


Come molte persone, ascolto un sacco di podcast. Alcuni sono sulla fantascienza. Altri sulla paleontologia. E altri ancora sui strani personaggi medievali. Nessun true crime purtroppo, a parte il mio occasionale cattivo gusto.
Ma... è faticoso ascoltare tutti questi podcast. E non sono nemmeno il peggio. Mi sono anche iscritto a molti feed di notizie. E questo può richiedere molta lettura. Sarebbe fantastico se potessi semplicemente prendere tutto il contenuto di quei feed di notizie, metterlo in un riassunto di cinque minuti e far sì che il mio telefono lo legga mentre mi lavo i denti la mattina.
Immagino che tu possa capire dove voglio arrivare. Sto usando Python per costruire uno strumento con (principalmente) lo stack tecnologico di Jina per creare il mio podcast giornaliero personalizzato di notizie.
Se vuoi andare avanti e sentire come suona, puoi ascoltare qui sotto:
tagCos'è un Feed di Notizie?
Prima di tutto, li chiamo "feed di notizie" poiché la maggior parte delle persone non ha familiarità con i termini RSS o Atom feeds. In breve, un feed è una lista strutturata di articoli pubblicati da un blog o una fonte di notizie, ordinati dal più recente al più vecchio. Molti siti li offrono, e ci sono diverse app e siti web che ti permettono di importare tutti i tuoi feed, permettendoti di leggere tutte le tue notizie in una sola app, senza dover visitare i siti web di Ars Technica, siti fan di Taylor Swift, e Washington Post:
Sono una tecnologia antica del web preistorico, ma molti siti web li supportano, incluso il blog di Jina AI (ecco il nostro feed).
In breve, i feed ti permettono di leggere tutte le tue notizie in un unico posto, saltando tutti gli elementi inutili nella barra laterale e la pubblicità. In questo post, useremo i feed di notizie per trovare e scaricare gli ultimi post dai siti che seguiamo.
tagIniziamo Questa Frenesia di Feed
pip install e l'impostazione delle chiavi in questo post, quindi se vuoi seguire il tutorial, consulta il notebook per l'esperienza completa e attieniti a questo post per il quadro generale.Link Colab | Link GitHub
Per realizzare la magia, useremo diversi servizi e librerie Python:
- Feedparser: Una libreria Python per scaricare ed estrarre contenuti dai feed di notizie.
- Jina Reader: L'API di Jina per estrarre solo il contenuto da ogni articolo, senza scaricare elementi inutili come header, footer e barre laterali.
- PromptPerfect: Prompts-as-Services riassumerà ogni articolo e poi combinerà questi riassunti in un unico paragrafo, nello stile di un lettore di notizie della NPR.
- gTTS: La libreria Text-to-Speech di Google, per leggere il notiziario ad alta voce.
Questo è tutto ciò che tratteremo nel post. Se vuoi creare un feed podcast per il tuo podcast personalizzato, ti suggeriamo di consultare altre fonti.
tagScaricare i Feed
Dato che questo è solo un esempio semplice, ci limiteremo a un paio di feed di notizie di The Register e OSNews, due siti di notizie tecnologiche.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]Con Feedparser possiamo scaricare i feed e poi scaricare i link degli articoli da ciascun feed:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagEstrarre il Testo degli Articoli Con Jina Reader
Ogni feed contiene link a ciascun articolo sul sito web corrispondente. Se scaricassimo semplicemente quella pagina web, otterremmo un sacco di HTML, incluse barre laterali, header, footer e altri elementi inutili di cui non abbiamo bisogno. Se dai questo a un LLM sarebbe come masticare erba. Certo, l'LLM può farlo, ma non è ciò che vuole mangiare naturalmente.
Ciò che un LLM vuole veramente è qualcosa simile al testo semplice. Jina Reader converte un articolo in Markdown.

Questo lo fa apparire più così:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...L'abbiamo tagliato più corto perché includere l'intero articolo sarebbe eccessivo. Ma puoi vedere che è un testo chiaro e leggibile (markdown).
