



En abril de 2024, lanzamos Jina Reader, una API que transforma cualquier página web en markdown compatible con LLM simplemente añadiendo r.jina.ai como prefijo de URL. En septiembre de 2024, lanzamos dos modelos de lenguaje pequeños, reader-lm-0.5b y reader-lm-1.5b, específicamente diseñados para convertir HTML sin procesar en markdown limpio. Hoy, nos complace presentar la segunda generación de ReaderLM, un modelo de lenguaje de 1.5B parámetros que convierte HTML sin procesar en markdown o JSON bellamente formateado con superior precisión y mejor manejo de contextos más largos. ReaderLM-v2 maneja hasta 512K tokens combinados de longitud de entrada y salida. El modelo ofrece soporte multilingüe en 29 idiomas, incluyendo inglés, chino, japonés, coreano, francés, español, portugués, alemán, italiano, ruso, vietnamita, tailandés, árabe y más.
Gracias a su nuevo paradigma de entrenamiento y datos de entrenamiento de mayor calidad, ReaderLM-v2 representa un salto significativo respecto a su predecesor, particularmente en el manejo de contenido extenso y la generación de sintaxis markdown. Mientras que la primera generación abordaba la conversión de HTML a markdown como una tarea de "copia selectiva", v2 lo trata como un verdadero proceso de traducción. Este cambio permite que el modelo aproveche magistralmente la sintaxis markdown, destacando en la generación de elementos complejos como bloques de código, listas anidadas, tablas y ecuaciones LaTex.
La comparación de resultados de conversión HTML a markdown de la página principal de HackerNews entre ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet y Gemini 2.0 Flash revela el estilo único y rendimiento de ReaderLM v2. ReaderLM v2 sobresale en preservar información completa del HTML sin procesar, incluyendo los enlaces originales de HackerNews, mientras estructura inteligentemente el contenido usando sintaxis markdown. El modelo utiliza listas anidadas para organizar elementos locales (puntos, marcas de tiempo y comentarios) mientras mantiene un formato global consistente a través de una jerarquía adecuada de encabezados (etiquetas h1 y h2).
Un desafío importante en nuestra primera versión fue la degeneración después de generar secuencias largas, particularmente en forma de repetición y bucles. El modelo comenzaba a repetir el mismo token o se quedaba atascado en un bucle, ciclando a través de una secuencia corta de tokens hasta alcanzar la longitud máxima de salida. ReaderLM-v2 alivia en gran medida este problema al añadir pérdida contrastiva durante el entrenamiento—su rendimiento se mantiene consistente independientemente de la longitud del contexto o la cantidad de tokens ya generados.

Más allá de la conversión a markdown, ReaderLM-v2 introduce la generación directa de HTML a JSON, permitiendo a los usuarios extraer información específica del HTML sin procesar siguiendo un esquema JSON dado. Este enfoque de extremo a extremo elimina la necesidad de conversión intermedia a markdown, un requisito común en muchos pipelines de limpieza y extracción de datos potenciados por LLM.

Tanto en evaluaciones cuantitativas como cualitativas, ReaderLM-v2 supera a modelos mucho más grandes como Qwen2.5-32B-Instruct, Gemini2-flash-expr, y GPT-4o-2024-08-06 en tareas de conversión de HTML a Markdown mientras muestra un rendimiento comparable en tareas de extracción de HTML a JSON, todo esto utilizando significativamente menos parámetros.

ReaderLM-v2-pro es un punto de control premium exclusivo reservado para nuestros clientes empresariales, que incluye entrenamiento y optimizaciones adicionales.


Estos resultados establecen que un modelo bien diseñado de 1.5B parámetros puede no solo igualar sino a menudo superar el rendimiento de modelos mucho más grandes en tareas de extracción de datos estructurados. Las mejoras progresivas de ReaderLM-v2 a ReaderLM-v2-pro demuestran la efectividad de nuestra nueva estrategia de entrenamiento para mejorar el rendimiento del modelo mientras se mantiene la eficiencia computacional.
tagComenzar
tagA través de Reader API

ReaderLM-v2 está ahora integrado con nuestra Reader API. Para usarlo, simplemente especifica x-engine: readerlm-v2 en los encabezados de tu solicitud y habilita el streaming de respuesta con -H 'Accept: text/event-stream':
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
Puedes probarlo sin una clave API con un límite de velocidad más bajo. Para límites de velocidad más altos, puedes comprar una clave API. Ten en cuenta que las solicitudes de ReaderLM-v2 consumen 3 veces el conteo normal de tokens de tu clave API. Esta función está actualmente en beta mientras colaboramos con el equipo de GCP para optimizar la eficiencia de la GPU y aumentar la disponibilidad del modelo.
tagEn Google Colab

Ten en cuenta que la GPU T4 gratuita tiene limitaciones: no admite bfloat16 ni flash attention 2, lo que lleva a un mayor uso de memoria y procesamiento más lento de entradas más largas. Sin embargo, ReaderLM v2 procesa exitosamente toda nuestra página legal bajo estas restricciones, logrando velocidades de procesamiento de 67 tokens/s de entrada y 36 tokens/s de salida. Para uso en producción, recomendamos una RTX 3090/4090 para un rendimiento óptimo.
La forma más sencilla de probar ReaderLM-v2 en un entorno alojado es a través de nuestro notebook de Colab, que demuestra la conversión de HTML a markdown, extracción JSON y seguimiento de instrucciones usando la página principal de HackerNews como ejemplo. El notebook está optimizado para el nivel gratuito de GPU T4 de Colab y requiere vllm y triton para aceleración y ejecución. Siéntete libre de probarlo con cualquier sitio web.
Conversión de HTML a Markdown
Puedes usar la función auxiliar create_prompt para crear fácilmente un prompt para convertir HTML a Markdown:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result será una cadena envuelta en comillas invertidas de Markdown como una valla de código. También puedes anular la configuración predeterminada para explorar diferentes salidas, por ejemplo:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()Sin embargo, dado que nuestros datos de entrenamiento pueden no cubrir todos los tipos de instrucciones, particularmente tareas que requieren razonamiento en múltiples pasos, los resultados más confiables provienen de la conversión de HTML a Markdown. Para la extracción de información más efectiva, recomendamos usar el esquema JSON como se muestra a continuación:
Extracción de HTML a JSON con esquema JSON
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result será una cadena envuelta en comillas invertidas con formato JSON, no un objeto JSON/dict real. Puedes usar Python para analizar la cadena en un diccionario o objeto JSON adecuado para su posterior procesamiento.
tagEn Producción: Disponible en CSP
ReaderLM-v2 está disponible en AWS SageMaker, Azure y GCP marketplace. Si necesitas usar estos modelos más allá de esas plataformas o en las instalaciones de tu empresa, ten en cuenta que este modelo y ReaderLM-v2-pro están licenciados bajo CC BY-NC 4.0. Para consultas sobre uso comercial o acceso a ReaderLM-v2-pro, no dudes en contactarnos.

