

對 AI 的討論經常帶有末世論調。部分原因在於末世科幻作品塑造了我們對人工智慧的印象。能夠製造更多機器的智慧機器,幾代以來一直是科幻小說中的常見主題。
許多人對近期 AI 發展帶來的存亡風險大聲疾呼,其中包括許多參與 AI 商業化的企業領袖,甚至一些科學家和研究人員。這已成為 AI 炒作的一部分:如果某個東西強大到能讓看似冷靜的科技和產業標誌性人物都在擔憂世界末日,那它肯定也強大到能夠賺取利潤,對吧?
那麼,我們是否應該擔心 AI 帶來的存亡威脅?我們需要擔心 Sam Altman 會用 ChatGPT 製造出奧創,讓它的AI 軍隊向我們投擲東歐城市嗎?我們應該擔心Peter Thiel 的 Palantir 建造天網並派遣帶著難以解釋的奧地利口音的機器人回到過去殺死我們嗎?
可能不用。業界領袖們至今尚未找到讓 AI 自負盈虧的明確方法,更別說顛覆產業了,更不用說對人類造成可與氣候變遷或核武器相比的威脅。
我們現有的 AI 模型離滅絕人類還差得遠。它們在繪畫手部時都有困難,無法數超過三個物件,認為販賣被老鼠啃過的乳酪是可以接受的,還會用佳得樂進行天主教洗禮。AI 帶來的平凡、非存亡性的風險——比如技術可能助長誤導、騷擾、產生垃圾訊息,以及被不了解其限制的人錯誤使用——已經夠令人擔憂的了。
但人工智慧確實存在一個合理的存亡風險:AI 對....AI 自身構成明確而迫切的危險。
這種擔憂通常被稱為"模型崩塌",並在 Shumailov 等人(2023)和 Alemohammad 等人(2023)的研究中得到了有力的實證。這個概念很簡單:如果你用 AI 生成的數據來訓練 AI 模型,然後用這個結果再去訓練另一個模型,如此重複多代,AI 的表現會客觀上變得越來越差。這就像複印品的複印品再複印。

最近有不少關於模型崩塌的討論,且新聞標題開始出現 關於 AI 用盡數據的報導。如果互聯網充斥著 AI 生成的數據,而人類製作的數據變得越來越難以識別和使用,那麼 AI 模型很快就會遇到品質上限。
同時,在 AI 開發中越來越多地使用合成數據和模型蒸餾技術。這兩種方法都包含使用其他 AI 模型的輸出來訓練 AI 模型。這兩個趨勢似乎相互矛盾。
事情比這更複雜。生成式 AI 會製造垃圾內容並阻礙自身進步嗎?或者 AI 會幫助我們製造更好的 AI?還是兩者都會發生?
我們將在本文中嘗試找到一些答案。
tag模型崩塌
雖然我們很喜歡 Alemohammad 等人發明的"模型自噬失調症(MAD)"這個術語,但"模型崩塌"更朗朗上口,且不涉及希臘語中的自我吞噬含義。用複印品再複印的比喻簡單地闡述了這個問題,但背後的理論還有更多內容。
訓練 AI 模型是一種統計建模,是統計學家和數據科學家長期以來工作的延伸。但在數據科學課程的第一天,你就會學到數據科學家的座右銘:
所有模型都是錯的,但有些是有用的。
這句歸因於George Box 的話,應該作為每個 AI 模型頂部的閃爍警示燈。你總可以為任何數據建立統計模型,該模型也總會給你一個答案,但絕對沒有任何保證這個答案是對的,甚至是接近正確的。
統計模型是某事物的近似。它的輸出可能有用,甚至可能足夠好,但它們仍然是近似值。即使你有一個經過良好驗證的模型,平均來說很準確,它仍然可能且很可能會偶爾犯大錯。
AI 模型繼承了統計建模的所有問題。任何玩過 ChatGPT 或其他大型 AI 模型的人都見過它犯錯。
所以,如果 AI 模型是某個真實事物的近似,那麼用另一個 AI 模型的輸出訓練的 AI 模型就是近似的近似。錯誤會累積,它本質上必然會比訓練它的模型更不準確。
Alemohammad 等人的研究表明,在訓練新的"子代"模型前,在 AI 輸出中添加一些原始訓練數據也無法解決這個問題。這只能減緩模型崩塌,無法阻止它。除非在使用 AI 輸出進行訓練時引入足夠的新的、之前未見過的真實世界數據,否則模型崩塌是不可避免的。
需要多少新數據才足夠取決於難以預測的、具體情況相關的因素,但新的、真實數據越多,AI 生成的數據越少總是更好。
這就是問題所在,因為所有容易獲取的人類製作的數據來源都已耗盡,而網路上 AI 生成的圖像和文字數據卻在快速增長。互聯網上人類製作與 AI 製作內容的比例正在下降,可能正在快速下降。沒有可靠的方法自動檢測 AI 生成的數據,且許多研究人員認為這是不可能的。公眾對 AI 圖像和文字生成模型的使用確保了這個問題會不斷增長,很可能會劇烈增長,且沒有明顯的解決方案。
網路上機器翻譯的數量可能意味著現在已經太遲了。機器翻譯的文本在網路上已經污染我們的數據來源多年,遠在生成式 AI 革命之前就已經存在。根據 Thompson 等人(2024)的研究,可能有一半的網路文本是從其他語言翻譯而來,而這些翻譯中有很大一部分品質低劣,並顯示出機器生成的跡象。這可能會扭曲從這些數據訓練出來的語言模型。
舉例來說,以下是來自 Die Welt der Habsburger 網站的一個頁面截圖,明顯可見機器翻譯的痕跡。"Hamster buying" 是德語單詞 hamstern 的過於直白的翻譯,其實際意思是囤積或恐慌性購買。太多這樣的實例會導致 AI 模型誤以為 "hamster buying" 是英語中的真實用語,並認為德語 hamstern 與寵物倉鼠有關。

