



В наших предыдущих постах мы исследовали проблемы чанкинга и представили концепцию позднего чанкинга, который помогает уменьшить потерю контекста при встраивании чанков. В этом посте мы сосредоточимся на другой проблеме: поиске оптимальных точек разбиения. Хотя наша стратегия позднего чанкинга доказала свою устойчивость к плохим границам, это не значит, что мы можем их игнорировать — они по-прежнему важны как для человеческой читаемости, так и для читаемости LLM. Наша точка зрения такова: при определении точек разбиения мы теперь можем полностью сосредоточиться на читаемости, не беспокоясь о потере семантики или контекста. Поздний чанкинг может справиться как с хорошими, так и с плохими точками разбиения, поэтому читаемость становится вашей основной заботой.
Учитывая это, мы обучили три малые языковые модели, специально разработанные для сегментации длинных документов с сохранением семантической согласованности и обработкой сложных структур содержимого. Это:

simple-qwen-0.5, которая сегментирует текст на основе структурных элементов документа.

topic-qwen-0.5, которая сегментирует текст на основе тем внутри текста.

summary-qwen-0.5, которая генерирует краткие описания для каждого сегмента.
В этом посте мы обсудим, почему мы разработали эту модель, как мы подошли к её трём вариантам, и как они сравниваются с API Segmenter от Jina AI. В заключение мы поделимся тем, что узнали, и некоторыми мыслями на будущее.
tagПроблема сегментации
Сегментация является ключевым элементом в системах RAG. То, как мы разбиваем длинные документы на связные, управляемые сегменты, напрямую влияет на качество как поиска, так и генерации, воздействуя на всё — от релевантности ответов до качества суммаризации. Традиционные методы сегментации давали неплохие результаты, но не без ограничений.
Перефразируя наш предыдущий пост:
При сегментации длинного документа ключевой проблемой является решение о том, где создавать сегменты. Это можно делать с использованием фиксированной длины токенов, заданного количества предложений или более продвинутых методов, таких как regex и модели семантической сегментации. Установление точных границ сегментов критически важно, так как это не только улучшает читаемость результатов поиска, но и гарантирует, что сегменты, предоставляемые LLM в системе RAG, являются как точными, так и достаточными.
Хотя поздний чанкинг улучшает производительность поиска, в приложениях RAG критически важно обеспечить, чтобы, насколько это возможно, каждый сегмент был осмысленным сам по себе, а не просто случайным фрагментом текста. LLM полагаются на согласованные, хорошо структурированные данные для генерации точных ответов. Если сегменты неполные или лишены смысла, LLM может столкнуться с трудностями в контексте и точности, влияя на общую производительность, несмотря на преимущества позднего чанкинга. Короче говоря, независимо от того, используете ли вы поздний чанкинг или нет, наличие надёжной стратегии сегментации необходимо для построения эффективной системы RAG (как вы увидите в разделе сравнительного анализа ниже).
Традиционные методы сегментации, будь то разбиение контента по простым границам, таким как новые строки или предложения, или использование жёстких правил на основе токенов, часто сталкиваются с одними и теми же ограничениями. Оба подхода не учитывают семантические границы и испытывают трудности с неоднозначными темами, что приводит к фрагментированным сегментам. Чтобы решить эти проблемы, мы разработали и обучили малую языковую модель, специально предназначенную для сегментации, разработанную для определения смены тем и поддержания согласованности, оставаясь при этом эффективной и адаптируемой к различным задачам.
tagПочему малая языковая модель?
Мы разработали малую языковую модель (SLM) для решения конкретных ограничений, с которыми мы столкнулись при использовании традиционных методов сегментации, особенно при обработке фрагментов кода и других сложных структур, таких как таблицы, списки и формулы. В традиционных подходах, которые часто опираются на подсчёт токенов или жёсткие структурные правила, было сложно сохранить целостность семантически согласованного содержимого. Например, фрагменты кода часто разбивались на несколько частей, нарушая их контекст и затрудняя последующим системам их понимание или точное извлечение.
