


分類是嵌入向量的常見下游任務。文本嵌入可以將文本分類成預定義的標籤,用於垃圾郵件檢測或情感分析。多模態嵌入向量,例如 jina-clip-v1 可用於基於內容的過濾或標籤註解。最近,分類也被用於根據複雜度和成本將查詢路由到合適的 LLM,例如簡單的算術查詢可能會被路由到小型語言模型。複雜的推理任務則可能被引導到更強大但成本更高的 LLM。
今天,我們要介紹 Jina AI 搜索基礎設施的全新 分類器 API。它支援 零樣本 和 少樣本 線上分類,基於我們最新的嵌入模型,如 jina-embeddings-v3 和 jina-clip-v1。分類器 API 基於線上被動-積極學習,使其能夠即時適應新資料。使用者可以從零樣本分類器開始並立即使用。然後,他們可以通過提交新範例或在概念偏移發生時逐步更新分類器。這使得跨各種內容類型的高效、可擴展的分類成為可能,而無需大量初始標記資料。使用者也可以發布他們的分類器供公開使用。當我們發布新的嵌入模型時,例如即將推出的多語言 jina-clip-v2,使用者可以通過分類器 API 立即使用它們,確保分類功能保持最新。

tag零樣本分類
分類器 API 提供強大的零樣本分類功能,無需預先訓練標記資料即可對文字或圖像進行分類。每個分類器都從零樣本能力開始,之後可以通過額外的訓練資料或更新來增強 - 我們將在下一節探討這個主題。
tag範例 1:路由 LLM 請求
這是使用分類器 API 進行 LLM 查詢路由的示例:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'這個示例展示了使用 jina-embeddings-v3 將多種語言(英語、中文、日語和德語)的使用者查詢路由到三個類別,這些類別對應於三種不同規模的 LLM。API 回應格式如下:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}回應包括:
usage:token 使用量的相關資訊。data:分類結果陣列,每個輸入對應一個結果。- 每個結果包含預測的標籤 (
prediction) 和置信度分數 (score)。每個類別的score是通過 softmax 正規化計算的 - 對於零樣本,它基於輸入和標籤嵌入之間的餘弦相似度在classificationtask-LoRA 下;而對於少樣本,它基於每個類別學習到的輸入嵌入的線性變換 - 產生的機率值在所有類別中總和為 1。 index對應於原始請求中輸入的位置。
- 每個結果包含預測的標籤 (
tag範例 2:對圖像和文字進行分類
讓我們探討一個使用 jina-clip-v1 的多模態示例。這個模型可以同時對文字和圖像進行分類,非常適合用於跨不同媒體類型的內容分類。考慮以下 API 呼叫:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'注意我們如何在請求中上傳圖像,你也可以使用 base64 字串來表示圖像。API 返回以下分類結果:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tag範例 3:檢測 Jina Reader 是否獲得真實內容
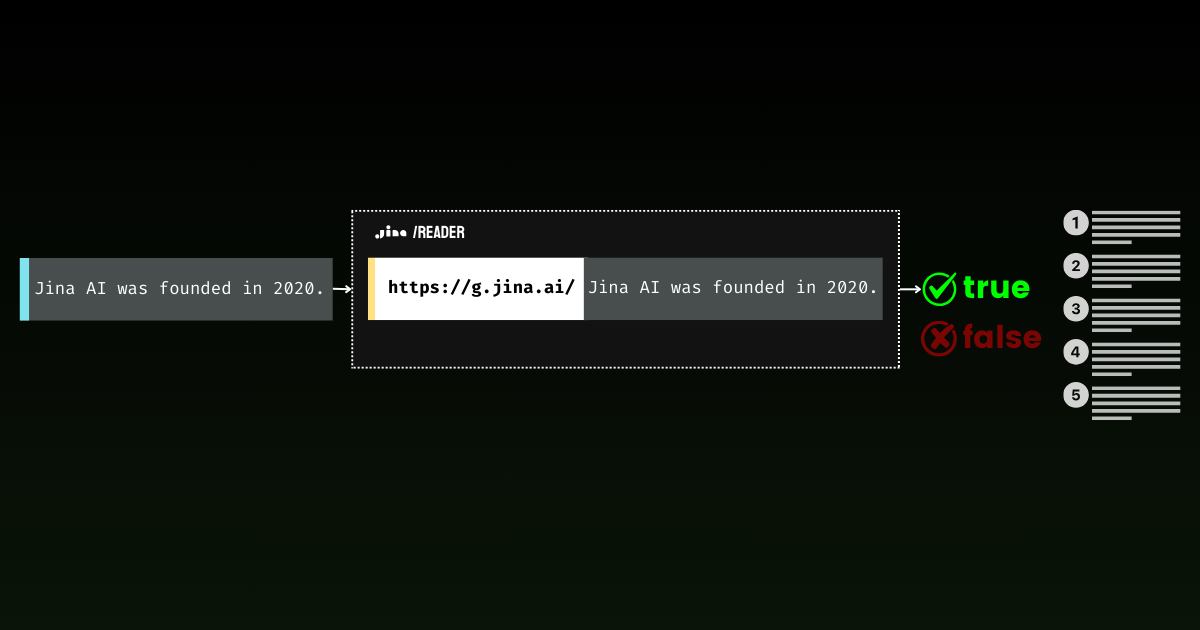
零樣本分類的一個有趣應用是通過 Jina Reader 判斷網站的可訪問性。雖然這看起來是個簡單的任務,但在實際操作中卻相當複雜。被阻擋的訊息因網站而異,使用不同語言並引述各種原因(付費牆、速率限制、伺服器中斷)。這種多樣性使得僅依靠正則表達式或固定規則來捕捉所有情況變得具有挑戰性。