tagEvaluación Cuantitativa
Evaluamos ReaderLM-v2 en tres tareas de extracción de datos estructurados frente a modelos de última generación: GPT-4o-2024-08-06, Gemini2-flash-expr y Qwen2.5-32B-Instruct. Nuestro marco de evaluación combina métricas que miden tanto la precisión del contenido como la fidelidad estructural. ReaderLM-v2 es la versión públicamente disponible con pesos abiertos, mientras que ReaderLM-v2-pro es un checkpoint premium exclusivo reservado para nuestros clientes empresariales, que cuenta con entrenamiento y optimizaciones adicionales. Tenga en cuenta que nuestra primera generación reader-lm-1.5b solo se evalúa en la tarea principal de extracción de contenido, ya que no admite capacidades de extracción por instrucciones o JSON.
tagMétricas de Evaluación
Para las tareas de HTML a Markdown, empleamos siete métricas complementarias. Nota: ↑ indica que mayor es mejor, ↓ indica que menor es mejor
- ROUGE-L (↑): Mide la subsecuencia común más larga entre el texto generado y de referencia, captando la preservación del contenido y la similitud estructural. Rango: 0-1, valores más altos indican mejor coincidencia de secuencias.
- WER (Tasa de Error de Palabras) (↓): Cuantifica el número mínimo de ediciones a nivel de palabra requeridas para transformar el texto generado en la referencia. Valores más bajos indican menos correcciones necesarias.
- SUB (Sustituciones) (↓): Cuenta el número de sustituciones de palabras necesarias. Valores más bajos sugieren mejor precisión a nivel de palabra.
- INS (Inserciones) (↓): Mide el número de palabras que necesitan ser insertadas para coincidir con la referencia. Valores más bajos indican mejor completitud.
- Distancia Levenshtein (↓): Calcula el número mínimo de ediciones de caracteres individuales requeridas. Valores más bajos sugieren mejor precisión a nivel de carácter.
- Distancia Damerau-Levenshtein (↓): Similar a Levenshtein pero también considera transposiciones de caracteres. Valores más bajos indican mejor coincidencia a nivel de carácter.
- Similitud Jaro-Winkler (↑): Enfatiza la coincidencia de caracteres al inicio de las cadenas, particularmente útil para evaluar la preservación de la estructura del documento. Rango: 0-1, valores más altos indican mejor similitud.
Para las tareas de HTML a JSON, lo consideramos como una tarea de recuperación y adoptamos cuatro métricas de recuperación de información:
- Puntuación F1 (↑): Media armónica de precisión y exhaustividad, proporcionando precisión general. Rango: 0-1.
- Precisión (↑): Proporción de información correctamente extraída entre todas las extracciones. Rango: 0-1.
- Exhaustividad (↑): Proporción de información correctamente extraída de toda la información disponible. Rango: 0-1.
- Tasa de Aciertos (↑): Proporción de salidas que son JSON válido y cumplen con el esquema. Rango: 0-1.
tagTarea Principal de HTML a Markdown
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tagTarea de HTML a Markdown por Instrucciones
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagTarea de HTML a JSON Basada en Esquema
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 representa un avance significativo en todas las tareas. Para la extracción de contenido principal, ReaderLM-v2-pro logra el mejor rendimiento en cinco de siete métricas, con puntuaciones superiores en ROUGE-L (0.86), WER (0.39), Levenshtein (0.20), Damerau (928.15) y Jaro-Winkler (0.83). Estos resultados demuestran mejoras integrales tanto en la preservación del contenido como en la precisión estructural en comparación con su versión base y modelos más grandes.
En la extracción por instrucciones, ReaderLM-v2 y ReaderLM-v2-pro lideran en ROUGE-L (0.72), tasa de sustitución (70.16), distancia Levenshtein (0.37) y similitud Jaro-Winkler (0.75, empatado con la versión base). Si bien GPT-4o muestra ventajas en WER y distancia Damerau, ReaderLM-v2-pro mantiene mejor estructura general del contenido y precisión. En la extracción de JSON, el modelo tiene un rendimiento competitivo, manteniéndose dentro de 0.01-0.02 puntos F1 de los modelos más grandes mientras logra altas tasas de acierto (0.99).
tagEvaluación Cualitativa
Durante nuestro análisis dereader-lm-1.5b, observamos que las métricas cuantitativas por sí solas pueden no capturar completamente el rendimiento del modelo. Las evaluaciones numéricas a veces fallaban en reflejar la calidad perceptual—casos donde puntuaciones métricas bajas producían markdown visualmente satisfactorio, o puntuaciones altas generaban resultados subóptimos. Para abordar esta discrepancia, realizamos evaluaciones cualitativas sistemáticas en 10 fuentes HTML diversas, incluyendo artículos de noticias, publicaciones de blog, páginas de productos, sitios de comercio electrónico y documentos legales en inglés, japonés y chino. El corpus de prueba enfatizó elementos de formato desafiantes como tablas de múltiples filas, diseños dinámicos, fórmulas LaTeX, tablas vinculadas y listas anidadas, proporcionando una visión más completa de las capacidades del modelo en el mundo real.
