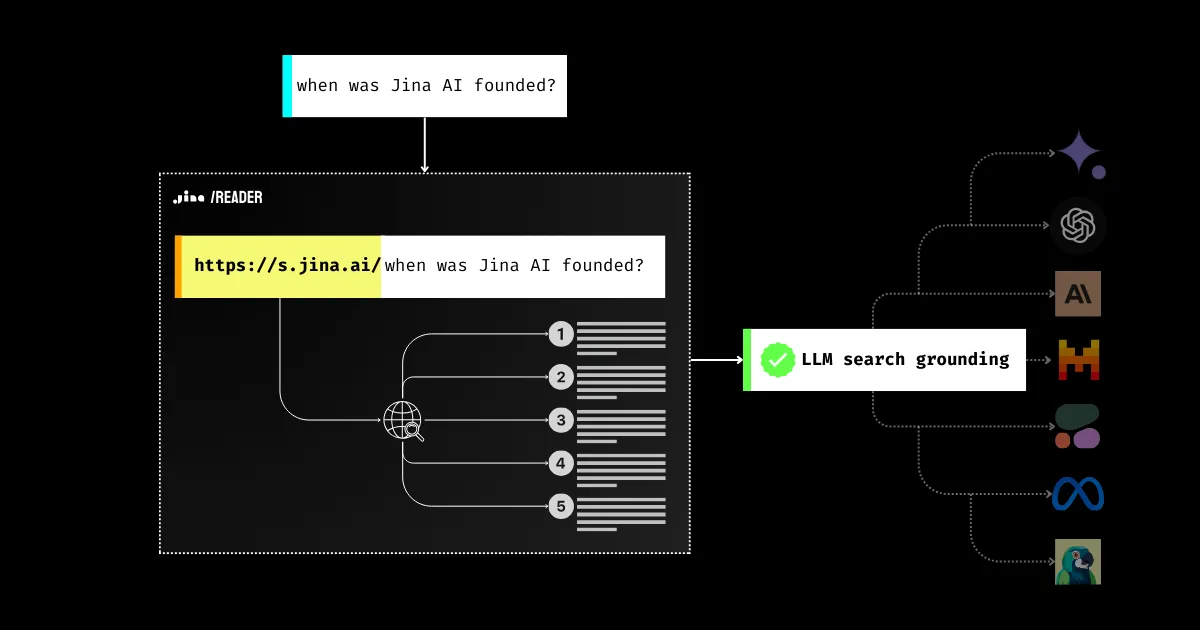

對於 GenAI 應用而言,資料依據(Grounding)是絕對重要的。
自 2023 年以來,您可能已看到許多工具、提示(prompts)和 RAG 管道,都是為了提升 LLMs 的事實準確性而設計的。為什麼?因為阻止企業向數百萬用戶部署 LLMs 的主要障礙是信任度:答案是真實的,還是僅僅是模型的幻覺(hallucination)?這是整個產業的問題,而 Jina AI 一直在努力解決。今天,透過新的 Jina Reader 搜尋依據功能,您只需使用 https://s.jina.ai/YOUR_SEARCH_QUERY 就能從網路上搜尋最新的世界知識。有了這個功能,您就離提升 LLMs 的事實準確性更近一步,使其回應更加可信且有幫助。

