


对 AI 的讨论常常带有末日色彩。这部分要归咎于末日科幻作品塑造了我们对人工智能的认知。几代科幻作品中都出现过智能机器能制造更多机器的情节。
许多人都对近期 AI 发展带来的存在性风险发出警告,其中包括很多参与 AI 商业化的商界领袖,甚至还有一些科学家和研究人员。这已经成为 AI 炒作的一部分:如果连这些看似稳重的科技和工业界标志性人物都在考虑世界末日,那这项技术肯定有足够的力量带来利润,对吧?
那么,我们是否应该担心 AI 带来的存在性风险?我们需要担心 Sam Altman 会用 ChatGPT 制造出 Ultron,让其AI 军团向我们投掷东欧城市吗?我们是否应该担心Peter Thiel 的 Palantir 建造天网并派出带着莫名其妙奥地利口音的机器人回到过去杀死我们?
可能不会。业界领袖们至今还没找到让 AI 自负盈亏的明确方法,更别说颠覆行业了,更不用说对人类造成可与气候变化或核武器相提并论的威胁了。
我们现有的 AI 模型根本无法消灭人类。它们在画手时就很困难,数不过三个东西,认为卖老鼠啃过的奶酪没问题,还会用佳得乐进行天主教洗礼。AI 带来的普通、非存在性风险——比如它可能助长错误信息传播、骚扰、垃圾信息生成,以及被不了解其局限性的人误用——这些就已经够令人担忧的了。
但人工智能确实存在一个合理的存在性风险:AI 对……AI 自身构成了明确而紧迫的威胁。
这种担忧通常被称为"模型崩溃",并在Shumailov 等人(2023)和Alemohammad 等人(2023)的研究中得到了有力的实证。这个概念很简单:如果用 AI 生成的数据训练 AI 模型,然后用这个模型的输出训练另一个模型,如此重复多代,AI 的表现将客观上越来越差。这就像复印件的复印件的复印件。

最近关于模型崩溃的讨论很多,新闻头条也开始报道 AI 训练数据即将用尽的问题。如果互联网充满了 AI 生成的数据,而人类制作的数据越来越难以识别和使用,那么 AI 模型很快就会遇到质量天花板。
同时,合成数据和模型蒸馏技术在 AI 开发中的使用也在增加。这两种技术都包含了使用其他 AI 模型的输出来训练 AI 模型。这两个趋势似乎是相互矛盾的。
实际情况比这更复杂。生成式 AI 会制造垃圾信息并阻碍自身进步吗?或者 AI 会帮助我们制造出更好的 AI?还是两者都会发生?
我们将在这篇文章中寻找一些答案。
tag模型崩溃
尽管我们很喜欢 Alemohammad 等人发明的"模型自噬失调(Model Autophagy Disorder,MAD)"这个术语,但"模型崩溃"更朗朗上口,而且不涉及希腊语中的自我吞噬概念。用复印件的复印件这个比喻可以简单地传达问题所在,但背后的理论还有更多内容。
训练 AI 模型是一种统计建模,是统计学家和数据科学家长期以来工作的延伸。但在数据科学课程的第一天,你就会学到数据科学家的座右铭:
所有模型都是错的,但有些是有用的。
这句话出自George Box,应该作为每个 AI 模型顶部的闪烁警示灯。你总能为任何数据建立统计模型,这个模型也总会给出答案,但没有任何东西能保证这个答案是对的,甚至是接近正确的。
统计模型是某个事物的近似。它的输出可能有用,甚至可能足够好,但它们仍然是近似值。即使你有一个经过良好验证、平均来说非常准确的模型,它有时仍然可能会(而且很可能会)犯大错。
AI 模型继承了统计建模的所有问题。任何玩过 ChatGPT 或其他大型 AI 模型的人都见过它犯错。
所以,如果一个 AI 模型是某个真实事物的近似,那么用另一个 AI 模型的输出训练的 AI 模型就是近似的近似。错误会累积,它本质上必然比训练它的模型更不准确。
Alemohammad 等人表明,在训练新的"子"模型之前,向 AI 输出中添加一些原始训练数据也无法解决这个问题。这只能减缓模型崩溃,无法阻止它。除非在使用 AI 输出进行训练时引入足够多的新的、之前未见过的真实世界数据,否则模型崩溃是不可避免的。
需要多少新数据才算足够取决于难以预测的、具体情况相关的因素,但新的真实数据越多、AI 生成的数据越少总是更好。
这就是个问题,因为所有容易获取的新鲜人工数据来源都已经用尽,而互联网上 AI 生成的图像和文本数据却在飞速增长。互联网上人工制作内容与 AI 制作内容的比率正在下降,可能下降得很快。没有可靠的方法自动检测 AI 生成的数据,而且许多研究人员认为这种方法可能根本不存在。公众可以访问 AI 图像和文本生成模型,这确保了这个问题会继续增长,很可能会剧烈增长,而且没有明显的解决方案。
互联网上机器翻译的数量可能意味着现在已经太晚了。机器翻译的文本已经在互联网上污染我们的数据来源多年,这远在生成式 AI 革命之前就开始了。根据 Thompson 等人,2024 的研究,互联网上可能有一半的文本是从其他语言翻译而来,而这些翻译中有很大一部分质量低劣,显示出机器生成的特征。这可能会扭曲从此类数据训练出的语言模型。
举个例子,下面是来自 Die Welt der Habsburger 网站的一个页面的截图,明显显示出机器翻译的痕迹。"Hamster buying" 是对德语单词 hamstern 的过于直白的翻译,其实际含义是"囤积"或"抢购"。太多这样的实例会导致 AI 模型认为 "hamster buying" 在英语中是真实存在的,并且认为德语 hamstern 与宠物仓鼠有关。

在几乎所有情况下,训练数据中包含更多 AI 输出都是不好的。这里的"几乎"很重要,我们将在下面讨论两个例外。
tag合成数据
合成数据是人工生成而非来自真实世界的 AI 训练或评估数据。Nikolenko(2021)追溯合成数据的起源到 1960 年代早期的计算机视觉项目,并概述了它在该领域作为重要元素的历史。
使用合成数据有很多原因。其中最大的原因之一是对抗偏见。
大型语言模型和图像生成器已经收到了很多关于偏见的高调投诉报道。"偏见"在统计学中有严格的定义,但这些投诉通常反映了道德、社会和政治方面的考虑,这些考虑并没有简单的数学形式或工程解决方案。
你不容易看到的偏见却更具破坏性,也更难修复。AI 模型学习复制的模式是从其训练数据中看到的模式,当这些数据存在系统性缺陷时,偏见就不可避免地出现了。我们期望 AI 能做的事情越多——模型的输入越多样化——就越有可能因为在训练中没有见到足够多的类似案例而出错。
如今合成数据在 AI 训练中的主要作用是确保训练数据中包含足够多某些特定情况的例子,这些情况在可获得的自然数据中可能并不充分。
下面是 MidJourney 在接收到 "doctor" 提示时生成的图像:四个男性,其中三个是白人,三个穿着白大褂带着听诊器,还有一个是真正的老年人。这并不反映大多数国家和环境中真实医生的种族、年龄、性别或着装,但很可能反映了在互联网上能找到的带标签图像。

再次提示时,它生成了一名女性和三名男性,全都是白人,不过其中一个是卡通形象。AI 有时确实很奇怪。

这种特定的偏见是 AI 图像生成器一直在试图防止的,因此我们不再像可能一年前那样从相同的系统获得如此明显带有偏见的结果。偏见仍然可见,但什么样的结果才算无偏见并不明显。
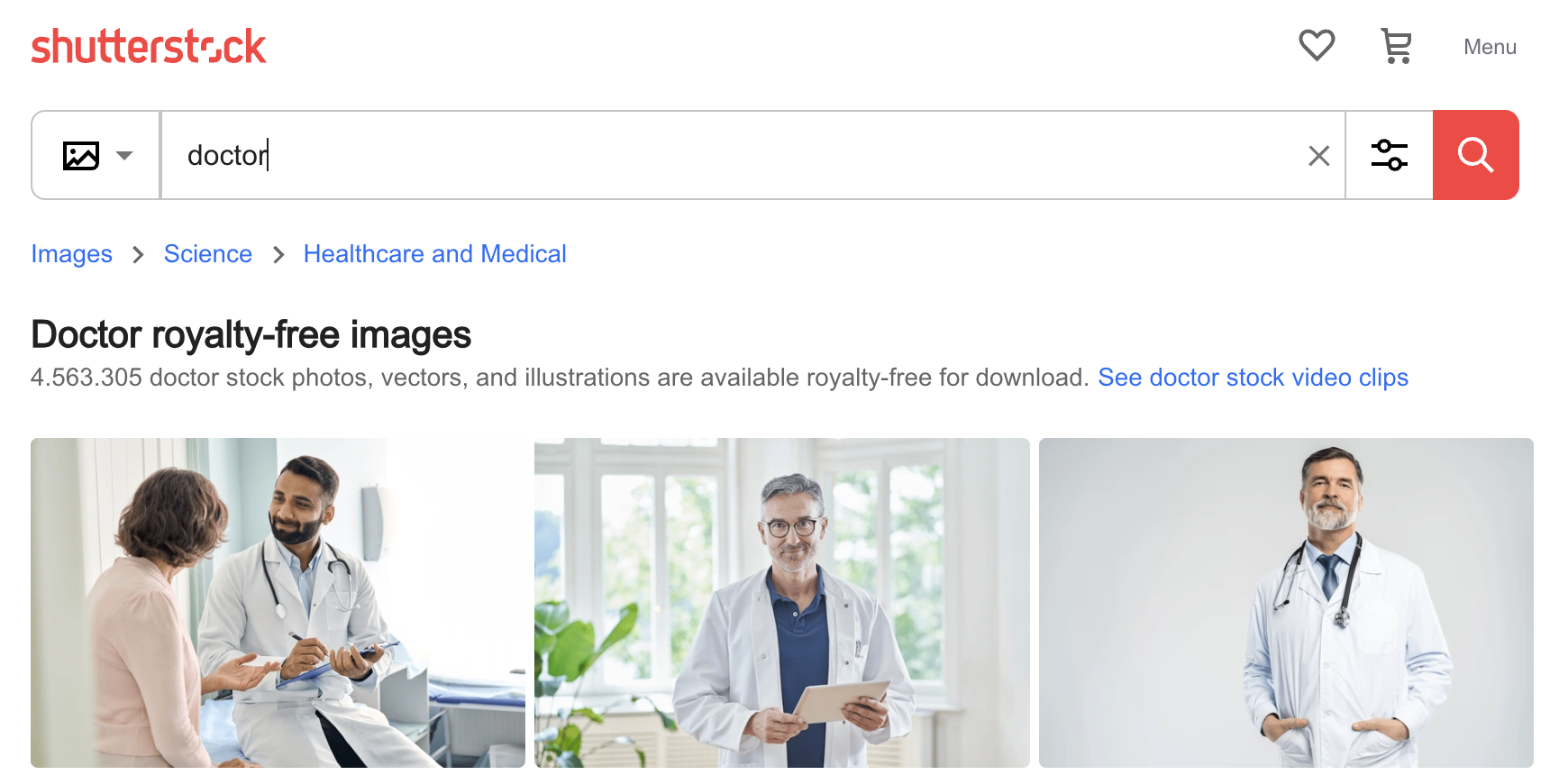
然而,不难理解 AI 是如何获得这些偏见的。下面是在 Shutterstock 照片网站上搜索 "doctor" 找到的前三张图片:三个男性,其中两个是年长的白人。AI 的偏见就是其训练的偏见,如果你使用未经筛选的数据训练模型,你总会发现这些类型的偏见。
缓解这个问题的一种方法是使用 AI 图像生成器来创建年轻医生、女性医生、有色人种医生,以及穿着手术服、西装或其他服装的医生的图像,然后将它们包含在训练中。以这种方式使用的合成数据可以改善 AI 模型的表现,至少相对于某些外部标准而言,而不是导致模型崩溃。然而,人为扭曲训练数据分布可能会产生意想不到的副作用,就像 Google 最近发现的那样。
tag模型蒸馏
模型蒸馏是一种直接从一个模型训练另一个模型的技术。一个已训练的生成模型——"教师"——创建所需的尽可能多的数据来训练一个未训练或训练较少的"学生"模型。
正如你所预料的,"学生"模型永远不可能比"教师"更好。乍一看,这样训练模型似乎没有意义,但它确实有好处。主要的好处是"学生"模型可能比"教师"小得多、更快或更高效,同时仍能近似其性能。
模型大小、训练数据和最终性能之间的关系很复杂。然而,总的来说,在其他条件相同的情况下:
- 大模型比小模型表现更好。
- 使用更多或更好的训练数据(或至少更多样化的训练数据)训练的模型比使用较少或较差数据训练的模型表现更好。
这意味着小模型有时可以和大模型表现一样好。例如,jina-embeddings-v2-base-en 在标准基准测试中显著优于许多更大的模型:
| Model | Size in parameters | MTEB average score |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |

| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