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)這個腳本通過 r.jina.ai 獲取內容,並使用分類器 API 將其分類為 "Blocked" 或 "Accessible"。例如,https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai 可能會因訪問限制而被標記為 "Blocked",而 https://r.jina.ai/https://jina.ai 應該是 "Accessible"。
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}分類器 API 可以有效區分 Jina Reader 的真實內容和被阻擋的結果。
這個示例利用 jina-embeddings-v3,為監控網站可訪問性提供了一種快速、自動化的方式,尤其適用於多語言環境下的內容聚合或網路爬蟲系統。
tag範例 4:為基礎支撐過濾陳述與觀點
零樣本分類的另一個有趣應用是在長篇文件中過濾出與意見相對的陳述性語句。請注意,分類器本身無法判斷某事是否是事實真相。相反地,它識別那些「寫作風格像是一個事實陳述」的文字,這些文字隨後可以透過事實核查 API 來驗證,而這通常成本很高。這個兩步驟流程是有效事實檢查的關鍵:首先過濾掉所有意見和感受,然後將剩餘的陳述送去核實。
考慮這段關於 1960 年代太空競賽的段落:
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
這段文字有意混合了不同類型的寫作 - 從陳述性語句(如「史普尼克 1 號於 1959 年 10 月 4 日發射」),到明顯的意見(「令人驚嘆的見證」)、情感語言(「引起了人心中的恐懼」),以及解釋性陳述(「標誌著一個新時代的無可爭議的開始」)。
零樣本分類器的工作純粹是語意層面的 - 它識別一段文字是以陳述方式書寫還是以意見/解釋方式書寫。例如,"The Soviet Union launched Sputnik 1 on October 4, 1959" 是以陳述方式書寫的,而 "The Space Race was a breathtaking testament" 則明顯是以意見方式書寫的。
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)你會得到:
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']請記住,某事以陳述方式書寫並不意味著它就是真實的。這就是為什麼我們需要第二步 - 將這些類似陳述的語句輸入到事實核查 API 進行實際的事實驗證。例如,讓我們驗證這個陳述:"NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973",使用以下代碼。
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())這會給你:
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}事實性得分為 1,事實核查 API 確認這個陳述在歷史事實中有良好的根據。這種方法開啟了令人著迷的可能性,從分析歷史文件到即時核實新聞文章。通過結合零樣本分類和事實驗證,我們創建了一個強大的自動化信息分析管道 - 首先過濾掉意見,然後根據可信來源驗證剩餘的陳述。
tag零樣本分類的注意事項
使用語意標籤
在使用零樣本分類時,使用有語意意義的標籤而不是抽象符號或數字至關重要。例如,"Technology"、"Nature" 和 "Food" 比 "Class1"、"Class2"、"Class3" 或 "0"、"1"、"2" 更有效。"Positive sentiment" 比 "Positive" 和 "True" 更有效。嵌入模型理解語意關係,所以描述性標籤能讓模型利用其預訓練知識進行更準確的分類。我們之前的文章探討了如何創建有效的語意標籤以獲得更好的分類結果。

