

Разговоры об ИИ часто носят апокалиптический характер. Часть вины лежит на том, как апокалиптическая научная фантастика сформировала наше представление об искусственном интеллекте. Видения умных машин, способных создавать новые машины, были распространенным тропом в научной фантастике на протяжении поколений.
Многие высказывали опасения по поводу экзистенциальных рисков от недавних разработок в области ИИ, среди них много бизнес-лидеров, занимающихся коммерциализацией ИИ, и даже несколько ученых и исследователей. Это стало частью хайпа вокруг ИИ: если что-то достаточно мощное, чтобы заставить здравомыслящих икон науки и промышленности задуматься о конце света, то оно наверняка достаточно мощное, чтобы приносить прибыль, верно?
Так стоит ли нам беспокоиться об экзистенциальных рисках от ИИ? Нужно ли бояться, что Сэм Альтман создаст Альтрона из ChatGPT и его армия ИИ будет швырять в нас восточноевропейские города? Должны ли мы беспокоиться, что Palantir Питера Тиля создаст Skynet и отправит роботов с необъяснимым австрийским акцентом назад во времени, чтобы убить нас?
Вероятно, нет. Лидеры индустрии еще не нашли четкого способа, как заставить ИИ окупать свои расходы, не говоря уже о разрушении индустрий, и тем более об угрозе человечеству на уровне, сравнимом с изменением климата или ядерным оружием.
Существующие модели ИИ едва ли способны уничтожить человечество. Они с трудом рисуют руки, не могут посчитать больше трех предметов, считают, что можно продавать сыр, который погрызли крысы, и проводят католическое крещение напитком Gatorade. Обычные, неэкзистенциальные риски ИИ — способность помогать в дезинформации, harassment, генерации спама и неправильное использование людьми, которые не понимают его ограничений — уже достаточно тревожны.
Но один экзистенциальный риск от искусственного интеллекта определенно легитимен: ИИ представляет явную и непосредственную угрозу для... самого ИИ.
Этот страх обычно называют "коллапсом моделей", и он получил серьезное эмпирическое подтверждение в работах Шумаилова и др. (2023) и Алемохаммада и др. (2023). Идея проста: если обучать модели ИИ на данных, сгенерированных ИИ, затем взять полученный ИИ и использовать его выходные данные для обучения другой модели, повторяя процесс на протяжении нескольких поколений, ИИ будет объективно становиться все хуже и хуже. Это как делать копию копии копии.

В последнее время ведется много обсуждений коллапса моделей, и появляются заголовки в прессе о том, что у ИИ заканчиваются данные. Если интернет заполнится данными, сгенерированными ИИ, а данные, созданные людьми, станет сложнее идентифицировать и использовать, то вскоре модели ИИ столкнутся с потолком качества.
В то же время растет использование методов синтетических данных и дистилляции моделей в разработке ИИ. Оба метода включают обучение моделей ИИ хотя бы частично на выходных данных других моделей ИИ. Эти две тенденции, кажется, противоречат друг другу.
На самом деле все немного сложнее. Заспамит ли генеративный ИИ все вокруг и остановит свой собственный прогресс? Или ИИ поможет нам создавать лучший ИИ? Или и то, и другое?
Попробуем найти ответы в этой статье.
tagКоллапс моделей
Как бы мы ни любили Алемохаммада и др. за изобретение термина "Model Autophagy Disorder (MAD)", "коллапс моделей" звучит гораздо лучше и не включает греческие слова для самоканнибализма. Метафора с созданием копий копий хорошо передает проблему простыми словами, но в основной теории есть еще некоторые нюансы.
Обучение модели ИИ — это вид статистического моделирования, расширение того, чем статистики и специалисты по данным занимаются уже давно. Но в первый же день обучения науке о данных вы узнаете девиз специалиста по данным:
Все модели неверны, но некоторые полезны.