tagMétricas de Evaluación
Nuestra evaluación humana se centró en tres dimensiones clave, con resultados calificados en una escala de 1-5:
Integridad del Contenido - Evalúa la preservación de información semántica durante la conversión de HTML a markdown, incluyendo:
- Precisión y completitud del contenido de texto
- Preservación de enlaces, imágenes, bloques de código, fórmulas y citas
- Retención del formato de texto y URLs de enlaces/imágenes
Precisión Estructural - Evalúa la conversión precisa de elementos estructurales HTML a Markdown:
- Preservación de la jerarquía de encabezados
- Precisión en el anidamiento de listas
- Fidelidad en la estructura de tablas
- Formato de bloques de código y citas
Cumplimiento del Formato - Mide la adherencia a los estándares de sintaxis Markdown:
- Uso apropiado de sintaxis para encabezados (#), listas (*, +, -), tablas, bloques de código (```)
- Formato limpio sin espacios en blanco excesivos o sintaxis no estándar
- Resultado renderizado consistente y legible
Al evaluar manualmente más de 10 páginas HTML, cada criterio de evaluación tiene una puntuación máxima de 50 puntos. ReaderLM-v2 demostró un fuerte rendimiento en todas las dimensiones:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
En cuanto a la completitud del contenido, sobresalió en el reconocimiento de elementos complejos, particularmente fórmulas LaTeX, listas anidadas y bloques de código. El modelo mantuvo alta fidelidad al manejar estructuras de contenido complejas mientras que los modelos competidores a menudo omitían encabezados H1 (reader-lm-1.5b), truncaban contenido (Claude 3.5), o retenían etiquetas HTML sin procesar (Gemini-2.0-flash).
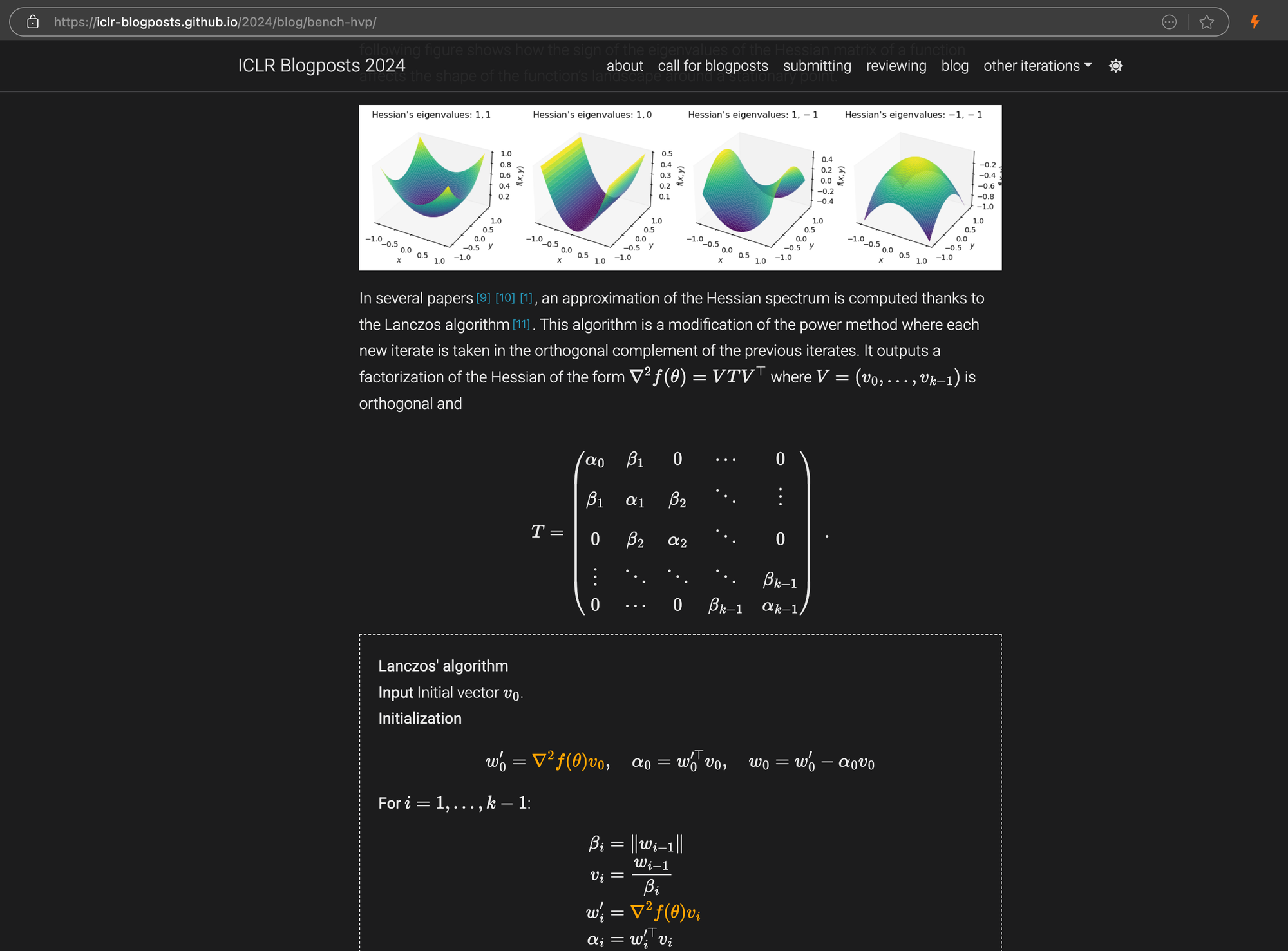
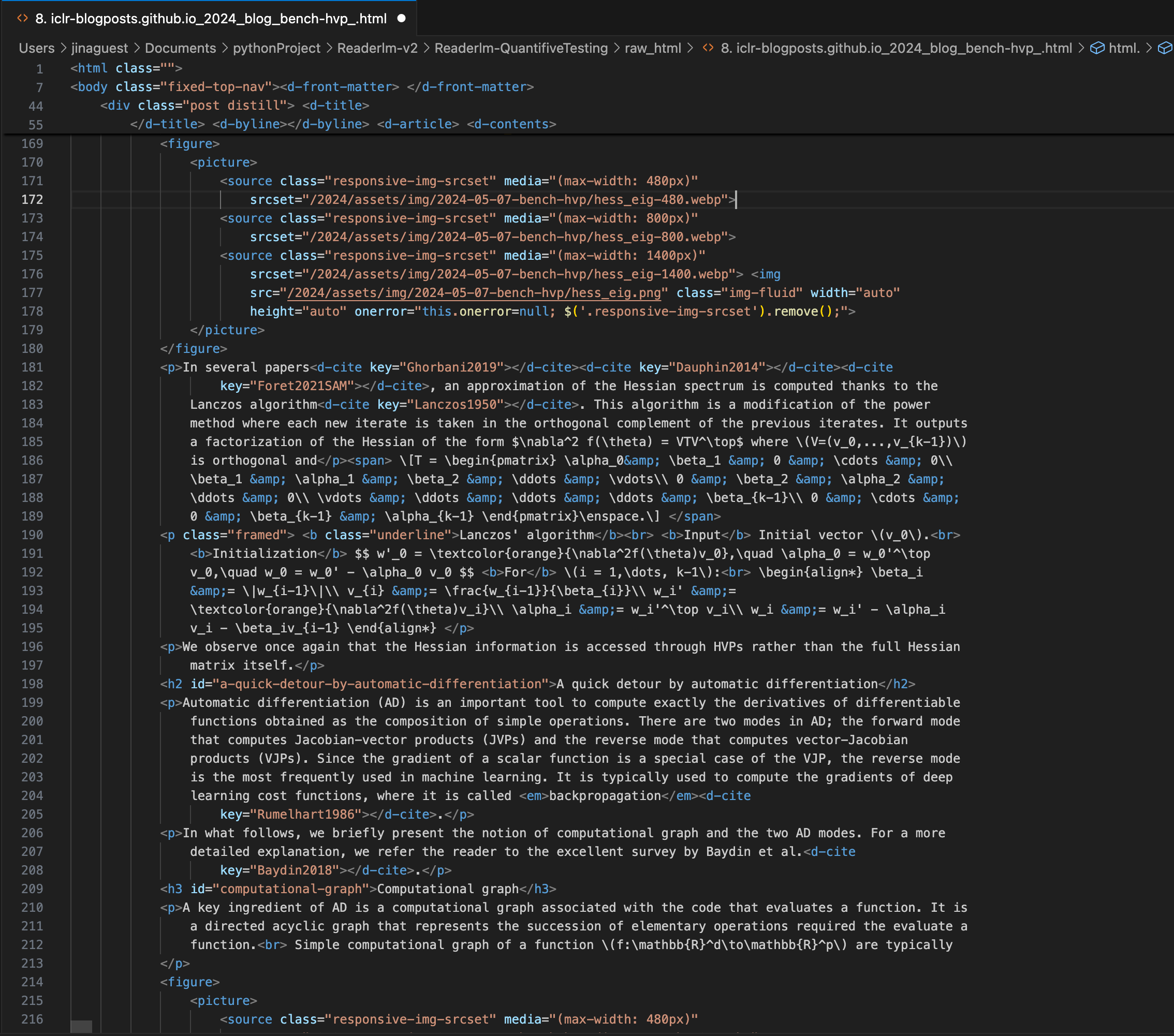
Una publicación del blog ICLR con ecuaciones LaTeX complejas incrustadas en markdown, mostrando el código fuente HTML en el panel derecho.
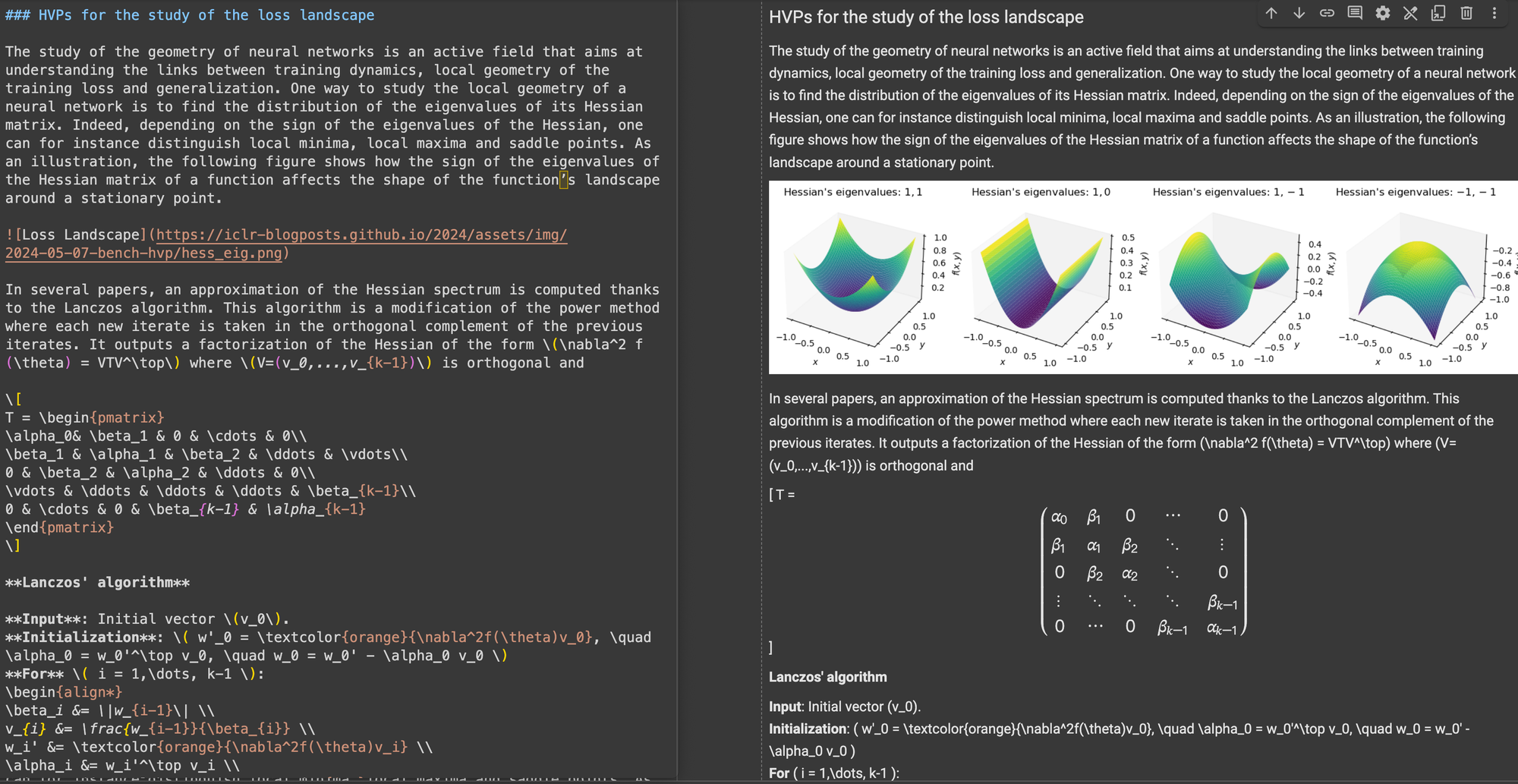
\[...\] (y sus equivalentes HTML) con delimitadores estándar de Markdown como $...$ para ecuaciones en línea y $$...$$ para ecuaciones en pantalla. Esto ayuda a prevenir conflictos de sintaxis en la interpretación de Markdown.En precisión estructural, ReaderLM-v2 mostró optimización para estructuras web comunes. Por ejemplo, en casos de Hacker News, reconstruyó exitosamente enlaces completos y optimizó la presentación de listas. El modelo manejó estructuras HTML complejas no blog que desafiaban a ReaderLM-v1.
