



En avril 2024, nous avons lancé Jina Reader, une API qui transforme n'importe quelle page web en markdown compatible avec les LLM en ajoutant simplement r.jina.ai comme préfixe d'URL. En septembre 2024, nous avons lancé deux petits modèles de langage, reader-lm-0.5b et reader-lm-1.5b, spécialement conçus pour convertir le HTML brut en markdown propre. Aujourd'hui, nous sommes ravis de présenter la deuxième génération de ReaderLM, un modèle de langage de 1,5B paramètres qui convertit le HTML brut en markdown ou JSON parfaitement formaté avec une précision supérieure et une meilleure gestion des contextes longs. ReaderLM-v2 gère jusqu'à 512K tokens combinés en entrée et en sortie. Le modèle offre un support multilingue pour 29 langues, notamment l'anglais, le chinois, le japonais, le coréen, le français, l'espagnol, le portugais, l'allemand, l'italien, le russe, le vietnamien, le thaï, l'arabe, et plus encore.
Grâce à son nouveau paradigme d'entraînement et à des données d'entraînement de meilleure qualité, ReaderLM-v2 représente un bond en avant significatif par rapport à son prédécesseur, particulièrement dans la gestion du contenu long et la génération de syntaxe markdown. Alors que la première génération abordait la conversion HTML-vers-markdown comme une tâche de « copie sélective », v2 la traite comme un véritable processus de traduction. Ce changement permet au modèle d'exploiter magistralement la syntaxe markdown, excellant dans la génération d'éléments complexes comme les blocs de code, les listes imbriquées, les tableaux et les équations LaTex.
La comparaison des résultats de conversion HTML-vers-markdown de la page d'accueil de HackerNews entre ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet et Gemini 2.0 Flash révèle l'ambiance unique et les performances de ReaderLM v2. ReaderLM v2 excelle dans la préservation des informations complètes du HTML brut, y compris les liens originaux de HackerNews, tout en structurant intelligemment le contenu avec la syntaxe markdown. Le modèle utilise des listes imbriquées pour organiser les éléments locaux (points, horodatages et commentaires) tout en maintenant un formatage global cohérent grâce à une hiérarchie appropriée des titres (balises h1 et h2).
Un défi majeur dans notre première version était la dégénérescence après la génération de longues séquences, particulièrement sous forme de répétition et de boucles. Le modèle commençait soit à répéter le même token, soit à se bloquer dans une boucle, parcourant une courte séquence de tokens jusqu'à atteindre la longueur maximale de sortie. ReaderLM-v2 atténue considérablement ce problème en ajoutant une perte contrastive pendant l'entraînement—ses performances restent cohérentes quelle que soit la longueur du contexte ou la quantité de tokens déjà générés.

Au-delà de la conversion markdown, ReaderLM-v2 introduit la génération directe HTML-vers-JSON, permettant aux utilisateurs d'extraire des informations spécifiques du HTML brut selon un schéma JSON donné. Cette approche de bout en bout élimine le besoin de conversion markdown intermédiaire, une exigence courante dans de nombreux pipelines de nettoyage et d'extraction de données basés sur les LLM.

Dans les évaluations quantitatives et qualitatives, ReaderLM-v2 surpasse des modèles beaucoup plus grands comme Qwen2.5-32B-Instruct, Gemini2-flash-expr, et GPT-4o-2024-08-06 sur les tâches de conversion HTML vers Markdown tout en montrant des performances comparables sur les tâches d'extraction HTML vers JSON, le tout en utilisant significativement moins de paramètres.

ReaderLM-v2-pro est un point de contrôle premium exclusif réservé à nos clients entreprise, comprenant des entraînements et optimisations supplémentaires.


Ces résultats établissent qu'un modèle bien conçu de 1,5B paramètres peut non seulement égaler mais souvent dépasser les performances de modèles beaucoup plus grands dans les tâches d'extraction de données structurées. Les améliorations progressives de ReaderLM-v2 à ReaderLM-v2-pro démontrent l'efficacité de notre nouvelle stratégie d'entraînement pour améliorer les performances du modèle tout en maintenant l'efficacité computationnelle.
tagCommencer
tagVia l'API Reader

ReaderLM-v2 est maintenant intégré à notre API Reader. Pour l'utiliser, spécifiez simplement x-engine: readerlm-v2 dans vos en-têtes de requête et activez le streaming de réponse avec -H 'Accept: text/event-stream' :
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
Vous pouvez l'essayer sans clé API avec une limite de taux inférieure. Pour des limites de taux plus élevées, vous pouvez acheter une clé API. Veuillez noter que les requêtes ReaderLM-v2 consomment 3 fois le nombre normal de tokens de votre clé API. Cette fonctionnalité est actuellement en version bêta pendant que nous collaborons avec l'équipe GCP pour optimiser l'efficacité GPU et augmenter la disponibilité du modèle.
tagSur Google Colab

Notez que le GPU T4 gratuit a des limitations — il ne prend pas en charge bfloat16 ou flash attention 2, ce qui entraîne une utilisation mémoire plus élevée et un traitement plus lent des entrées longues. Néanmoins, ReaderLM v2 traite avec succès notre page juridique complète dans ces conditions, atteignant des vitesses de traitement de 67 tokens/s en entrée et 36 tokens/s en sortie. Pour une utilisation en production, nous recommandons une RTX 3090/4090 pour des performances optimales.
La façon la plus simple d'essayer ReaderLM-v2 dans un environnement hébergé est via notre notebook Colab, qui démontre la conversion HTML vers Markdown, l'extraction JSON et le suivi d'instructions en utilisant la page d'accueil de HackerNews comme exemple. Le notebook est optimisé pour le niveau GPU T4 gratuit de Colab et nécessite vllm et triton pour l'accélération et l'exécution. N'hésitez pas à le tester avec n'importe quel site web.
Conversion HTML vers Markdown
Vous pouvez utiliser la fonction d'aide create_prompt pour créer facilement une invite pour convertir HTML en Markdown :
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result sera une chaîne enveloppée dans des backticks Markdown comme bloc de code. Vous pouvez également remplacer les paramètres par défaut pour explorer différentes sorties, par exemple :
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()Cependant, comme nos données d'entraînement peuvent ne pas couvrir tous les types d'instructions, en particulier les tâches nécessitant un raisonnement en plusieurs étapes, les résultats les plus fiables proviennent de la conversion HTML vers Markdown. Pour l'extraction d'informations la plus efficace, nous recommandons d'utiliser un schéma JSON comme montré ci-dessous :
Extraction HTML vers JSON avec schéma JSON
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result sera une chaîne enveloppée dans des backticks de bloc de code formaté JSON, pas un véritable objet JSON/dict. Vous pouvez utiliser Python pour analyser la chaîne en un dictionnaire ou un objet JSON approprié pour un traitement ultérieur.
tagEn Production : Disponible sur CSP
ReaderLM-v2 est disponible sur AWS SageMaker, Azure et GCP marketplace. Si vous devez utiliser ces modèles au-delà de ces plateformes ou sur site au sein de votre entreprise, notez que ce modèle et ReaderLM-v2-pro sont tous deux sous licence CC BY-NC 4.0. Pour les demandes d'utilisation commerciale ou l'accès à ReaderLM-v2-pro, n'hésitez pas à nous contacter.