Эта цитата, приписываемая Джорджу Боксу, должна быть мигающим красным светом над каждой моделью ИИ. Вы всегда можете создать статистическую модель для любых данных, и эта модель всегда даст вам ответ, но абсолютно ничто не гарантирует, что этот ответ правильный или хотя бы близок к правильному.
Статистическая модель — это аппроксимация чего-то. Ее выходные данные могут быть полезными, они могут быть даже достаточно хорошими, но они все равно остаются аппроксимациями. Даже если у вас есть хорошо валидированная модель, которая в среднем очень точна, она все равно может и, вероятно, будет иногда делать большие ошибки.
Модели ИИ наследуют все проблемы статистического моделирования. Каждый, кто играл с ChatGPT или любой другой большой моделью ИИ, видел, как она делает ошибки.
Таким образом, если модель ИИ является аппроксимацией чего-то реального, то модель ИИ, обученная на выходных данных другой модели ИИ, является аппроксимацией аппроксимации. Ошибки накапливаются, и она неизбежно должна быть менее точной моделью, чем та, на которой она обучалась.
Алемохаммад и др. показывают, что проблему нельзя решить, добавляя часть оригинальных тренировочных данных к выходным данным ИИ перед обучением новой "дочерней" модели. Это только замедляет коллапс модели, но не может его остановить. Если не вводить достаточно новых, ранее не виденных данных из реального мира при каждом обучении с использованием выходных данных ИИ, коллапс модели неизбежен.
Сколько новых данных достаточно, зависит от трудно предсказуемых, специфических для каждого случая факторов, но больше новых, реальных данных и меньше данных, сгенерированных ИИ, всегда лучше, чем наоборот.
И это проблема, потому что все легкодоступные источники свежих данных, созданных человеком, уже исчерпаны, в то время как количество данных, сгенерированных ИИ, в изображениях и тексте растет стремительными темпами. Соотношение созданного человеком и созданного ИИ контента в Интернете падает, возможно, падает быстро. Не существует надежного способа автоматически обнаруживать данные, сгенерированные ИИ, и многие исследователи считают, что его не может быть. Публичный доступ к моделям генерации изображений и текста ИИ гарантирует, что эта проблема будет расти, вероятно, драматически, и не имеет очевидного решения.
Количество машинного перевода в интернете может означать, что уже слишком поздно. Машинный перевод текстов в интернете загрязняет наши источники данных уже много лет, задолго до революции генеративного ИИ. Согласно исследованию Thompson и соавторов, 2024, возможно, половина текстов в интернете переведена с других языков, причем большая часть этих переводов низкого качества и имеет признаки машинной генерации. Это может искажать языковую модель, обученную на таких данных.
В качестве примера ниже приведен скриншот страницы с сайта Die Welt der Habsburger, демонстрирующий явные признаки машинного перевода. "Hamster buying" — это слишком буквальный перевод немецкого слова hamstern, означающего делать запасы или скупать в панике. Слишком много таких примеров приведет к тому, что модель ИИ будет считать "hamster buying" реальным английским выражением и что немецкое hamstern как-то связано с домашними хомяками.

Практически во всех случаях наличие большего количества выходных данных ИИ в обучающих данных — это плохо. Слово практически важно, и мы обсудим два исключения ниже.
tagСинтетические данные
Синтетические данные — это данные для обучения или оценки ИИ, которые были созданы искусственно, а не взяты из реального мира. По данным Николенко (2021), синтетические данные берут начало в ранних проектах компьютерного зрения 1960-х годов, и он описывает их историю как важный элемент этой области.
Существует много причин для использования синтетических данных. Одна из главных — борьба с предвзятостью.
Большие языковые модели и генераторы изображений получили много громких жалоб по поводу предвзятости. Слово предвзятость имеет строгое значение в статистике, но эти жалобы часто отражают моральные, социальные и политические соображения, не имеющие простого математического выражения или инженерного решения.