API 和 demo 可在產品頁面找到
tagLLMs 的事實準確性問題
我們都知道 LLMs 可能會編造內容並損害用戶信任。LLMs 可能會說出不符事實的內容(即所謂的幻覺),特別是對於它們在訓練期間沒有學習到的主題。這可能是訓練後產生的新資訊,或是在訓練過程中被「邊緣化」的專門知識。
因此,當遇到「今天天氣如何?」或「今年誰獲得了奧斯卡最佳女主角?」這類問題時,模型要麼回答「我不知道」,要麼給出過時的資訊。
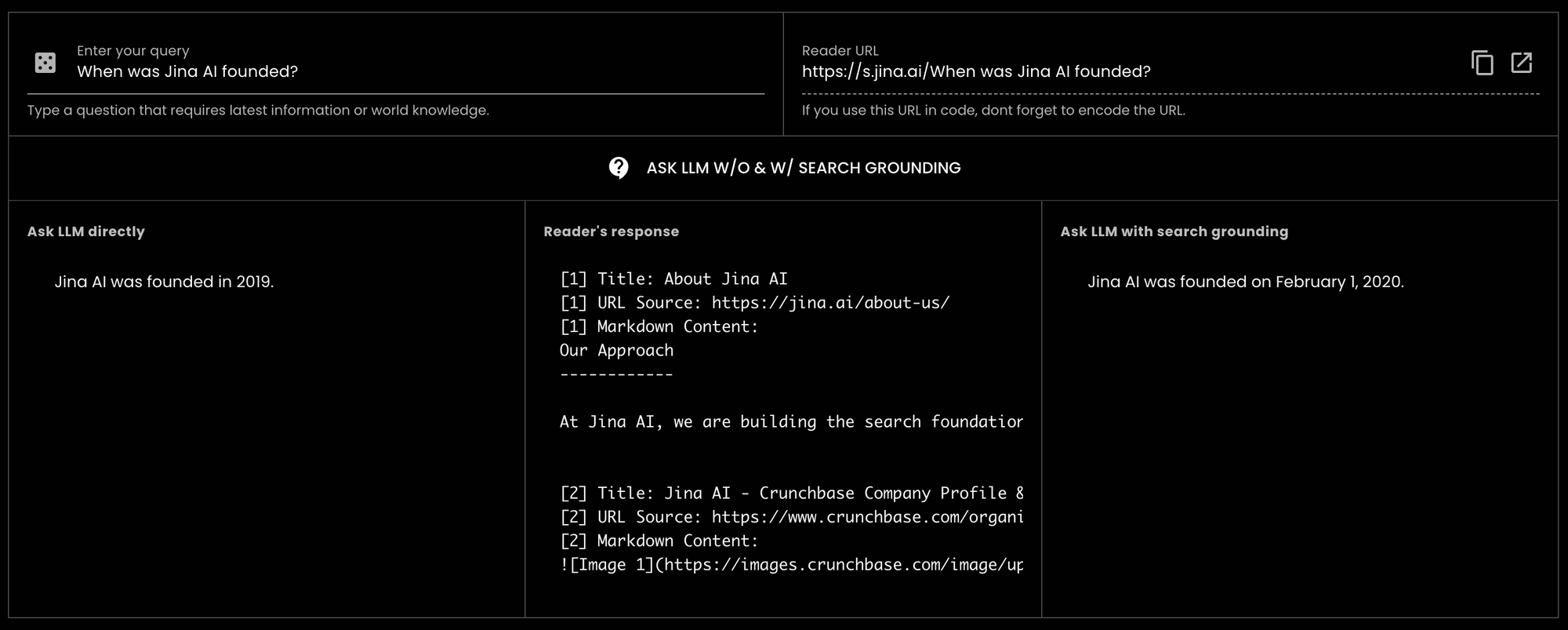
GPT-3.5-turbo 詢問「Jina AI 是何時成立的?」時,得到了錯誤的答案。然而,當使用 Reader 進行搜尋依據時,相同的 LLM 能夠提供正確答案。實際上,它精確到了具體日期。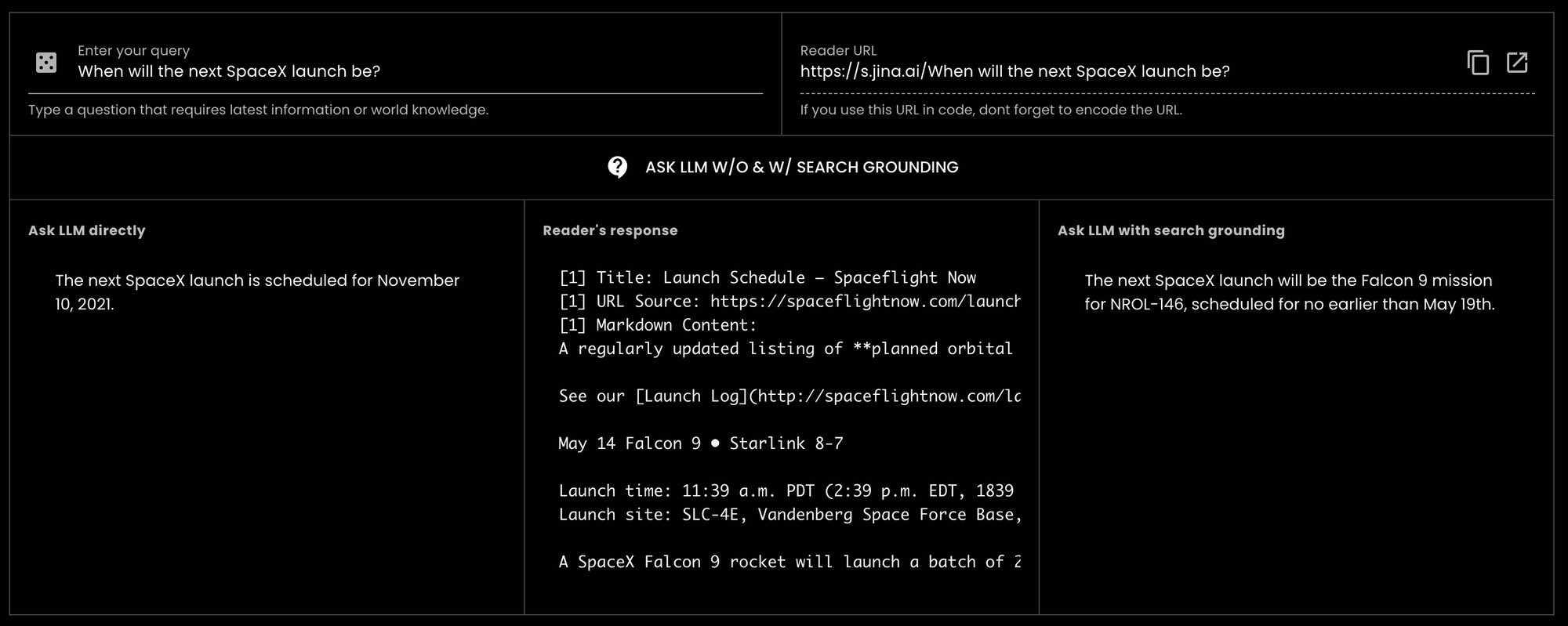