tagÉvaluation Quantitative
Nous évaluons ReaderLM-v2 sur trois tâches d'extraction de données structurées en le comparant aux modèles de pointe : GPT-4o-2024-08-06, Gemini2-flash-expr, et Qwen2.5-32B-Instruct. Notre cadre d'évaluation combine des métriques qui mesurent à la fois la précision du contenu et la fidélité structurelle. ReaderLM-v2 est la version publiquement disponible avec des poids ouverts, tandis que ReaderLM-v2-pro est un point de contrôle premium exclusif réservé à nos clients entreprise, comprenant des entraînements et des optimisations supplémentaires. Notez que notre première génération reader-lm-1.5b n'est évaluée que sur la tâche d'extraction de contenu principal, car elle ne prend pas en charge les capacités d'extraction par instruction ou JSON.
tagMétriques d'Évaluation
Pour les tâches HTML-vers-Markdown, nous utilisons sept métriques complémentaires. Note : ↑ indique que plus c'est élevé, mieux c'est, ↓ indique que plus c'est bas, mieux c'est
- ROUGE-L (↑) : Mesure la plus longue sous-séquence commune entre le texte généré et le texte de référence, capturant la préservation du contenu et la similarité structurelle. Plage : 0-1, les valeurs plus élevées indiquent une meilleure correspondance des séquences.
- WER (Taux d'Erreur de Mots) (↓) : Quantifie le nombre minimum d'éditions au niveau des mots nécessaires pour transformer le texte généré en référence. Les valeurs plus basses indiquent moins de corrections nécessaires.
- SUB (Substitutions) (↓) : Compte le nombre de substitutions de mots nécessaires. Les valeurs plus basses suggèrent une meilleure précision au niveau des mots.
- INS (Insertions) (↓) : Mesure le nombre de mots qui doivent être insérés pour correspondre à la référence. Les valeurs plus basses indiquent une meilleure complétude.
- Distance de Levenshtein (↓) : Calcule le nombre minimum d'éditions de caractères individuels nécessaires. Les valeurs plus basses suggèrent une meilleure précision au niveau des caractères.
- Distance de Damerau-Levenshtein (↓) : Similaire à Levenshtein mais prend aussi en compte les transpositions de caractères. Les valeurs plus basses indiquent une meilleure correspondance au niveau des caractères.
- Similarité Jaro-Winkler (↑) : Met l'accent sur la correspondance des caractères au début des chaînes, particulièrement utile pour évaluer la préservation de la structure du document. Plage : 0-1, les valeurs plus élevées indiquent une meilleure similarité.
Pour les tâches HTML-vers-JSON, nous la considérons comme une tâche de recherche d'information et adoptons quatre métriques :
- Score F1 (↑) : Moyenne harmonique de la précision et du rappel, fournissant une précision globale. Plage : 0-1.
- Précision (↑) : Proportion d'informations correctement extraites parmi toutes les extractions. Plage : 0-1.
- Rappel (↑) : Proportion d'informations correctement extraites parmi toutes les informations disponibles. Plage : 0-1.
- Taux de Réussite (↑) : Proportion de sorties qui sont des JSON valides et conformes au schéma. Plage : 0-1.
tagTâche de Conversion HTML-vers-Markdown du Contenu Principal
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tagTâche de Conversion HTML-vers-Markdown par Instructions
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagTâche de Conversion HTML-vers-JSON basée sur un Schéma
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 représente une avancée significative dans toutes les tâches. Pour l'extraction du contenu principal, ReaderLM-v2-pro obtient les meilleures performances dans cinq métriques sur sept, avec des scores supérieurs en ROUGE-L (0,86), WER (0,39), Levenshtein (0,20), Damerau (928,15), et Jaro-Winkler (0,83). Ces résultats démontrent des améliorations globales dans la préservation du contenu et la précision structurelle par rapport à sa version de base et aux modèles plus grands.
Dans l'extraction par instructions, ReaderLM-v2 et ReaderLM-v2-pro sont en tête pour le ROUGE-L (0,72), le taux de substitution (70,16), la distance de Levenshtein (0,37), et la similarité Jaro-Winkler (0,75, à égalité avec la version de base). Bien que GPT-4o montre des avantages en WER et distance Damerau, ReaderLM-v2-pro maintient une meilleure structure globale et précision du contenu. Dans l'extraction JSON, le modèle est compétitif, restant à 0,01-0,02 points F1 des modèles plus grands tout en atteignant des taux de réussite élevés (0,99).
tagÉvaluation Qualitative
Durant notre analyse dePour reader-lm-1.5b, nous avons observé que les métriques quantitatives seules ne capturent pas pleinement les performances du modèle. Les évaluations numériques ne reflétaient parfois pas la qualité perceptuelle — des cas où de faibles scores métriques produisaient un markdown visuellement satisfaisant, ou des scores élevés donnaient des résultats sous-optimaux. Pour remédier à cette disparité, nous avons mené des évaluations qualitatives systématiques sur 10 sources HTML diverses, incluant des articles d'actualité, des billets de blog, des pages de produits, des sites e-commerce et des documents juridiques en anglais, japonais et chinois. Le corpus de test mettait l'accent sur des éléments de formatage complexes tels que des tableaux multi-lignes, des mises en page dynamiques, des formules LaTeX, des tableaux liés et des listes imbriquées, offrant une vision plus complète des capacités réelles du modèle.
tagMétriques d'évaluation
Notre évaluation humaine s'est concentrée sur trois dimensions clés, avec des notes sur une échelle de 1 à 5 :
Intégrité du contenu - Évalue la préservation des informations sémantiques lors de la conversion HTML vers markdown, incluant :
- Précision et exhaustivité du contenu textuel
- Préservation des liens, images, blocs de code, formules et citations
- Conservation du formatage du texte et des URLs des liens/images
Précision structurelle - Évalue la conversion précise des éléments structurels HTML vers Markdown :
- Préservation de la hiérarchie des en-têtes
- Précision de l'imbrication des listes
- Fidélité de la structure des tableaux
- Formatage des blocs de code et des citations
Conformité du format - Mesure le respect des standards de syntaxe Markdown :
- Utilisation correcte de la syntaxe pour les en-têtes (#), listes (*, +, -), tableaux, blocs de code (```)
- Formatage propre sans espaces superflus ou syntaxe non standard
- Rendu cohérent et lisible
Lors de notre évaluation manuelle de plus de 10 pages HTML, chaque critère d'évaluation a un score maximum de 50 points. ReaderLM-v2 a démontré de solides performances dans toutes les dimensions :
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
Pour l'exhaustivité du contenu, il a excellé dans la reconnaissance d'éléments complexes, particulièrement les formules LaTeX, les listes imbriquées et les blocs de code. Le modèle a maintenu une haute fidélité dans le traitement des structures de contenu complexes alors que les modèles concurrents omettaient souvent les en-têtes H1 (reader-lm-1.5b), tronquaient le contenu (Claude 3.5), ou conservaient les balises HTML brutes (Gemini-2.0-flash).