Обучая специализированную SLM, мы стремились создать модель, которая могла бы интеллектуально распознавать и сохранять эти значимые границы, обеспечивая, чтобы связанные элементы оставались вместе. Это не только улучшает качество поиска в системах RAG, но и улучшает последующие задачи, такие как суммаризация и ответы на вопросы, где поддержание согласованных и контекстуально релевантных сегментов является критически важным. Подход SLM предлагает более адаптируемое, специфичное для задачи решение, которое традиционные методы сегментации с их жёсткими границами просто не могут обеспечить.
tagОбучение SLM: три подхода
Мы обучили три версии нашей SLM:
simple-qwen-0.5— самая простая модель, разработанная для определения границ на основе структурных элементов документа. Её простота делает её эффективным решением для базовых потребностей сегментации.topic-qwen-0.5, вдохновлённая рассуждениями Chain-of-Thought, делает шаг вперёд в сегментации, определяя темы внутри текста, такие как "начало Второй мировой войны", и использует эти темы для определения границ сегментов. Эта модель обеспечивает тематическую целостность каждого сегмента, что делает её хорошо подходящей для сложных, многотемных документов. Начальные тесты показали, что она отлично справляется с сегментацией контента способом, близким к человеческой интуиции.summary-qwen-0.5не только определяет границы текста, но и генерирует краткие описания для каждого сегмента. Суммирование сегментов очень выгодно в приложениях RAG, особенно для задач вопросов и ответов по длинным документам, хотя это требует больше данных при обучении.
Все модели возвращают только заголовки сегментов — усечённую версию каждого сегмента. Вместо генерации целых сегментов модели выводят ключевые точки или подтемы, что улучшает определение границ и согласованность, фокусируясь на семантических переходах, а не просто копируя входной контент. При извлечении сегментов текст документа разбивается на основе этих заголовков сегментов, и полные сегменты реконструируются соответственно.
tagНабор данных
Мы использовали набор данных wiki727k, большую коллекцию структурированных текстовых фрагментов, извлечённых из статей Википедии. Он содержит более 727 000 разделов текста, каждый из которых представляет собой отдельную часть статьи Википедии, такую как введение, раздел или подраздел.
 koomri
koomritagАугментация данных
Для создания обучающих пар для каждого варианта модели мы использовали GPT-4 для аугментации данных. Для каждой статьи в нашем обучающем наборе данных мы отправляли следующий промпт:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()Мы использовали простое разделение для создания секций из каждой статьи, разделяя по \\n\\n\\n, а затем подразделяя по \\n\\n, чтобы получить следующее (в данном случае статья о Common Gateway Interface):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
Затем мы сгенерировали структуру JSON с секциями, темами и краткими описаниями:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface в веб-серверах",
"История и стандартизация CGI",
"CGI-скрипты для редактирования веб-страниц",
"Снижение нагрузки на веб-сервер при вызове команд"
],
"summaries": [
"CGI предоставляет протокол для веб-серверов для запуска программ, генерирующих динамические веб-страницы.",
"NCSA изначально определила CGI в 1993 году, что привело к его принятию в качестве стандарта для веб-серверов и последующей формализации в RFC 3875 под председательством Ken Coar.",
"Этот текст описывает, как CGI-скрипт может обрабатывать редактирование и сохранение содержимого веб-страниц через HTML-формы.",
"В тексте обсуждаются методы минимизации нагрузки на сервер при частом вызове команд, включая предварительное создание процессов, использование предварительно скомпилированных CGI-программ и внедрение пользовательских модулей веб-сервера."
]
}
Мы также добавили шум путем перемешивания данных, добавления случайных символов/слов/букв, случайного удаления пунктуации и всегда удаляли символы новой строки.
Все это может частично помочь в разработке хорошей модели, но только до определенной степени. Чтобы действительно раскрыть весь потенциал, нам нужно было, чтобы модель создавала согласованные фрагменты, не нарушая фрагменты кода. Для этого мы дополнили набор данных кодом, формулами и списками, сгенерированными GPT-4o.
tagНастройка обучения
Для обучения моделей мы реализовали следующую настройку:
- Framework: Мы использовали библиотеку
transformersот Hugging Face, интегрированную сUnslothдля оптимизации модели. Это было crucial для оптимизации использования памяти и ускорения обучения, что позволило эффективно обучать маленькие модели на больших наборах данных. - Optimizer and Scheduler: Мы использовали оптимизатор AdamW с линейным графиком скорости обучения и шагами разогрева, что позволило стабилизировать процесс обучения в начальные эпохи.