Invece di questo:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...Abbiamo dovuto tagliarlo prima di arrivare al contenuto effettivo. C'è semplicemente troppo materiale non leggibile dall'uomo.
Fornendo all'LLM qualcosa che può digerire più naturalmente (come markdown invece di HTML), può darci un output migliore. Altrimenti è come dare Doritos a un leone. Certo, può mangiarli, ma non sarà il miglior leone possibile se mantiene quella dieta.
Per estrarre solo il testo in modo leggibile useremo l'API di Jina Reader:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url>, per esempio https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagRiassumere gli articoli con PromptPerfect
Dato che potrebbero esserci molti articoli, useremo un LLM per riassumere ciascuno separatamente. Se li mettessimo tutti insieme e li dessimo all'LLM da riassumere, potrebbe soffocare con troppi token in una volta.
Questo varierà a seconda di quanti articoli vuoi gestire. Per pochi articoli potrebbe valere la pena concatenarli tutti in un'unica stringa lunga e fare una sola chiamata, risparmiando tempo e denaro. Tuttavia per questo esempio supporremo di avere a che fare con un numero maggiore di articoli.
Per riassumerli useremo un Prompt-as-a-Service da PromptPerfect.
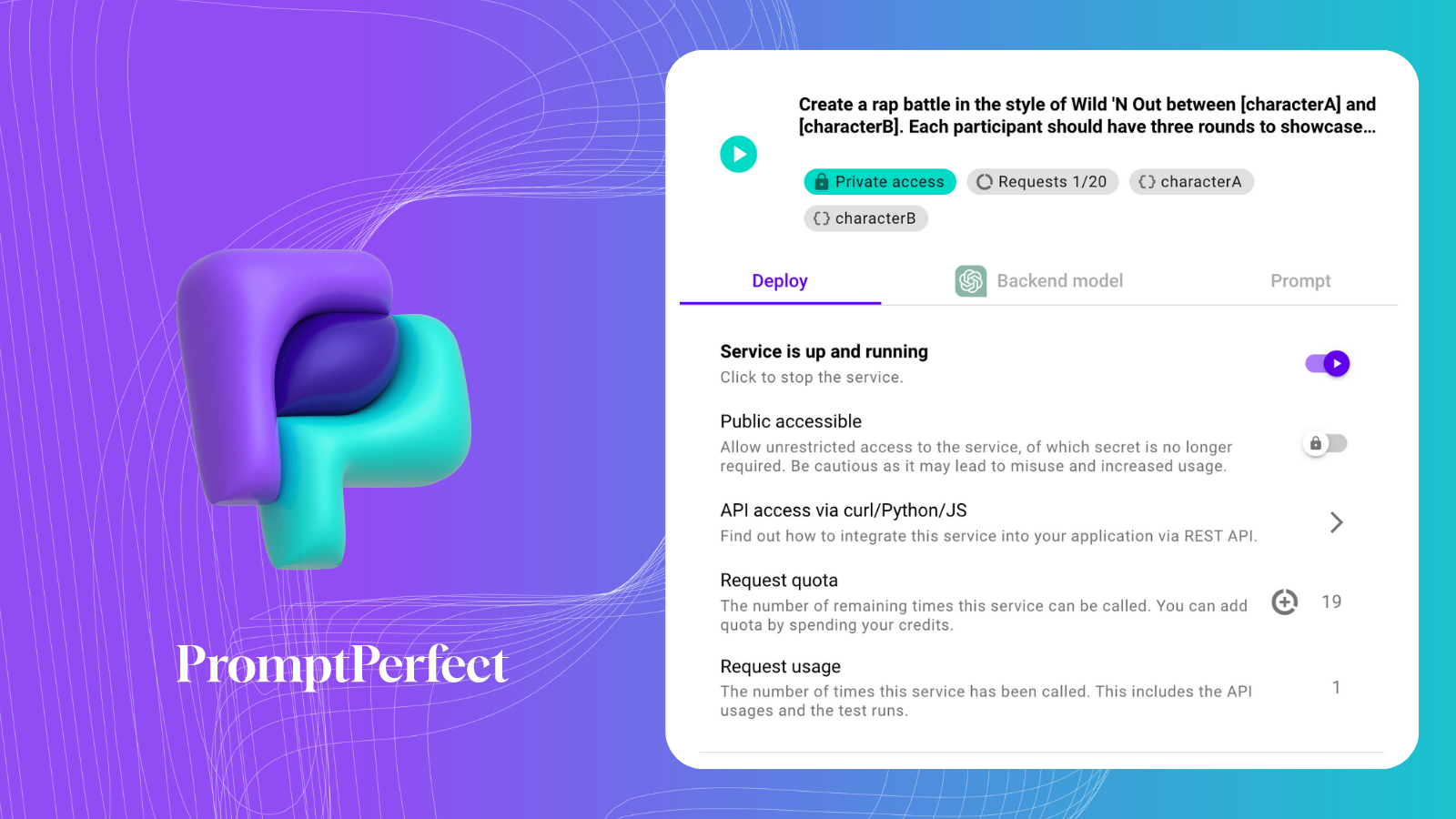
Ecco il nostro Prompt-as-Service:

Scriveremo una funzione per fare questo, poiché chiameremo un altro Prompt-as-Service più avanti in questo post:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.textQuindi prenderemo ogni riassunto e li aggiungeremo a una lista, per infine concatenarli in una lista markdown con punti elenco:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagGenerare un Report di Notizie con PromptPerfect
Ora che abbiamo quella lista con punti elenco, possiamo inviarla a un altro Prompt-as-a-Service per generare un bollettino di notizie che suoni come un naturale discorso da speaker:

Il prompt completo è:
You are an NPR technology news editor. You have received the following news summaries:
[summaries]
Your job is to give a one paragraph overview of the news, covering each item in an organic way, with segues to the next item. You can change the order of the items if that makes sense, and merge duplicates.