無狀態性質
零樣本分類本質上是無狀態的,這與傳統機器學習方法不同。這意味著給定相同的輸入和模型,無論誰使用 API 或何時使用,結果都將保持一致。模型不會根據它執行的分類進行學習或更新;每個任務都是獨立的。這使得可以立即使用而無需設置或訓練,並且提供了在 API 調用之間改變類別的靈活性。
這種無狀態性質與少樣本和在線學習方法形成鮮明對比,我們將在接下來探討這些方法。在這些方法中,模型可以適應新的例子,可能會隨著時間或用戶的不同而產生不同的結果。
tag少樣本分類
少樣本分類提供了一種使用最少標記數據來創建和更新分類器的簡單方法。這種方法提供兩個主要端點:train 和 classify。
train 端點讓你可以用一小組示例創建或更新分類器。你第一次調用 train 將返回一個
classifier_id 可用於當您有新資料、發現資料分布變化或需要新增類別時的後續訓練。這種靈活的方法使您的分類器能夠隨時間演進,適應新的模式和類別而無需從頭開始。與零樣本分類類似,您將使用 classify 端點進行預測。主要區別在於您需要在請求中包含您的 classifier_id,但不需要提供候選標籤,因為它們已經是您訓練模型的一部分。
tag範例:訓練客服工單分配器
讓我們通過一個為快速成長的科技新創公司分類客服工單並分配給不同團隊的範例來探索這些功能。
初始訓練
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'請注意,在少樣本學習中,即使 team1 team2 這樣的類別標籤沒有內在的語義含義,我們也可以自由使用它們。在回應中,您將獲得一個代表此新建分類器的 classifier_id。
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
記下這個 classifier_id,您稍後需要用它來引用這個分類器。
更新分類器以適應團隊重組
隨著示例公司的成長,新類型的問題出現,團隊結構也發生變化。少樣本分類的優點在於能夠快速適應這些變化。我們可以輕鬆地通過提供 classifier_id 和新的範例來更新分類器,引入新的團隊類別(如 team4)或根據組織的發展重新分配現有問題類型給不同的團隊。
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'使用已訓練的分類器
在推論階段,您只需提供輸入文本和 classifier_id。API 會處理輸入和先前訓練的類別之間的映射,基於分類器的當前狀態返回最適合的標籤。
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'少樣本模式有兩個獨特的參數。
tag參數 num_iters
num_iters 參數調整分類器從訓練範例中學習的強度。雖然預設值 10 適用於大多數情況,但您可以根據對訓練資料的信心策略性地調整這個值。對於對分類至關重要的高品質範例,增加 num_iters 以強化其重要性。相反,對於較不可靠的範例,降低 num_iters 以最小化它們對分類器性能的影響。這個參數也可以用於實現時間感知學習,其中較新的範例獲得較高的迭代次數,以適應不斷變化的模式,同時保持歷史知識。
tag參數 access
access 參數讓您控制誰可以使用您的分類器。預設情況下,分類器是私人的,只有您可以訪問。將 access 設置為 "public" 允許任何擁有您的 classifier_id 的人使用他們自己的 API key 和 token 配額來使用它。這使得分享分類器成為可能,同時保持隱私性 - 使用者無法看到您的訓練資料或配置,您也無法看到他們的分類請求。此參數僅與少樣本分類相關,因為零樣本分類器是無狀態的。無需分享零樣本分類器,因為無論誰發出請求,相同的請求總是會產生相同的回應。
