


With neural search seeing rapid adoption, more people are looking at using it for indexing and searching through their unstructured data. I know several folks already building PDF search engines powered by AI, so I figured I’d give it a stab too. How hard could it possibly be?
The answer: very.
This will be part 1 of 3 posts that walk you through creating a PDF neural search engine using Python:
- In this post we’ll cover how to extract the images and text from PDFs, process them, and store them in a sane way.
- For the next post we’ll look at feeding these into CLIP, a deep learning model that “understands” text and images. After extracting our PDF’s text and images, CLIP will generate a semantically-useful index that we can search by giving it an image or text as input (and it’ll understand the input semantically, not just match keywords or pixels).
- Next we’ll look at how to search through that index using a client and Streamlit frontend.
- Finally we’ll look at some other useful tasks, like extracting metadata.
This is just a rough and ready roadmap — so stay tuned to see how things really pan out.

tagUse case
I want to build a search engine for a dataset of arbitrary PDFs. A user can type in text or upload an image, and the search engine will return similar images and text snippets, with a link to the original PDF they came from.
Looking back, “arbitrary” might be where things started to go wrong. Because arbitrary can be pretty broad when it comes to PDFs:
tagHow hard can it be though?
If we’re just talking using a model to index text and images? Not very.
If we’re talking actually getting the data out of the PDFs and into a usable format? Ohhhh boy…
I mean the spec is only 900-something pages long:
As anyone who’s spent any time in data science knows, wrangling the data into a usable state is 90% of the job. So that’s what we’ll focus on in this post. In future posts we’ll look at how to actually search through that data.
tagOur tech stack
Since this task is a whole search pipeline that deals with different kinds of data, we’ll use some specialist tools to get this done
 jina-aijina-ai
jina-aijina-ai
We may throw in a few others tools along the way for certain processing tasks, but the ones above are the big three.
tagSo, how could we do this?
Off the top of my head…
- Take a PDF file and use Jina Hub’s PDFSegmenter to extract the text and images into chunks.
- Screenshot every page of the PDF with ImageMagick and OCR it.
- Convert the PDF to HTML using something like Pandoc , extracting images to a directory and then converting the HTML to text using Pandoc again. Or something like this with similar tools.
I went with the first option since I didn’t want to shave too many yaks.
tagGetting our PDF
First, we need a sample file. Let’s just print-to-PDF an entry from Wikipedia, in this case the “Rabbit” article:
You can find the resulting PDF here.
Footguns
A footgun is a thing that will shoot you in the foot. Rest assured you will find many of them when you attempt to work with PDFs. These ones just involve generating a PDF to work with!
- Firefox and Chrome create PDFs that are slightly different. In my experience Firefox tried to be fancy about glyphs, turning
scientificintoscientific. I’ve got enough potential PDF headaches to last a lifetime, so to be safe I used the Chrome version. YMMV. - Headers, footers, etc should be disabled, otherwise our index will be full of
page 4/798and similar. - Maybe try changing the paper size to avoid page breaks?
Of course, for your own use case you may be searching PDFs you didn’t create yourself. Be sure to let us know your own personal footgun collection!
tagExtracting text and images
Now that we have our PDF, we can run it through a Jina Flow (using a Hub Executor) to extract our data. A Flow refers to a pipeline in Jina that performs a “big” task, like building up a searchable index of our PDF documents, or searching through said index.
Each Flow is made up of several Executors, each of which perform a simpler task. These are chained together, so any Document fed into one end will be processed by each Executor in turn and then the processed version will pop out of the other end.
In our Flow we’ll start with just one Executor, PDFSegmenter, which we’ll pull from Jina Hub. With Jina Sandbox we can even run it in the cloud so we don’t have to use local compute:
from docarray import DocumentArray
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", install_requirements=True, name="segmenter")
)
with flow:
indexed_docs = flow.index(docs)We’ll feed in our PDFs in the form of a DocumentArray. In Jina, each piece of data (be it text, image, PDF file, or whatever) is a Document, and a DocumentArray is just a container for these. We’ll use DocumentArray.from_files() so we can just auto-load everything from one directory.
After feeding our DocumentArray into the Flow we’ll have the processed DocumentArray stored in indexed_docs .
