



Im April 2024 haben wir Jina Reader eingeführt,eine API,die jede Webseite in LLM-freundliches Markdown umwandelt,indem einfach r.jina.ai als URL-Präfix hinzugefügt wird. Im September 2024 haben wir zwei kleine Sprachmodelle,reader-lm-0.5b und reader-lm-1.5b,veröffentlicht,die speziell für die Umwandlung von rohem HTML in sauberes Markdown entwickelt wurden. Heute stellen wir die zweite Generation von ReaderLM vor,ein Sprachmodell mit 1,5B Parametern,das rohes HTML mit überlegener Genauigkeit und verbesserter Handhabung längerer Kontexte in schön formatiertes Markdown oder JSON umwandelt. ReaderLM-v2 verarbeitet bis zu 512K Token kombinierte Ein- und Ausgabelänge. Das Modell bietet mehrsprachige Unterstützung für 29 Sprachen,einschließlich Englisch,Chinesisch,Japanisch,Koreanisch,Französisch,Spanisch,Portugiesisch,Deutsch,Italienisch,Russisch,Vietnamesisch,Thai,Arabisch und mehr.
Dank seines neuen Trainingsparadigmas und hochwertigeren Trainingsdaten stellt ReaderLM-v2 einen bedeutenden Fortschritt gegenüber seinem Vorgänger dar,besonders bei der Verarbeitung von Langform-Inhalten und der Markdown-Syntax-Generierung. Während die erste Generation die HTML-zu-Markdown-Konvertierung als eine „selektive Kopier"-Aufgabe betrachtete,behandelt v2 es als echten Übersetzungsprozess. Diese Änderung ermöglicht es dem Modell,die Markdown-Syntax meisterhaft zu nutzen und bei der Generierung komplexer Elemente wie Code-Fences,verschachtelter Listen,Tabellen und LaTex-Gleichungen zu brillieren.
Der Vergleich der HTML-zu-Markdown-Ergebnisse der HackerNews-Startseite zwischen ReaderLM v2,ReaderLM 1.5b,Claude 3.5 Sonnet und Gemini 2.0 Flash zeigt ReaderLM v2's einzigartigen Charakter und Leistung. ReaderLM v2 überzeugt durch die umfassende Bewahrung von Informationen aus dem rohen HTML,einschließlich der ursprünglichen HackerNews-Links,während es den Inhalt intelligent mithilfe der Markdown-Syntax strukturiert. Das Modell verwendet verschachtelte Listen zur Organisation lokaler Elemente (Punkte,Zeitstempel und Kommentare) und behält gleichzeitig eine konsistente globale Formatierung durch eine angemessene Überschriftenhierarchie (h1- und h2-Tags) bei.
Eine große Herausforderung in unserer ersten Version war die Degeneration nach der Generierung langer Sequenzen,besonders in Form von Wiederholungen und Schleifen. Das Modell begann entweder,dasselbe Token zu wiederholen oder blieb in einer Schleife stecken,wobei es eine kurze Tokensequenz durchlief,bis die maximale Ausgabelänge erreicht war. ReaderLM-v2 mildert dieses Problem deutlich durch das Hinzufügen von kontrastivem Verlust während des Trainings—seine Leistung bleibt konsistent,unabhängig von der Kontextlänge oder der Menge der bereits generierten Token.

Über die Markdown-Konvertierung hinaus führt ReaderLM-v2 die direkte HTML-zu-JSON-Generierung ein,die es Benutzern ermöglicht,spezifische Informationen aus rohem HTML entsprechend einem vorgegebenen JSON-Schema zu extrahieren. Dieser End-to-End-Ansatz eliminiert die Notwendigkeit einer intermediären Markdown-Konvertierung,eine häufige Anforderung in vielen LLM-gestützten Datenreinigungs- und Extraktions-Pipelines.

In sowohl quantitativen als auch qualitativen Benchmarks übertrifft ReaderLM-v2 weitaus größere Modelle wie Qwen2.5-32B-Instruct, Gemini2-flash-expr und GPT-4o-2024-08-06 bei HTML-zu-Markdown-Aufgaben, während es bei HTML-zu-JSON-Extraktionsaufgaben vergleichbare Leistung zeigt – und das alles mit deutlich weniger Parametern.

ReaderLM-v2-pro ist ein exklusiver Premium-Checkpoint, der unseren Enterprise-Kunden vorbehalten ist und zusätzliches Training sowie Optimierungen bietet. 


Diese Ergebnisse zeigen, dass ein gut konzipiertes Modell mit 1,5B Parametern die Leistung von viel größeren Modellen bei strukturierten Datenextraktionsaufgaben nicht nur erreichen, sondern oft übertreffen kann. Die fortschreitenden Verbesserungen von ReaderLM-v2 zu ReaderLM-v2-pro demonstrieren die Effektivität unserer neuen Trainingsstrategie bei der Verbesserung der Modellleistung bei gleichzeitiger Beibehaltung der Recheneffizienz.
tagErste Schritte
tagÜber die Reader API

ReaderLM-v2 ist jetzt in unsere Reader API integriert. Um es zu nutzen, geben Sie einfach x-engine: readerlm-v2 in Ihren Request-Headers an und aktivieren Sie Response-Streaming mit -H 'Accept: text/event-stream':
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
Sie können es ohne API-Schlüssel mit einer niedrigeren Rate-Limit testen. Für höhere Rate-Limits können Sie einen API-Schlüssel erwerben. Bitte beachten Sie, dass ReaderLM-v2-Anfragen die 3-fache normale Token-Anzahl von Ihrem API-Schlüssel verbrauchen. Diese Funktion befindet sich derzeit in der Beta-Phase, während wir mit dem GCP-Team zusammenarbeiten, um die GPU-Effizienz zu optimieren und die Modellverfügbarkeit zu erhöhen.
tagAuf Google Colab

Beachten Sie, dass die kostenlose T4 GPU Einschränkungen hat—sie unterstützt kein bfloat16 oder Flash Attention 2, was zu höherem Speicherverbrauch und langsamerer Verarbeitung längerer Eingaben führt. Dennoch verarbeitet ReaderLM v2 erfolgreich unsere gesamte Rechtsseite unter diesen Einschränkungen und erreicht Verarbeitungsgeschwindigkeiten von 67 Token/s Eingabe und 36 Token/s Ausgabe. Für den Produktiveinsatz empfehlen wir eine RTX 3090/4090 für optimale Leistung.
Der einfachste Weg, ReaderLM-v2 in einer gehosteten Umgebung zu testen, ist über unser Colab-Notebook, das HTML-zu-Markdown-Konvertierung, JSON-Extraktion und instruktionsbasierte Verarbeitung am Beispiel der HackerNews-Startseite demonstriert. Das Notebook ist für Colabs kostenlosen T4 GPU-Tier optimiert und benötigt vllm und triton für Beschleunigung und Ausführung. Sie können es gerne mit jeder beliebigen Website testen.