Предвзятость, которую не видно сразу, гораздо более разрушительна и сложнее поддается исправлению. Шаблоны, которые модели ИИ учатся воспроизводить, — это те, которые присутствуют в их обучающих данных, и там, где эти данные имеют систематические недостатки, предвзятость неизбежна. Чем больше разных задач мы ожидаем от ИИ — чем разнообразнее входные данные для модели — тем больше шансов, что она сделает что-то неправильно, потому что никогда не видела достаточно похожих случаев в своем обучении.
Основная роль синтетических данных в обучении ИИ сегодня — обеспечить достаточное количество примеров определенных типов ситуаций, которые могут быть недостаточно представлены в доступных естественных данных.
Ниже приведено изображение, которое MidJourney создал при запросе "doctor": четыре мужчины, трое белых, трое в белых халатах со стетоскопами, и один действительно пожилой. Это не отражает реальную расовую принадлежность, возраст, пол или одежду настоящих врачей в большинстве стран и контекстов, но, вероятно, отражает размеченные изображения, которые можно найти в интернете.

При повторном запросе он создал одну женщину и трех мужчин, все белые, хотя один из них — мультипликационный персонаж. ИИ может быть странным.

Этот конкретный источник предвзятости — тот, который генераторы изображений ИИ пытаются предотвратить, поэтому мы больше не получаем таких явно предвзятых результатов, как, возможно, год назад от тех же систем. Предвзятость все еще заметна, но не очевидно, как должен выглядеть непредвзятый результат.
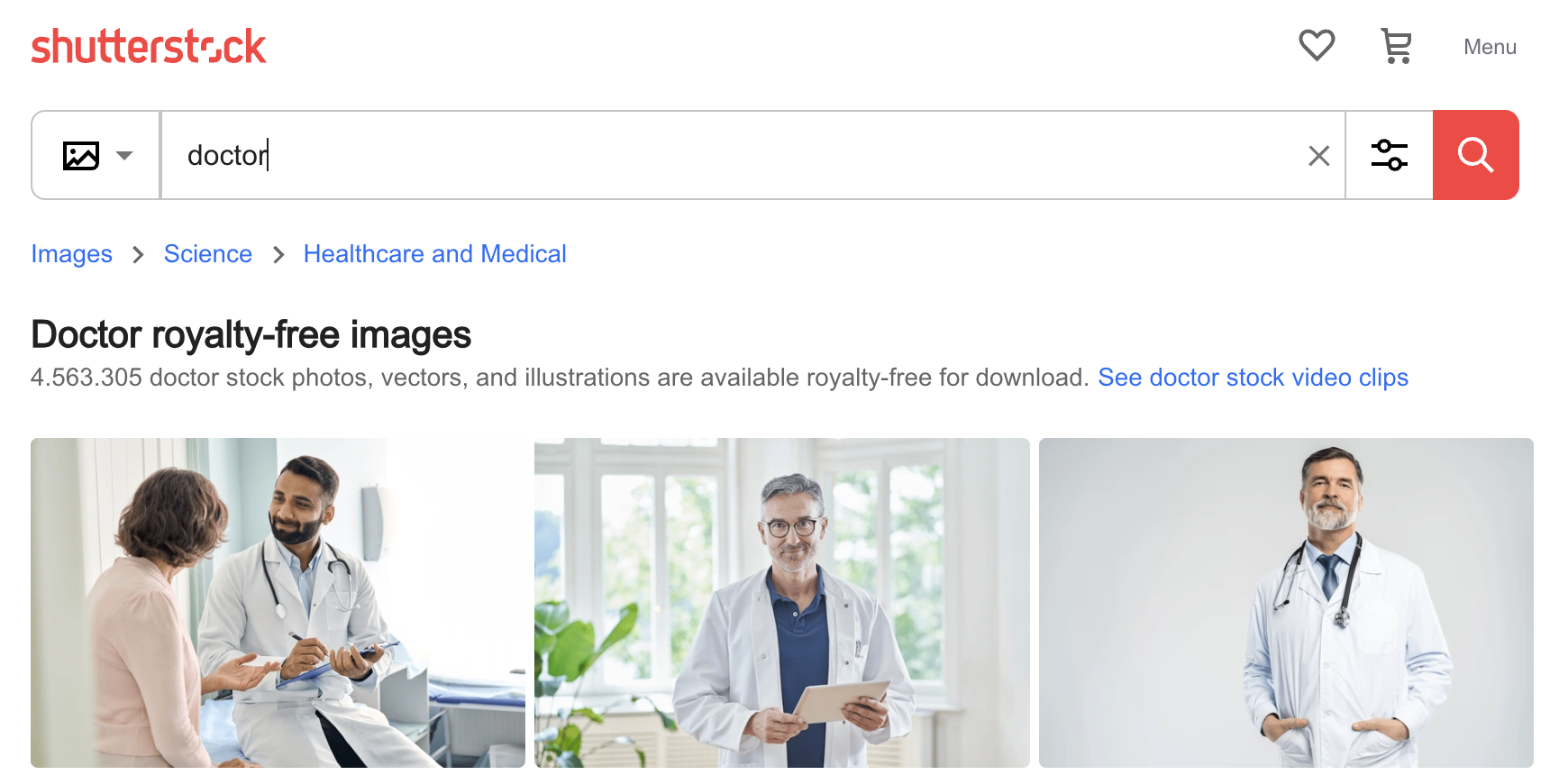
Тем не менее, нетрудно понять, как ИИ мог приобрести такие предрассудки. Ниже показаны первые три изображения, найденные по запросу "doctor" на фотосайте Shutterstock: три мужчины, двое пожилые и белые. Предвзятость ИИ — это предвзятость его обучения, и если вы обучаете модели, используя необработанные данные, вы всегда найдете такие виды предвзятости.