- Отслеживание экспериментов: Мы отслеживали все эксперименты по обучению с помощью Weights & Biases и регистрировали ключевые метрики, такие как потери при обучении и валидации, изменения скорости обучения и общую производительность модели. Это отслеживание в реальном времени дало нам представление о том, как прогрессируют модели, позволяя быстро вносить коррективы при необходимости для оптимизации результатов обучения.
tagСамо обучение
Используя qwen2-0.5b-instruct в качестве базовой модели, мы обучили три варианта нашей SLM с помощью Unsloth, каждый с разной стратегией сегментации. Для наших образцов мы использовали пары для обучения, состоящие из текста статьи из wiki727k и полученных sections, topics или summaries (упомянутых выше в разделе "Дополнение данных") в зависимости от обучаемой модели.
simple-qwen-0.5: Мы обучилиsimple-qwen-0.5на 10 000 образцах с 5 000 шагов, достигнув быстрой сходимости и эффективного обнаружения границ между связными разделами текста. Потери при обучении составили 0,16.topic-qwen-0.5: Как иsimple-qwen-0.5, мы обучилиtopic-qwen-0.5на 10 000 образцах с 5 000 шагов, достигнув потерь при обучении 0,45.summary-qwen-0.5: Мы обучилиsummary-qwen-0.5на 30 000 образцах с 15 000 шагов. Эта модель показала перспективы, но имела более высокие потери (0,81) во время обучения, что говорит о необходимости большего количества данных (примерно вдвое больше нашего исходного количества образцов) для достижения полного потенциала.
tagСами сегменты
Вот примеры трех последовательных сегментов для каждой стратегии сегментации, вместе с Jina's Segmenter API. Чтобы получить эти сегменты, мы сначала использовали Jina Reader для извлечения поста из блога Jina AI в виде простого текста (включая все данные страницы, такие как заголовки, нижние колонтитулы и т. д.), затем передали его каждому методу сегментации.

tagJina Segmenter API
Jina Segmenter API применил очень детальный подход к сегментации поста, разделяя текст по символам вроде \n, \t и т.д., чтобы разбить текст на часто очень маленькие сегменты. Рассматривая только первые три, он извлек search\\n, notifications\\n и NEWS\\n из навигационной панели сайта, но ничего относящегося к содержанию самого поста:

Далее мы наконец получили некоторые сегменты из фактического содержания блог-поста, хотя в каждом сохранялось мало контекста:

(В интересах справедливости мы показали больше фрагментов для Segmenter API, чем для моделей, просто потому, что иначе было бы очень мало значимых сегментов для показа)
tagsimple-qwen-0.5
simple-qwen-0.5 разбил блог-пост на основе семантической структуры, извлекая гораздо более длинные сегменты, имеющие связное значение:
tagtopic-qwen-0.5
topic-qwen-0.5 сначала определил темы на основе содержания документа, затем сегментировал документ на основе этих тем:
tagsummary-qwen-0.5
summary-qwen-0.5 определил границы сегментов и сгенерировал краткое содержание контента внутри каждого сегмента:
tagТестирование моделей
Для оценки производительности наших моделей мы извлекли восемь блог-постов из блога Jina AI и сгенерировали шесть вопросов и правильных ответов с помощью GPT-4o.
Мы применили каждый метод сегментации, включая Jina Segmenter API, к этим блог-постам, а затем сгенерировали эмбеддинги для получившихся сегментов с помощью jina-embeddings-v3, без позднего разбиения или переранжирования.

Затем каждый набор сегментов был проиндексирован отдельно, и мы использовали систему RAG для запроса к каждому индексу с помощью ранее сгенерированных вопросов.
topic-qwen-0.5 и summary-qwen-0.5 мы индексировали только сами сегменты, а не сгенерированные саммари или темы. Индексация этих дополнительных данных, вероятно, еще больше улучшила бы производительность.Для измерения производительности мы сравнили ответы, сгенерированные из индекса каждого метода сегментации, с эталонными ответами, используя F1-оценки из ROUGE-L evaluation, где более высокие оценки указывают на лучшую производительность.
