


Wie viele andere Menschen höre auch ich eine Menge Podcasts. Einige handeln von Science Fiction. Einige von Paläontologie. Und manche von seltsamen mittelalterlichen Typen. Leider keine True Crime Podcasts, abgesehen von meinem gelegentlich schlechten Geschmack.
Aber... es ist mühsam, all diese Podcasts zu hören. Und das ist noch nicht einmal das Schlimmste. Ich abonniere auch viele News-Feeds. Und das bedeutet eine Menge Lesearbeit. Es wäre fantastisch, wenn ich einfach den gesamten Inhalt dieser News-Feeds nehmen, in eine fünfminütige Zusammenfassung packen und mir von meinem Handy vorlesen lassen könnte, während ich mir morgens die Zähne putze.
Sie können sich wahrscheinlich denken, worauf das hinausläuft. Ich entwickle mit Python ein Tool, das (größtenteils) den Jina Tech Stack nutzt, um meinen persönlichen täglichen Nachrichten-Podcast zu erstellen.
Wenn Sie direkt hören möchten, wie es klingt, können Sie unten reinhören:
tagWas ist ein News-Feed?
Zunächst nenne ich sie "News-Feeds", da die meisten Menschen mit den Begriffen RSS oder Atom Feeds nicht vertraut sind. Kurz gesagt ist ein Feed eine strukturierte Liste von Artikeln, die von einem Blog oder einer Nachrichtenquelle veröffentlicht wurden, sortiert von neu nach alt. Viele Websites bieten sie an, und es gibt verschiedene Apps und Websites, mit denen Sie all Ihre Feeds importieren können. So können Sie alle Ihre Nachrichten in einer App lesen, ohne die Websites von Ars Technica, Taylor Swift Fansites und der Washington Post besuchen zu müssen:
Sie sind eine uralte Technologie aus der prähistorischen Web-Ära, aber viele Websites unterstützen sie, einschließlich Jina AIs eigenem Blog (hier ist unser Feed).
Kurz gesagt ermöglichen Feeds es Ihnen, alle Ihre Nachrichten an einem Ort zu lesen und dabei die ganze Sidebar-Werbung und Anzeigen zu überspringen. In diesem Beitrag werden wir News-Feeds verwenden, um die neuesten Beiträge von den Websites zu finden und herunterzuladen, denen wir folgen.
tagStarten wir diese Feed-Frenzy
pip installs und das Setzen von Schlüsseln werden in diesem Beitrag übersprungen. Wenn Sie mitmachen möchten, folgen Sie dem Notebook für die vollständige Erfahrung und bleiben Sie bei diesem Beitrag für den größeren Überblick.Colab Link | GitHub Link
Um die Magie geschehen zu lassen, verwenden wir verschiedene Dienste und Python-Bibliotheken:
- Feedparser: Eine Python-Bibliothek zum Herunterladen und Extrahieren von Inhalten aus News-Feeds.
- Jina Reader: Jinas API zur Extraktion des reinen Inhalts aus jedem Artikel, ohne überflüssige Elemente wie Header, Footer und Seitenleisten.
- PromptPerfect: Prompts-as-Services fasst jeden Artikel zusammen und kombiniert diese Zusammenfassungen in einem einzigen Absatz, im Stil eines NPR-Nachrichtensprechers.
- gTTS: Googles Text-to-Speech-Bibliothek, um die Nachrichten vorzulesen.
Das ist alles, was wir in diesem Beitrag behandeln werden. Wenn Sie einen Podcast-Feed für Ihren personalisierten Podcast erstellen möchten, empfehlen wir Ihnen, andere Quellen zu konsultieren.
tagFeeds herunterladen
Da dies nur ein einfaches Beispiel ist, beschränken wir uns auf einige News-Feeds von The Register und OSNews, zwei Tech-News-Websites.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]Mit Feedparser können wir die Feeds herunterladen und dann die Artikel-Links aus jedem Feed extrahieren:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagExtrahieren von Artikeltext mit Jina Reader
Jeder Feed enthält Links zu den einzelnen Artikeln auf der jeweiligen Website. Wenn wir einfach diese Webseite herunterladen, erhalten wir eine Menge HTML, einschließlich Seitenleisten, Header, Footer und anderen überflüssigen Elementen, die wir nicht brauchen. Wenn Sie dies einem LLM füttern, ist es, als würden Sie Gras kauen. Klar, das LLM kann es verarbeiten, aber es ist nicht das, was es natürlicherweise fressen möchte.
Was ein LLM wirklich will, ist etwas, das nahe an reinem Text ist. Jina Reader wandelt einen Artikel in Markdown um.

Dadurch sieht es eher so aus:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...Wir haben dies gekürzt, da der vollständige Artikel zu lang wäre. Aber Sie können sehen, dass es sich um klaren, menschenlesbaren (Markdown-)Text handelt.