You will output a one paragraph script that sounds organic, to be read on NPR daily news. The script should take no longer than five minutes to read aloud.
Otterremo lo script delle notizie con questo codice:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)Ecco il testo finale:
Today in tech news, we have a range of updates and developments to discuss. First up, the Tiny11 Builder tool offers users the ability to debloat Windows 11, creating a customized image tailored to their preferences. Moving on to the world of gaming, we delve into the hidden components inside Super Nintendo cartridges, shedding light on the technology that fascinated gamers in the '90s. Shifting gears to software, the Niri tiling window manager for Wayland has released a major update, offering new features like infinite scrolling and improved animations. In the realm of AI, Microsoft's Copilot feature has faced some hiccups in its rollout to Windows Insiders, with bugs and intrusive behavior prompting a halt in the deployment. Meanwhile, the UK's Information Commissioner's Office raises concerns about Google's Privacy Sandbox, questioning its privacy implications and impact on competition. Lastly, the US Federal Aviation Administration has updated its launch license requirements, now mandating reentry vehicles to obtain a license before launch, following an incident involving Varda Space Industries. These diverse tech stories highlight the ongoing advancements and challenges in the tech world.
tagLeggere le Notizie ad Alta Voce
Per leggere il testo ad alta voce useremo la libreria TTS di Google.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")Questo ci darà un file audio finale:
tagProssimi Passi
Non tratteremo il resto dell'esperienza di creazione del podcast in questo post. Non è il nostro punto di forza e, proprio come per i consigli medici, probabilmente non dovreste ascoltarci quando si tratta dei dettagli pratici sulla configurazione di un feed podcast, sul caricamento su Spotify, Apple Podcasts, ecc. Per consigli medici o sui podcast, rivolgetevi rispettivamente al vostro medico o a Joe Rogan.
Per quanto riguarda cosa altro può fare Jina Reader, pensate a tutte le applicazioni RAG che potete creare scaricando versioni leggibili di qualsiasi pagina web. O per PromptPerfect, scoprite come può aiutare anche gli YouTuber (o gli esperti di marketing, se è quello che vi interessa.)