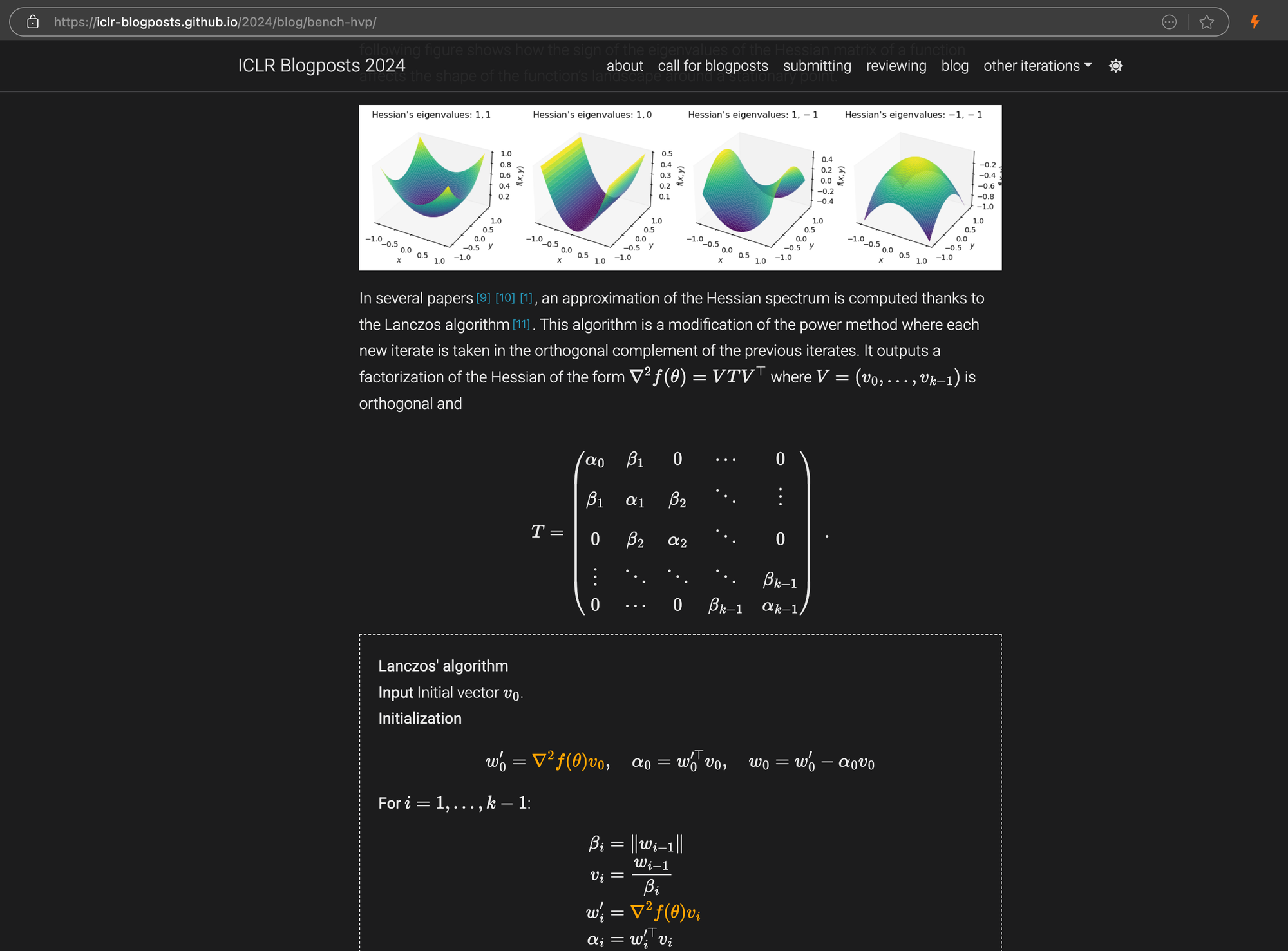
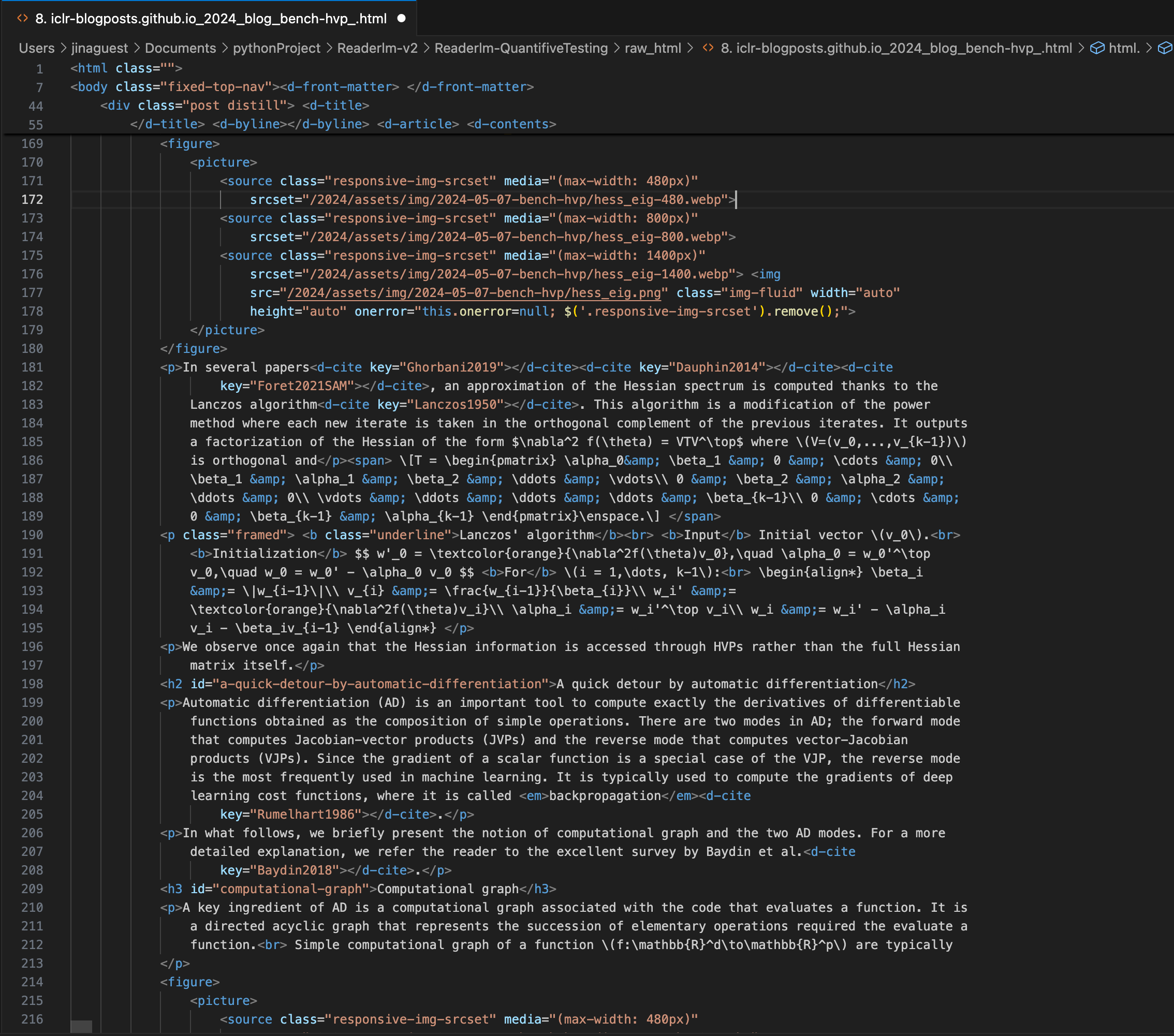
Un article de blog ICLR avec des équations LaTeX complexes intégrées en markdown, montrant le code source HTML dans le panneau de droite.