HTML zu Markdown Konvertierung
Sie können die create_prompt Hilfsfunktion verwenden, um einfach einen Prompt für die Konvertierung von HTML zu Markdown zu erstellen:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result wird ein String sein, der in Markdown-Backticks als Code-Fence eingeschlossen ist. Sie können auch die Standardeinstellungen überschreiben, um verschiedene Ausgaben zu erkunden, zum Beispiel:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()Da unsere Trainingsdaten möglicherweise nicht alle Arten von Anweisungen abdecken, insbesondere Aufgaben, die mehrstufiges Denken erfordern, kommen die zuverlässigsten Ergebnisse von der HTML-zu-Markdown-Konvertierung. Für die effektivste Informationsextraktion empfehlen wir die Verwendung von JSON-Schema wie unten gezeigt:
HTML zu JSON Extraktion mit JSON Schema
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result wird ein String sein, der in JSON-formatierten Code-Fence-Backticks eingeschlossen ist, nicht ein tatsächliches JSON/dict-Objekt. Sie können Python verwenden, um den String in ein richtiges Dictionary oder JSON-Objekt für die weitere Verarbeitung zu parsen.
tagIn Produktion: Verfügbar auf CSP
ReaderLM-v2 ist auf AWS SageMaker, Azure und GCP Marketplace verfügbar. Wenn Sie diese Modelle über diese Plattformen hinaus oder On-Premises in Ihrem Unternehmen nutzen möchten, beachten Sie, dass dieses Modell und ReaderLM-v2-pro beide unter CC BY-NC 4.0 lizenziert sind. Für Anfragen zur kommerziellen Nutzung oder den Zugang zu ReaderLM-v2-pro kontaktieren Sie uns gerne.

tagQuantitative Evaluation
Wir evaluieren ReaderLM-v2 in drei strukturierten Datenextraktionsaufgaben im Vergleich zu State-of-the-Art Modellen: GPT-4o-2024-08-06, Gemini2-flash-expr und Qwen2.5-32B-Instruct. Unser Bewertungsrahmen kombiniert Metriken, die sowohl die Genauigkeit des Inhalts als auch die strukturelle Treue messen. ReaderLM-v2 ist die öffentlich verfügbare Version mit offenen Gewichten, während ReaderLM-v2-pro ein exklusiver Premium-Checkpoint für unsere Unternehmenskunden ist, der zusätzliches Training und Optimierungen enthält. Beachten Sie, dass unser reader-lm-1.5b der ersten Generation nur bei der Hauptinhaltsextraktionsaufgabe evaluiert wird, da es keine Funktionen für instruierte Extraktion oder JSON-Extraktion unterstützt.
tagEvaluationsmetriken
Für HTML-zu-Markdown-Aufgaben verwenden wir sieben komplementäre Metriken. Hinweis: ↑ bedeutet höher ist besser, ↓ bedeutet niedriger ist besser
- ROUGE-L (↑): Misst die längste gemeinsame Teilsequenz zwischen generiertem und Referenztext und erfasst Inhaltserhaltung und strukturelle Ähnlichkeit. Bereich: 0-1, höhere Werte zeigen bessere Sequenzübereinstimmung.
- WER (Word Error Rate) (↓): Quantifiziert die minimale Anzahl von Wort-Level-Bearbeitungen, die erforderlich sind, um den generierten Text in die Referenz umzuwandeln. Niedrigere Werte bedeuten weniger notwendige Korrekturen.
- SUB (Substitutions) (↓): Zählt die Anzahl der erforderlichen Wortsubstitutionen. Niedrigere Werte deuten auf bessere Wortgenauigkeit hin.
- INS (Insertions) (↓): Misst die Anzahl der Wörter, die eingefügt werden müssen, um der Referenz zu entsprechen. Niedrigere Werte zeigen bessere Vollständigkeit.
- Levenshtein Distance (↓): Berechnet die minimale Anzahl von Einzelzeichen-Bearbeitungen. Niedrigere Werte deuten auf bessere Zeichengenauigkeit hin.
- Damerau-Levenshtein Distance (↓): Ähnlich wie Levenshtein, berücksichtigt aber auch Zeichenvertauschungen. Niedrigere Werte zeigen bessere Zeichenübereinstimmung.
- Jaro-Winkler Similarity (↑): Betont übereinstimmende Zeichen am Stringanfang, besonders nützlich für die Bewertung der Dokumentstrukturerhaltung. Bereich: 0-1, höhere Werte zeigen bessere Ähnlichkeit.
Für HTML-zu-JSON-Aufgaben betrachten wir es als Retrieval-Aufgabe und verwenden vier Metriken aus dem Information Retrieval:
- F1 Score (↑): Harmonisches Mittel von Precision und Recall, liefert Gesamtgenauigkeit. Bereich: 0-1.
- Precision (↑): Anteil der korrekt extrahierten Informationen an allen Extraktionen. Bereich: 0-1.
- Recall (↑): Anteil der korrekt extrahierten Informationen aus allen verfügbaren Informationen. Bereich: 0-1.
- Pass-Rate (↑): Anteil der Ausgaben, die valides JSON sind und dem Schema entsprechen. Bereich: 0-1.
tagHauptinhalt HTML-zu-Markdown-Aufgabe
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tagInstruierte HTML-zu-Markdown-Aufgabe
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagSchema-basierte HTML-zu-JSON-Aufgabe
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 stellt einen bedeutenden Fortschritt in allen Aufgaben dar. Bei der Hauptinhaltsextraktion erzielt ReaderLM-v2-pro die beste Leistung in fünf von sieben Metriken, mit überlegenen ROUGE-L (0,86), WER (0,39), Levenshtein (0,20), Damerau (928,15) und Jaro-Winkler (0,83) Werten. Diese Ergebnisse zeigen umfassende Verbesserungen sowohl in der Inhaltserhaltung als auch in der strukturellen Genauigkeit im Vergleich zu seiner Basisversion und größeren Modellen.
Bei der instruierten Extraktion führt ReaderLM-v2 und ReaderLM-v2-pro bei ROUGE-L (0,72), Substitutionsrate (70,16), Levenshtein-Distanz (0,37) und Jaro-Winkler-Ähnlichkeit (0,75, gleichauf mit Basisversion). Während GPT-4o Vorteile bei WER und Damerau-Distanz zeigt, behält ReaderLM-v2-pro eine bessere Gesamtstruktur und Genauigkeit bei. Bei der JSON-Extraktion zeigt das Modell eine wettbewerbsfähige Leistung und bleibt innerhalb von 0,01-0,02 F1-Punkten von größeren Modellen, während es hohe Pass-Raten (0,99) erreicht.
tagQualitative Evaluation
Während unserer Analyse vonBei reader-lm-1.5b haben wir beobachtet, dass quantitative Metriken allein die Modellleistung nicht vollständig erfassen. Numerische Auswertungen spiegelten manchmal nicht die wahrgenommene Qualität wider - Fälle, in denen niedrige Metrikwerte visuell zufriedenstellendes Markdown produzierten oder hohe Werte suboptimale Ergebnisse lieferten. Um diese Diskrepanz zu beheben, führten wir systematische qualitative Bewertungen über 10 verschiedene HTML-Quellen durch, darunter Nachrichtenartikel, Blogbeiträge, Produktseiten, E-Commerce-Websites und juristische Dokumente in Englisch, Japanisch und Chinesisch. Das Testkorpus legte den Schwerpunkt auf anspruchsvolle Formatierungselemente wie mehrzeilige Tabellen, dynamische Layouts, LaTeX-Formeln, verlinkte Tabellen und verschachtelte Listen und bot einen umfassenderen Einblick in die realen Fähigkeiten des Modells.
