



Nell'aprile 2024, abbiamo lanciato Jina Reader, un'API che trasforma qualsiasi pagina web in markdown compatibile con LLM semplicemente aggiungendo r.jina.ai come prefisso URL. Nel settembre 2024, abbiamo lanciato due piccoli modelli linguistici, reader-lm-0.5b e reader-lm-1.5b, specificamente progettati per convertire l'HTML grezzo in markdown pulito. Oggi, siamo entusiasti di presentare la seconda generazione di ReaderLM, un modello linguistico da 1,5B parametri che converte l'HTML grezzo in markdown o JSON formattato in modo impeccabile con una precisione superiore e una migliore gestione di contesti più lunghi. ReaderLM-v2 gestisce fino a 512K token combinati tra input e output. Il modello offre supporto multilingue per 29 lingue, tra cui inglese, cinese, giapponese, coreano, francese, spagnolo, portoghese, tedesco, italiano, russo, vietnamita, thai, arabo e altre.
Grazie al suo nuovo paradigma di addestramento e ai dati di training di qualità superiore, ReaderLM-v2 rappresenta un significativo passo avanti rispetto al suo predecessore, in particolare nella gestione di contenuti lunghi e nella generazione della sintassi markdown. Mentre la prima generazione affrontava la conversione da HTML a markdown come un compito di "copia selettiva", v2 lo tratta come un vero processo di traduzione. Questo cambiamento permette al modello di sfruttare magistralmente la sintassi markdown, eccellendo nella generazione di elementi complessi come blocchi di codice, liste annidate, tabelle ed equazioni LaTex.
Il confronto dei risultati della conversione da HTML a markdown della prima pagina di HackerNews tra ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet e Gemini 2.0 Flash rivela le caratteristiche uniche e le prestazioni di ReaderLM v2. ReaderLM v2 eccelle nel preservare informazioni complete dall'HTML grezzo, inclusi i link originali di HackerNews, strutturando intelligentemente il contenuto utilizzando la sintassi markdown. Il modello utilizza liste annidate per organizzare gli elementi locali (punti, timestamp e commenti) mantenendo una formattazione globale coerente attraverso una corretta gerarchia dei titoli (tag h1 e h2).
Una sfida importante nella nostra prima versione era la degenerazione dopo la generazione di sequenze lunghe, in particolare sotto forma di ripetizione e loop. Il modello avrebbe iniziato a ripetere lo stesso token o si sarebbe bloccato in un loop, ciclando attraverso una breve sequenza di token fino a raggiungere la lunghezza massima dell'output. ReaderLM-v2 allevia notevolmente questo problema aggiungendo una perdita contrastiva durante l'addestramento—le sue prestazioni rimangono costanti indipendentemente dalla lunghezza del contesto o dalla quantità di token già generati.

Oltre alla conversione in markdown, ReaderLM-v2 introduce la generazione diretta da HTML a JSON, permettendo agli utenti di estrarre informazioni specifiche dall'HTML grezzo seguendo uno schema JSON dato. Questo approccio end-to-end elimina la necessità di una conversione intermedia in markdown, un requisito comune in molte pipeline di pulizia ed estrazione dati basate su LLM.

Sia nei benchmark quantitativi che qualitativi, ReaderLM-v2 supera modelli molto più grandi come Qwen2.5-32B-Instruct, Gemini2-flash-expr e GPT-4o-2024-08-06 nelle attività di conversione da HTML a Markdown, mostrando prestazioni comparabili nelle attività di estrazione da HTML a JSON, il tutto utilizzando significativamente meno parametri.

ReaderLM-v2-pro è un checkpoint premium esclusivo riservato ai nostri clienti enterprise, che include addestramento e ottimizzazioni aggiuntive.


Questi risultati stabiliscono che un modello da 1.5B parametri ben progettato può non solo eguagliare ma spesso superare le prestazioni di modelli molto più grandi nelle attività di estrazione di dati strutturati. I miglioramenti progressivi da ReaderLM-v2 a ReaderLM-v2-pro dimostrano l'efficacia della nostra nuova strategia di addestramento nel migliorare le prestazioni del modello mantenendo l'efficienza computazionale.
tagPer Iniziare
tagTramite Reader API

ReaderLM-v2 è ora integrato con la nostra Reader API. Per utilizzarlo, specifica semplicemente x-engine: readerlm-v2 negli header della richiesta e abilita lo streaming delle risposte con -H 'Accept: text/event-stream':
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
Puoi provarlo senza una chiave API con un limite di velocità inferiore. Per limiti di velocità più alti, puoi acquistare una chiave API. Si noti che le richieste ReaderLM-v2 consumano 3 volte il normale conteggio di token dalla tua chiave API. Questa funzionalità è attualmente in beta mentre collaboriamo con il team GCP per ottimizzare l'efficienza della GPU e aumentare la disponibilità del modello.
tagSu Google Colab

Nota che la GPU T4 gratuita ha delle limitazioni—non supporta bfloat16 o flash attention 2, portando a un maggiore utilizzo della memoria e a un'elaborazione più lenta degli input più lunghi. Tuttavia, ReaderLM v2 elabora con successo la nostra intera pagina legale con questi vincoli, raggiungendo velocità di elaborazione di 67 token/s in input e 36 token/s in output. Per l'uso in produzione, raccomandiamo una RTX 3090/4090 per prestazioni ottimali.