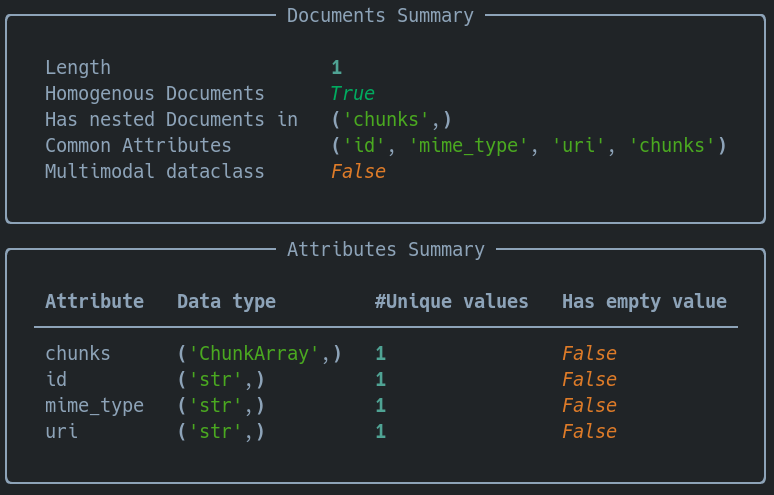
indexed_docs contains just one Document (based on rabbit.pdf), containing text chunks and image chunks:

Let’s take a look at the summary of that DocumentArray with indexed_docs.summary() :
And now let’s check out some of those chunks with indexed_docs[0].chunks.summary() :
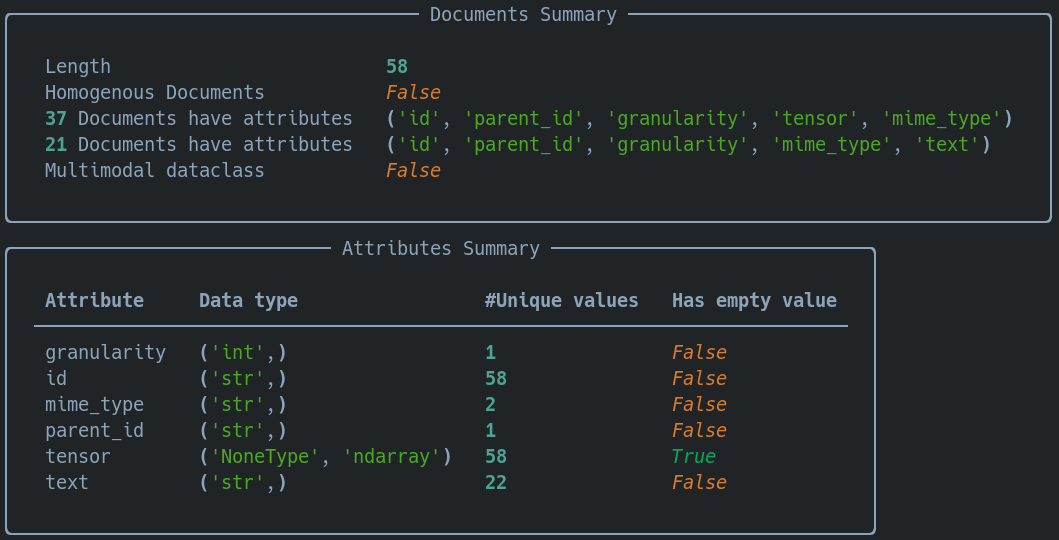
We can see our Document has 58 chunks, some of which have tensors (so are images) and some which have strings (so are text)
Let’s dig a little deeper and print out chunk.content for each chunk :
chunks = indexed_docs[0].chunks
for chunk in chunks:
print(chunk.content)We can see the images are tensors:
[[184. 193. 188.]
[163. 174. 158.] // fix this. it's not full tensor
[150. 162. 140.]
...
[ 43. 42. 24.]
[ 41. 40. 22.]
[ 41. 38. 23.]]And the text is just several normal (very long) text strings. Here’s just one single string for reference:
See also
References
Notes
Citations
Further reading
External links
Terminology and etymology
Male rabbits are called bucks; females are called does. An older term for an adult rabbit used until the 18th
century is coney (derived ultimately from the Latin cuniculus), while rabbit once referred only to the young
[2]
animals. Another term for a young rabbit is bunny, though this term is often applied informally
(particularly by children) to rabbits generally, especially domestic ones. More recently, the term kit or kitten
has been used to refer to a young rabbit.