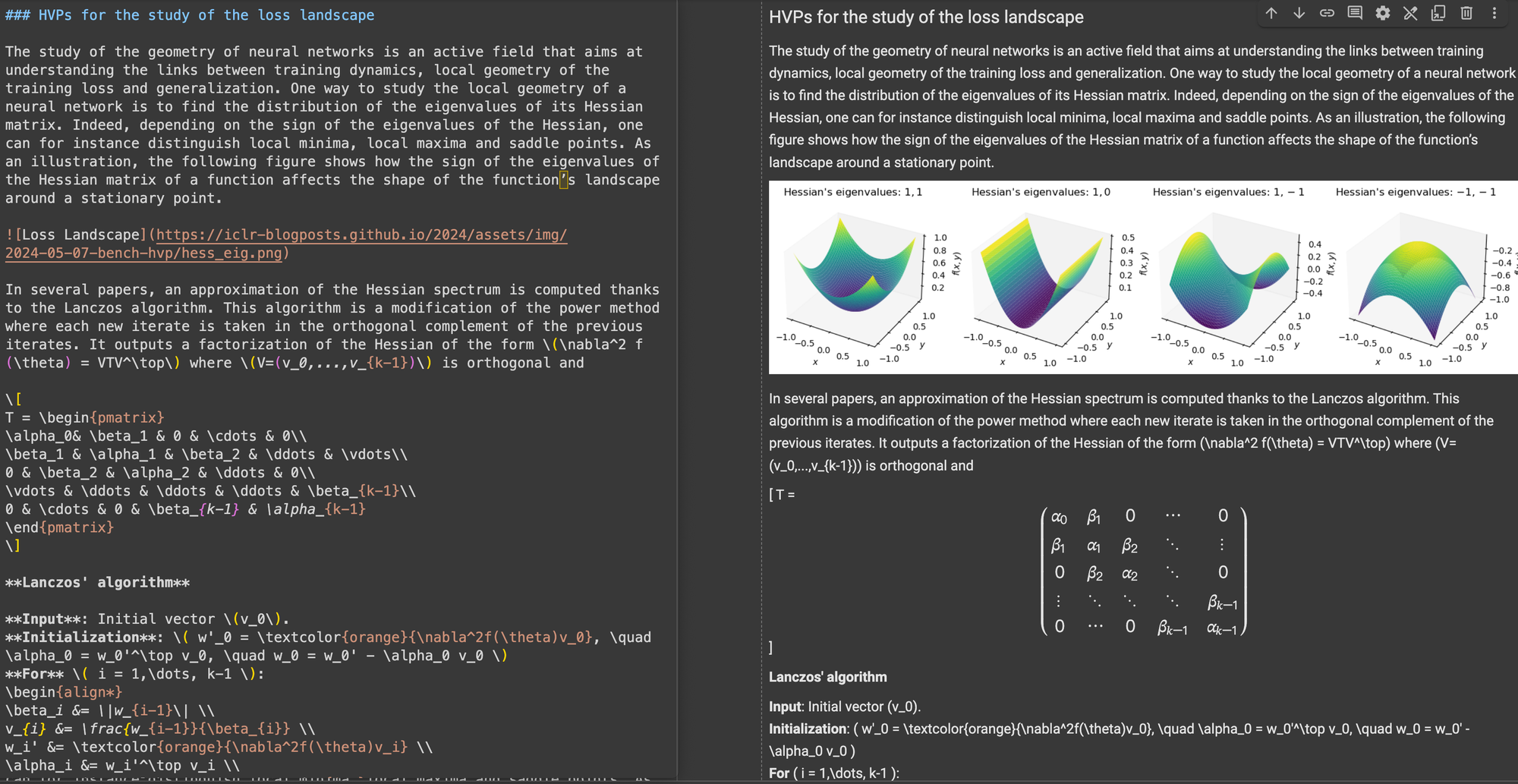
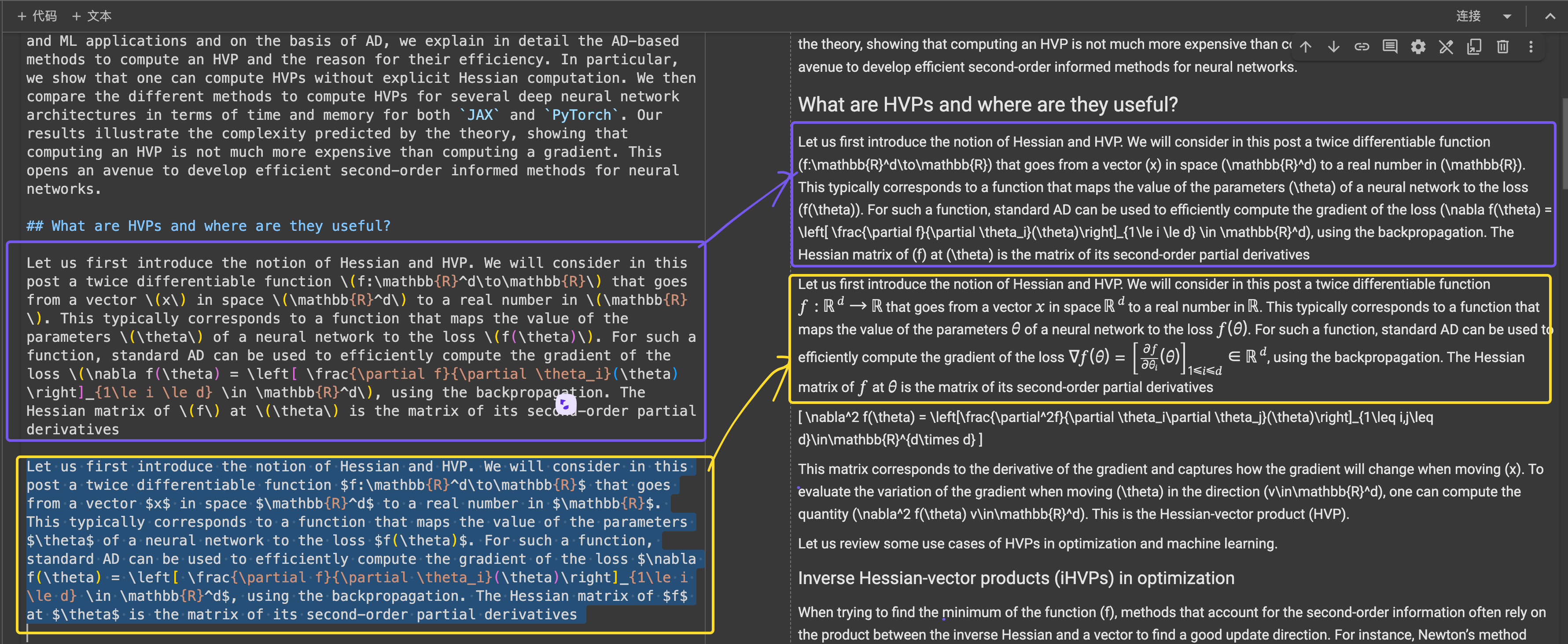
\[...\] (et ses équivalents HTML) par des délimiteurs standard Markdown comme $...$ pour les équations en ligne et $$...$$ pour les équations en affichage. Cela aide à prévenir les conflits de syntaxe dans l'interprétation Markdown.En termes de précision structurelle, ReaderLM-v2 a montré une optimisation pour les structures web courantes. Par exemple, dans les cas Hacker News, il a réussi à reconstruire les liens complets et optimisé la présentation des listes. Le modèle a géré des structures HTML complexes non-blog qui mettaient au défi ReaderLM-v1.