Один из способов смягчить эту проблему — использовать генератор изображений ИИ для создания изображений молодых врачей, женщин-врачей, врачей разных рас и врачей в медицинской одежде, костюмах или другой одежде, а затем включить их в обучение. Синтетические данные, используемые таким образом, могут улучшить производительность модели ИИ, по крайней мере, относительно некоторой внешней нормы, вместо того чтобы приводить к коллапсу модели. Однако искусственное искажение распределений обучающих данных может создать непредвиденные побочные эффекты, как недавно обнаружил Google.
tagДистилляция модели
Дистилляция модели — это техника обучения одной модели непосредственно от другой. Обученная генеративная модель — "учитель" — создает столько данных, сколько необходимо для обучения необученной или менее обученной модели "ученика".
Как и следовало ожидать, модель "ученика" никогда не может быть лучше "учителя". На первый взгляд, обучать модель таким образом кажется бессмысленным, но есть преимущества. Основное из них заключается в том, что модель "ученика" может быть намного меньше, быстрее или эффективнее "учителя", при этом близко приближаясь к его производительности.
Связь между размером модели, обучающими данными и конечной производительностью сложна. Однако в целом, при прочих равных условиях:
- Большая модель работает лучше, чем маленькая.
- Модель, обученная на большем количестве или лучших данных (или, по крайней мере, более разнообразных обучающих данных), работает лучше, чем обученная на меньшем количестве или худших данных.
Это означает, что маленькая модель иногда может работать так же хорошо, как большая. Например, jina-embeddings-v2-base-en значительно превосходит многие гораздо более крупные модели по стандартным тестам:
| Model | Size in parameters | MTEB average score |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |
Дистилляция моделей — это способ взять большую модель, которая стоит слишком дорого для запуска, и использовать ее для создания меньшей, более дешевой модели. В каждом случае происходит некоторая потеря производительности, но в лучших случаях она может быть очень небольшой.
Учитывая затраты, связанные с очень большими моделями искусственного интеллекта, эти преимущества весьма существенны. Дистилляция создает модели, которые работают быстрее, на более дешевых чипах, с меньшим объемом памяти и потребляют меньше энергии.