A group of rabbits is known as a colony or nest (or, occasionally, a warren, though this more commonly
[3]
refers to where the rabbits live). A group of baby rabbits produced from a single mating is referred to as a
[4] [5]
litter and a group of domestic rabbits living together is sometimes called a herd.
The word rabbit itself derives from the Middle English rabet, a borrowing from the Walloon robète, which
[6]
was a diminutive of the French or Middle Dutch robbe.
Taxonomy
Rabbits and hares were formerly classified in the order Rodentia (rodent) until 1912, when they were moved
into a new order, Lagomorpha (which also includes pikas). Below are some of the genera and species of the
rabbit.Phew! That’s a pretty long string. Guess we’ll need to do a bit of work on it.
tagProcessing our data
If we want to search our data, we’ll need to do some processing first:
- For text segments, break them down into smaller chunks, like sentences. Right now our long strings contain so many concepts that they’re not semantically very meaningful. By sentencizing we can derive a clear semantic meaning from each chunk of text.
- For images, resize and normalize them so we can encode them with our deep learning model later.
Sentencizing our text
Before we sentencize our whole dataset, let’s just test some assumptions. Because you know what they say about assuming…
We all know a sentence when we see one: slam a few words together, put a certain kind of punctuation mark at the end, and bam, sentence:
- It was a dark and stormy night.
- What do a raven and a writing desk have in common?
- Turn to p.13 to read about J.R.R. Tolkien pinging google.com in 3.4 seconds.
If we take Jina Hub’s Sentencizer Executor and run these strings through it. We’d expect to get one sentence back for each string, right?
from docarray import DocumentArray, Document
from jina import Executor
docs = DocumentArray(
[
Document(text="It was a dark and stormy night."),
Document(text="What do a raven and a writing desk have in common?"),
Document(text="Turn to p.13 to read about J.R.R. Tolkien pinging google.com in 3.4 seconds")
]
)
exec = Executor.from_hub("jinahub://Sentencizer")
exec.segment(docs, parameters={})
for doc in docs:
for chunk in doc.chunks:
print(chunk.text)
print("---")So, given three sentences as input, we should get three sentences as output:It was a dark and stormy night.
It was a dark and stormy night.
---
What do a raven and a writing desk have in common?
---
Turn to p.
13 to read about J.
R.
R.
Tolkien pinging google.
com in 3.
4 seconds.
---Damn. That’s 1+1+7. Not the 3 we were hoping for. Looks like Sentencizer is a bit of a footgun. Turns out that a full stop/period doesn’t always end a sentence.
We have two approaches moving forwards:
- Admit that this language thing was a mistake for humanity and just head back to the trees.
- Use a less naive sentencizer.
As temping as option one is, let’s just use a better sentencizer. For this, I wrote SpacySentencizer (an Executor that integrates spaCy’s sentencizer into Jina). It’s barely tested, and all the options are hardcoded, but it does a slightly better job. We just need to change line 12 of our code:
from docarray import DocumentArray, Document
from jina import Executor
docs = DocumentArray(
[
Document(text="It was a dark and stormy night."),
Document(text="What do a raven and a writing desk have in common?"),
Document(text="Turn to p.13 to read about J.R.R. Tolkien pinging google.com in 3.4 seconds")
]
)
exec = Executor.from_hub("jinahub://SpacySentencizer")
exec.segment(docs, parameters={})
for doc in docs:
for chunk in doc.chunks:
print(chunk.text)
print("---")And now let’s see the results:It was a dark and stormy night.
It was a dark and stormy night.
---
What do a raven and a writing desk have in common?
---
Turn to p.13 to read about J.R.R. Tolkien pinging google.com in 3.4 seconds
---Hooray! 3 sentences!
As I said, SpacySentencizer is still really rough and ready (that’s on me, not on spaCy). In a future post I may go into how to improve it, but if you want to un-hardcode some options or just optimize it, PRs are more than welcome!
alexcg1Let’s integrate it into our Flow. Since we only want to sentencize our Document’s chunks, and not the Document itself, I wrapped my SpacySentencizer in another Executor (in an ideal world I’d add a traversal_path parameter, but I just want to get the job done and not become a professional yak stylist.)
