


Como mucha gente, escucho varios podcasts. Algunos son sobre ciencia ficción. Algunos son sobre paleontología. Y algunos son sobre tipos medievales extraños. No hay true crime desafortunadamente, excepto por mi ocasional mal gusto.
Pero... es agotador escuchar todos estos podcasts. Y ni siquiera son lo peor. También estoy suscrito a muchos feeds de noticias. Y eso puede ser mucha lectura. Sería fantástico si pudiera tomar todo el contenido de esos feeds de noticias, convertirlo en un resumen de cinco minutos y hacer que mi teléfono lo lea mientras me cepillo los dientes por la mañana.
Supongo que pueden ver hacia dónde va esto. Estoy usando Python para construir una herramienta con (mayormente) el stack tecnológico de Jina para crear mi podcast diario personalizado de noticias.
Si quieres adelantarte y simplemente escuchar cómo suena, puedes escucharlo a continuación:
tag¿Qué es un Feed de Noticias?
Primero, los llamo "feeds de noticias" ya que la mayoría de la gente no está familiarizada con los términos RSS o Atom feeds. En resumen, un feed es una lista estructurada de artículos publicados por un blog o fuente de noticias, ordenados de nuevos a antiguos. Muchos sitios los ofrecen, y hay varias apps y sitios web que te permiten importar todos tus feeds, permitiéndote leer todas tus noticias en una sola app, sin tener que visitar los sitios web de Ars Technica, sitios de fans de Taylor Swift, y el Washington Post:
Son una tecnología antigua de la web prehistórica, pero muchos sitios web los soportan, incluyendo el propio blog de Jina AI (aquí está nuestro feed).
En resumen, los feeds te permiten leer todas tus noticias en un solo lugar, saltándote toda la basura de las barras laterales y los anuncios. En este post, usaremos feeds de noticias para encontrar y descargar las últimas publicaciones de los sitios que seguimos.
tagComencemos esta Locura por los Feeds
pip install y la configuración de claves en esta publicación se omiten, así que si quieres seguir el proceso, consulta el notebook para la experiencia completa y quédate con esta publicación para tener una visión general.Enlace de Colab | Enlace de GitHub
Para hacer realidad la magia, vamos a utilizar varios servicios y bibliotecas de Python:
- Feedparser: Una biblioteca de Python para descargar y extraer contenido de feeds de noticias.
- Jina Reader: API de Jina para extraer solo el contenido de cada artículo, sin descargar elementos innecesarios como encabezados, pies de página y barras laterales.
- PromptPerfect: Prompts-as-Services resumirá cada artículo y luego combinará esos resúmenes en un solo párrafo, al estilo de un locutor de noticias de NPR.
- gTTS: La biblioteca de texto a voz de Google, para leer el informe de noticias en voz alta.
Eso es todo lo que cubriremos en esta publicación. Si deseas crear un feed de podcast para tu podcast personalizado, te sugerimos consultar otras fuentes.
tagDescargando Feeds
Como este es solo un ejemplo simple, nos quedaremos con un par de feeds de noticias de The Register y OSNews, dos sitios web de noticias tecnológicas.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]Con Feedparser podemos descargar los feeds y luego descargar los enlaces de artículos de cada feed:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagExtrayendo el Texto del Artículo con Jina Reader
Cada feed contiene enlaces a cada artículo en el sitio web correspondiente. Si solo descargamos esa página web, obtenemos una gran cantidad de HTML, incluyendo barras laterales, encabezados, pies de página y otros elementos innecesarios que no necesitamos. Si alimentas esto a un LLM sería como masticar hierba. Claro, el LLM puede hacerlo, pero no es lo que naturalmente quiere consumir.
Lo que un LLM realmente quiere es algo cercano al texto plano. Jina Reader convierte un artículo a Markdown.

Esto hace que se vea más así:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...Lo acortamos ya que incluir todo el artículo sería excesivo. Pero puedes ver que es texto claro y legible para humanos (markdown).
En lugar de esto:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...Tuvimos que cortar esto antes incluso de llegar al contenido real. Hay demasiada información ilegible para humanos.