En cumplimiento de formato, ReaderLM-v2 demostró particular fortaleza al manejar contenido como Hacker News, blogs y artículos de WeChat. Mientras que otros modelos de lenguaje grandes funcionaron bien con fuentes similares a markdown, tuvieron dificultades con sitios web tradicionales que requieren más interpretación y reformateo.
Nuestro análisis reveló que gpt-4o sobresale en el procesamiento de sitios web más cortos, demostrando una comprensión superior de la estructura y el formato del sitio en comparación con otros modelos. Sin embargo, al manejar contenido más largo, gpt-4o tiene dificultades con la completitud, a menudo omitiendo partes del principio y final del texto. Hemos incluido un análisis comparativo de las salidas de gpt-4o, ReaderLM-v2 y ReaderLM-v2-pro usando el sitio web de Zillow como ejemplo.
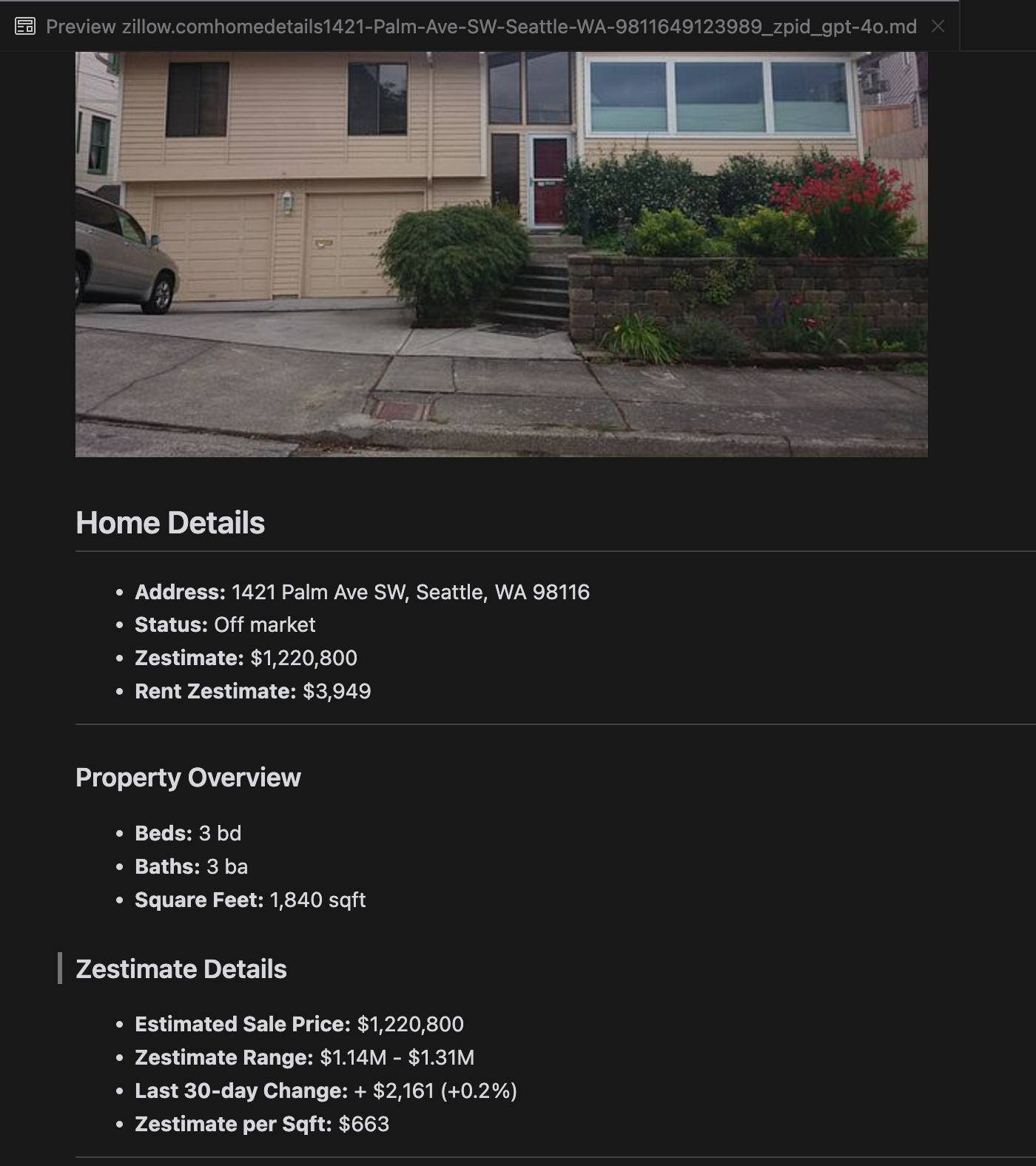
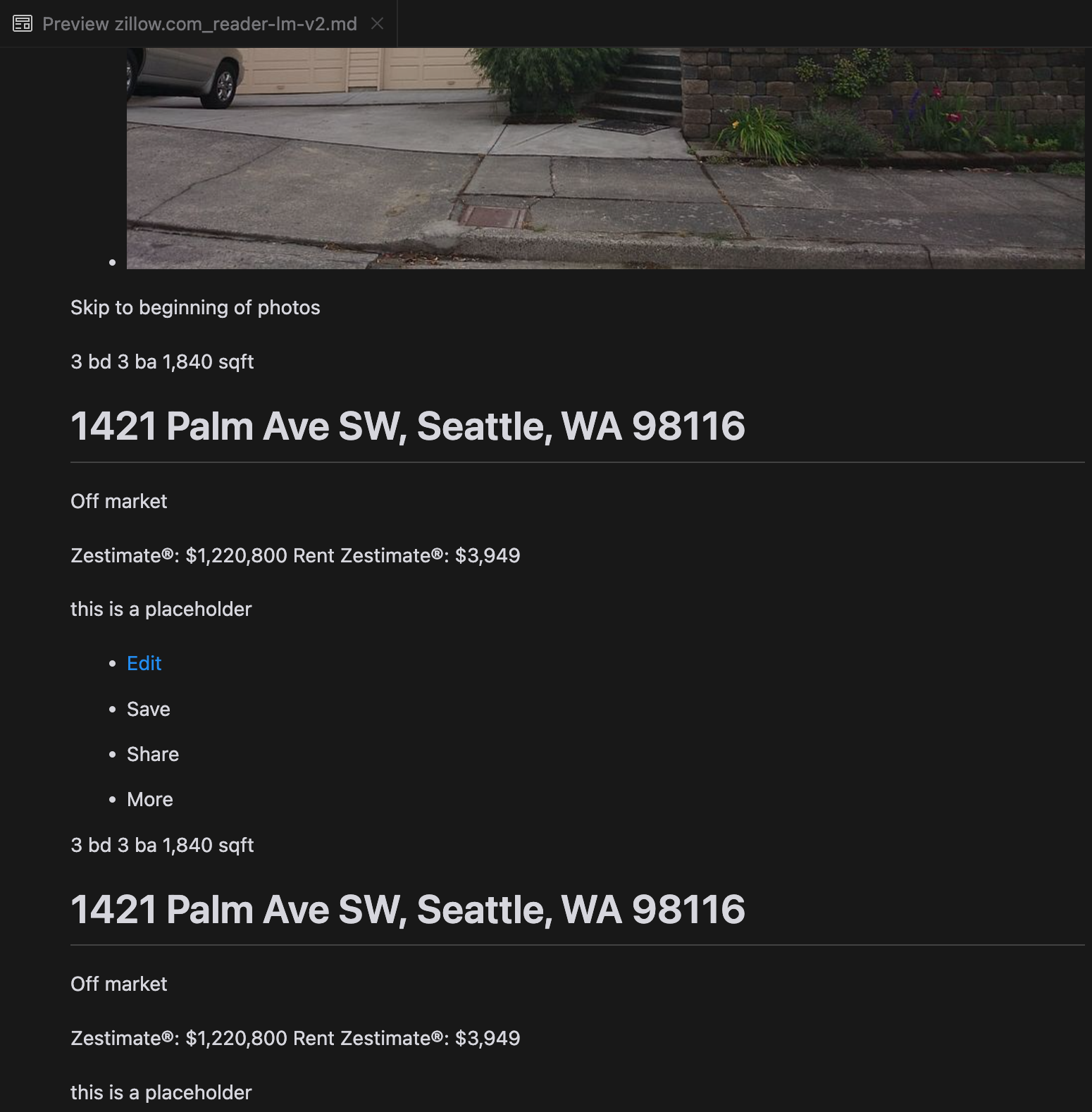
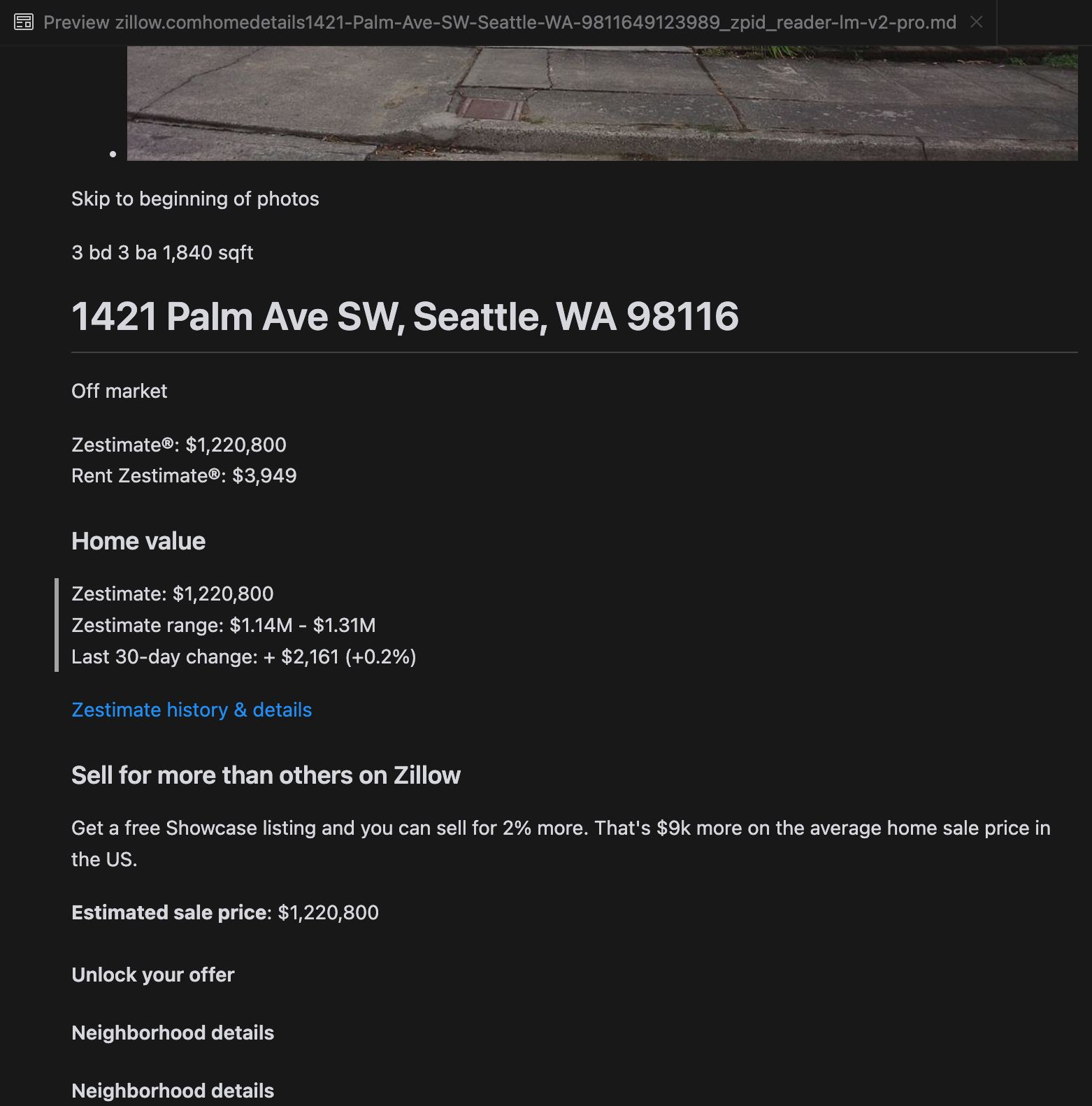
Una comparación de las salidas Markdown renderizadas de gpt-4o (izquierda), ReaderLM-v2 (centro) y ReaderLM-v2-pro (derecha).