tagEvaluierungsmetriken
Unsere menschliche Bewertung konzentrierte sich auf drei Hauptdimensionen, wobei die Outputs auf einer Skala von 1-5 bewertet wurden:
Inhaltsintegrität - Bewertet die Bewahrung semantischer Informationen während der HTML-zu-Markdown-Konvertierung, einschließlich:
- Genauigkeit und Vollständigkeit des Textinhalts
- Erhaltung von Links, Bildern, Code-Blöcken, Formeln und Zitaten
- Beibehaltung der Textformatierung und Link/Bild-URLs
Strukturelle Genauigkeit - Beurteilt die korrekte Konvertierung von HTML-Strukturelementen zu Markdown:
- Erhaltung der Header-Hierarchie
- Genauigkeit der Listenverschachtelung
- Tabellentreue
- Formatierung von Code-Blöcken und Zitaten
Formatkonformität - Misst die Einhaltung von Markdown-Syntaxstandards:
- Korrekte Syntaxverwendung für Header (#), Listen (*, +, -), Tabellen, Code-Blöcke (```)
- Saubere Formatierung ohne überflüssige Leerzeichen oder nicht standardmäßige Syntax
- Konsistente und lesbare gerenderte Ausgabe
Bei der manuellen Bewertung von über 10 HTML-Seiten hat jedes Bewertungskriterium eine maximale Punktzahl von 50 Punkten. ReaderLM-v2 zeigte in allen Dimensionen eine starke Leistung:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