Il modo più semplice per provare ReaderLM-v2 in un ambiente ospitato è attraverso il nostro notebook Colab, che dimostra la conversione da HTML a Markdown, l'estrazione JSON e il seguimento delle istruzioni utilizzando la prima pagina di HackerNews come esempio. Il notebook è ottimizzato per il livello gratuito GPU T4 di Colab e richiede vllm e triton per l'accelerazione e l'esecuzione. Sentiti libero di testarlo con qualsiasi sito web.
Conversione da HTML a Markdown
Puoi utilizzare la funzione helper create_prompt per creare facilmente un prompt per convertire HTML in Markdown:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result sarà una stringa racchiusa in backtick Markdown come recinzione di codice. Puoi anche sovrascrivere le impostazioni predefinite per esplorare output diversi, per esempio:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()Tuttavia, poiché i nostri dati di addestramento potrebbero non coprire ogni tipo di istruzione, in particolare compiti che richiedono ragionamento in più passaggi, i risultati più affidabili provengono dalla conversione da HTML a Markdown. Per l'estrazione di informazioni più efficace, raccomandiamo di utilizzare lo schema JSON come mostrato di seguito:
Estrazione da HTML a JSON con schema JSON
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result sarà una stringa racchiusa in backtick formattati JSON, non un vero oggetto JSON/dict. Puoi utilizzare Python per analizzare la stringa in un dizionario o oggetto JSON appropriato per ulteriori elaborazioni.
tagIn Produzione: Disponibile su CSP
ReaderLM-v2 è disponibile su AWS SageMaker, Azure e GCP marketplace. Se hai bisogno di utilizzare questi modelli al di fuori di queste piattaforme o on-premises all'interno della tua azienda, nota che questo modello e ReaderLM-v2-pro sono entrambi licenziati sotto CC BY-NC 4.0. Per richieste di utilizzo commerciale o l'accesso a ReaderLM-v2-pro, non esitare a contattarci.

tagValutazione Quantitativa
Valutiamo ReaderLM-v2 su tre task di estrazione di dati strutturati confrontandolo con modelli allo stato dell'arte: GPT-4o-2024-08-06, Gemini2-flash-expr e Qwen2.5-32B-Instruct. Il nostro framework di valutazione combina metriche che misurano sia l'accuratezza del contenuto che la fedeltà strutturale. ReaderLM-v2 è la versione pubblicamente disponibile con pesi aperti, mentre ReaderLM-v2-pro è un checkpoint premium esclusivo riservato ai nostri clienti enterprise, che presenta training e ottimizzazioni aggiuntive. Si noti che la nostra prima generazione reader-lm-1.5b è valutata solo sul task di estrazione del contenuto principale, poiché non supporta le capacità di estrazione guidata o estrazione JSON.
tagMetriche di Valutazione
Per i task HTML-to-Markdown, utilizziamo sette metriche complementari. Nota: ↑ indica che valori più alti sono migliori, ↓ indica che valori più bassi sono migliori
- ROUGE-L (↑): Misura la più lunga sottosequenza comune tra il testo generato e quello di riferimento, catturando la conservazione del contenuto e la similarità strutturale. Intervallo: 0-1, valori più alti indicano una migliore corrispondenza delle sequenze.
- WER (Word Error Rate) (↓): Quantifica il numero minimo di modifiche a livello di parola necessarie per trasformare il testo generato in quello di riferimento. Valori più bassi indicano meno correzioni necessarie.
- SUB (Sostituzioni) (↓): Conta il numero di sostituzioni di parole necessarie. Valori più bassi suggeriscono una migliore accuratezza a livello di parola.
- INS (Inserimenti) (↓): Misura il numero di parole che devono essere inserite per corrispondere al riferimento. Valori più bassi indicano una migliore completezza.
- Distanza di Levenshtein (↓): Calcola il numero minimo di modifiche a singoli caratteri necessarie. Valori più bassi suggeriscono una migliore accuratezza a livello di carattere.
- Distanza di Damerau-Levenshtein (↓): Simile a Levenshtein ma considera anche le trasposizioni di caratteri. Valori più bassi indicano una migliore corrispondenza a livello di carattere.
- Similarità di Jaro-Winkler (↑): Enfatizza la corrispondenza dei caratteri all'inizio delle stringhe, particolarmente utile per valutare la conservazione della struttura del documento. Intervallo: 0-1, valori più alti indicano una migliore similarità.
Per i task HTML-to-JSON, lo consideriamo come un task di recupero e adottiamo quattro metriche dal recupero di informazioni:
- F1 Score (↑): Media armonica di precisione e richiamo, fornisce l'accuratezza complessiva. Intervallo: 0-1.
- Precision (↑): Proporzione di informazioni estratte correttamente tra tutte le estrazioni. Intervallo: 0-1.
- Recall (↑): Proporzione di informazioni estratte correttamente da tutte le informazioni disponibili. Intervallo: 0-1.