Pour la conformité du format, ReaderLM-v2 a démontré une force particulière dans le traitement de contenus comme Hacker News, les blogs et les articles WeChat. Alors que d'autres grands modèles de langage performaient bien sur les sources de type markdown, ils peinaient avec les sites web traditionnels nécessitant plus d'interprétation et de reformatage.
Notre analyse a révélé que gpt-4o excelle dans le traitement des sites web plus courts, démontrant une compréhension supérieure de la structure et du formatage du site par rapport aux autres modèles. Cependant, lors du traitement de contenus plus longs, gpt-4o a des difficultés avec l'exhaustivité, omettant souvent des portions au début et à la fin du texte. Nous avons inclus une analyse comparative des sorties de gpt-4o, ReaderLM-v2 et ReaderLM-v2-pro en utilisant le site web de Zillow comme exemple.
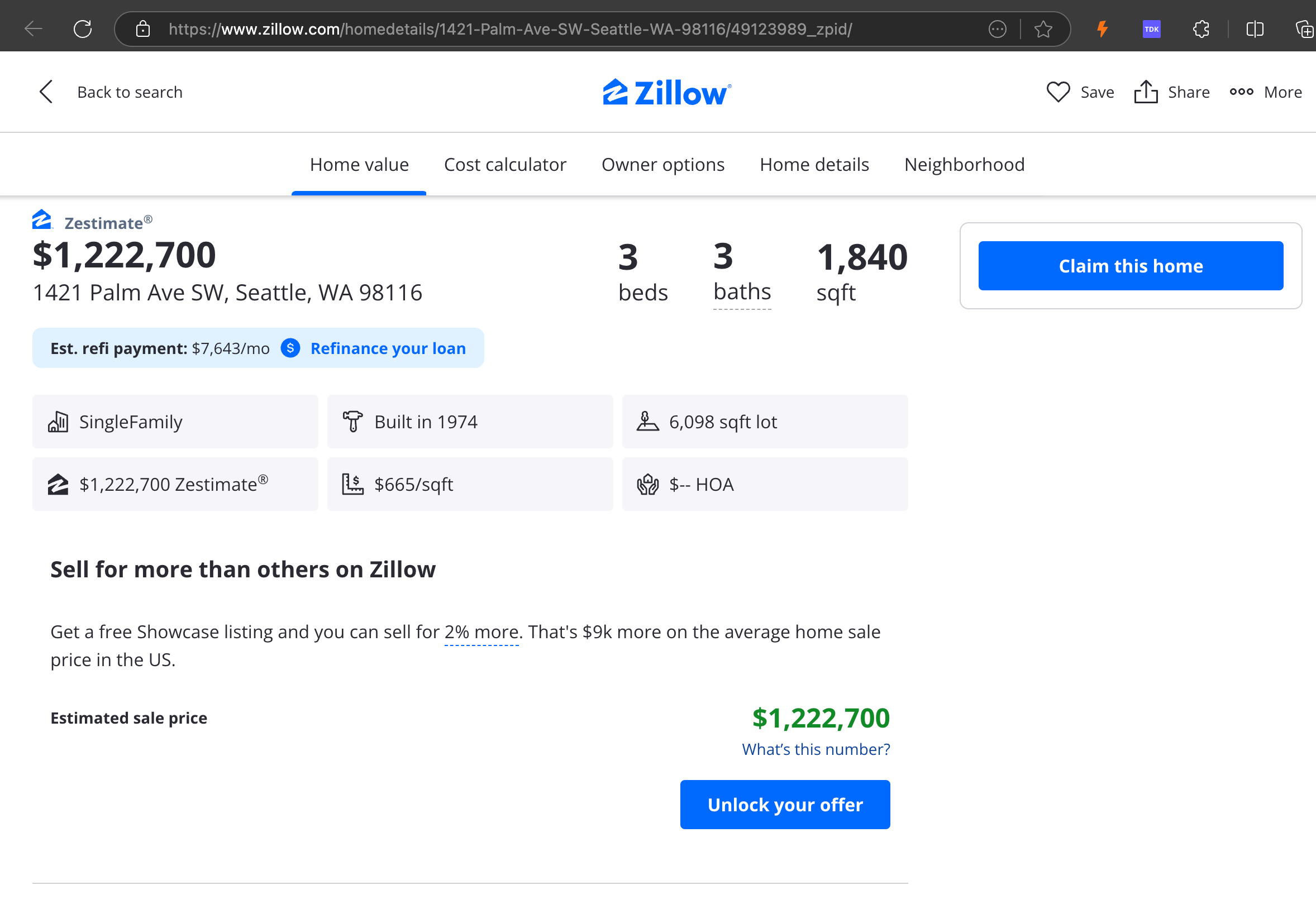
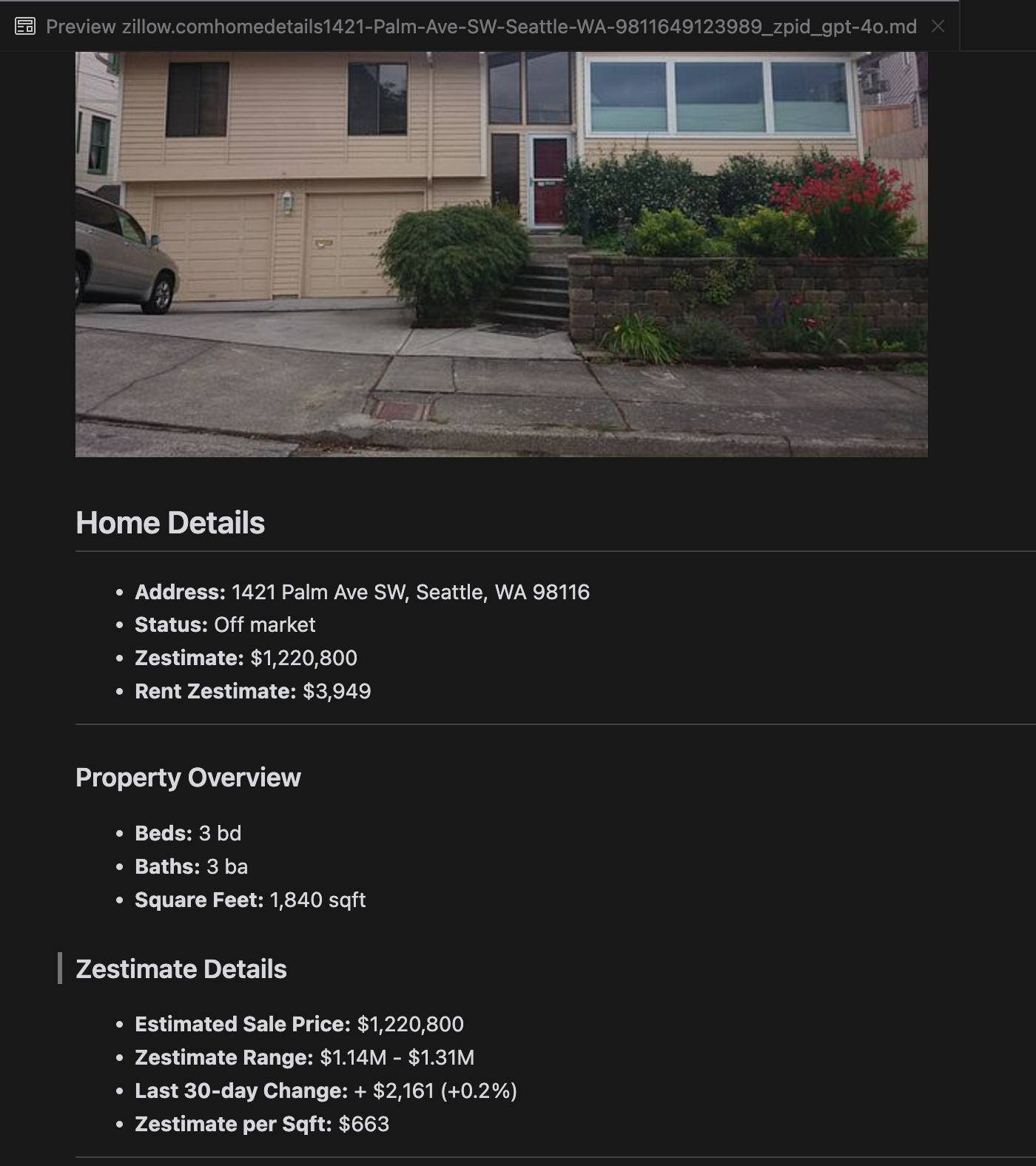
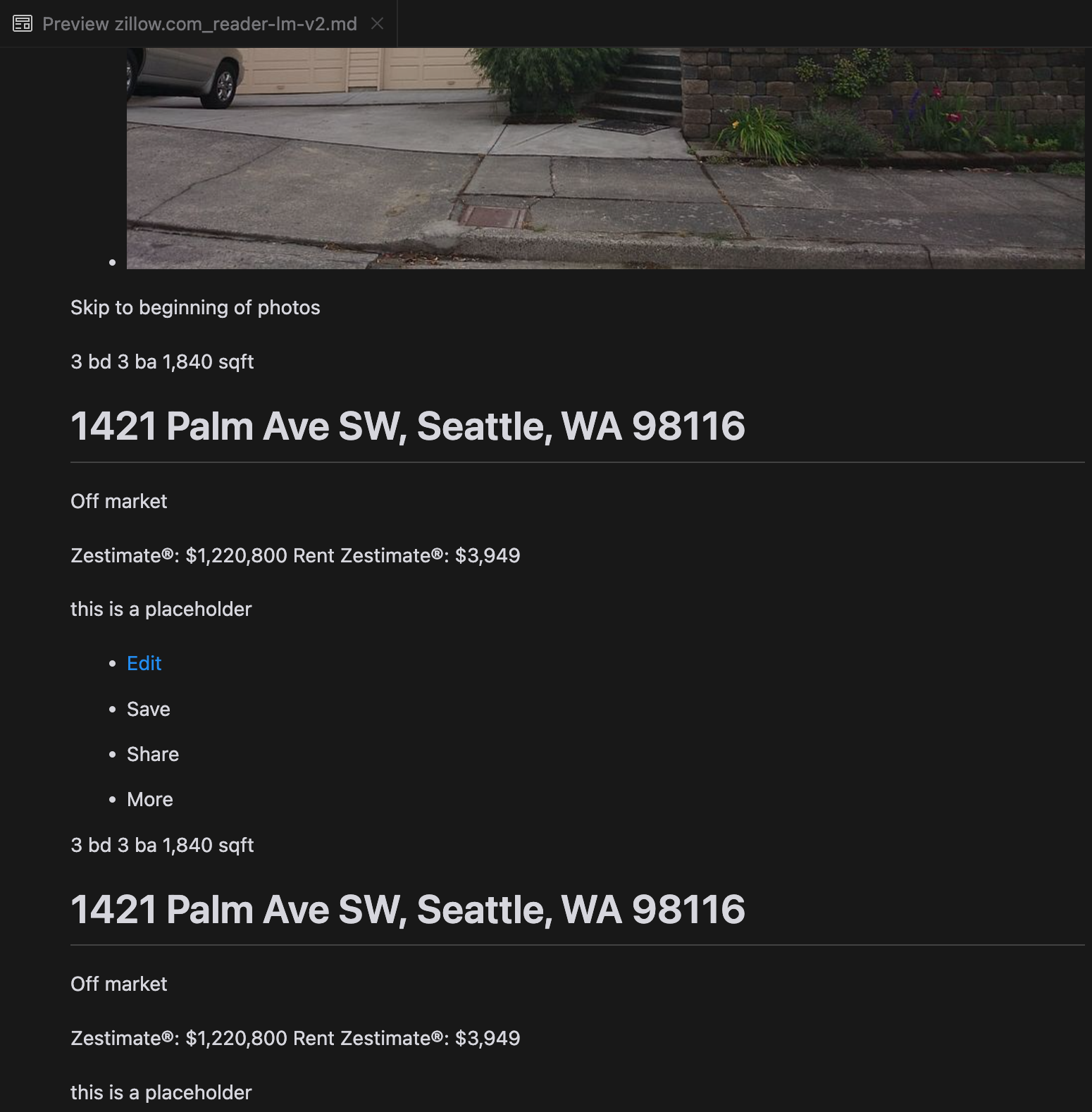
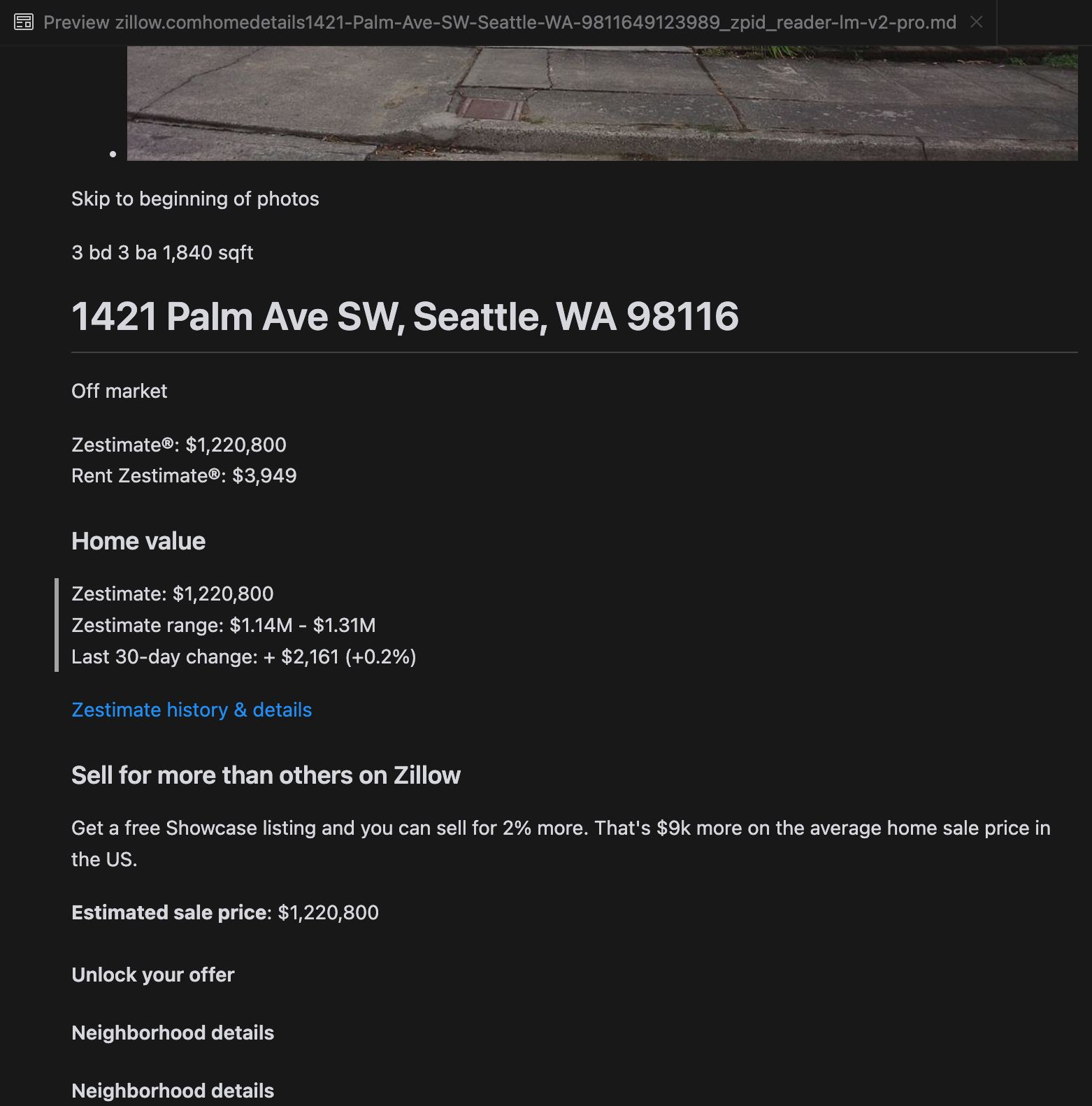
Une comparaison des sorties Markdown rendues par gpt-4o (gauche), ReaderLM-v2 (milieu) et ReaderLM-v2-pro (droite).