Bei der Inhaltsvollständigkeit überzeugte es besonders bei der Erkennung komplexer Elemente, insbesondere bei LaTeX-Formeln, verschachtelten Listen und Code-Blöcken. Das Modell behielt eine hohe Genauigkeit bei der Verarbeitung komplexer Inhaltsstrukturen bei, während konkurrierende Modelle oft H1-Header wegließen (reader-lm-1.5b), Inhalte abschnitten (Claude 3.5) oder rohe HTML-Tags beibehielten (Gemini-2.0-flash).
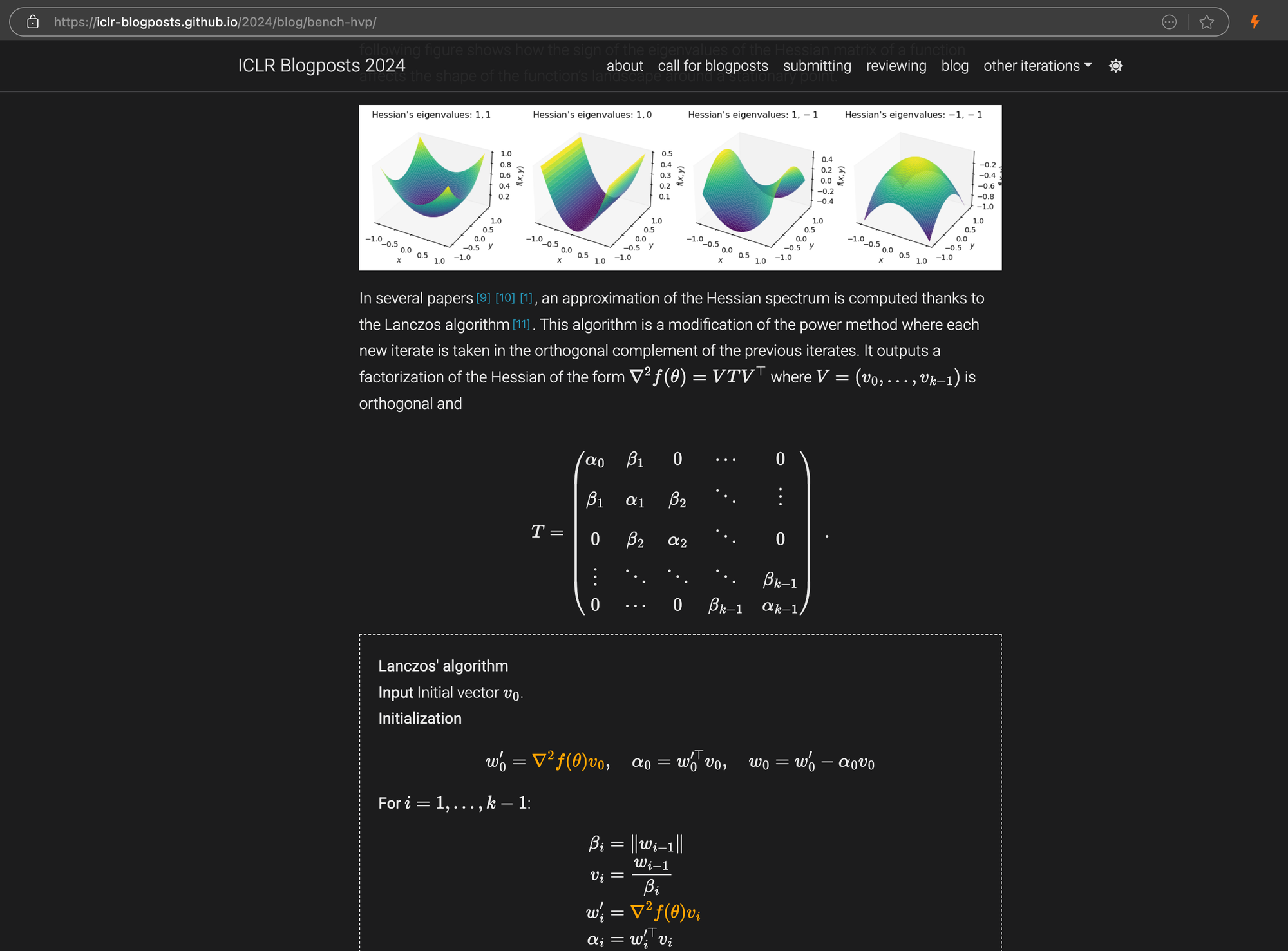
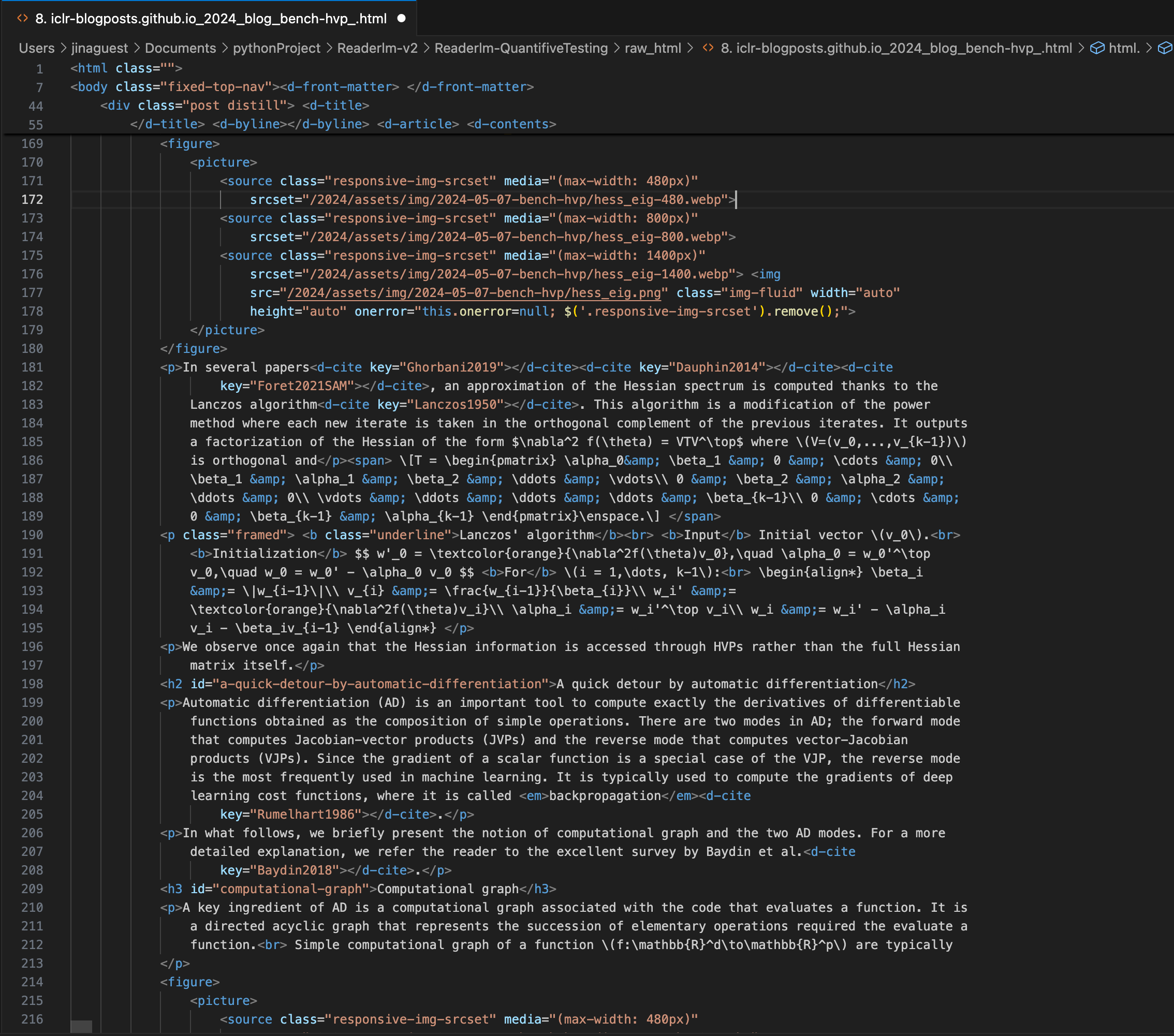
Ein ICLR-Blogbeitrag mit komplexen LaTeX-Gleichungen in Markdown, der den HTML-Quellcode im rechten Panel zeigt.
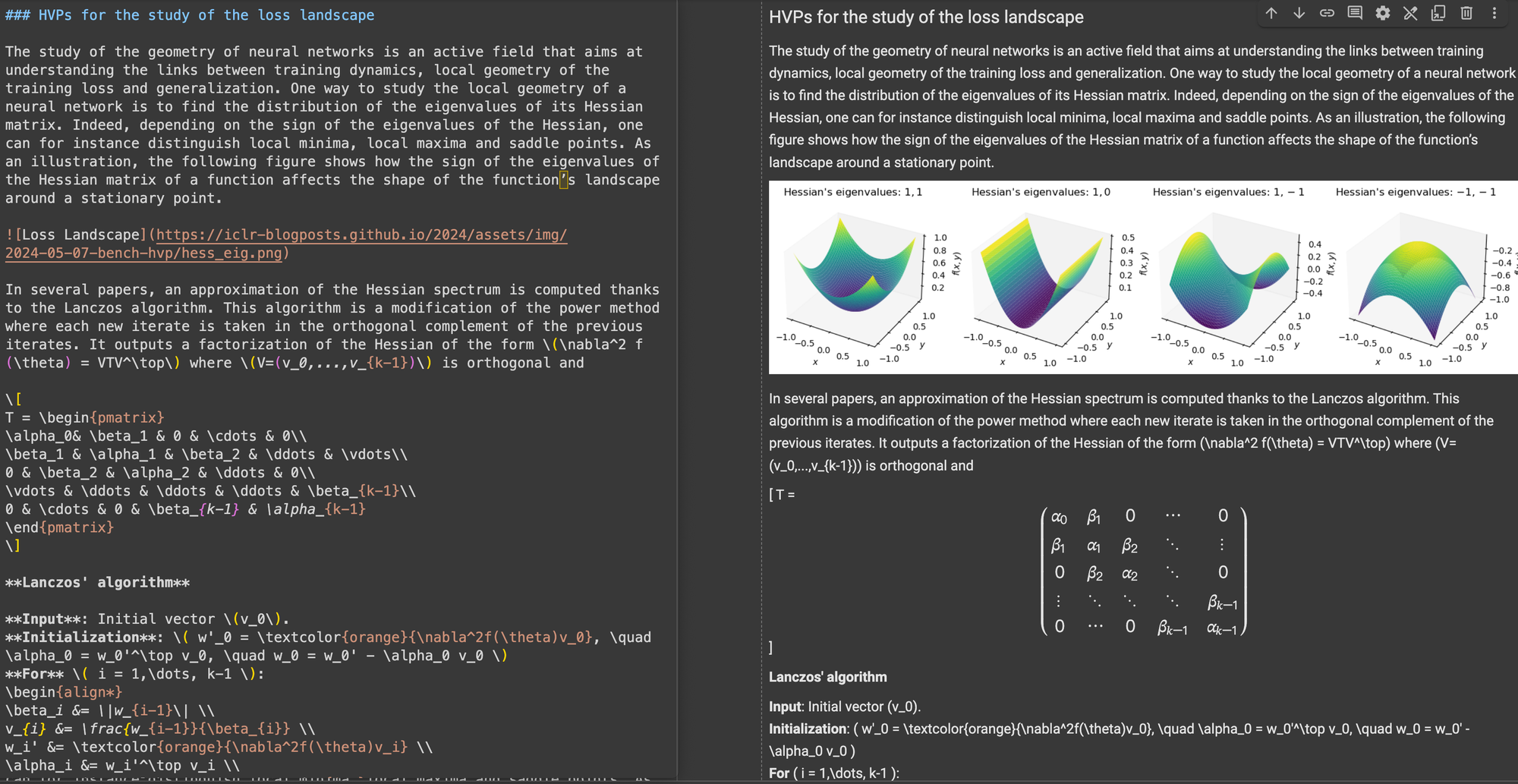
\[...\] (und seine HTML-Äquivalente) durch Markdown-Standardbegrenzer wie $...$ für Inline-Gleichungen und $$...$$ für Display-Gleichungen. Dies hilft, Syntaxkonflikte in der Markdown-Interpretation zu vermeiden.In der strukturellen Genauigkeit zeigte ReaderLM-v2 eine Optimierung für gängige Web-Strukturen. Bei Hacker News-Fällen rekonstruierte es beispielsweise erfolgreich vollständige Links und optimierte die Listendarstellung. Das Modell bewältigte komplexe Nicht-Blog-HTML-Strukturen, die für ReaderLM-v1 eine Herausforderung darstellten.
Bei der Formatkonformität zeigte ReaderLM-v2 besondere Stärke im Umgang mit Inhalten wie Hacker News, Blogs und WeChat-Artikeln. Während andere große Sprachmodelle gut mit markdown-ähnlichen Quellen umgehen konnten, hatten sie Schwierigkeiten mit traditionellen Websites, die mehr Interpretation und Neuformatierung erforderten.
