


Трудно сказать, люди ненавидят любить RAG или любят ненавидеть RAG.
Согласно недавним обсуждениям в X и HN, RAG должен быть мертв, снова. На этот раз критики сосредоточены на чрезмерном усложнении большинства RAG-фреймворков, которое, как показали @jeremyphoward @HamelHusain @Yampeleg, можно реализовать всего 20 строками Python-кода.
В последний раз такие настроения были вскоре после выпуска Claude/Gemini с супердлинным контекстным окном. Что делает эту ситуацию хуже — даже RAG от Google генерирует забавные результаты, как показали @icreatelife @mark_riedl, что иронично, поскольку в апреле на Google Next в Лас-Вегасе Google представил RAG как решение для заземления.
tagДве проблемы RAG
Я вижу две проблемы с RAG-фреймворками и решениями, которые у нас есть сегодня.
tagТолько прямая передача
Во-первых, практически все RAG-фреймворки реализуют только путь "прямой передачи" и не имеют пути "обратного распространения". Это неполная система. Я помню, как @swyx в одном из эпизодов @latentspacepod утверждал, что RAG не будет убит длинным контекстным окном LLM, поскольку:
- длинный контекст дорог для разработчиков и
- длинный контекст сложно отлаживать и ему не хватает декомпозируемости.
Но если все RAG-фреймворки фокусируются только на пути вперед, как это проще отлаживать, чем LLM? Также интересно, как много людей чрезмерно восхищаются автоматическими результатами RAG из случайных POC и полностью забывают, что добавление дополнительных прямых слоев без обратной настройки — это ужасная идея. Мы все знаем, что добавление еще одного слоя в нейронные сети расширяет их параметрическое пространство и, следовательно, способность к представлению, позволяя делать больше потенциальных вещей, но без обучения это ничто. Есть несколько стартапов в Bay Area, работающих над оценкой — по сути, пытающихся оценить потери системы прямой передачи. Это полезно? Да. Но помогает ли это замкнуть цикл RAG? Нет.
Так кто же работает над обратным распространением RAG? Насколько мне известно, немногие. Я в основном знаком с DSPy, библиотекой от @stanfordnlp @lateinteraction, которая ставит перед собой такую миссию.