Pour certains cas complexes comme les pages de présentation de produits et les documents gouvernementaux, les performances de ReaderLM-v2 et ReaderLM-v2-pro sont restées robustes mais peuvent encore être améliorées. Les formules mathématiques complexes et le code dans les articles de blog ICLR ont posé des défis pour la plupart des modèles, bien que ReaderLM-v2 ait mieux géré ces cas que l'API Reader de référence.
tagComment nous avons entraîné ReaderLM v2
ReaderLM-v2 est construit sur Qwen2.5-1.5B-Instruction, un modèle de base compact connu pour son efficacité dans le suivi des instructions et les tâches à contexte long. Dans cette section, nous décrivons comment nous avons entraîné le ReaderLM-v2, en mettant l'accent sur la préparation des données, les méthodes d'entraînement et les défis rencontrés.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagPréparation des données
Le succès de ReaderLM-v2 dépendait largement de la qualité de ses données d'entraînement. Nous avons créé le jeu de données html-markdown-1m, qui comprenait un million de documents HTML collectés sur Internet. En moyenne, chaque document contenait 56 000 tokens, reflétant la longueur et la complexité des données web réelles. Pour préparer ce jeu de données, nous avons nettoyé les fichiers HTML en supprimant les éléments inutiles comme JavaScript et CSS, tout en préservant les éléments structurels et sémantiques clés. Après le nettoyage, nous avons utilisé Jina Reader pour convertir les fichiers HTML en Markdown en utilisant des motifs regex et des heuristiques.
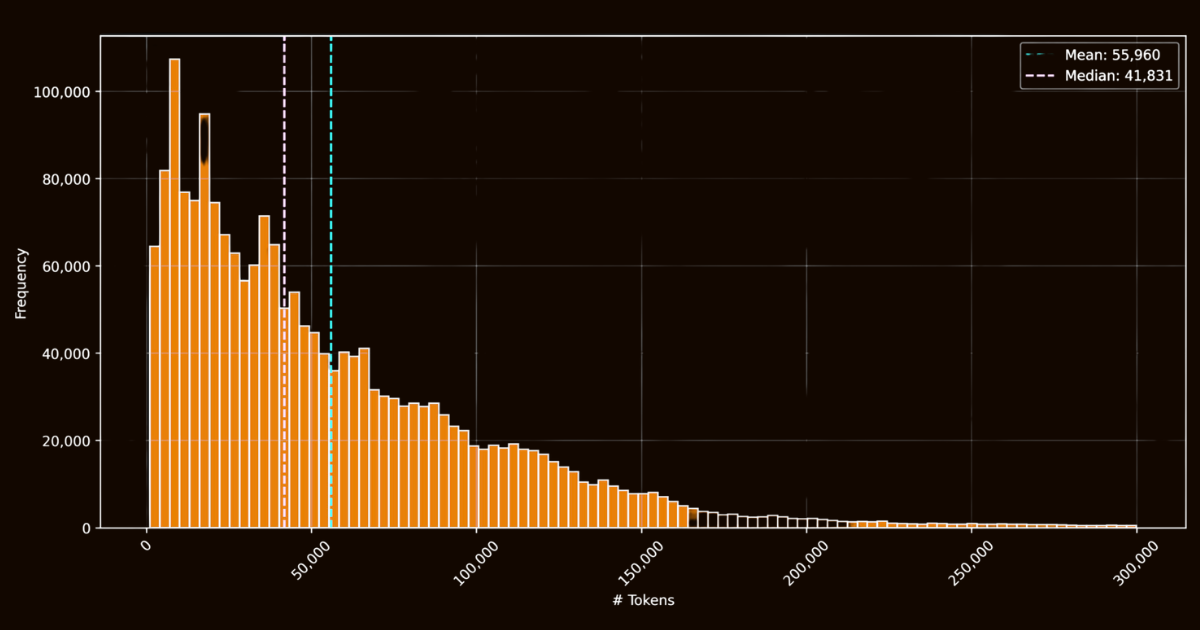
html-markdown-1mBien que cela ait créé un jeu de données de base fonctionnel, cela a mis en évidence une limitation critique : les modèles entraînés uniquement sur ces conversions directes apprendraient essentiellement à imiter les motifs regex et les heuristiques utilisés par Jina Reader. Cela est devenu évident avec reader-lm-0.5b/1.5b, dont le plafond de performance était limité par la qualité de ces conversions basées sur des règles.
Pour résoudre ces limitations, nous avons développé un pipeline en trois étapes s'appuyant sur le modèle Qwen2.5-32B-Instruction, qui est essentiel pour créer un jeu de données synthétiques de haute qualité.

Qwen2.5-32B-Instruction- Ébauche : Nous avons généré des sorties Markdown et JSON initiales basées sur les instructions fournies au modèle. Ces sorties, bien que diverses, étaient souvent bruitées ou incohérentes.