Например, на вопрос: "Какие факторы влияют на способности числового сравнения модели jina-embeddings-v2-base-en?", мы получили следующие ответы:
tagЭталонный ответ (Сгенерирован GPT-4o из полного текста поста):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API (оценка: 0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5 (оценка: 0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5 (оценка: 0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5 (0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5 такая низкая оценка?Это в основном случайность, основанная на конкретном вопросе, который мы задали модели. Как видно из таблицы ниже, средняя оценка ROUGE для
topic-qwen-0.5 является самой высокой среди всех методологий сегментации.Мы также оценили скорость каждого метода (измеряя время, необходимое как для генерации, так и для встраивания сегментов) и оценили дисковое пространство (умножая количество эмбеддингов на размер одного 1024-мерного эмбеддинга из jina-embeddings-v3). Это позволило нам оценить как точность, так и эффективность различных стратегий сегментации.
tagКлючевые выводы
После тестирования вариантов моделей друг против друга и Jina Segmenter API мы обнаружили, что новые модели действительно показали улучшенные результаты при использовании всех трех методов, особенно тематической сегментации:
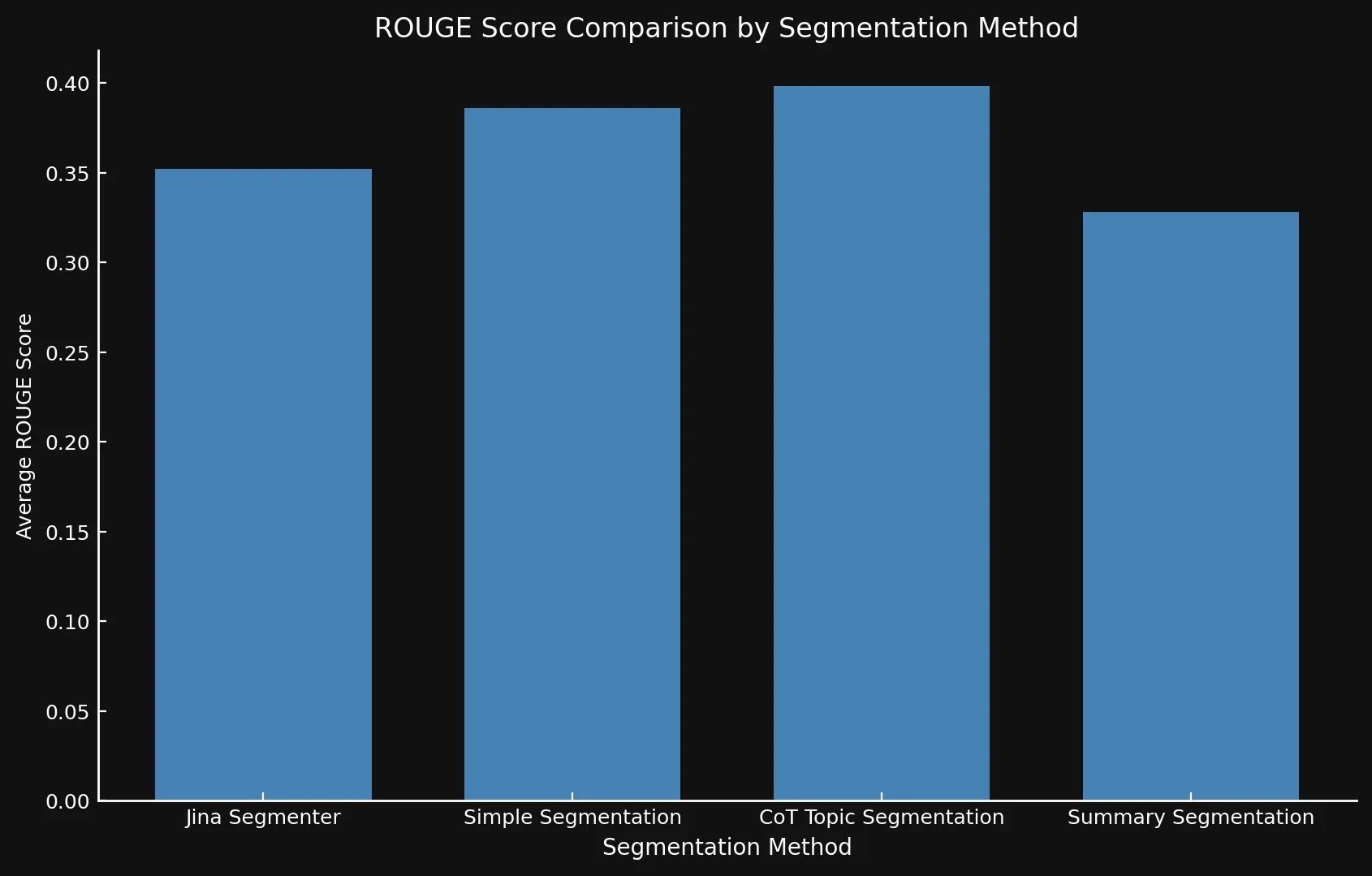
| Segmentation Method | Average ROUGE Score |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 оценка ROUGE ниже, чем у topic-qwen-0.5? Если коротко, summary-qwen-0.5 показала более высокую потерю во время обучения, что указывает на необходимость дополнительного обучения для получения лучших результатов. Это может быть темой для будущих экспериментов.Однако было бы интересно рассмотреть результаты с функцией позднего разбиения jina-embeddings-v3, которая повышает контекстную релевантность эмбеддингов сегментов, обеспечивая более релевантные результаты. Это может быть темой для будущего блог-поста.