Более того, большие модели могут изучать удивительно тонкие паттерны из необработанных данных — паттерны, которые меньшая модель никогда не смогла бы выучить из тех же данных. Большая модель может создавать гораздо более разнообразные тренировочные данные, чем те, на которых она была обучена, достаточно для того, чтобы меньшая модель смогла выучить те же тонкие паттерны. Когда у вас есть большая обученная модель, вы можете использовать ее, чтобы "научить" тому, что она узнала, меньшую модель, которая никогда не смогла бы научиться этому самостоятельно. В таких случаях дистилляция иногда является лучшим способом обучения, чем использование реальных тренировочных данных.
tagТак что, мы все катимся в тартарары?
Возможно.
Хорошая новость в том, что без решения проблемы коллапса моделей мы, вероятно, не сможем обучить суперинтеллектуальный ИИ, способный уничтожить человечество, по крайней мере, теми методами, которые мы использовали. Мы можем спокойно вернуться к беспокойству об изменении климата и ядерной войне.
Для индустрии ИИ картина не столь оптимистична. Девизом машинного обучения долгое время было "больше данных — лучше данные." (Иногда: "Нет лучших данных, чем больше данных.") Статистики знают, что это неверно. Здравый смысл говорит, что это неверно. Но эта стратегия работала для исследователей ИИ долгое время, по крайней мере, с тех пор, как я начал работать исследователем в области машинного перевода в начале 2000-х.
На это есть причины. Разнообразные данные — данные, которые включают множество различных возможностей — являются гораздо лучшим источником для обучения, чем однородные данные. И на практике, в реальном мире, больше данных обычно означает более разнообразные данные.
Но мы исчерпываем новые источники хороших, разнообразных данных, и создание новых произведений человеком вряд ли будет успевать за генерацией ИИ. Так или иначе, нам в конечном итоге придется изменить способ обучения моделей ИИ. В противном случае мы можем достичь порога производительности, который больше не сможем превзойти. Это преобразило бы индустрию, поскольку фокус сместился бы с создания и запуска более крупных, дорогостоящих моделей на разработку фреймворков, контекстов и ниш, в которых существующие модели могут принести новую добавленную стоимость.
tagКак Jina AI обучает свои модели ИИ
В Jina AI мы стараемся предоставить нашим пользователям преимущества лучших практик ИИ. Хотя мы не производим текстовые LLM или генераторы изображений ИИ, мы по-прежнему обеспокоены проблемой коллапса моделей. Мы используем подмножества Common Crawl для основной предварительной подготовки, а затем используем курированные и синтетические данные для оптимизации производительности наших моделей. Мы стремимся обеспечить современную производительность для экономичных моделей и компактных, низкоразмерных эмбеддингов.
Тем не менее, коллапс модели является неизбежной проблемой для данных Common Crawl. Мы ожидаем со временем перейти к использованию более курированных данных и меньшему использованию Common Crawl. Мы ожидаем, что другие игроки индустрии ИИ сделают то же самое. Это будет иметь свою цену — как в денежном выражении, так и с точки зрения скорости улучшения качества — но пока слишком рано пытаться оценить эти затраты.