- Pass-Rate (↑): Proporzione di output che sono JSON validi e conformi allo schema. Intervallo: 0-1.
tagTask HTML-to-Markdown del Contenuto Principale
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tagTask HTML-to-Markdown Guidato
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagTask HTML-to-JSON Basato su Schema
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 rappresenta un significativo avanzamento in tutti i task. Per l'estrazione del contenuto principale, ReaderLM-v2-pro raggiunge le migliori prestazioni in cinque metriche su sette, con punteggi superiori in ROUGE-L (0.86), WER (0.39), Levenshtein (0.20), Damerau (928.15) e Jaro-Winkler (0.83). Questi risultati dimostrano miglioramenti complessivi sia nella conservazione del contenuto che nell'accuratezza strutturale rispetto sia alla versione base che ai modelli più grandi.
Nell'estrazione guidata, ReaderLM-v2 e ReaderLM-v2-pro sono in testa per ROUGE-L (0.72), tasso di sostituzione (70.16), distanza di Levenshtein (0.37) e similarità di Jaro-Winkler (0.75, alla pari con la versione base). Mentre GPT-4o mostra vantaggi in WER e distanza di Damerau, ReaderLM-v2-pro mantiene una migliore struttura e accuratezza complessiva del contenuto. Nell'estrazione JSON, il modello si comporta in modo competitivo, rimanendo entro 0.01-0.02 punti F1 dai modelli più grandi mentre raggiunge alti tassi di successo (0.99).
tagValutazione Qualitativa
Durante la nostra analisi diCon reader-lm-1.5b, abbiamo osservato che le metriche quantitative da sole potrebbero non catturare completamente le prestazioni del modello. Le valutazioni numeriche a volte non riflettevano la qualità percepita—casi in cui punteggi metrici bassi producevano markdown visivamente soddisfacente, o punteggi alti davano risultati subottimali. Per affrontare questa discrepanza, abbiamo condotto valutazioni qualitative sistematiche su 10 diverse fonti HTML, tra cui articoli di news, post di blog, pagine di prodotti, siti di e-commerce e documenti legali in inglese, giapponese e cinese. Il corpus di test ha enfatizzato elementi di formattazione impegnativi come tabelle multi-riga, layout dinamici, formule LaTeX, tabelle collegate e liste annidate, fornendo una visione più completa delle capacità del modello nel mondo reale.
tagMetriche di Valutazione
La nostra valutazione umana si è concentrata su tre dimensioni chiave, con output valutati su una scala da 1 a 5:
Integrità dei Contenuti - Valuta la preservazione delle informazioni semantiche durante la conversione da HTML a markdown, inclusi:
- Accuratezza e completezza del contenuto testuale
- Preservazione di link, immagini, blocchi di codice, formule e citazioni
- Mantenimento della formattazione del testo e degli URL di link/immagini
Accuratezza Strutturale - Valuta la corretta conversione degli elementi strutturali HTML in Markdown:
- Preservazione della gerarchia dei header
- Accuratezza dell'annidamento delle liste
- Fedeltà della struttura delle tabelle
- Formattazione di blocchi di codice e citazioni
Conformità al Formato - Misura l'aderenza agli standard della sintassi Markdown:
- Uso corretto della sintassi per header (#), liste (*, +, -), tabelle, blocchi di codice (```)
- Formattazione pulita senza spazi bianchi in eccesso o sintassi non standard
- Output renderizzato coerente e leggibile
Durante la valutazione manuale di oltre 10 pagine HTML, ogni criterio di valutazione ha un punteggio massimo di 50 punti. ReaderLM-v2 ha dimostrato forti prestazioni in tutte le dimensioni:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
Per la completezza dei contenuti, ha eccelluto nel riconoscimento di elementi complessi, in particolare formule LaTeX, liste annidate e blocchi di codice. Il modello ha mantenuto un'alta fedeltà nella gestione di strutture di contenuto complesse mentre i modelli concorrenti spesso tralasciavano gli header H1 (reader-lm-1.5b), troncavano il contenuto (Claude 3.5), o mantenevano i tag HTML grezzi (Gemini-2.0-flash).