Unsere Analyse ergab, dass gpt-4o bei der Verarbeitung kürzerer Websites hervorragend ist und im Vergleich zu anderen Modellen ein überlegenes Verständnis von Website-Struktur und Formatierung zeigt. Bei längeren Inhalten hat gpt-4o jedoch Schwierigkeiten mit der Vollständigkeit und lässt oft Teile am Anfang und Ende des Textes weg. Wir haben eine vergleichende Analyse der Outputs von gpt-4o, ReaderLM-v2 und ReaderLM-v2-pro am Beispiel der Zillow-Website beigefügt.
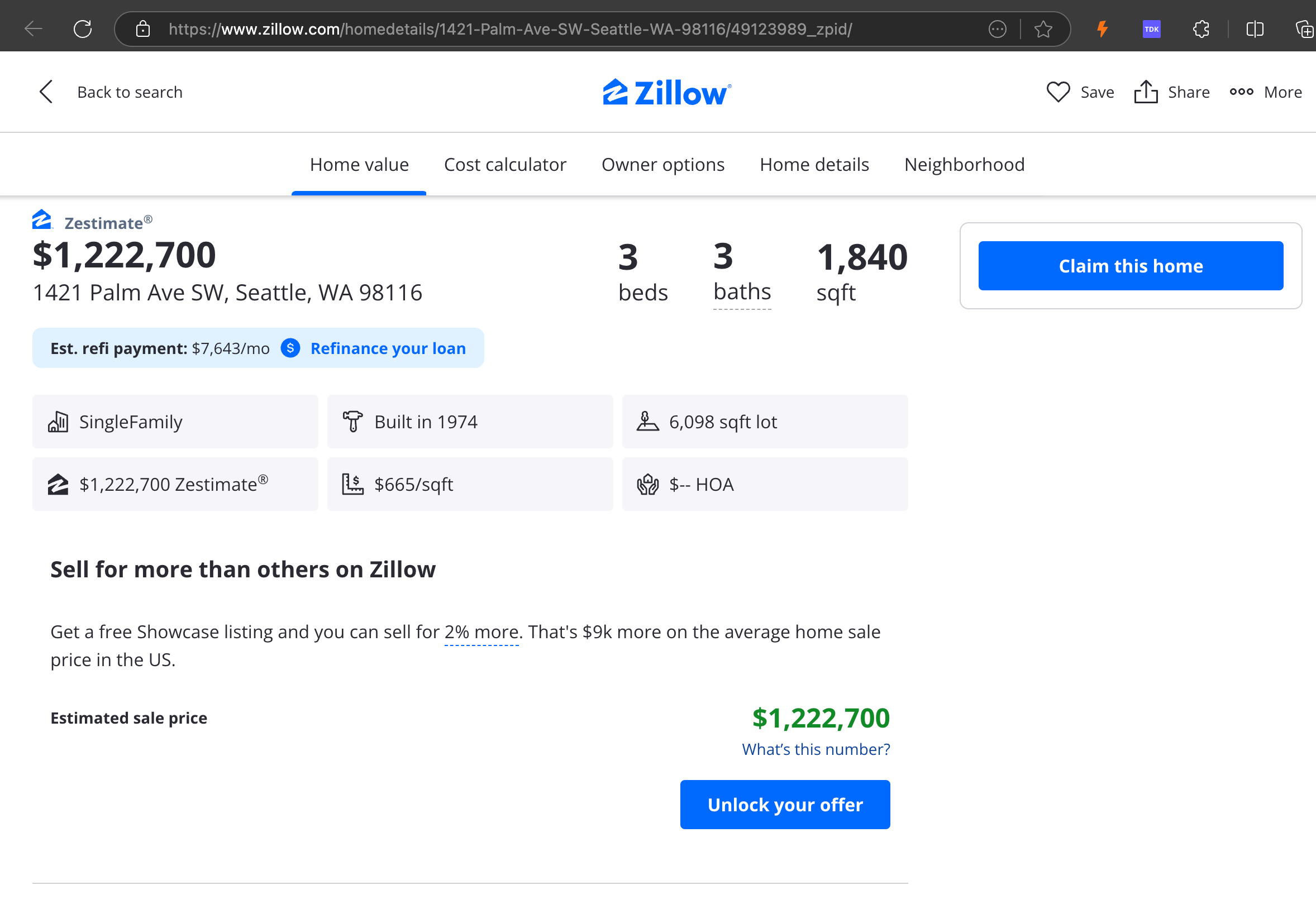
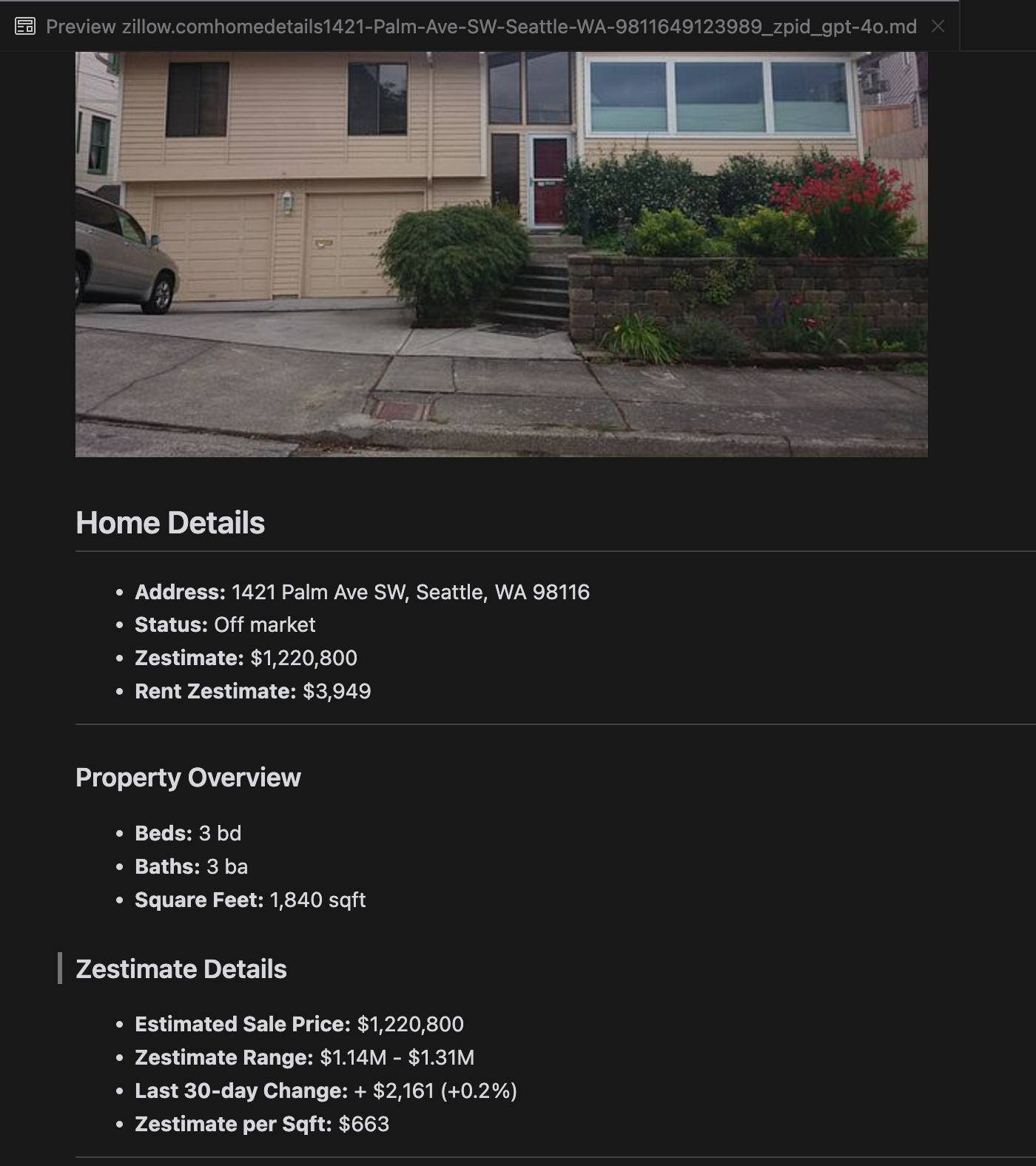
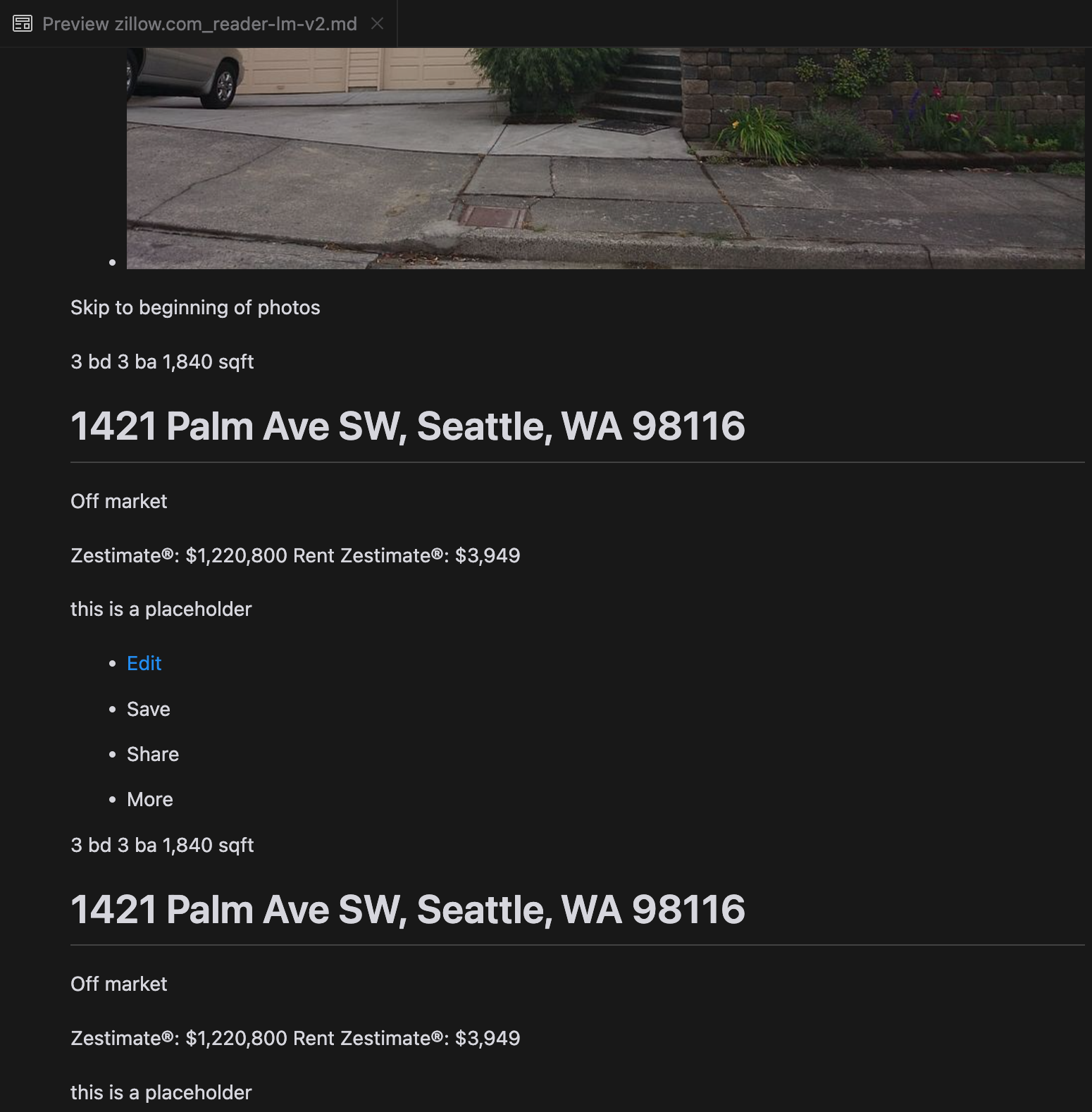
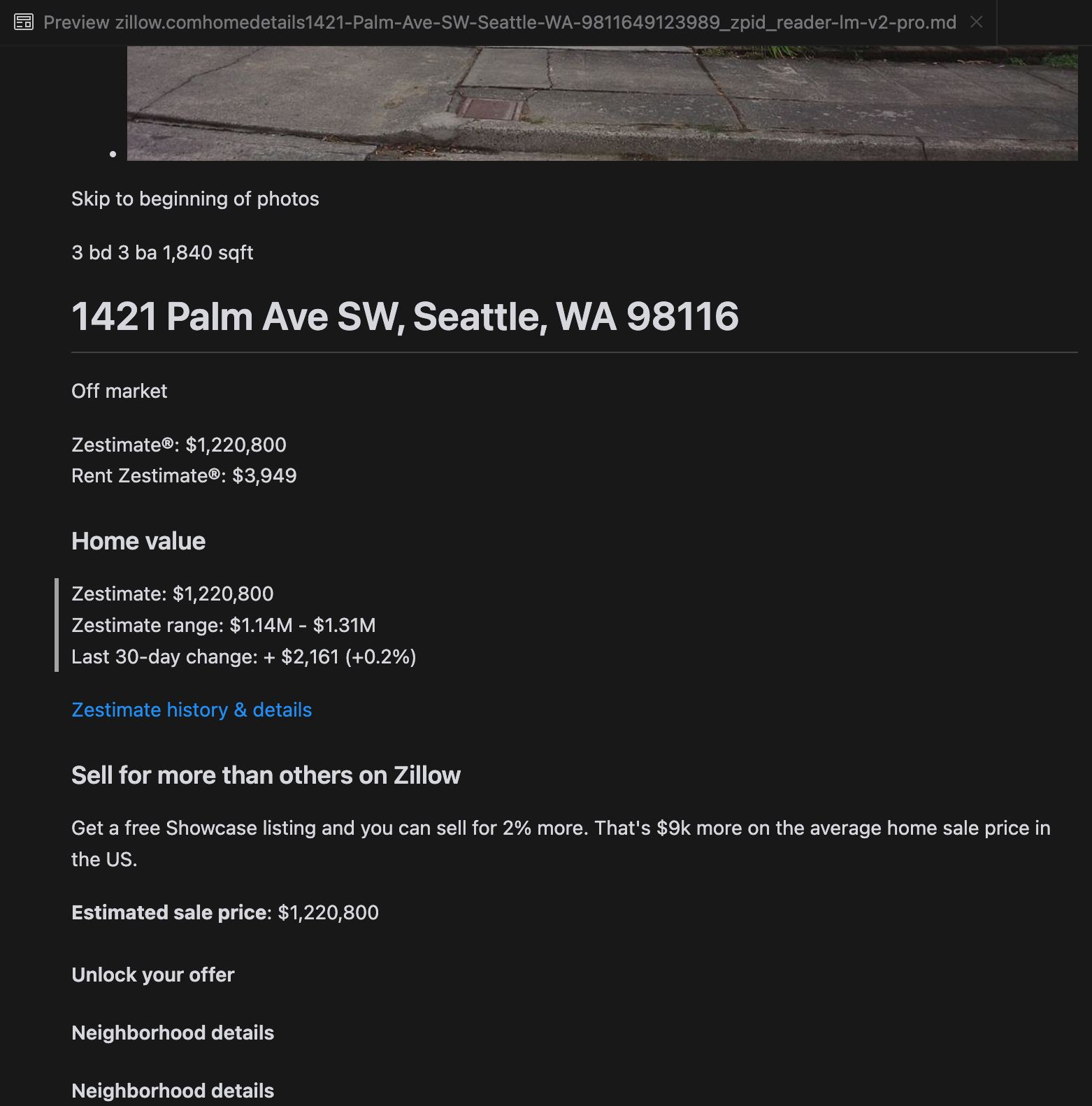
Ein Vergleich der gerenderten Markdown-Ausgaben von gpt-4o (links), ReaderLM-v2 (Mitte) und ReaderLM-v2-pro (rechts).