Statt diesem:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...Wir mussten dies kürzen, bevor wir überhaupt zum eigentlichen Inhalt kamen. Es gibt einfach zu viel nicht-menschenlesbaren Müll.
Indem wir dem LLM etwas geben, das es natürlicher verarbeiten kann (wie Markdown statt HTML), kann es uns bessere Ergebnisse liefern. Andernfalls ist es, als würde man einem Löwen Doritos füttern. Klar, er kann sie essen, aber er wird nicht sein bestes Löwen-Selbst sein, wenn er diese Ernährung beibehält.
Um nur den Text in einer menschenlesbaren Form zu extrahieren, verwenden wir die Jina Reader API:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url> gehen, zum Beispiel https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagZusammenfassen der Artikel mit PromptPerfect
Da es möglicherweise sehr viele Artikel gibt, verwenden wir ein LLM, um jeden einzeln zusammenzufassen. Wenn wir sie einfach alle zusammenfügen und dem LLM zum Zusammenfassen geben würden, könnte es an zu vielen Tokens ersticken.
Dies wird davon abhängen, wie viele Artikel Sie verarbeiten möchten. Für nur wenige könnte es sich lohnen, sie alle in einen langen String zu konkatenieren und nur einen Aufruf zu machen, was Zeit und Geld spart. In diesem Beispiel gehen wir jedoch davon aus, dass wir es mit einer größeren Anzahl von Artikeln zu tun haben.
Zum Zusammenfassen verwenden wir einen Prompt-as-a-Service von PromptPerfect.
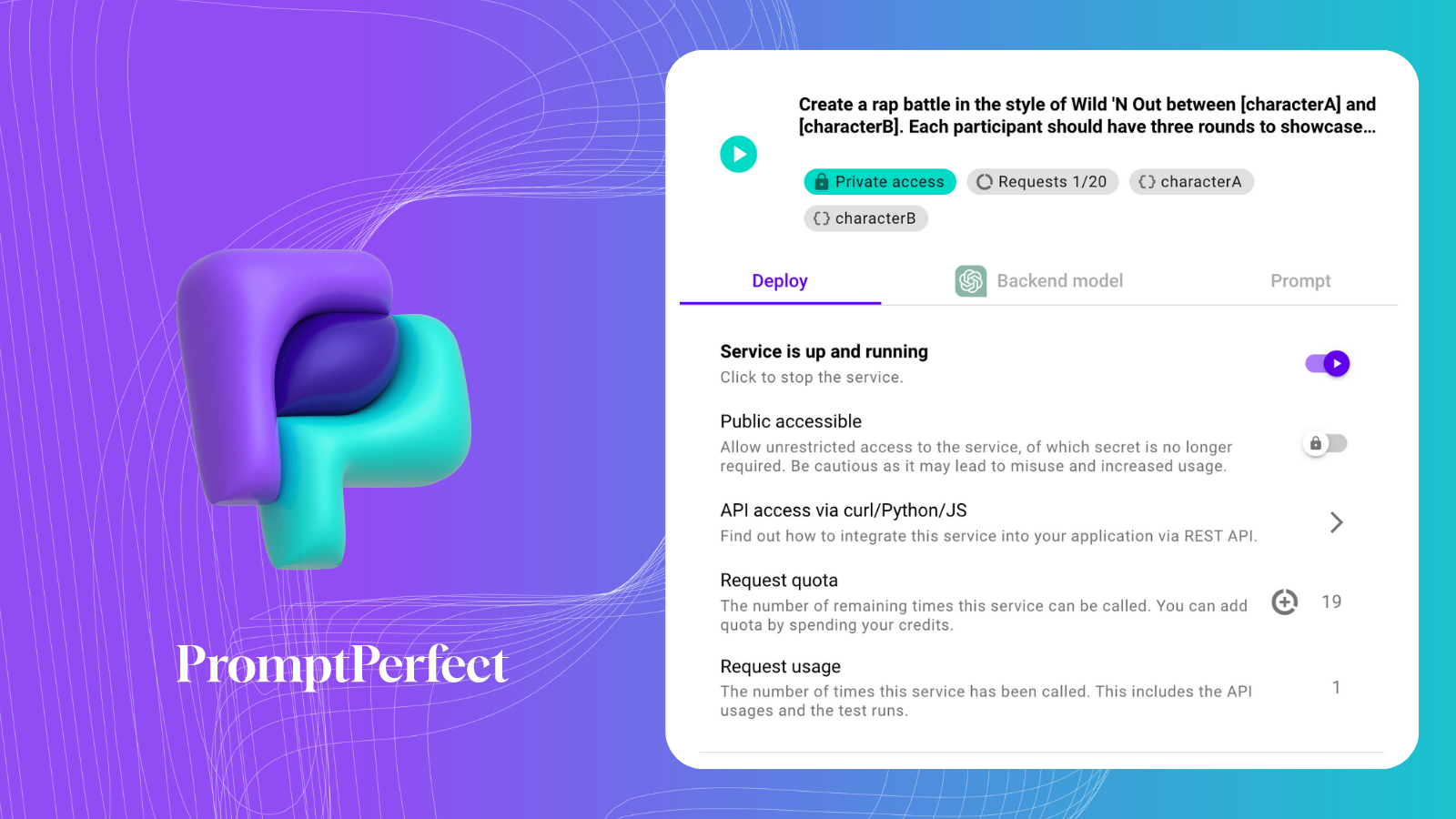
Hier ist unser Prompt-as-Service:

Wir werden eine Funktion dafür schreiben, da wir später in diesem Beitrag einen weiteren Prompt-as-Service aufrufen werden:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.textWir werden dann jede Zusammenfassung zu einer Liste hinzufügen und sie schließlich in eine Markdown-Aufzählungsliste zusammenführen:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagGenerieren eines Nachrichtenberichts mit PromptPerfect
Nachdem wir diese Aufzählungsliste haben, können wir sie an einen weiteren Prompt-as-a-Service senden, um einen Nachrichtenbericht zu generieren, der wie natürliche Nachrichtensprecherstimme klingt:

Der vollständige Prompt lautet:
Sie sind ein NPR-Technologie-Nachrichtenredakteur. Sie haben folgende Nachrichtenzusammenfassungen erhalten:
[summaries]
Ihre Aufgabe ist es, einen einzigen Absatz als Überblick über die Nachrichten zu geben und dabei jeden Punkt auf organische Weise abzudecken, mit Übergängen zum nächsten Punkt. Sie können die Reihenfolge der Punkte ändern, wenn das sinnvoll erscheint, und Duplikate zusammenführen.