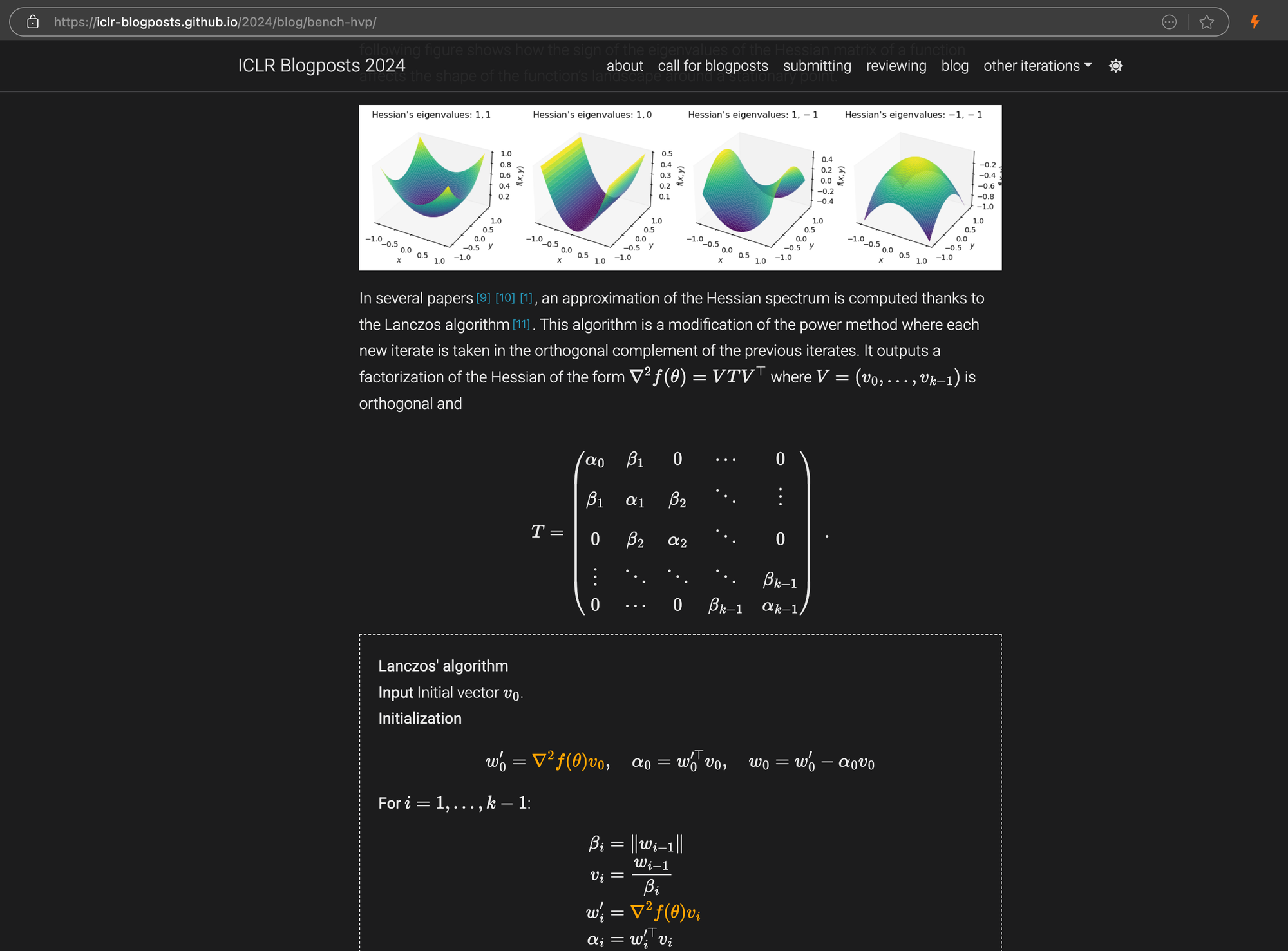
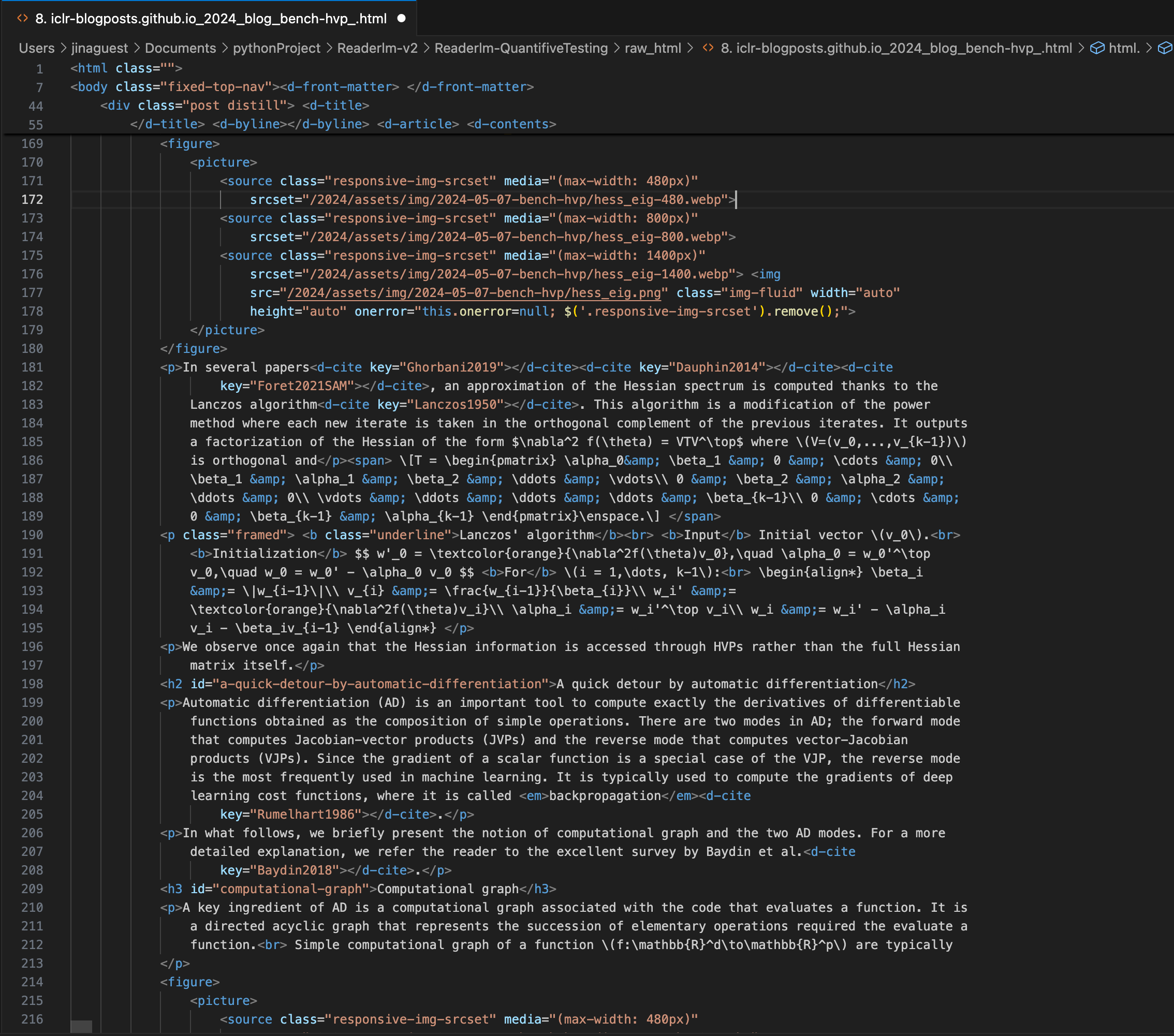
Un post del blog ICLR con complesse equazioni LaTeX incorporate nel markdown, che mostra il codice HTML sorgente nel pannello di destra.