Für bestimmte anspruchsvolle Fälle wie Produkt-Landingpages und Behördendokumente blieb die Leistung von ReaderLM-v2 und ReaderLM-v2-pro robust, hat aber noch Verbesserungspotenzial. Komplexe mathematische Formeln und Code in ICLR-Blogbeiträgen stellten für die meisten Modelle eine Herausforderung dar, wobei ReaderLM-v2 diese Fälle besser handhabte als die Baseline Reader API.
tagWie wir ReaderLM v2 trainiert haben
ReaderLM-v2 basiert auf Qwen2.5-1.5B-Instruction, einem kompakten Basismodell, das für seine Effizienz bei der Anweisungsbefolgung und bei Aufgaben mit langem Kontext bekannt ist. In diesem Abschnitt beschreiben wir, wie wir das ReaderLM-v2 trainiert haben, mit Fokus auf Datenvorbereitung, Trainingsmethoden und den Herausforderungen, denen wir begegnet sind.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagDatenvorbereitung
Der Erfolg von ReaderLM-v2 hing größtenteils von der Qualität seiner Trainingsdaten ab. Wir erstellten den html-markdown-1m Datensatz, der eine Million HTML-Dokumente aus dem Internet enthielt. Im Durchschnitt enthielt jedes Dokument 56.000 Token, was die Länge und Komplexität realer Webdaten widerspiegelt. Zur Vorbereitung dieses Datensatzes bereinigten wir die HTML-Dateien durch Entfernen unnötiger Elemente wie JavaScript und CSS, während wir wichtige Struktur- und semantische Elemente beibehielten. Nach der Bereinigung verwendeten wir Jina Reader, um HTML-Dateien mithilfe von Regex-Mustern und Heuristiken in Markdown umzuwandeln.
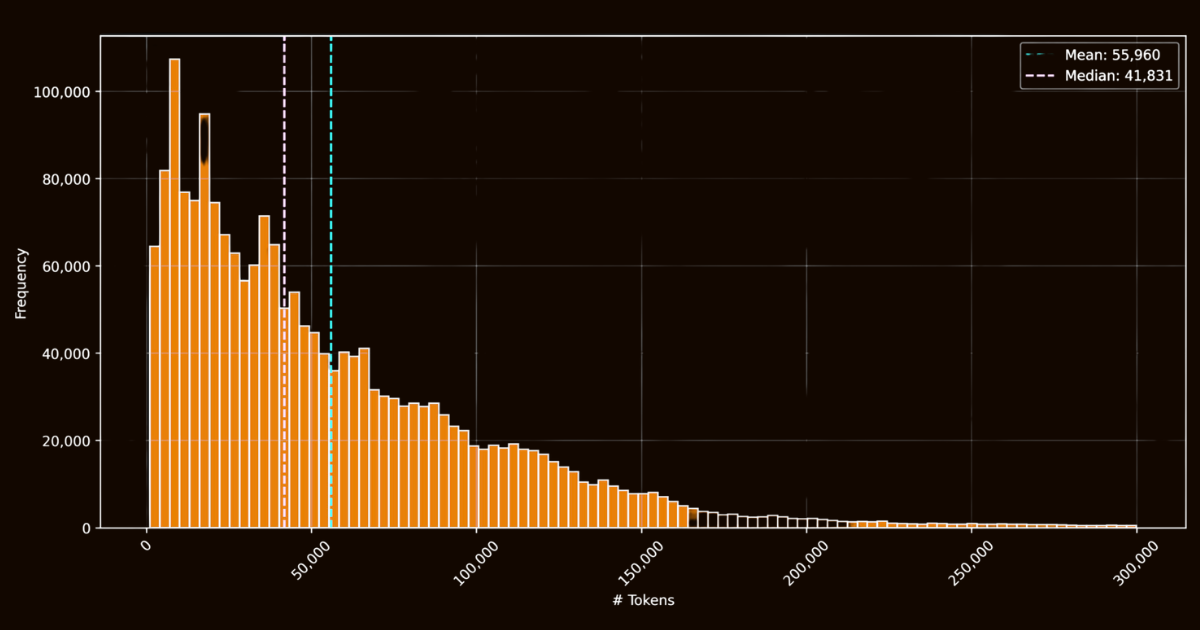
html-markdown-1m DatensatzWährend dies einen funktionalen Basis-Datensatz schuf, zeigte sich eine kritische Einschränkung: Modelle, die ausschließlich mit diesen direkten Konvertierungen trainiert wurden, würden im Wesentlichen nur lernen, die von Jina Reader verwendeten Regex-Muster und Heuristiken nachzuahmen. Dies wurde bei reader-lm-0.5b/1.5b deutlich, deren Leistungsgrenze durch die Qualität dieser regelbasierten Konvertierungen eingeschränkt war.
Um diese Einschränkungen zu adressieren, entwickelten wir eine dreistufige Pipeline, die sich auf das Qwen2.5-32B-Instruction Modell stützte, was für die Erstellung eines hochwertigen synthetischen Datensatzes essentiell war.

Qwen2.5-32B-Instruction- Entwurf: Wir generierten erste Markdown- und JSON-Ausgaben basierend auf den dem Modell gegebenen Anweisungen. Diese Ausgaben waren zwar vielfältig, aber oft verrauscht oder inkonsistent.
- Verfeinerung: Die generierten Entwürfe wurden durch Entfernen redundanter Inhalte, Durchsetzen struktureller Konsistenz und Ausrichtung an gewünschten Formaten verbessert. Dieser Schritt stellte sicher, dass die Daten sauber und mit den Aufgabenanforderungen übereinstimmten.
- Kritik: Verfeinerte Ausgaben wurden anhand der ursprünglichen Anweisungen evaluiert. Nur Daten, die diese Evaluierung bestanden, wurden in den finalen Datensatz aufgenommen. Dieser iterative Ansatz stellte sicher, dass die Trainingsdaten die notwendigen Qualitätsstandards für strukturierte Datenextraktion erfüllten.
tagTrainingsprozess
Unser Trainingsprozess umfasste mehrere Phasen, die auf die Herausforderungen der Verarbeitung von Dokumenten mit langem Kontext zugeschnitten waren.