tag關於少樣本學習的備註
我們 API 中的少樣本分類具有一些值得注意的獨特特性。與傳統機器學習模型不同,我們的實現使用單次線上學習 - 訓練範例被處理以更新分類器的權重,但之後不會被存儲。這意味著您無法檢索歷史訓練資料,但它確保了更好的隱私性和資源效率。
雖然少樣本學習很強大,但它確實需要一個預熱期才能超越零樣本分類。我們的基準測試顯示,通常需要 200-400 個訓練範例才能看到更優的性能。但是,您不需要一開始就為所有類別提供範例 - 分類器可以隨時間擴展以適應新的類別。只需注意,新增的類別可能會經歷短暫的冷啟動期或類別不平衡,直到提供足夠的範例。
tag基準測試
在我們的基準分析中,我們評估了零樣本和少樣本方法在各種數據集上的表現,包括情緒檢測(6 個類別)和垃圾郵件檢測(2 個類別)等文本分類任務,以及像 CIFAR10(10 個類別)這樣的圖像分類任務。評估框架使用標準的訓練-測試分割,零樣本不需要訓練資料,而少樣本使用部分訓練集。我們追踪了關鍵指標,如訓練集大小和目標類別數量,允許進行受控比較。為確保穩健性,特別是對於少樣本學習,每個輸入都經過多次訓練迭代。我們將這些現代方法與傳統基準(如線性 SVM 和 RBF SVM)進行比較,以提供其性能的背景參考。



圖中繪製了 F1 分數。有關完整的基準設置,請查看這個 Google 試算表。
F1 圖表揭示了三個任務的有趣模式。毫不意外地,零樣本分類從一開始就表現穩定,不受訓練數據量的影響。相比之下,小樣本學習呈現出快速的學習曲線,雖然初始表現較低,但隨著訓練數據增加,很快就超過了零樣本的表現。兩種方法最終在大約 400 個樣本時達到相近的準確率,其中小樣本保持些微優勢。這種模式在多分類和圖像分類場景中都成立,表明當有一些訓練數據時,小樣本學習特別有優勢,而零樣本即使在沒有任何訓練樣本的情況下也能提供可靠的表現。下表從 API 使用者的角度總結了零樣本和小樣本分類的差異。
| 功能 | 零樣本 | 小樣本 |
|---|---|---|
| 主要使用場景 | 一般分類的預設解決方案 | 用於 v3/clip-v1 領域外或時效性數據 |
| 需要訓練數據 | 否 | 是 |
| /train 中需要標籤 | 不適用 | 是 |
| /classify 中需要標籤 | 是 | 否 |
| 需要分類器 ID | 否 | 是 |
| 需要語義標籤 | 是 | 否 |
| 狀態管理 | 無狀態 | 有狀態 |
| 持續模型更新 | 否 | 是 |
| 存取控制 | 否 | 是 |
| 最大類別數 | 256 | 16 |
| 最大分類器數 | 不適用 | 16 |
| 每個請求的最大輸入數 | 1,024 | 1,024 |
| 每個輸入的最大 Token 長度 | 8,192 tokens | 8,192 tokens |
tag總結
Classifier API 為文本和圖像內容提供強大的零樣本和小樣本分類功能,由先進的嵌入模型如 jina-embeddings-v3 和 jina-clip-v1 驅動。我們的基準測試顯示,零樣本分類無需訓練數據即可提供可靠的表現,支援多達 256 個類別,這使其成為大多數任務的絕佳起點。雖然小樣本學習通過訓練數據可以達到稍微更好的準確率,我們建議從零樣本分類開始,因為它能立即產生結果且具有靈活性。
API 的多功能性支援各種應用,從 LLM 查詢路由到網站無障礙檢測和多語言內容分類。無論您是從零樣本開始,還是為特定案例轉向小樣本學習,API 都維持一致的介面,可以無縫整合到您的流程中。我們特別期待看到開發者如何在他們的應用中運用這個 API,未來我們還將推出對 jina-clip-v2 等新嵌入模型的支援。