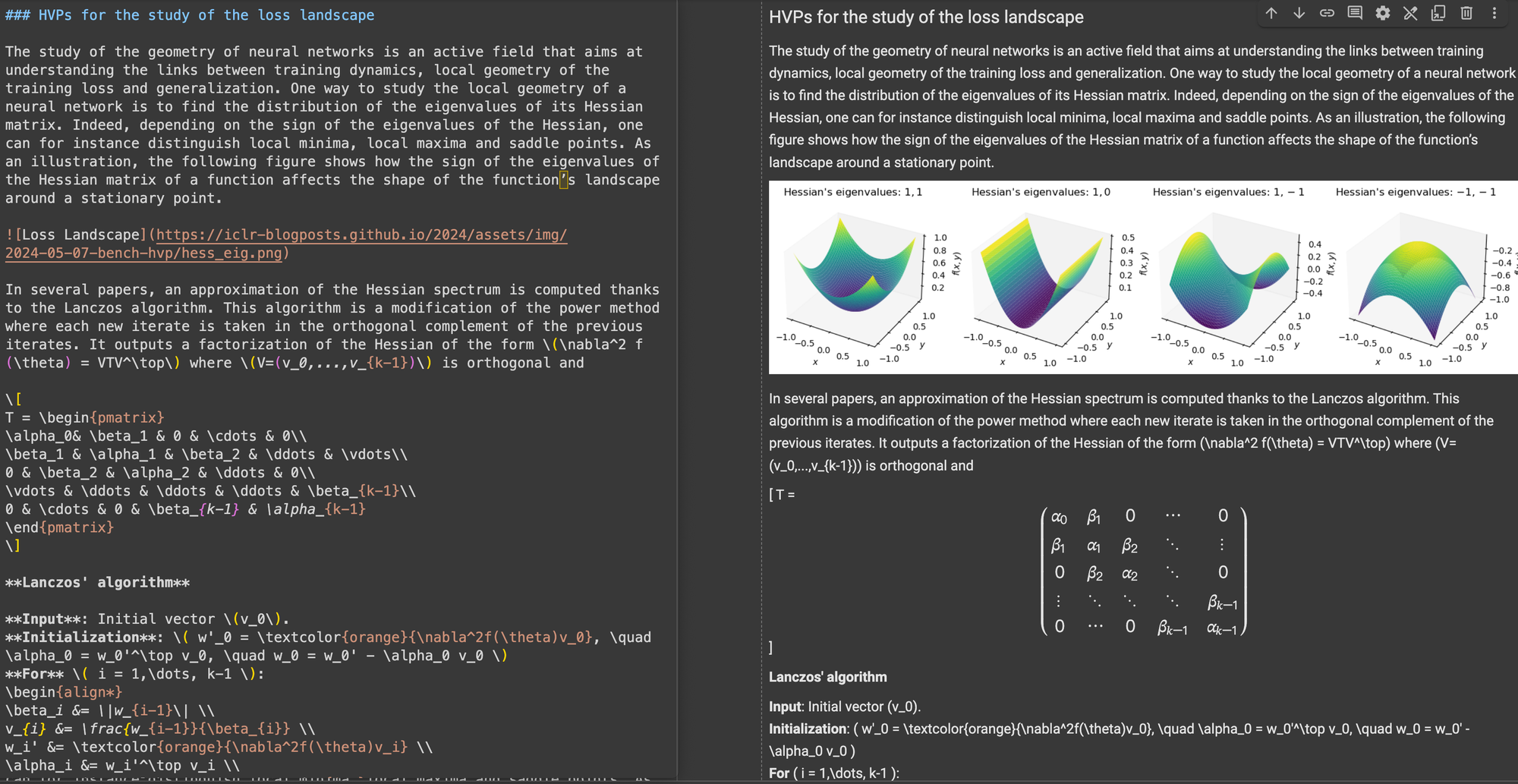
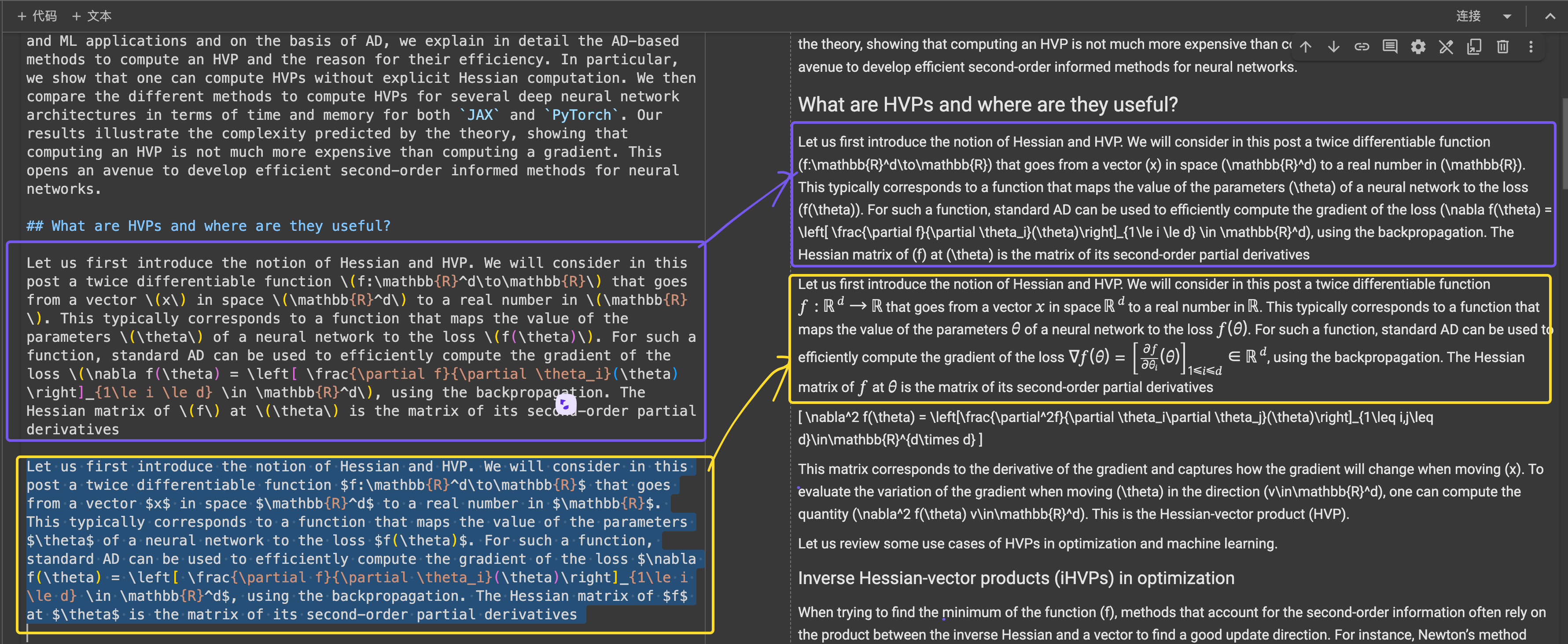
\[...\] (e i suoi equivalenti HTML) con delimitatori standard Markdown come $...$ per le equazioni in linea e $$...$$ per le equazioni visualizzate. Questo aiuta a prevenire conflitti di sintassi nell'interpretazione Markdown.Nell'accuratezza strutturale, ReaderLM-v2 ha mostrato ottimizzazione per le strutture web comuni. Per esempio, nei casi di Hacker News, ha ricostruito con successo i link completi e ottimizzato la presentazione delle liste. Il modello ha gestito strutture HTML complesse non-blog che avevano messo in difficoltà ReaderLM-v1.
Per la conformità al formato, ReaderLM-v2 ha dimostrato particolare forza nella gestione di contenuti come Hacker News, blog e articoli WeChat. Mentre altri modelli linguistici di grandi dimensioni hanno performato bene su fonti simili a markdown, hanno faticato con siti web tradizionali che richiedevano maggiore interpretazione e riformattazione.
La nostra analisi ha rivelato che gpt-4o eccelle nell'elaborazione di siti web più brevi, dimostrando una comprensione superiore della struttura e della formattazione del sito rispetto ad altri modelli. Tuttavia, quando gestisce contenuti più lunghi, gpt-4o ha difficoltà con la completezza, spesso omettendo porzioni dall'inizio e dalla fine del testo. Abbiamo incluso un'analisi comparativa degli output di gpt-4o, ReaderLM-v2 e ReaderLM-v2-pro usando il sito web di Zillow come esempio.