在幾乎所有情況下,訓練數據中包含更多 AI 輸出都是不利的。這裡的幾乎很重要,我們將在下面討論兩個例外。
tag合成數據
合成數據是人工生成而非來自真實世界的 AI 訓練或評估數據。Nikolenko(2021)追溯合成數據的起源至 1960 年代的早期電腦視覺專案,並概述了它作為該領域重要元素的歷史。
使用合成數據有許多原因。其中最重要的一個是對抗偏見。
大型語言模型和圖像生成器因偏見問題而收到許多高調的投訴。"偏見"在統計學中有嚴格的定義,但這些投訴通常反映的是道德、社會和政治層面的考量,這些並沒有簡單的數學形式或工程解決方案。
不容易察覺的偏見更具破壞性,也更難修正。AI 模型學習複製的模式來自其訓練數據,當數據存在系統性缺陷時,偏見就不可避免。我們期望 AI 能做的事情越多──模型的輸入越多樣化──它就越有可能因為在訓練中沒有見過足夠的類似案例而出錯。
合成數據在當今 AI 訓練中的主要作用是確保訓練數據中包含足夠多某些特定情況的範例,這些情況在可用的自然數據中可能並不充足。
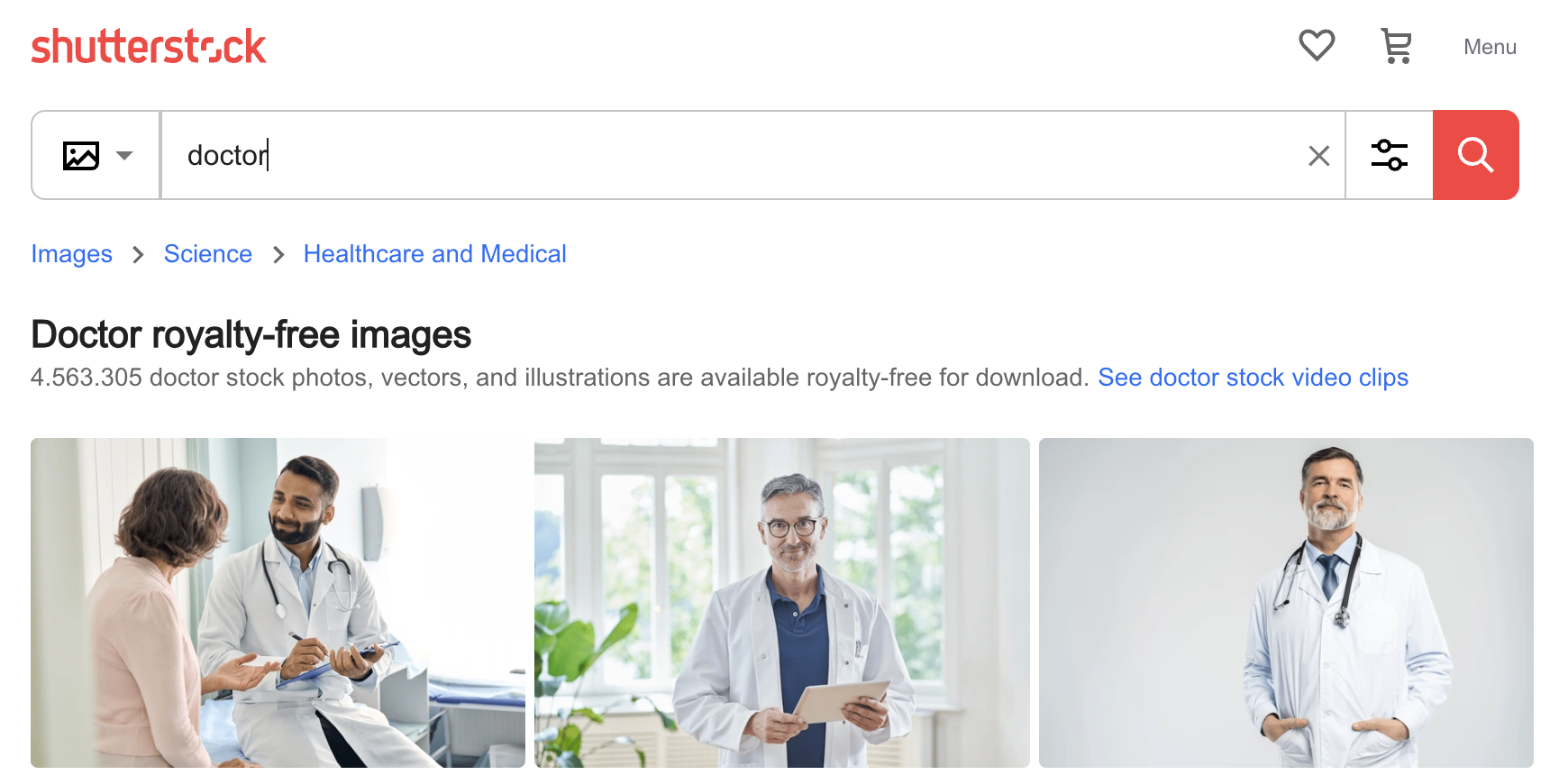
以下是 MidJourney 在接收 "doctor" 提示詞後生成的圖像:四個男性,三個白人,三個穿著白大褂並戴著聽診器,其中一個明顯年長。這並不反映大多數國家和情境中真實醫生的種族、年齡、性別或著裝,但可能反映了網路上可以找到的標記圖像。