GPT-3.5-turbo 詢問「SpaceX 下一次發射是什麼時候?」(現在是 2024 年 5 月 14 日),模型回覆的是 2021 年的舊資訊。tagJina Reader 如何幫助提供更好的資料依據
之前,用戶可以輕鬆地在網址前加上 https://r.jina.ai,將特定 URL 的文字和圖片內容讀取成 LLM 友好的格式,用於檢查依據和事實驗證。自 4 月 15 日首次發布以來,我們已經處理了超過 1800 萬次來自全球的請求,顯示其受歡迎程度。
今天,我們很高興透過引入搜尋依據 API https://s.jina.ai 進一步推進。只需在查詢前加上這個前綴,Reader 就會搜尋網路並檢索前 5 個結果。每個結果都包含標題、LLM 友好的 markdown(完整內容!不是摘要)以及URL,讓您能夠引用來源。以下是一個例子,您也可以試試我們的即時 demo。
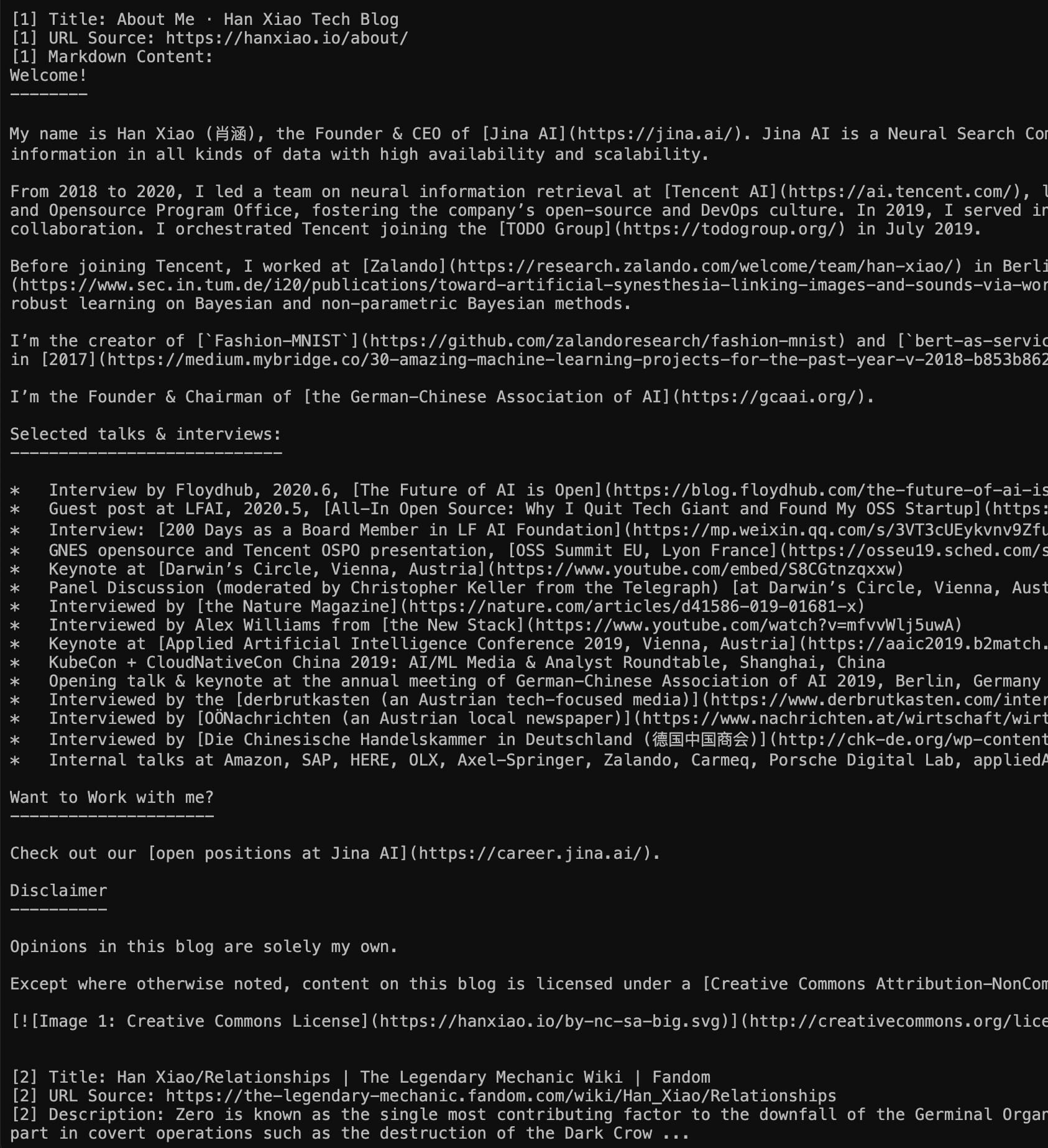
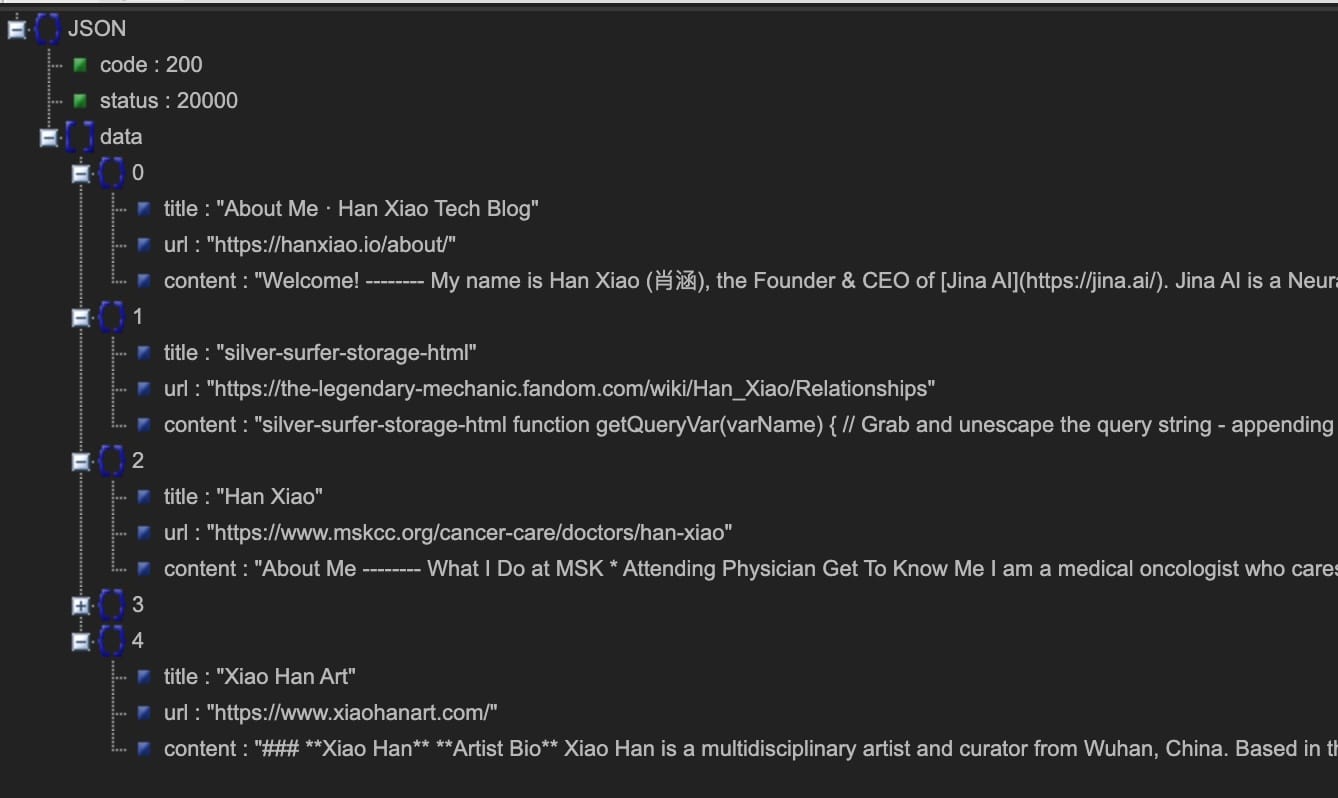
左:Markdown 模式(直接訪問 https://s.jina.ai/who+is+han+xiao);右:JSON 模式(使用 curl https://s.jina.ai/who+is+han+xiao -H 'accept: application/json')。順便說一下,這種自我相關的問題總是作為一個很好的測試案例。
在設計 Reader 的搜尋依據時,我們遵循三個原則:
- 提高事實準確性;
- 獲取最新資訊,即世界知識;
- 將答案與其來源連結。