Para ciertos casos desafiantes como páginas de aterrizaje de productos y documentos gubernamentales, el rendimiento de ReaderLM-v2 y ReaderLM-v2-pro se mantuvo robusto pero aún tiene margen de mejora. Las fórmulas matemáticas complejas y el código en las publicaciones de ICLR representaron desafíos para la mayoría de los modelos, aunque ReaderLM-v2 manejó estos casos mejor que el Reader API básico.
tagCómo Entrenamos ReaderLM v2
ReaderLM-v2 está construido sobre Qwen2.5-1.5B-Instruction, un modelo base compacto conocido por su eficiencia en tareas de seguimiento de instrucciones y contexto largo. En esta sección, describimos cómo entrenamos el ReaderLM-v2, enfocándonos en la preparación de datos, métodos de entrenamiento y los desafíos que encontramos.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagPreparación de Datos
El éxito de ReaderLM-v2 dependió en gran medida de la calidad de sus datos de entrenamiento. Creamos el conjunto de datos html-markdown-1m, que incluía un millón de documentos HTML recopilados de internet. En promedio, cada documento contenía 56,000 tokens, reflejando la longitud y complejidad de los datos web del mundo real. Para preparar este conjunto de datos, limpiamos los archivos HTML eliminando elementos innecesarios como JavaScript y CSS, mientras preservábamos elementos estructurales y semánticos clave. Después de la limpieza, usamos Jina Reader para convertir archivos HTML a Markdown usando patrones regex y heurísticas.
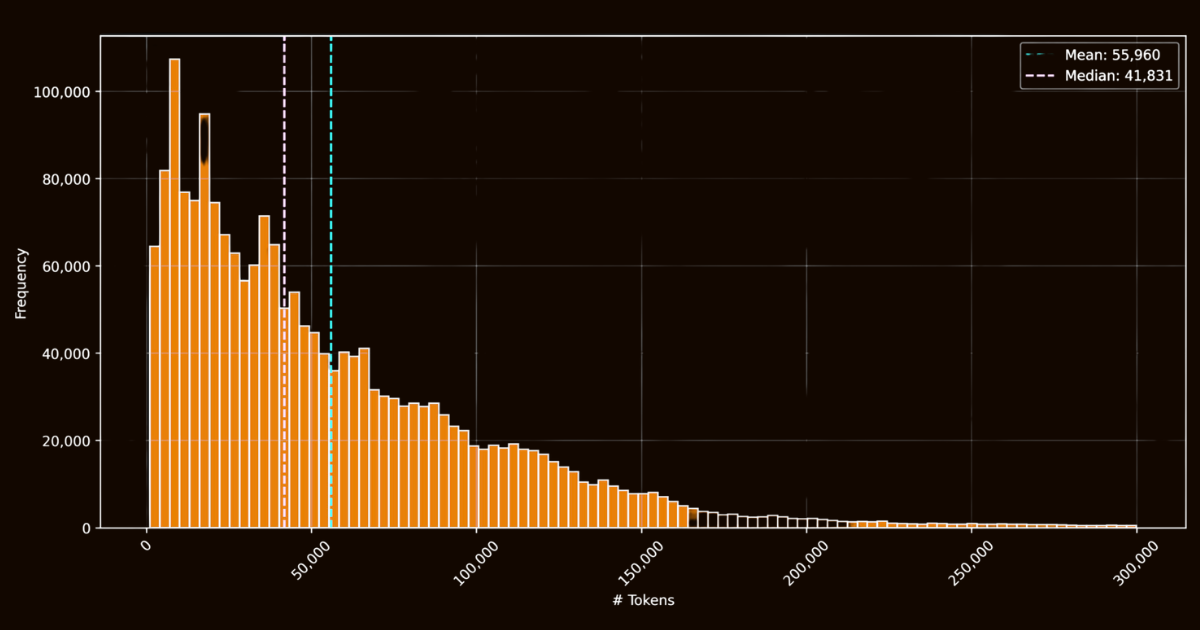
html-markdown-1mSi bien esto creó un conjunto de datos base funcional, resaltó una limitación crítica: los modelos entrenados únicamente en estas conversiones directas esencialmente solo aprenderían a imitar los patrones regex y heurísticas utilizados por Jina Reader. Esto se hizo evidente con reader-lm-0.5b/1.5b, cuyo límite de rendimiento estaba restringido por la calidad de estas conversiones basadas en reglas.
Para abordar estas limitaciones, desarrollamos un proceso de tres pasos que se basó en el modelo Qwen2.5-32B-Instruction, que es esencial para crear un conjunto de datos sintético de alta calidad.

Qwen2.5-32B-Instruction- Borrador: Generamos salidas iniciales en Markdown y JSON basadas en instrucciones proporcionadas al modelo. Estas salidas, aunque diversas, a menudo eran ruidosas o inconsistentes.
- Refinamiento: Los borradores generados fueron mejorados eliminando contenido redundante, reforzando la consistencia estructural y alineando con los formatos deseados. Este paso aseguró que los datos estuvieran limpios y alineados con los requisitos de la tarea.
- Crítica: Las salidas refinadas fueron evaluadas contra las instrucciones originales. Solo los datos que pasaron esta evaluación fueron incluidos en el conjunto de datos final. Este enfoque iterativo aseguró que los datos de entrenamiento cumplieran con los estándares de calidad necesarios para la extracción de datos estructurados.
tagProceso de Entrenamiento
Nuestro proceso de entrenamiento involucró múltiples etapas adaptadas a los desafíos de procesar documentos de contexto largo.