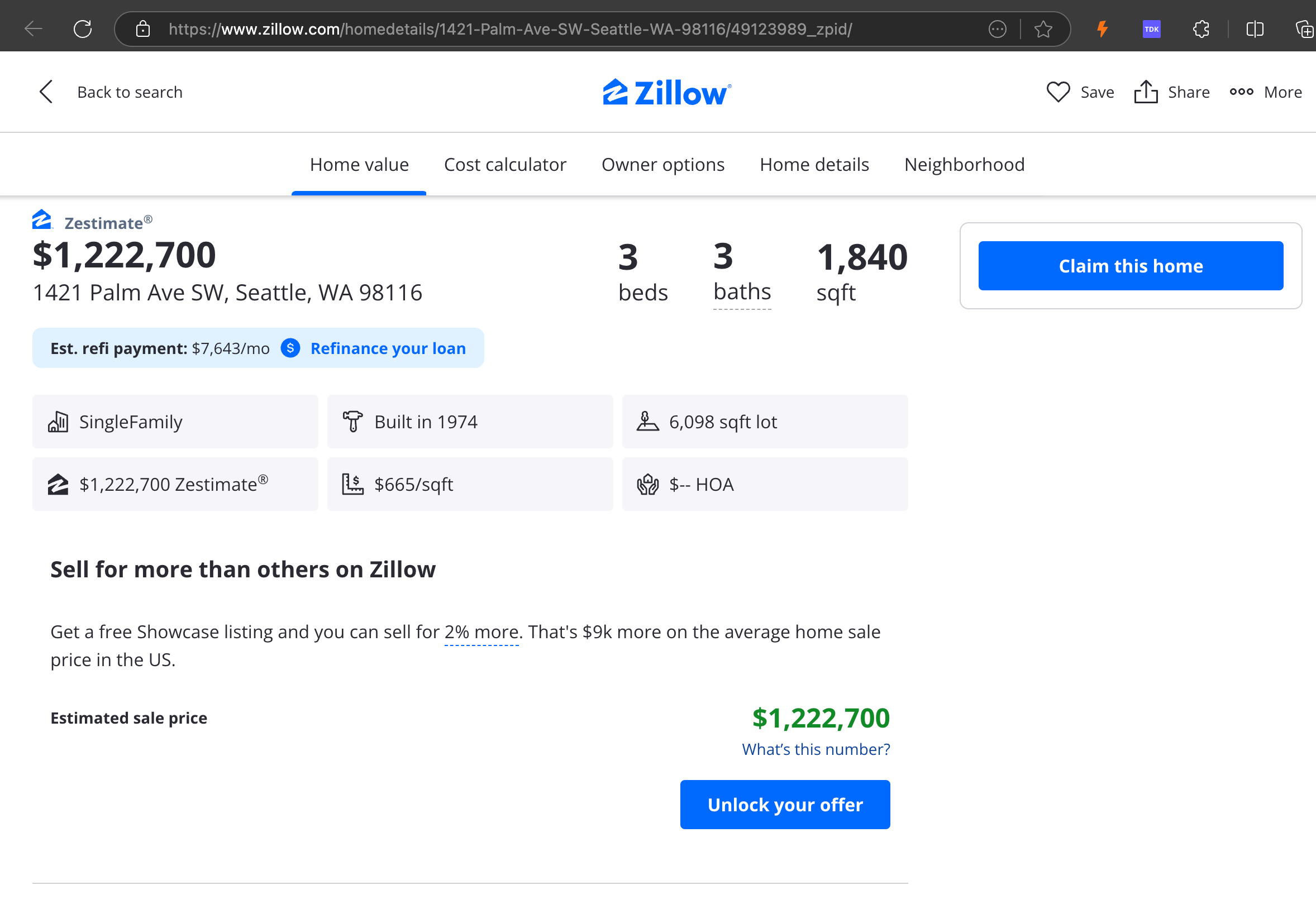
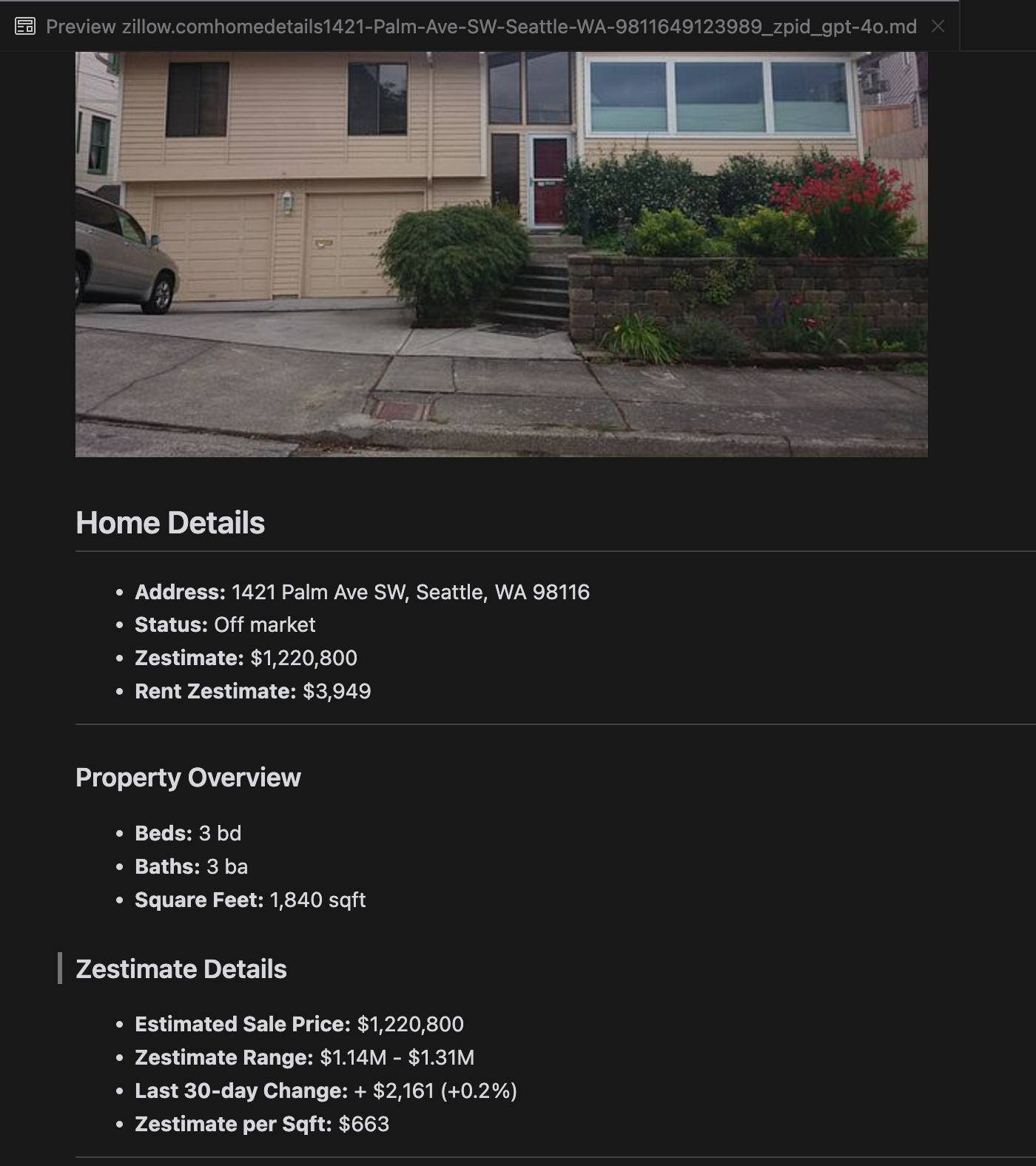