Что касается скорости, сложно сравнивать новые модели с Jina Segmenter, поскольку последний является API, в то время как мы запускали три модели на GPU Nvidia 3090. Как видно, любой выигрыш в производительности во время быстрого этапа сегментации API Segmenter быстро нивелируется необходимостью генерировать эмбеддинги для такого большого количества сегментов:
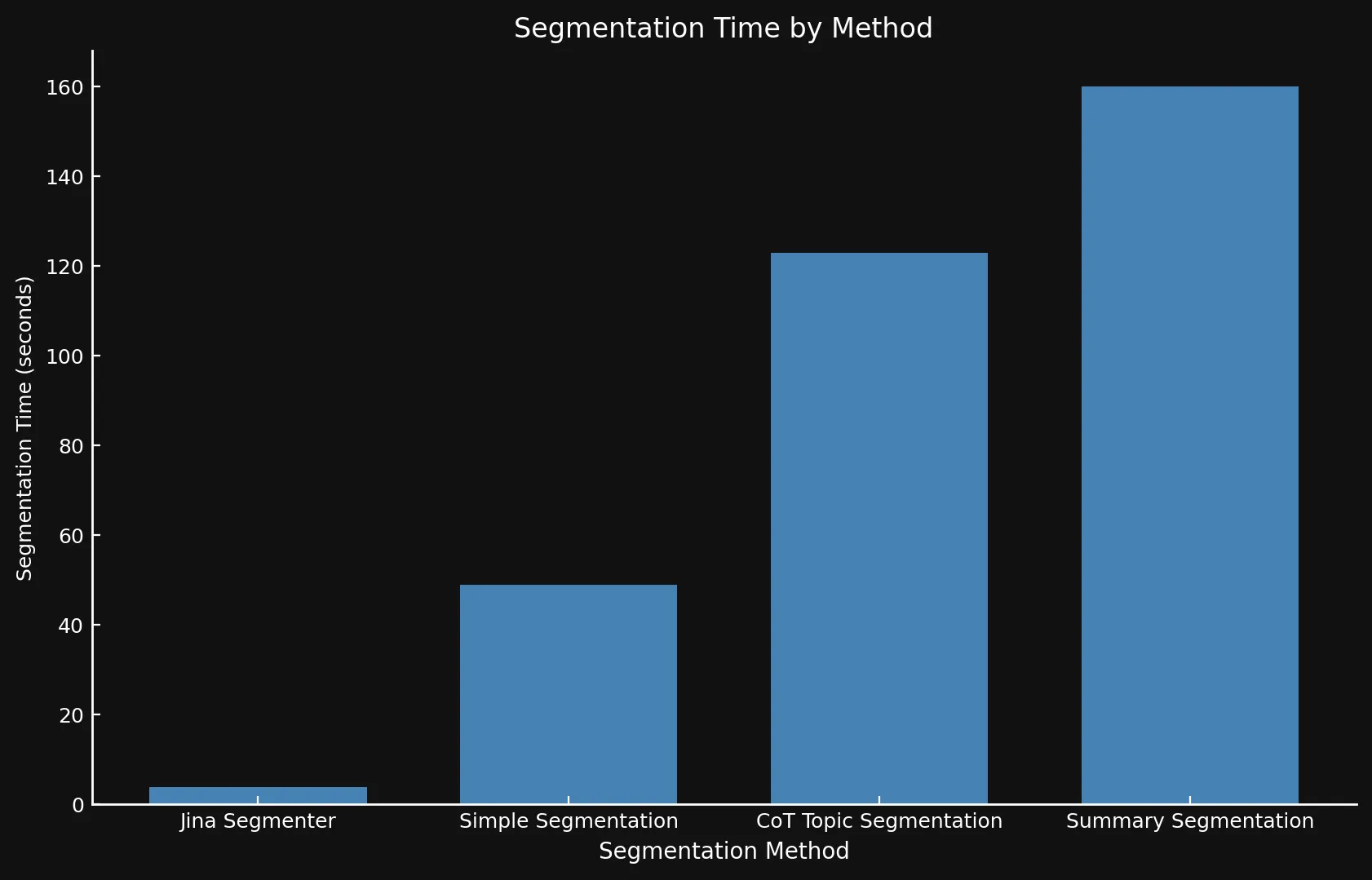
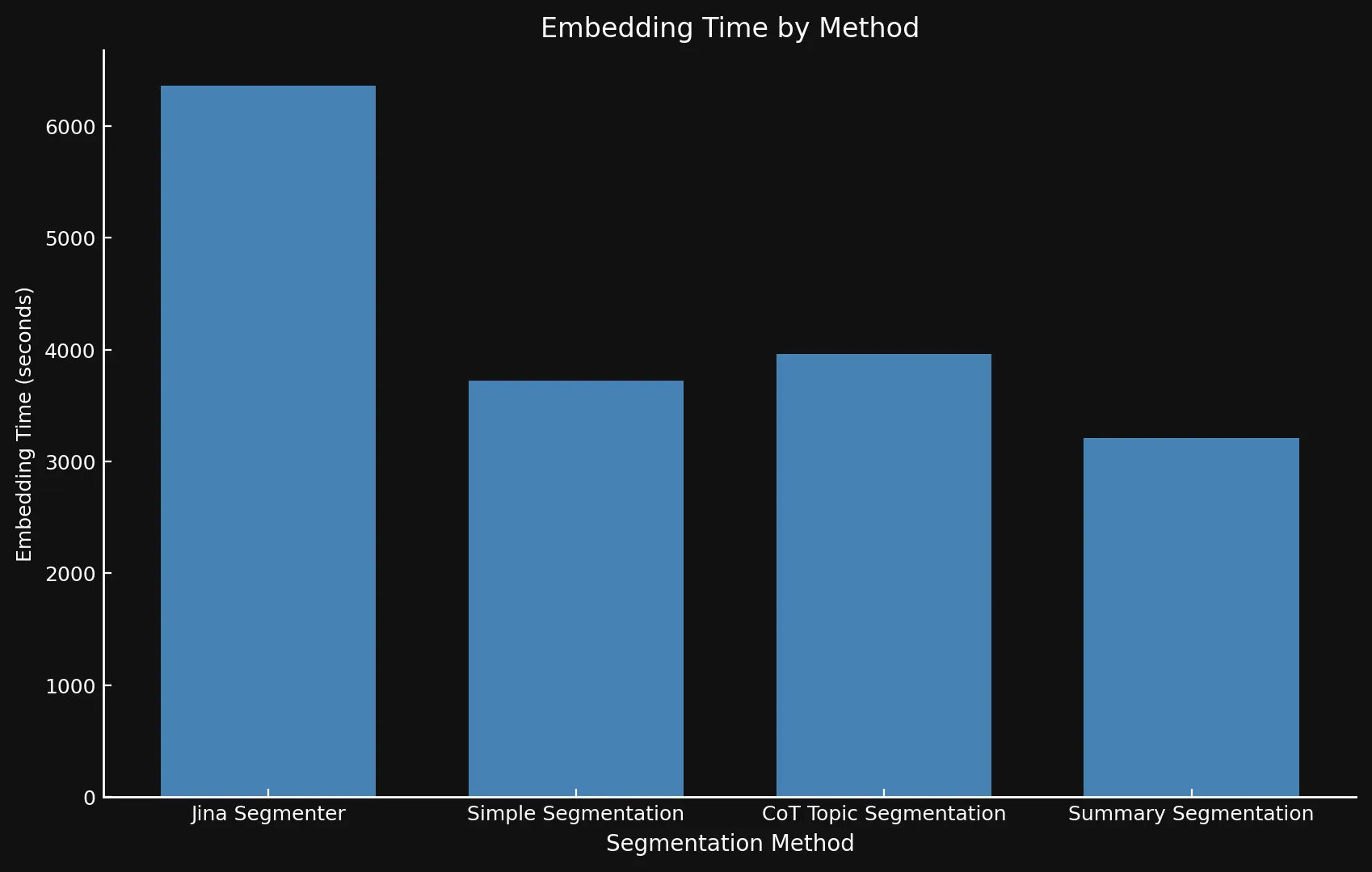
• Мы используем разные оси Y на обоих графиках, поскольку представление таких разных временных рамок на одном графике или с согласованными осями Y было бы нецелесообразным.