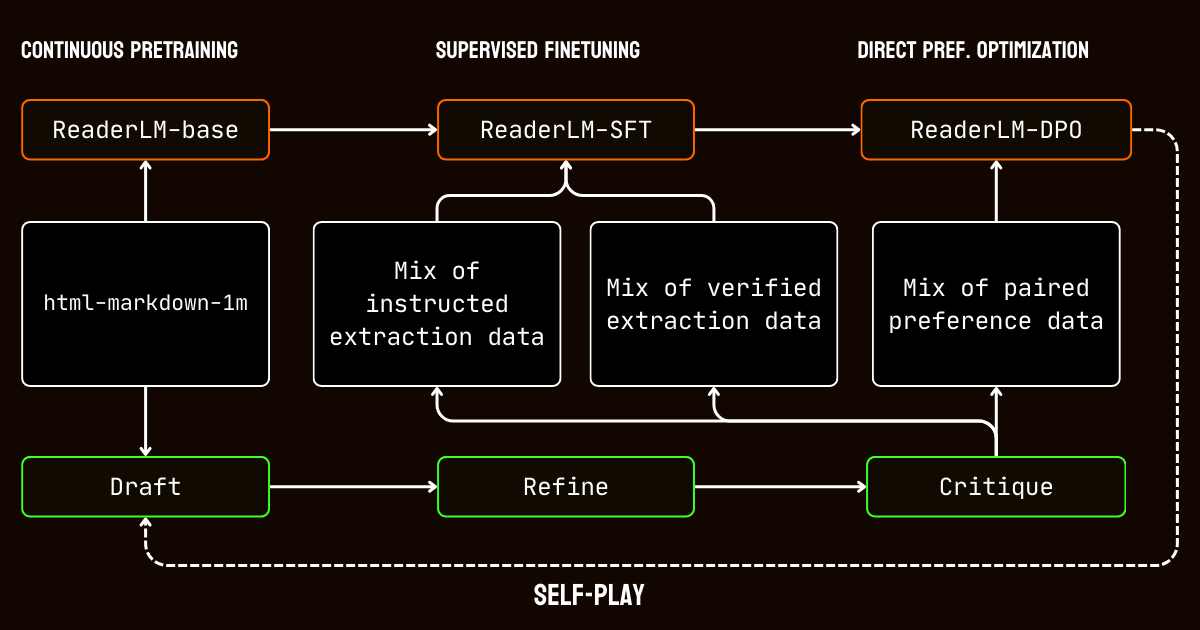
Wir begannen mit dem Vortraining für langen Kontext, unter Verwendung des html-markdown-1m Datensatzes. Techniken wie Ring-Zag-Attention und Rotary Positional Encoding (RoPE) wurden verwendet, um die Kontextlänge des Modells schrittweise von 32.768 Token auf 256.000 Token zu erweitern. Um Stabilität und Effizienz zu gewährleisten, verwendeten wir einen graduellen Trainingsansatz, beginnend mit kürzeren Sequenzen und schrittweiser Erhöhung der Kontextlänge.
Nach dem Vortraining gingen wir zum überwachten Feintuning (SFT) über. Diese Phase nutzte die verfeinerten Datensätze, die im Datenvorbereitungsprozess generiert wurden. Diese Datensätze enthielten detaillierte Anweisungen für Markdown- und JSON-Extraktionsaufgaben sowie Beispiele für die Verfeinerung von Entwürfen. Jeder Datensatz wurde sorgfältig konzipiert, um dem Modell beim Lernen spezifischer Aufgaben zu helfen, wie etwa der Identifizierung von Hauptinhalten oder der Einhaltung schemabasierter JSON-Strukturen.
Dann wendeten wir Direct Preference Optimization (DPO) an, um die Ausgaben des Modells mit hochwertigen Ergebnissen in Einklang zu bringen. In dieser Phase wurde das Modell mit Paaren von Entwurfs- und verfeinerten Antworten trainiert. Durch das Lernen, die verfeinerten Ausgaben zu priorisieren, verinnerlichte das Modell die subtilen Unterschiede, die polierte und aufgabenspezifische Ergebnisse definieren.
Schließlich implementierten wir Selbstspiel-Reinforcement-Tuning, einen iterativen Prozess, bei dem das Modell seine eigenen Ausgaben generierte, verfeinerte und evaluierte. Dieser Zyklus ermöglichte es dem Modell, sich kontinuierlich zu verbessern, ohne zusätzliche externe Überwachung zu benötigen. Durch die Nutzung seiner eigenen Kritiken und Verfeinerungen verbesserte das Modell schrittweise seine Fähigkeit, genaue und strukturierte Ausgaben zu produzieren.
tagFazit
Im April 2024 wurde Jina Reader die erste LLM-freundliche Markdown-API. Sie setzte einen neuen Trend, erlangte breite Community-Akzeptanz und inspirierte uns vor allem dazu, kleine Sprachmodelle für Datenbereinigung und -extraktion zu entwickeln. Heute setzen wir mit ReaderLM-v2 erneut neue Maßstäbe und erfüllen die Versprechen, die wir im letzten September gegeben haben: bessere Handhabung langer Kontexte, Unterstützung für Eingabeanweisungen und die Fähigkeit, spezifische Webseiteninhalte in Markdown-Format zu extrahieren. Einmal mehr haben wir gezeigt, dass kleine Sprachmodelle mit sorgfältigem Training und Kalibrierung eine State-of-the-Art-Leistung erreichen können, die größere Modelle übertrifft.
Während des Trainingsprozesses von ReaderLM-v2 identifizierten wir zwei Erkenntnisse. Eine effektive Strategie war das Training spezialisierter Modelle auf separaten Datensätzen, die auf spezifische Aufgaben zugeschnitten waren. Diese aufgabenspezifischen Modelle wurden später durch lineare Parameterinterpolation verschmolzen. Während dieser Ansatz zusätzlichen Aufwand erforderte, half er dabei, die einzigartigen Stärken jedes spezialisierten Modells im endgültigen vereinheitlichten System zu bewahren.
Der iterative Datensyntheseprozess erwies sich als entscheidend für den Erfolg unseres Modells. Durch wiederholte Verfeinerung und Auswertung synthetischer Daten konnten wir die Modellleistung deutlich über einfache regelbasierte Ansätze hinaus verbessern. Diese iterative Strategie war, trotz der Herausforderungen bei der Aufrechterhaltung konsistenter Kritikauswertungen und der Verwaltung von Rechenkosten, essentiell, um die Grenzen der Verwendung von regex- und heuristikbasierten Trainingsdaten aus Jina Reader zu überwinden. Dies zeigt sich deutlich am Leistungsunterschied zwischen reader-lm-1.5b, das stark auf den regelbasierten Konvertierungen von Jina Reader basiert, und ReaderLM-v2, das von diesem iterativen Verfeinerungsprozess profitiert.
Wir freuen uns auf Ihr Feedback, wie ReaderLM-v2 Ihre Datenqualität verbessert. Mit Blick auf die Zukunft planen wir die Erweiterung um multimodale Fähigkeiten, insbesondere für gescannte Dokumente, und eine weitere Optimierung der Generierungsgeschwindigkeit. Wenn Sie an einer auf Ihren spezifischen Bereich zugeschnittenen Version von ReaderLM interessiert sind, kontaktieren Sie uns bitte.