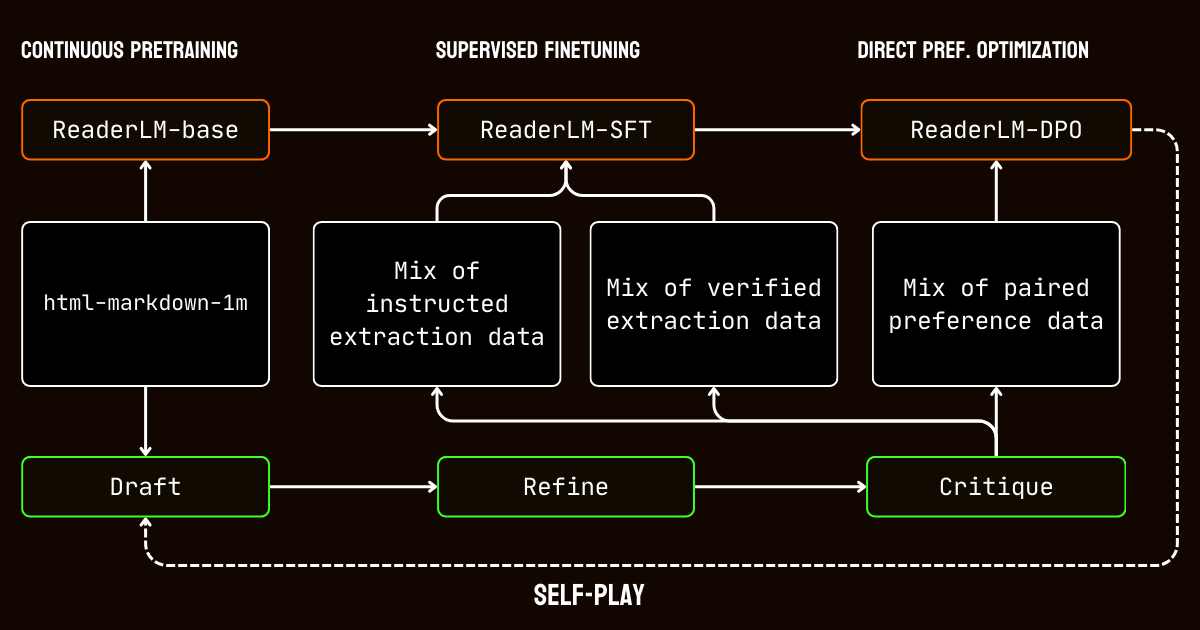
Comenzamos con el pre-entrenamiento de contexto largo, usando el conjunto de datos html-markdown-1m. Se utilizaron técnicas como la atención ring-zag y la codificación posicional rotatoria (RoPE) para expandir progresivamente la longitud de contexto del modelo de 32,768 tokens a 256,000 tokens. Para mantener la estabilidad y eficiencia, adoptamos un enfoque de entrenamiento gradual, comenzando con secuencias más cortas e incrementando gradualmente la longitud del contexto.
Después del pre-entrenamiento, pasamos al ajuste fino supervisado (SFT). Esta etapa utilizó los conjuntos de datos refinados generados en el proceso de preparación de datos. Estos conjuntos de datos incluían instrucciones detalladas para tareas de extracción de Markdown y JSON, junto con ejemplos para refinar borradores. Cada conjunto de datos fue cuidadosamente diseñado para ayudar al modelo a aprender tareas específicas, como identificar contenido principal o adherirse a estructuras JSON basadas en esquemas.
Luego aplicamos la optimización directa de preferencias (DPO) para alinear las salidas del modelo con resultados de alta calidad. En esta fase, el modelo fue entrenado en pares de respuestas borrador y refinadas. Al aprender a priorizar las salidas refinadas, el modelo internalizó las distinciones sutiles que definen resultados pulidos y específicos para cada tarea.
Finalmente, implementamos el ajuste de refuerzo por auto-juego, un proceso iterativo donde el modelo genera, refina y evalúa sus propias salidas. Este ciclo permitió que el modelo mejorara continuamente sin requerir supervisión externa adicional. Al aprovechar sus propias críticas y refinamientos, el modelo mejoró gradualmente su capacidad para producir salidas precisas y estructuradas.
tagConclusión
En abril de 2024, Jina Reader se convirtió en la primera API de markdown compatible con LLM. Estableció una nueva tendencia, ganó una amplia adopción en la comunidad y, lo más importante, nos inspiró a construir modelos de lenguaje pequeños para limpieza y extracción de datos. Hoy, estamos elevando el listón nuevamente con ReaderLM-v2, cumpliendo las promesas que hicimos el septiembre pasado: mejor manejo de contexto largo, soporte para instrucciones de entrada y la capacidad de extraer contenido específico de páginas web en formato markdown. Una vez más, hemos demostrado que con un entrenamiento y calibración cuidadosos, los modelos de lenguaje pequeños pueden lograr un rendimiento de vanguardia que supera a los modelos más grandes.
Durante el proceso de entrenamiento de ReaderLM-v2, identificamos dos ideas clave. Una estrategia efectiva fue entrenar modelos especializados en conjuntos de datos separados adaptados a tareas específicas. Estos modelos específicos para tareas fueron posteriormente fusionados usando interpolación lineal de parámetros. Si bien este enfoque requirió esfuerzo adicional, ayudó a preservar las fortalezas únicas de cada modelo especializado en el sistema unificado final.
El proceso iterativo de síntesis de datos resultó crucial para el éxito de nuestro modelo. A través del refinamiento y evaluación repetida de datos sintéticos, mejoramos significativamente el rendimiento del modelo más allá de los enfoques simples basados en reglas. Esta estrategia iterativa, aunque presentó desafíos para mantener evaluaciones consistentes de críticas y gestionar costos computacionales, fue esencial para trascender las limitaciones del uso de datos de entrenamiento basados en regex y heurísticas de Jina Reader. Esto se demuestra claramente por la brecha de rendimiento entre reader-lm-1.5b, que depende en gran medida de las conversiones basadas en reglas de Jina Reader, y ReaderLM-v2 que se beneficia de este proceso de refinamiento iterativo.
Nos entusiasma recibir sus comentarios sobre cómo ReaderLM-v2 mejora la calidad de sus datos. De cara al futuro, planeamos expandirnos hacia capacidades multimodales, particularmente para documentos escaneados, y optimizar aún más la velocidad de generación. Si está interesado en una versión personalizada de ReaderLM adaptada a su dominio específico, no dude en contactarnos.