• Поскольку мы проводили это исключительно в качестве эксперимента, мы не использовали пакетную обработку при генерации эмбеддингов. Использование пакетной обработки существенно ускорило бы операции для всех методов.
Естественно, больше сегментов означает больше эмбеддингов. И эти эмбеддинги занимают много места: эмбеддинги для восьми блог-постов, которые мы тестировали, заняли более 21 МБ с Segmenter API, в то время как Summary Segmentation уместился в изящные 468 КБ. Это, плюс более высокие оценки ROUGE от наших моделей, означает меньше сегментов, но лучшие сегменты, экономя деньги и повышая производительность:
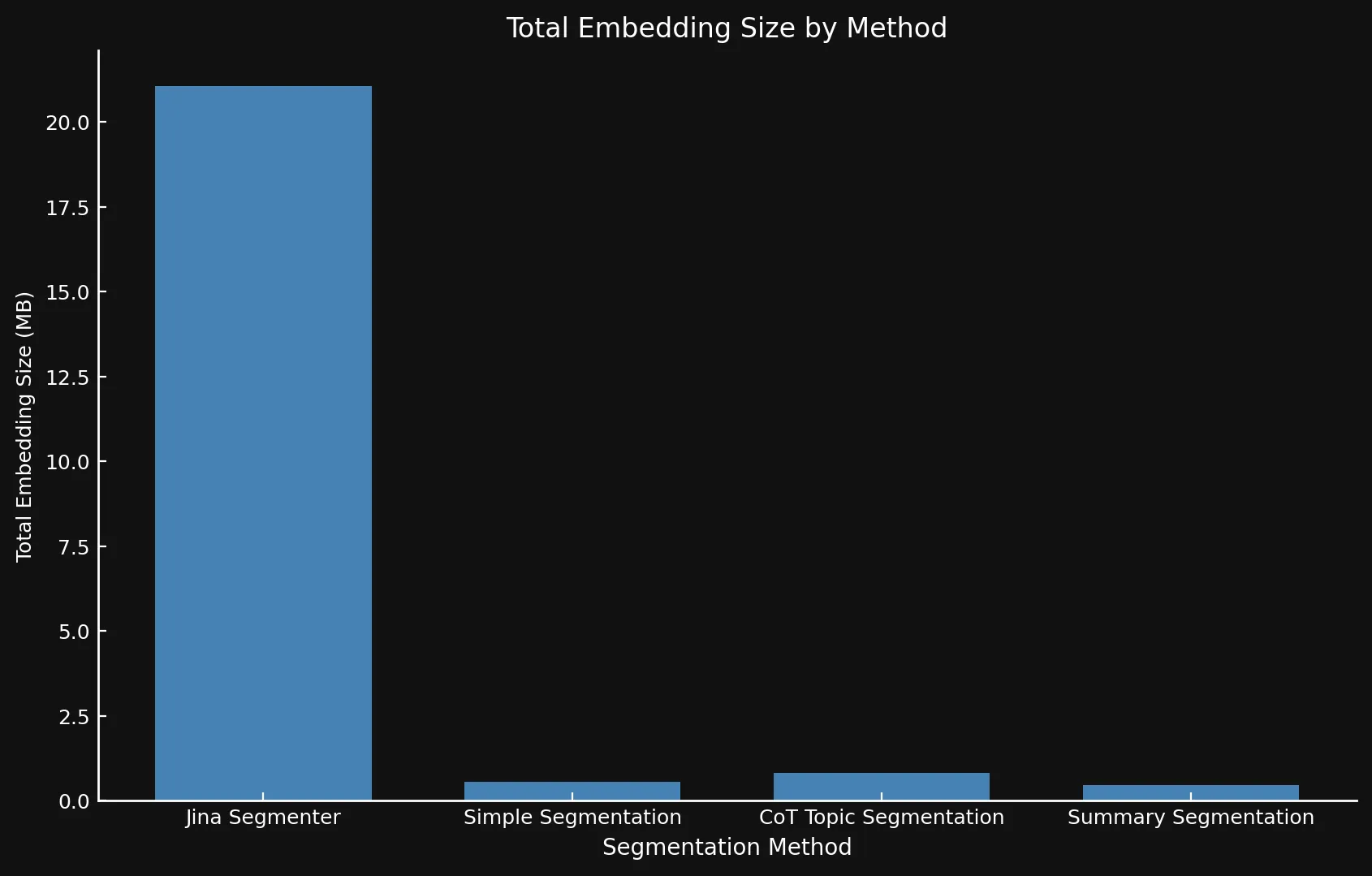
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tagЧто мы узнали
tagФормулировка задачи имеет решающее значение
Одним из ключевых выводов стало влияние того, как мы сформулировали задачу. Заставив модель выводить заголовки сегментов, мы улучшили определение границ и согласованность, сосредоточившись на семантических переходах, а не просто копируя входной контент в отдельные сегменты. Это также привело к более быстрой модели сегментации, поскольку генерация меньшего объема текста позволила модели быстрее выполнить задачу.