Let’s add that Executor to the Flow:
from docarray import DocumentArray
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", install_requirements=True, name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
)
with flow:
indexed_docs = flow.index(docs)tagProcessing our images
Before we can feed our images into a deep learning model, we need to do some pre-processing to ensure they’re all the same shape. Let’s write our own Executor to do just that:
from jina import Executor, requests
import numpy as np
class ImageNormalizer(Executor):
@requests(on="/index")
def normalize_chunks(self, docs, **kwargs):
for doc in docs:
for chunk in doc.chunks[...]:
if chunk.blob:
chunk.convert_blob_to_image_tensor()
if hasattr(chunk, "tensor"):
if chunk.tensor is not None:
chunk.convert_image_tensor_to_uri()
chunk.tags["image_datauri"] = chunk.uri
chunk.tensor = chunk.tensor.astype(np.uint8)
chunk.set_image_tensor_shape((64, 64))
chunk.set_image_tensor_normalization()- 1–6: General Executor boilerplate. On line 5 we’re telling our Executor to process Documents only when the
indexendpoint is called. Otherwise it’ll do nothing. - 8: with
[...]we enable recursion, so every chunk, chunk of chunk, chunk of chunk of chunk, etc, will be processed. Our chunkage isn’t that deep in this case, but it doesn’t take much effort to add[...], and it makes it useful if we do further chunkage in future. - 9: If we have a
blob, convert it to a tensor. This is the data structure expected by the CLIP encoder which we’ll look at in a future post. - 12–18: Assuming we have the tensor, add the
datauriof the unprocessed tensor to our metadata (a.k.atags) so we can retrieve it later and show the image in our frontend. Then apply various transformations to ensure all tensors are consistent and ready to go into the encoder.
As you can see, we’re adding several checks to ensure our Executor doesn’t choke on text Documents. Likewise I put checks in our sentencizing Executor to stop it meddling with image chunks.
Again, we’ll add it to the Flow:
from docarray import DocumentArray
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", install_requirements=True, name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ImageNormalizer, name="image_normalizer")
)
with flow:
indexed_docs = flow.index(docs)tagWhat do we have so far?
To recap:
- We started with a single PDF.
- We split that PDF into text chunks and image chunks.
- We then further split the text chunks into sentences (stored as chunks of chunks).
- We normalized our images.
That gives us something like the following:
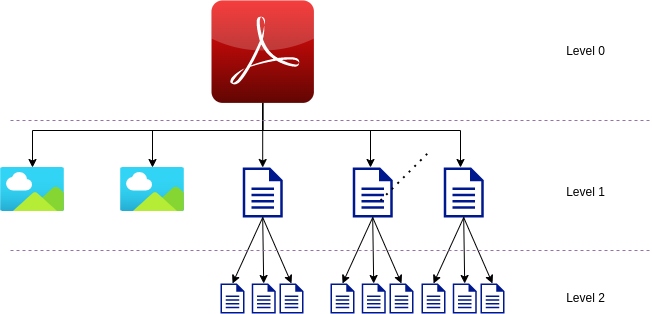
That’s great, but it’d be nice to have all the chunks in one level. We can do that with — you guessed it — another Executor. This one, ChunkMerger, is dead simple though:
from jina import Executor, requests
import numpy as np
class ImageNormalizer(Executor):
@requests(on="/index")
def normalize_chunks(self, docs, **kwargs):
...
class ChunkMerger(Executor):
@requests(on="/index")
def merge_chunks(self, docs, **kwargs):
for doc in docs: # level 0 document
for chunk in doc.chunks:
if doc.text:
docs.pop(chunk.id)
doc.chunks = doc.chunks[...]This code simply:
pops the level-1 text chunks of each Document (i.e. the really long passages of text), not touching level-1 image chunks.- Assigns the Document’s level 1 chunks to all chunks from the Document (minus the ones we popped), using
[...]for recursion.
The result? All of our text and image chunks on one level.
We can put that in our Flow straight after the sentencizer (because let’s keep all of our text processing together):
from docarray import DocumentArray
from executors import ChunkSentencizer, ChunkMerger, ImageNormalizer
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", install_requirements=True, name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ChunkMerger, name="chunk_merger")
.add(uses=ImageNormalizer, name="image_normalizer")
)
with flow:
indexed_docs = flow.index(docs)tagNext steps
In the next post we’ll add an encoder to our Flow, which will use CLIP to encode our text and images into embeddings in a shared vector space, thus allowing easy semantic search to happen.







