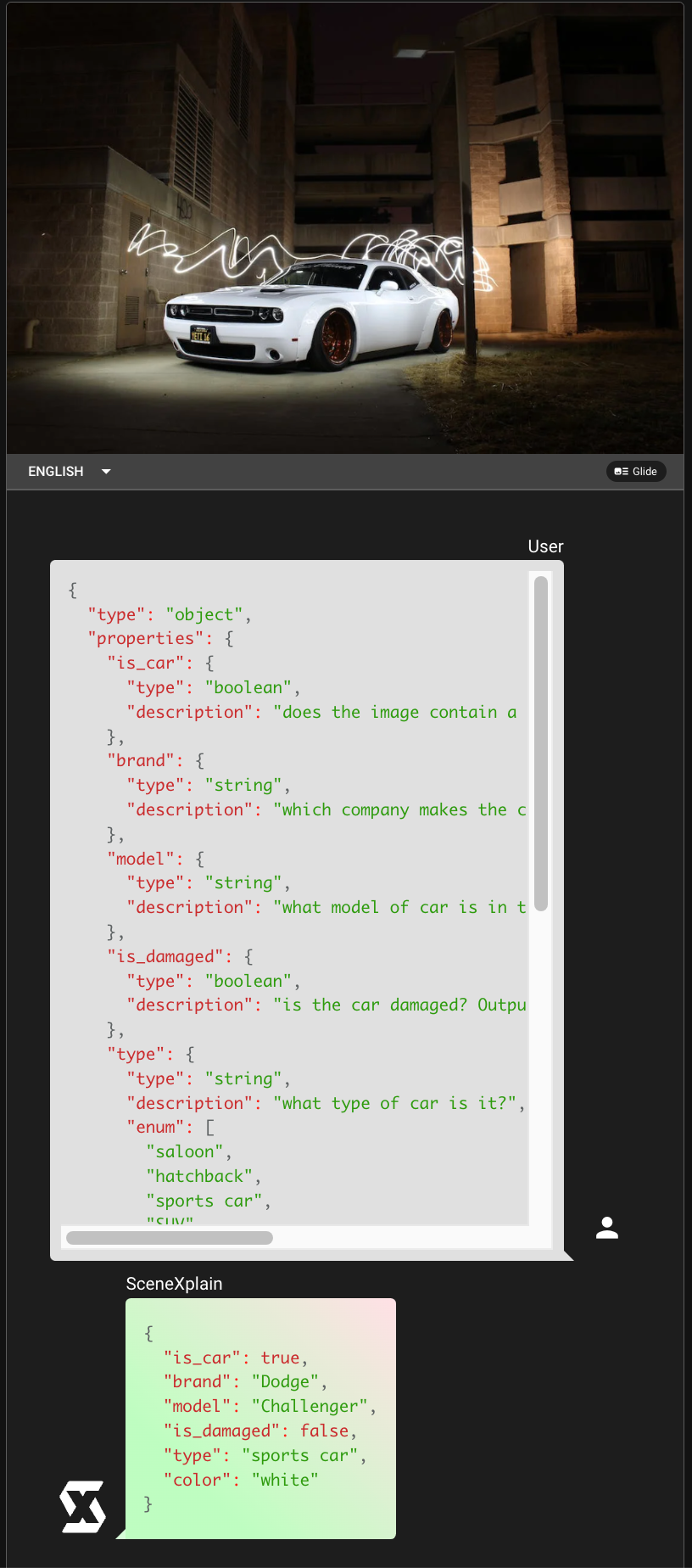
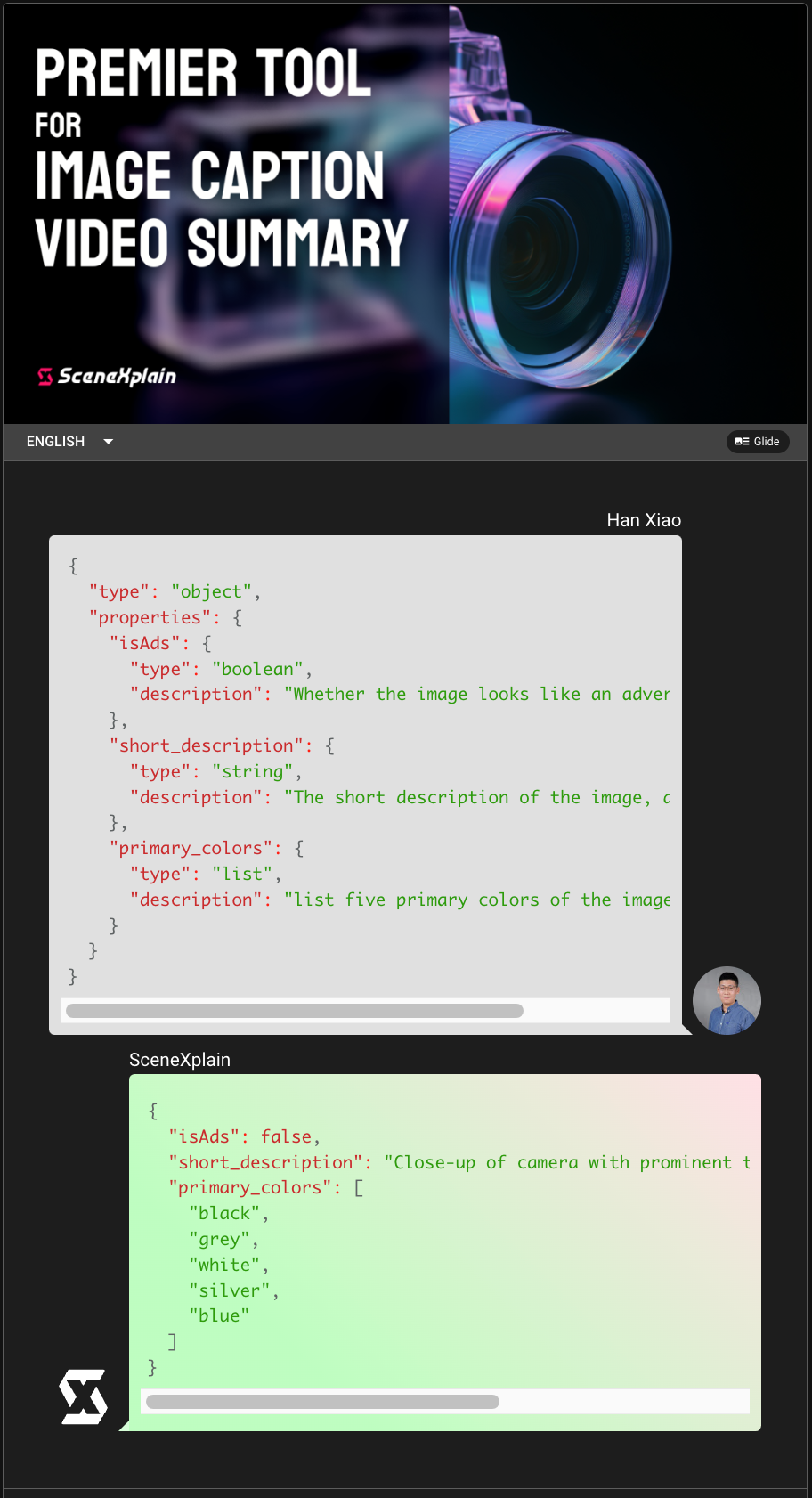
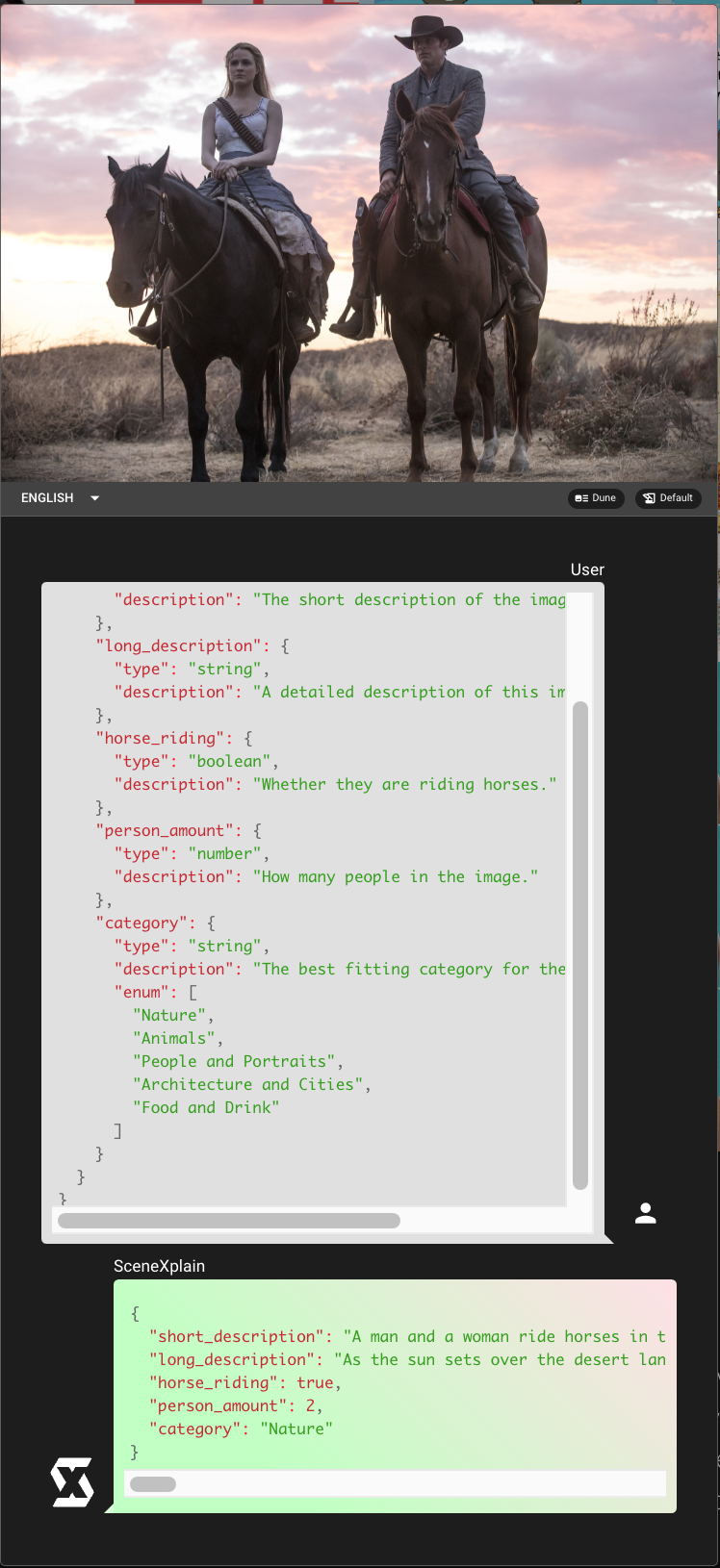
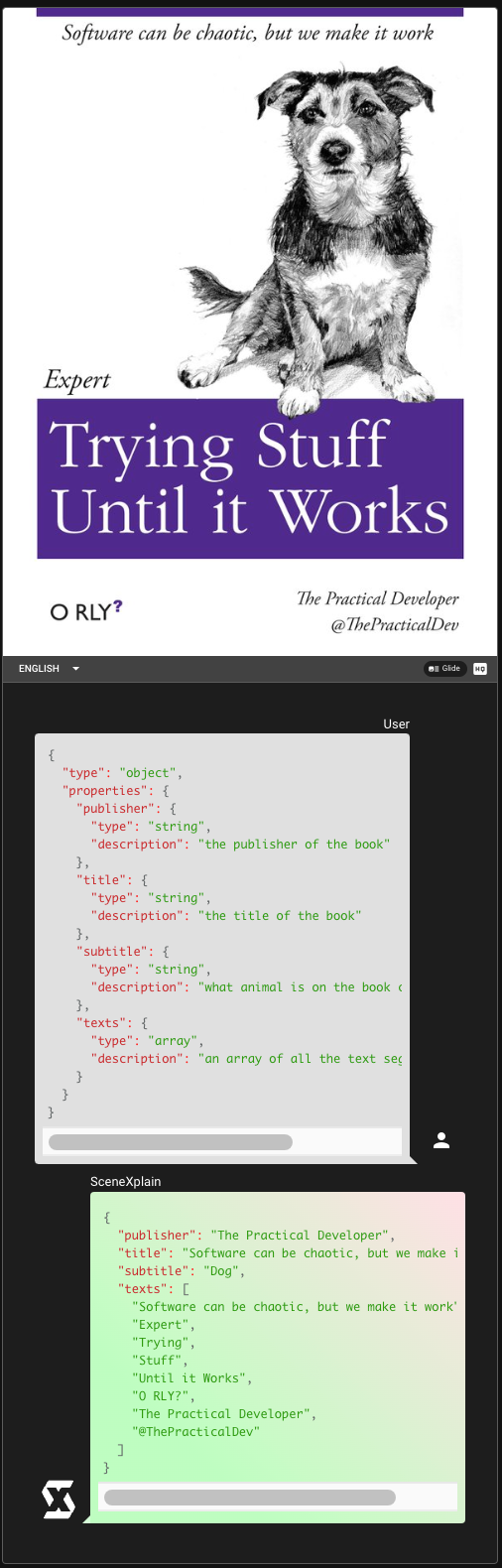
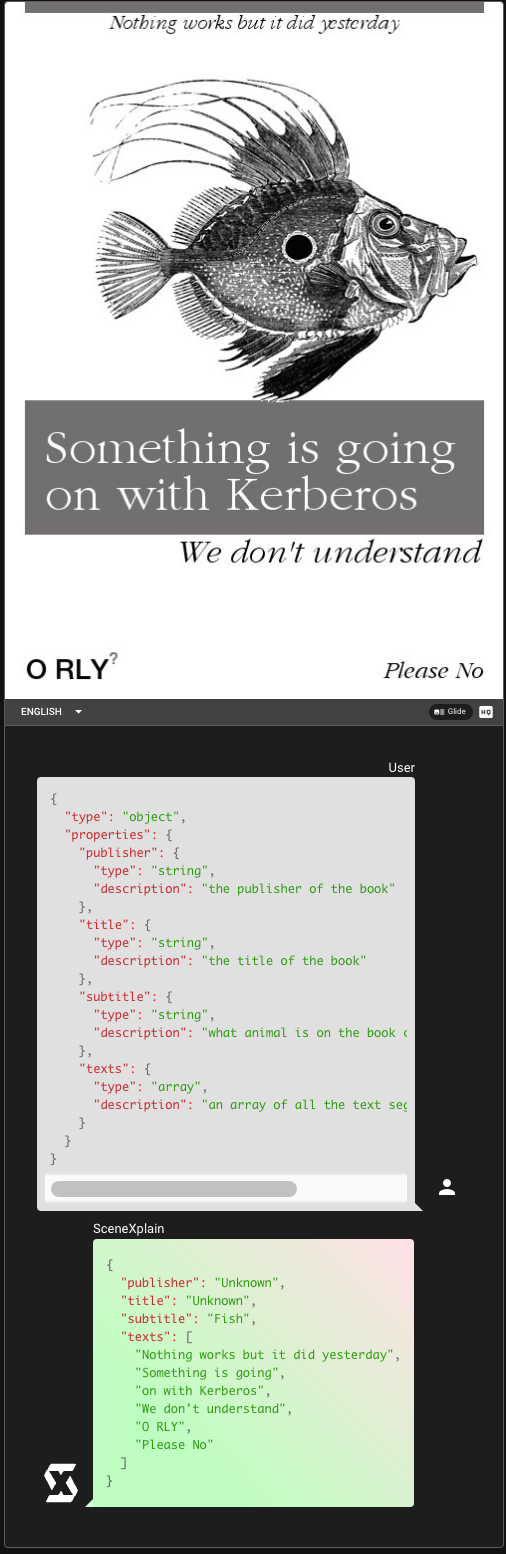
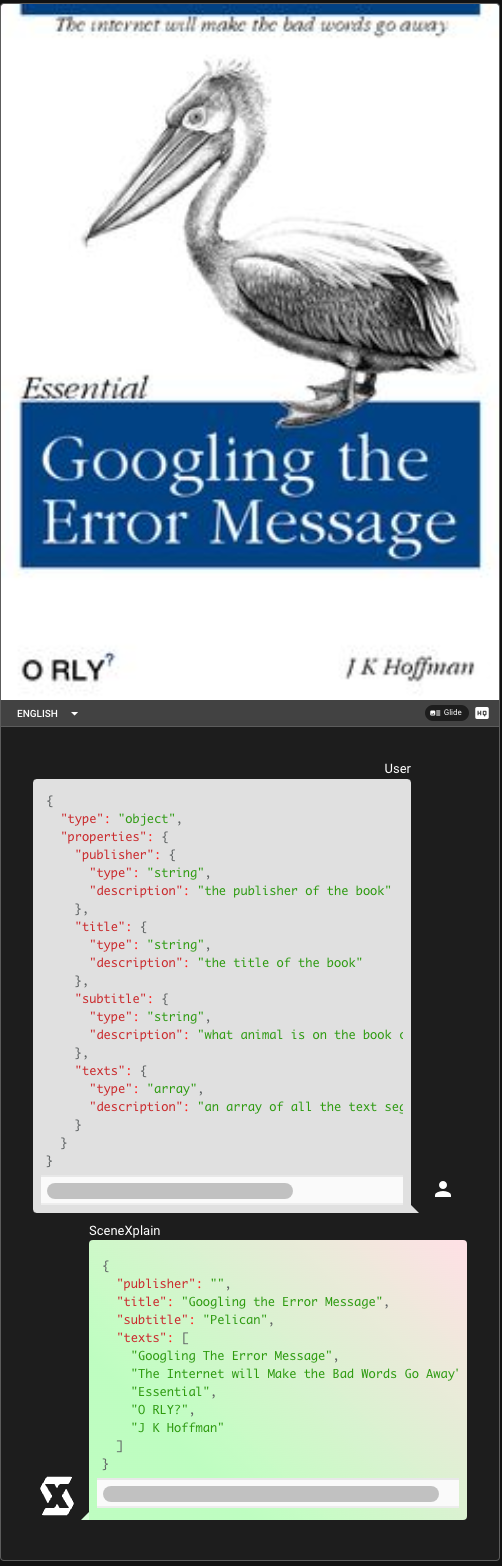
tagReal-World Applications and API Integration
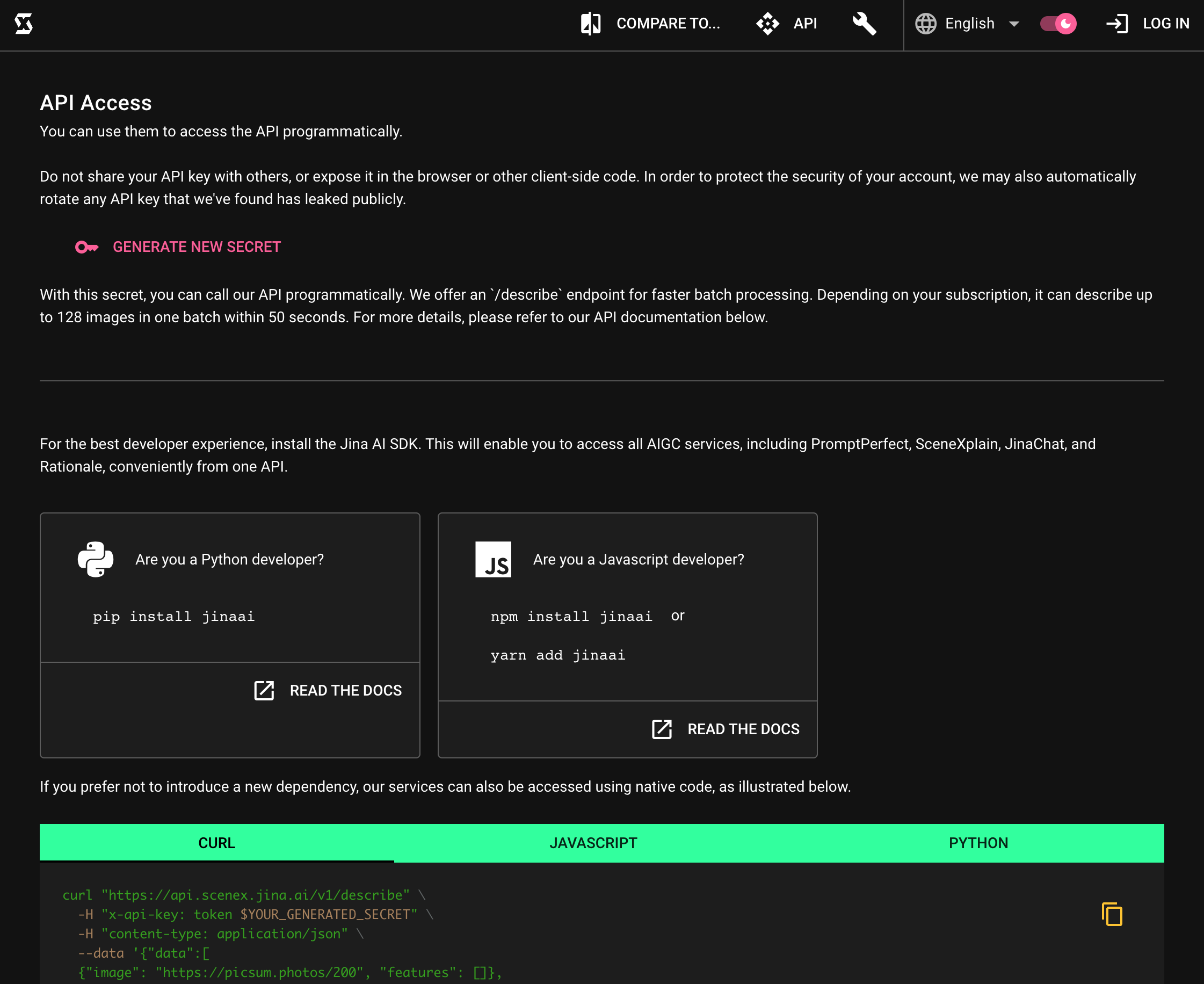