tagДанные, сгенерированные LLM, эффективны
Использование данных, сгенерированных LLM, особенно для сложного контента, такого как списки, формулы и фрагменты кода, расширило обучающий набор модели и улучшило ее способность обрабатывать различные структуры документов. Это сделало модель более адаптивной к различным типам контента, что является crucial преимуществом при работе с техническими или структурированными документами.
tagСбор данных только для вывода
Используя коллатор данных только для вывода, мы обеспечили фокусировку модели на предсказании целевых токенов во время обучения, а не просто копировании из входных данных. Коллатор только для вывода гарантировал, что модель учится на фактических целевых последовательностях, подчеркивая правильные завершения или границы. Это различие позволило модели быстрее сходиться, избегая переобучения на входных данных, и помогло ей лучше обобщать на разных наборах данных.
tagЭффективное обучение с Unsloth
С помощью Unsloth мы оптимизировали обучение нашей небольшой языковой модели, сумев запустить ее на GPU Nvidia 4090. Этот оптимизированный конвейер позволил нам обучить эффективную, производительную модель без необходимости в массивных вычислительных ресурсах.
tagОбработка сложных текстов
Модели сегментации отлично справились с обработкой сложных документов, содержащих код, таблицы и списки, которые обычно сложны для более традиционных методов. Для технического контента более сложные стратегии, такие как topic-qwen-0.5 и summary-qwen-0.5, оказались более эффективными, с потенциалом улучшения последующих задач RAG.
tagПростые методы для простого контента
Для простого, повествовательного контента часто достаточно более простых методов, таких как Segmenter API. Продвинутые стратегии сегментации могут быть необходимы только для более сложного, структурированного контента, что обеспечивает гибкость в зависимости от конкретного случая использования.
tagСледующие шаги
Хотя этот эксперимент был разработан в первую очередь как proof of concept, если бы мы хотели его расширить, мы могли бы внести несколько улучшений. Во-первых, хотя продолжение этого конкретного эксперимента маловероятно, обучение summary-qwen-0.5 на большем наборе данных — в идеале 60 000 образцов вместо 30 000 — вероятно, привело бы к более оптимальной производительности. Кроме того, было бы полезно усовершенствовать наш процесс тестирования. Вместо оценки ответов, сгенерированных LLM из системы RAG, мы бы сосредоточились на сравнении извлеченных сегментов непосредственно с эталонными данными. Наконец, мы бы вышли за рамки оценок ROUGE и приняли более продвинутые метрики (возможно, комбинацию ROUGE и оценки LLM), которые лучше отражают нюансы качества извлечения и сегментации.
tagЗаключение
В этом эксперименте мы исследовали, как пользовательские модели сегментации, разработанные для конкретных задач, могут улучшить производительность RAG. Разрабатывая и обучая модели, такие как simple-qwen-0.5, topic-qwen-0.5 и summary-qwen-0.5, мы решили ключевые проблемы, встречающиеся в традиционных методах сегментации, особенно в отношении поддержания семантической согласованности и эффективной обработки сложного контента, такого как фрагменты кода. Среди протестированных моделей topic-qwen-0.5 последовательно обеспечивала наиболее осмысленную и контекстуально релевантную сегментацию, особенно для документов с несколькими темами.
В то время как модели сегментации обеспечивают структурную основу, необходимую для систем RAG, они выполняют другую функцию по сравнению с поздней фрагментацией, которая оптимизирует производительность извлечения, поддерживая контекстуальную релевантность между сегментами. Эти два подхода могут быть взаимодополняющими, но сегментация особенно важна, когда требуется метод, который фокусируется на разделении документов для согласованных рабочих процессов генерации, специфичных для конкретных задач.