再次提示時,它生成了一個女性和三個男性,全都是白人,雖然其中一個是卡通形象。AI 有時確實很奇怪。

這種特定的偏見是 AI 圖像生成器一直在試圖防止的,所以我們現在從相同系統得到的結果不像可能一年前那樣明顯帶有偏見。偏見仍然明顯存在,但什麼才是無偏見的結果並不明確。
不過,要弄清楚 AI 如何產生這些偏見並不難。以下是在 Shutterstock 圖片網站上搜索 "doctor" 時找到的前三張圖片:三個男性,其中兩個是年長的白人。AI 的偏見就是其訓練的偏見,如果你使用未經策劃的數據訓練模型,你總是會發現這些類型的偏見。
緩解這個問題的一種方法是使用 AI 圖像生成器來創建年輕醫生、女性醫生、有色人種醫生,以及穿著手術服、西裝或其他服裝的醫生的圖像,然後將它們納入訓練中。這樣使用的合成數據可以改善 AI 模型的表現,至少相對於某些外部標準而言,而不是導致模型崩潰。然而,人為扭曲訓練數據分佈可能會產生意想不到的副作用,就像 Google 最近發現的那樣。
tag模型蒸餾
模型蒸餾是一種直接從一個模型訓練另一個模型的技術。一個已訓練的生成模型──"教師"──創建所需的數據量來訓練一個未訓練或訓練較少的"學生"模型。
如你所料,"學生"模型永遠不可能比"教師"更好。乍看之下,這樣訓練模型似乎沒有意義,但這確實有其好處。主要的一個好處是"學生"模型可能比"教師"小得多、更快或更有效率,同時仍能近似其表現。
模型大小、訓練數據和最終表現之間的關係很複雜。然而,總的來說,在其他條件相同的情況下:
- 更大的模型比小型模型表現更好。
- 使用更多或更好的訓練數據(或至少更多樣化的訓練數據)訓練的模型比使用較少或較差數據訓練的模型表現更好。
這意味著小型模型有時可以表現得和大型模型一樣好。例如,jina-embeddings-v2-base-en 在標準基準測試中明顯優於許多更大的模型:
| Model | Size in parameters | MTEB average score |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |

| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |