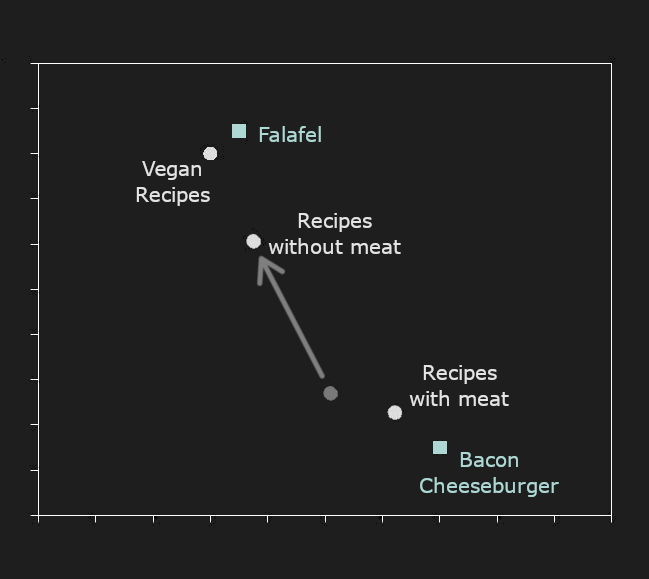
Мы используем синтетические данные в областях, где модели эмбеддингов имеют известные проблемы. Например, модели ИИ с трудом представляют отрицание. "Рецепты с мясом" и "рецепты без мяса" обычно имеют очень близкие эмбеддинги, но пользователям часто нужно, чтобы они были очень далеки друг от друга. Наше самое большое использование синтетических данных — это создание большого корпуса сгенерированных ИИ пар предложений, различающихся этим видом отрицания (называемым полярностью в ИИ и некоторых видах лингвистики), а затем использование его для улучшения наших моделей.
Например, ниже представлена 2D-проекция гипотетических эмбеддингов. "Рецепты с мясом" и "Рецепты без мяса" находятся относительно близко друг к другу. "Бургер с беконом" намного ближе к "Рецептам с мясом", чем к чему-либо еще, а "Фалафель" ближе к "Рецептам без мяса", чем к "Рецептам с мясом". Однако "Бургер с беконом" намного ближе к "Рецептам без мяса", чем "Фалафель".

Глядя исключительно на эмбеддинги, мы могли бы заключить, что бургеры с беконом являются лучшим примером рецепта без мяса, чем фалафель.
Чтобы предотвратить это, мы обучаем наши модели с помощью синтетических данных. Мы используем LLM для генерации пар предложений с противоположной полярностью – например, "X с Y" / "X без Y" – и обучаем наши модели эмбеддингов разносить эти пары дальше друг от друга. Мы также используем синтетические данные для других видов целенаправленного отрицательного майнинга, набора методов, используемых для улучшения определенных аспектов производительности модели ИИ путем представления ей курированных данных.
Мы также используем генеративный ИИ для обучения моделей эмбеддингов для языков программирования, используя преимущества больших моделей, которые генерируют множество примеров кода, чтобы мы могли правильно встраивать даже довольно редкие особенности конкретных языков и фреймворков.
Дистилляция моделей является ключом к тому, как мы создаем компактные модели, которые экономят компьютерные ресурсы. Дистилляция гораздо эффективнее и надежнее, чем обучение с нуля, и наши результаты показывают, что дистиллированная модель все еще может иметь высококачественную производительность. В таблице ниже показаны дистиллированные модели ранжировщика Jina AI в сравнении с базовым ранжировщиком, использованным для их обучения, и другими моделями с гораздо большим количеством параметров, но худшей производительностью.
| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
Мы знаем, что ИИ может быть дорогостоящей инвестицией, и что предприятия все больше осознают свои моральные и юридические обязательства по сокращению выбросов углерода. Мы также осознаем это. Дистилляция моделей — это важная часть того, как мы решаем эти проблемы.
tagПозвольте нам помочь вам ориентироваться в ИИ
Jina AI стремится предоставить предприятиям доступные, эффективные, работающие решения ИИ. Мы можем интегрироваться с вашей существующей облачной инфраструктурой на Azure и AWS. Мы предоставляем веб-API, которые соблюдают строгие стандарты безопасности и конфиденциальности и не сохраняют ваши данные для собственного обучения. Мы можем помочь вам установить наши модели с открытым исходным кодом на вашем собственном оборудовании, сохраняя всю вашу операцию внутри компании.
Может быть сложно отделить хайп от технологий и оставаться в курсе лучших практик в этой быстро меняющейся области. Позвольте нам сделать это за вас.