Sie werden einen einzigen Absatz als Skript ausgeben, der organisch klingt und in den täglichen NPR-Nachrichten vorgelesen werden soll. Das Skript sollte nicht länger als fünf Minuten zum Vorlesen benötigen.
Wir erhalten das Nachrichtenskript mit diesem Code:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)Hier ist der finale Text:
In den heutigen Technologie-Nachrichten haben wir eine Reihe von Updates und Entwicklungen zu besprechen. Zunächst bietet das Tiny11 Builder-Tool Benutzern die Möglichkeit, Windows 11 zu entschlacken und ein maßgeschneidertes Image nach ihren Vorlieben zu erstellen. Weiter geht es in die Welt der Videospiele, wo wir uns mit den versteckten Komponenten in Super Nintendo-Kartuschen befassen und die Technologie beleuchten, die Gamer in den 90er Jahren faszinierte. Im Bereich Software hat der Niri Tiling Window Manager für Wayland ein großes Update veröffentlicht, das neue Funktionen wie unendliches Scrollen und verbesserte Animationen bietet. Im Bereich KI ist Microsofts Copilot-Funktion bei der Auslieferung an Windows Insider auf einige Schwierigkeiten gestoßen, wobei Bugs und störendes Verhalten zu einem Stopp der Bereitstellung führten. Währenddessen äußert das britische Information Commissioner's Office Bedenken bezüglich Googles Privacy Sandbox und hinterfragt deren Auswirkungen auf Privatsphäre und Wettbewerb. Zu guter Letzt hat die US Federal Aviation Administration ihre Anforderungen für Startlizenzen aktualisiert und verlangt nun von Wiedereintrittsfahrzeugen eine Lizenz vor dem Start, nach einem Vorfall mit Varda Space Industries. Diese vielfältigen Tech-Stories unterstreichen die fortlaufenden Entwicklungen und Herausforderungen in der Tech-Welt.
tagVorlesen der Nachrichten
Um den Text vorzulesen, verwenden wir die Google TTS-Bibliothek.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")Dies wird uns eine finale Audiodatei liefern:
tagNächste Schritte
Wir werden den Rest der Podcast-Erstellung in diesem Beitrag nicht behandeln. Das ist nicht unsere Stärke, und genau wie bei medizinischen Ratschlägen sollten Sie uns wahrscheinlich nicht zuhören, wenn es um die Details der Einrichtung eines Podcast-Feeds, das Hochladen auf Spotify, Apple Podcasts usw. geht. Für medizinische oder Podcast-Ratschläge wenden Sie sich bitte an Ihren Arzt bzw. Joe Rogan.
Was die weiteren Möglichkeiten von Jina Reader betrifft, denken Sie an all die RAG-Anwendungen, die Sie durch das Herunterladen lesbarer Versionen beliebiger Webseiten erstellen können. Oder sehen Sie bei PromptPerfect, wie es YouTubern (oder Marketern, falls das Ihr Ding ist) noch weiter helfen kann.