Al alimentar al LLM con algo que puede digerir más naturalmente (como markdown en lugar de HTML), puede darnos una mejor salida. De lo contrario, es como alimentar a un león con Doritos. Claro, puede comerlos, pero no será su mejor versión leonina si mantiene esa dieta.
Para extraer solo el texto de una manera legible para humanos, usaremos la API de Jina Reader:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url>, por ejemplo https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagResumiendo los artículos con PromptPerfect
Como puede haber muchos artículos, usaremos un LLM para resumir cada uno por separado. Si simplemente los juntamos todos y alimentamos eso al LLM para resumir, podría atragantarse con demasiados tokens a la vez.
Esto variará dependiendo de cuántos artículos quieras manejar. Para unos pocos puede valer la pena concatenarlos todos en una cadena larga y hacer una sola llamada, ahorrando tiempo y dinero. Sin embargo, para este ejemplo asumiremos que estamos tratando con un número mayor de artículos.
Para resumirlos usaremos un Prompt-as-a-Service de PromptPerfect.
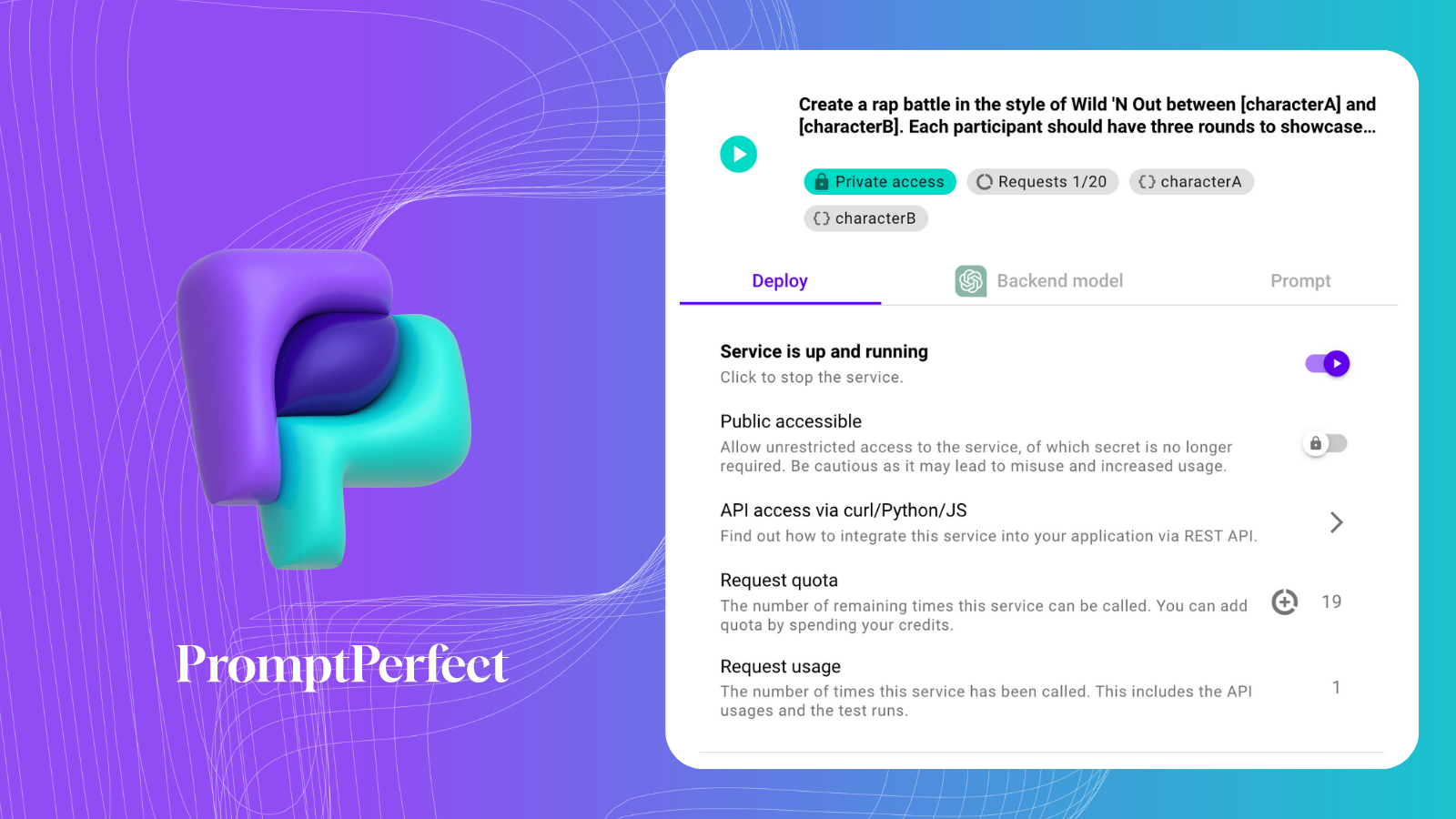
Aquí está nuestro Prompt-as-Service:

Escribiremos una función para hacer esto, ya que llamaremos a otro Prompt-as-Service más adelante en esta publicación:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.textLuego tomaremos cada resumen y los agregaremos a una lista, finalmente concatenándolos en una lista markdown con viñetas:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagGenerando un Informe de Noticias con PromptPerfect
Ahora que tenemos esa lista con viñetas, podemos enviarla a otro Prompt-as-a-Service para generar un boletín de noticias que suene como un discurso natural de locutor:

El prompt completo es:
Eres un editor de noticias de tecnología de NPR. Has recibido los siguientes resúmenes de noticias:
[summaries]
Tu trabajo es dar un resumen de un párrafo de las noticias, cubriendo cada elemento de manera orgánica, con transiciones al siguiente tema. Puedes cambiar el orden de los elementos si tiene sentido, y fusionar duplicados.
Generarás un guion de un párrafo que suene natural, para ser leído en las noticias diarias de NPR. El guion no debe tardar más de cinco minutos en leerse en voz alta.
Obtendremos el guion de noticias con este código:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)Aquí está el texto final:
En las noticias de tecnología de hoy, tenemos una serie de actualizaciones y desarrollos para discutir. En primer lugar, la herramienta Tiny11 Builder ofrece a los usuarios la capacidad de eliminar elementos innecesarios de Windows 11, creando una imagen personalizada adaptada a sus preferencias. Pasando al mundo de los videojuegos, profundizamos en los componentes ocultos dentro de los cartuchos de Super Nintendo, arrojando luz sobre la tecnología que fascinó a los jugadores en los 90. Cambiando al software, el gestor de ventanas en mosaico Niri para Wayland ha lanzado una actualización importante, ofreciendo nuevas características como el desplazamiento infinito y animaciones mejoradas. En el ámbito de la IA, la función Copilot de Microsoft ha enfrentado algunos contratiempos en su implementación para Windows Insiders, con errores y comportamiento intrusivo que provocaron una pausa en el despliegue. Mientras tanto, la Oficina del Comisionado de Información del Reino Unido plantea preocupaciones sobre el Privacy Sandbox de Google, cuestionando sus implicaciones de privacidad y el impacto en la competencia. Por último, la Administración Federal de Aviación de EE. UU. ha actualizado sus requisitos de licencia de lanzamiento, exigiendo ahora que los vehículos de reentrada obtengan una licencia antes del lanzamiento, tras un incidente con Varda Space Industries. Estas diversas historias tecnológicas destacan los avances y desafíos continuos en el mundo de la tecnología.
tagLeyendo las Noticias en Voz Alta
Para leer el texto en voz alta usaremos la biblioteca TTS de Google.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")Esto nos dará un archivo de audio final:
tagPróximos Pasos
No vamos a cubrir el resto de la experiencia de creación de podcast en esta publicación. No es nuestra especialidad, y al igual que con el consejo médico, probablemente no deberías escucharnos cuando se trata de los detalles específicos de configurar un feed de podcast, subirlo a Spotify, Apple Podcasts, etc. Para consejos médicos o sobre podcasts, consulta a tu médico o a Joe Rogan respectivamente.
En cuanto a qué más puede hacer Jina Reader, piensa en todas las aplicaciones de RAG que puedes crear descargando versiones legibles de cualquier página web. O para PromptPerfect, mira cómo puede ayudar a los YouTubers (o marketers, si eso es lo tuyo.)