Beyond the user interface, this feature can be seamlessly integrated into systems via our API. For developers looking to harness the power of Image-to-JSON programmatically, our API documentation provides comprehensive guidance.
tagImage-to-JSON vs. VQA & Image Captioning
The table below provides a clear comparison between SceneXplain's Image-to-JSON, Visual Question Answering (VQA), Traditional Image Captioning, and the Good-Old OCR based on various features.
| Task | SceneXplain's Image-to-JSON | Visual Question Answering | Traditional Image Captioning | OCR |
|---|---|---|---|---|
| Flexibility | Customizable JSON output | Customizable queries | Fixed text description | Extracted text snippets |
| Output Types | Structured: Enums, Lists, Strings, Booleans, Numbers (including nested structures) | Text only | Text only | Text only |
| Granularity of Information | High (detailed structured data) | Medium (depends on the query) | Low (general description) | Low (text without context) |
| User Control | Full via JSON Schema | Limited by precise prompting | None | None |
| Custom Queries | Supported via "description" key | Possible | Not available | Not applicable |
| Integration Complexity | Moderate (due to structured output) | Low (simple text output) | Low (simple text output) | Low (simple text output) |
| Scalability | High (designed for large-scale data processing) | Medium (depends on backend) | Medium (depends on backend) | High (simple text extraction) |
tagIn Conclusion
SceneXplain's Image-to-JSON isn't just an incremental improvement; it's a monumental leap. By offering unparalleled flexibility and precision, we're empowering users to extract the exact insights they seek from images. As we continue our innovation journey, we eagerly await the myriad ways you'll employ this feature to redefine visual comprehension.
Stay connected for more groundbreaking updates from SceneXplain!