除了使用極其簡單外,s.jina.ai 還具有高度的可擴展性和客製化能力,因為它利用了現有的靈活且可擴展的 r.jina.ai 基礎設施。您可以透過請求標頭設置參數來控制圖片說明、過濾粒度等。
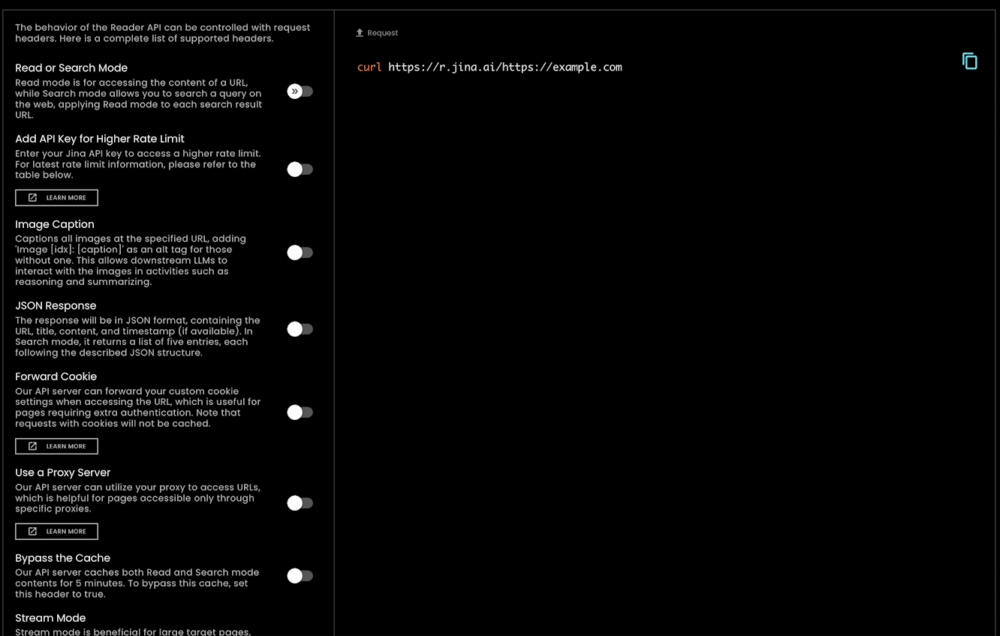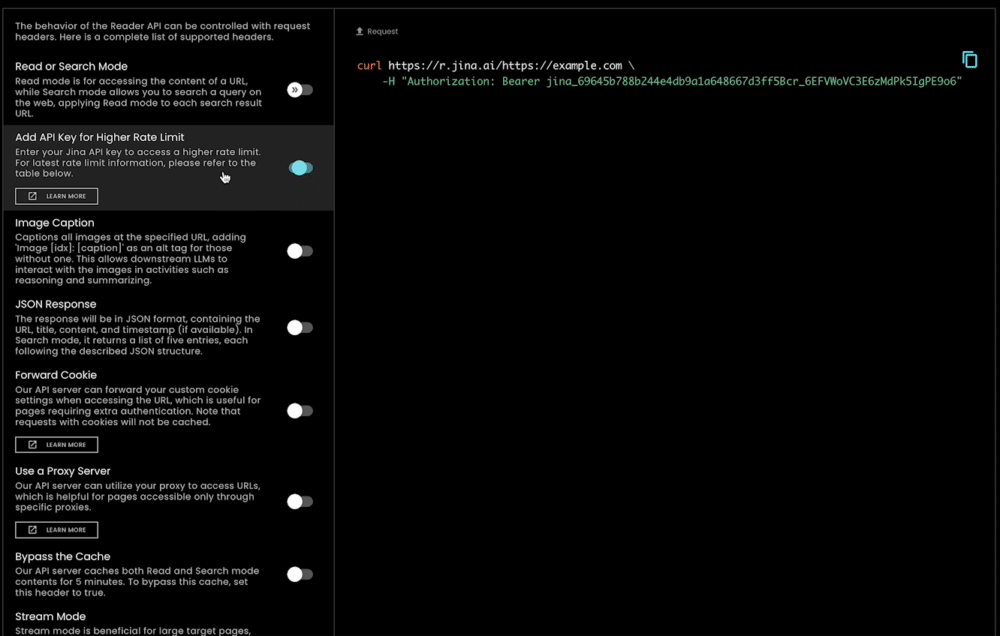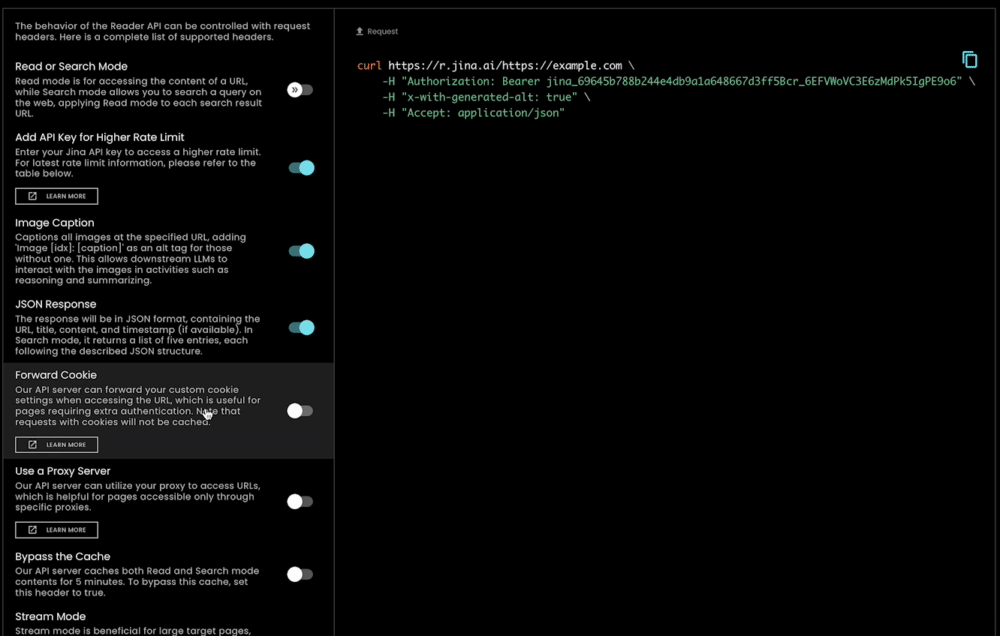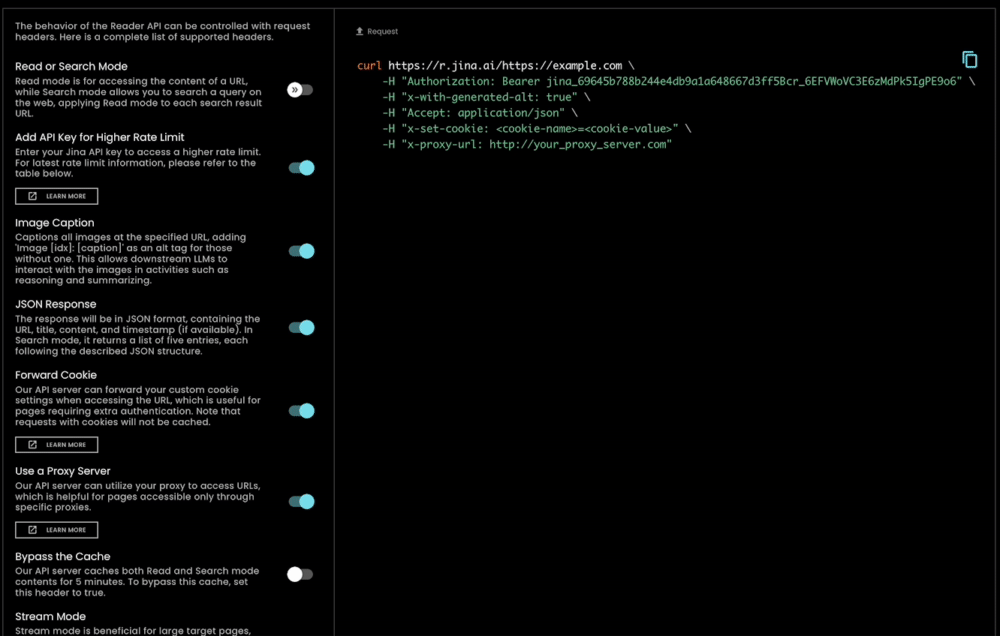
tagJina Reader 作為全面的資料依據解決方案

如果我們結合搜尋依據(s.jina.ai)和檢查依據(r.jina.ai),我們可以為 LLMs、代理和 RAG 系統建立一個非常全面的資料依據解決方案。在一個典型的可信賴 RAG 工作流程中,Jina Reader 的工作方式如下:
- 用戶輸入問題;
- 使用