 stanfordnlp
stanfordnlpНо даже для DSPy основное внимание уделяется оптимизации few-shot демонстраций, а не всей системы (по крайней мере, судя по использованию сообществом). Но почему эта проблема сложна? Потому что сигнал очень разреженный, а оптимизация недифференцируемой системы по сути является комбинаторной проблемой — другими словами, крайне сложной. Во время PhD я изучал субмодулярную оптимизацию, и у меня есть ощущение, что эта техника найдет хорошее применение в оптимизации RAG.
tagЗаземление в реальных условиях сложно
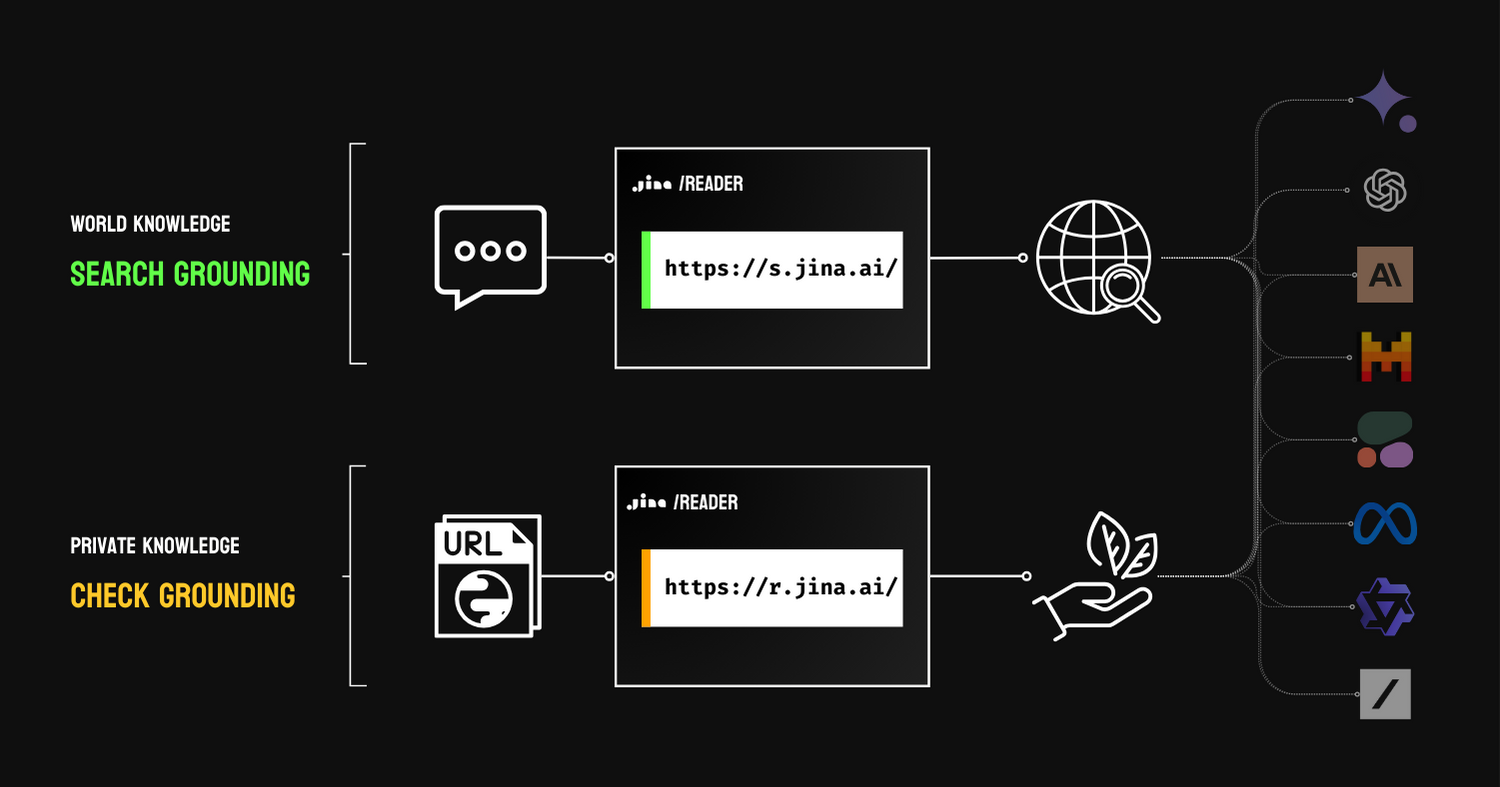
Я согласен, что RAG предназначен для заземления, несмотря на забавные результаты поиска от Google. Существует два типа заземления: поисковое заземление, которое использует поисковые системы для расширения мировых знаний LLM, и проверочное заземление, которое использует частные знания (например, проприетарные данные) для проверки фактов.
В обоих случаях оно цитирует внешние знания для улучшения фактической точности результата, при условии, что эти внешние ресурсы заслуживают доверия. В забавных результатах поиска Google легко увидеть, что не всему в интернете можно доверять (да, большой сюрприз, кто бы мог подумать!), что делает поисковое заземление неэффективным. Но я верю, что над этим можно только посмеяться сейчас. За пользовательским интерфейсом Google Search есть некоторые неявные механизмы обратной связи, которые собирают реакции пользователей на эти результаты и взвешивают достоверность сайта для лучшего заземления. В целом, это должно быть временным явлением, так как этому RAG просто нужно пройти холодный старт, и результаты будут улучшаться со временем.


RAG был представлен как решение для граундинга на конференции Google Next.
tagМое мнение
RAG ни мертв, ни жив; так что прекратите спорить об этом. RAG — это просто один из алгоритмических паттернов, который вы можете использовать. Но если вы делаете его тем самым алгоритмом и превозносите его, то вы живете в созданном вами пузыре, и этот пузырь лопнет.