- Raffinement : Les ébauches générées ont été améliorées en supprimant le contenu redondant, en imposant une cohérence structurelle et en alignant les formats souhaités. Cette étape a assuré que les données étaient propres et alignées avec les exigences des tâches.
- Critique : Les sorties raffinées ont été évaluées par rapport aux instructions originales. Seules les données ayant passé cette évaluation ont été incluses dans le jeu de données final. Cette approche itérative a assuré que les données d'entraînement répondaient aux normes de qualité nécessaires pour l'extraction de données structurées.
tagProcessus d'entraînement
Notre processus d'entraînement comprenait plusieurs étapes adaptées aux défis du traitement des documents à contexte long.
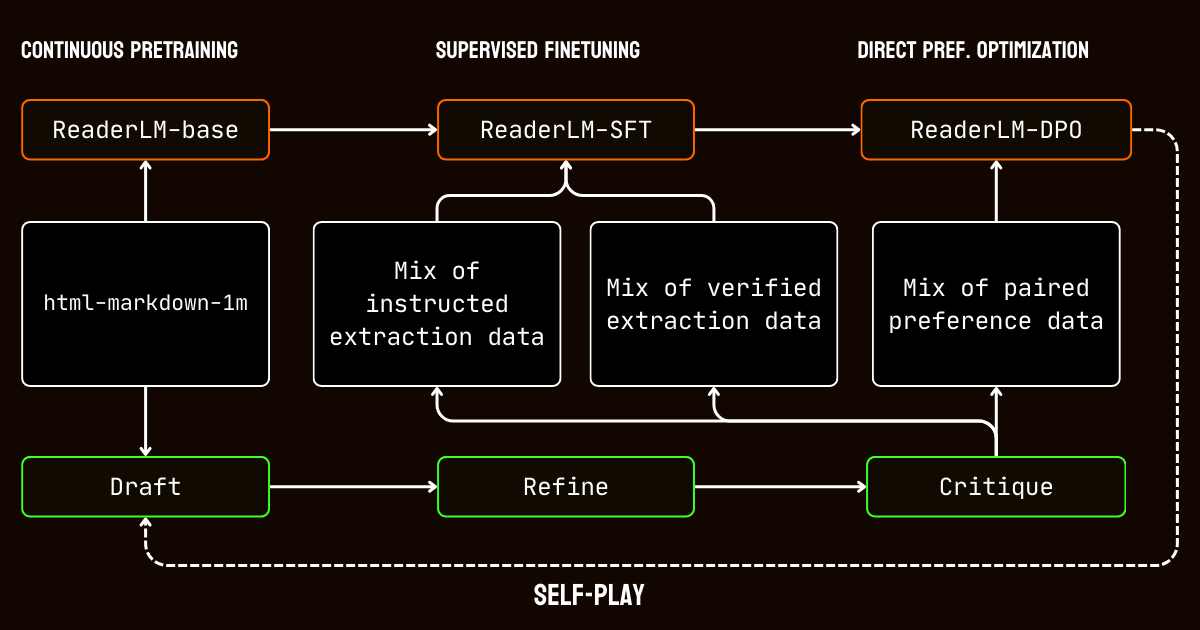
Nous avons commencé par le pré-entraînement à contexte long, en utilisant le jeu de données html-markdown-1m. Des techniques comme l'attention ring-zag et l'encodage positionnel rotatif (RoPE) ont été utilisées pour étendre progressivement la longueur de contexte du modèle de 32 768 tokens à 256 000 tokens. Pour maintenir la stabilité et l'efficacité, nous avons adopté une approche d'entraînement graduelle, commençant par des séquences plus courtes et augmentant progressivement la longueur du contexte.
Après le pré-entraînement, nous sommes passés au fine-tuning supervisé (SFT). Cette étape a utilisé les jeux de données raffinés générés dans le processus de préparation des données. Ces jeux de données incluaient des instructions détaillées pour les tâches d'extraction Markdown et JSON, ainsi que des exemples pour raffiner les ébauches. Chaque jeu de données a été soigneusement conçu pour aider le modèle à apprendre des tâches spécifiques, comme l'identification du contenu principal ou l'adhésion aux structures JSON basées sur des schémas.
Nous avons ensuite appliqué l'optimisation directe des préférences (DPO) pour aligner les sorties du modèle avec des résultats de haute qualité. Dans cette phase, le modèle a été entraîné sur des paires d'ébauches et de réponses raffinées. En apprenant à privilégier les sorties raffinées, le modèle a intériorisé les subtiles distinctions qui définissent des résultats polis et adaptés aux tâches.
Enfin, nous avons mis en œuvre un fine-tuning par renforcement en auto-apprentissage, un processus itératif où le modèle générait, raffinait et évaluait ses propres sorties. Ce cycle a permis au modèle de s'améliorer continuellement sans nécessiter de supervision externe supplémentaire. En s'appuyant sur ses propres critiques et raffinements, le modèle a progressivement amélioré sa capacité à produire des sorties précises et structurées.
tagConclusion
En avril 2024, Jina Reader est devenu la première API markdown compatible avec les LLM. Elle a établi une nouvelle tendance, a gagné une large adoption communautaire et, plus important encore, nous a inspiré à construire de petits modèles de langage pour le nettoyage et l'extraction de données. Aujourd'hui, nous repoussons à nouveau les limites avec ReaderLM-v2, tenant les promesses que nous avons faites en septembre dernier : une meilleure gestion des contextes longs, la prise en charge des instructions d'entrée et la capacité d'extraire du contenu spécifique des pages web au format markdown. Une fois de plus, nous avons démontré qu'avec un entraînement et un calibrage soigneux, les petits modèles de langage peuvent atteindre des performances état de l'art qui dépassent celles des modèles plus grands.
Tout au long du processus d'entraînement de ReaderLM-v2, nous avons identifié deux insights. Une stratégie efficace consistait à entraîner des modèles spécialisés sur des jeux de données séparés adaptés à des tâches spécifiques. Ces modèles spécialisés ont ensuite été fusionnés en utilisant une interpolation linéaire des paramètres. Bien que cette approche ait nécessité des efforts supplémentaires, elle a aidé à préserver les forces uniques de chaque modèle spécialisé dans le système unifié final.
Le processus itératif de synthèse des données s'est avéré crucial pour le succès de notre modèle. Grâce à l'affinage et à l'évaluation répétés des données synthétiques, nous avons considérablement amélioré les performances du modèle au-delà des simples approches basées sur des règles. Cette stratégie itérative, bien que présentant des défis dans le maintien d'évaluations critiques cohérentes et la gestion des coûts de calcul, était essentielle pour transcender les limitations de l'utilisation des données d'entraînement basées sur regex et heuristiques de Jina Reader. Cela est clairement démontré par l'écart de performance entre reader-lm-1.5b, qui s'appuie fortement sur les conversions basées sur des règles de Jina Reader, et ReaderLM-v2 qui bénéficie de ce processus d'affinage itératif.
Nous sommes impatients de recevoir vos retours sur la façon dont ReaderLM-v2 améliore la qualité de vos données. Pour l'avenir, nous prévoyons d'étendre les capacités multimodales, particulièrement pour les documents numérisés, et d'optimiser davantage la vitesse de génération. Si vous êtes intéressé par une version personnalisée de ReaderLM adaptée à votre domaine spécifique, n'hésitez pas à nous contacter.