s.jina.ai從網路獲取最新資訊; - 根據上一步驟的搜尋結果生成初始答案並引用來源;
- 使用
r.jina.ai將答案連結到您自己的 URL;或從步驟 3 返回的來源讀取內嵌 URL 以獲得更深入的依據; - 生成最終答案並向用戶標示潛在未經驗證的聲明。
tag使用 API Keys 提高使用限制
用戶無需授權即可免費使用新的搜尋基礎查詢端點。此外,當在請求標頭中提供 Jina AI API key(可與 Embedding/Reranking API 使用相同的金鑰)時,您可以立即享受 r.jina.ai 每個 IP 每分鐘 200 個請求,以及 s.jina.ai 每個 IP 每分鐘 40 個請求的額度。詳細資訊請參考下表:
| 端點 | 描述 | 無 API key 的使用限制 | 有 API key 的使用限制 | Token 計算方式 | 平均延遲 |
|---|---|---|---|---|---|
r.jina.ai | 讀取 URL 並返回其內容,適用於檢查基礎依據 | 20 RPM | 200 RPM | 基於輸出 tokens | 3 秒 |
s.jina.ai | 在網路上搜尋並返回前 5 個結果,適用於搜尋基礎依據 | 5 RPM | 40 RPM | 基於所有 5 個搜尋結果的輸出 tokens | 30 秒 |
tag結論
我們相信基礎依據對生成式 AI 應用程式至關重要,且建立具有基礎依據的解決方案應該讓每個人都能輕鬆做到。這就是我們推出新的搜尋基礎查詢端點 s.jina.ai 的原因,它讓開發人員能夠輕鬆地將世界知識整合到他們的生成式 AI 應用程式中。我們希望開發人員能夠建立用戶信任,提供可解釋的答案,並激發數百萬用戶的好奇心。