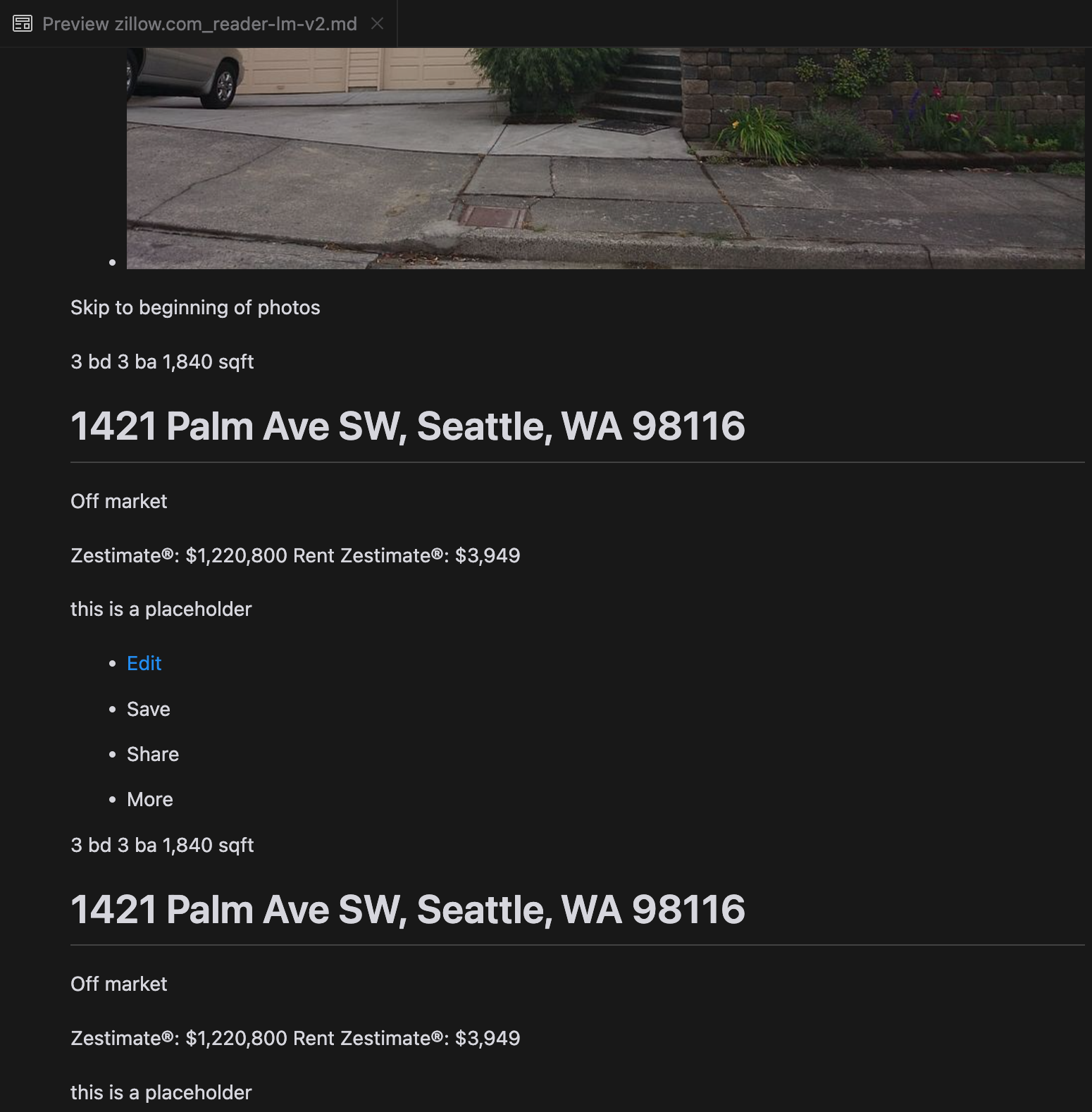
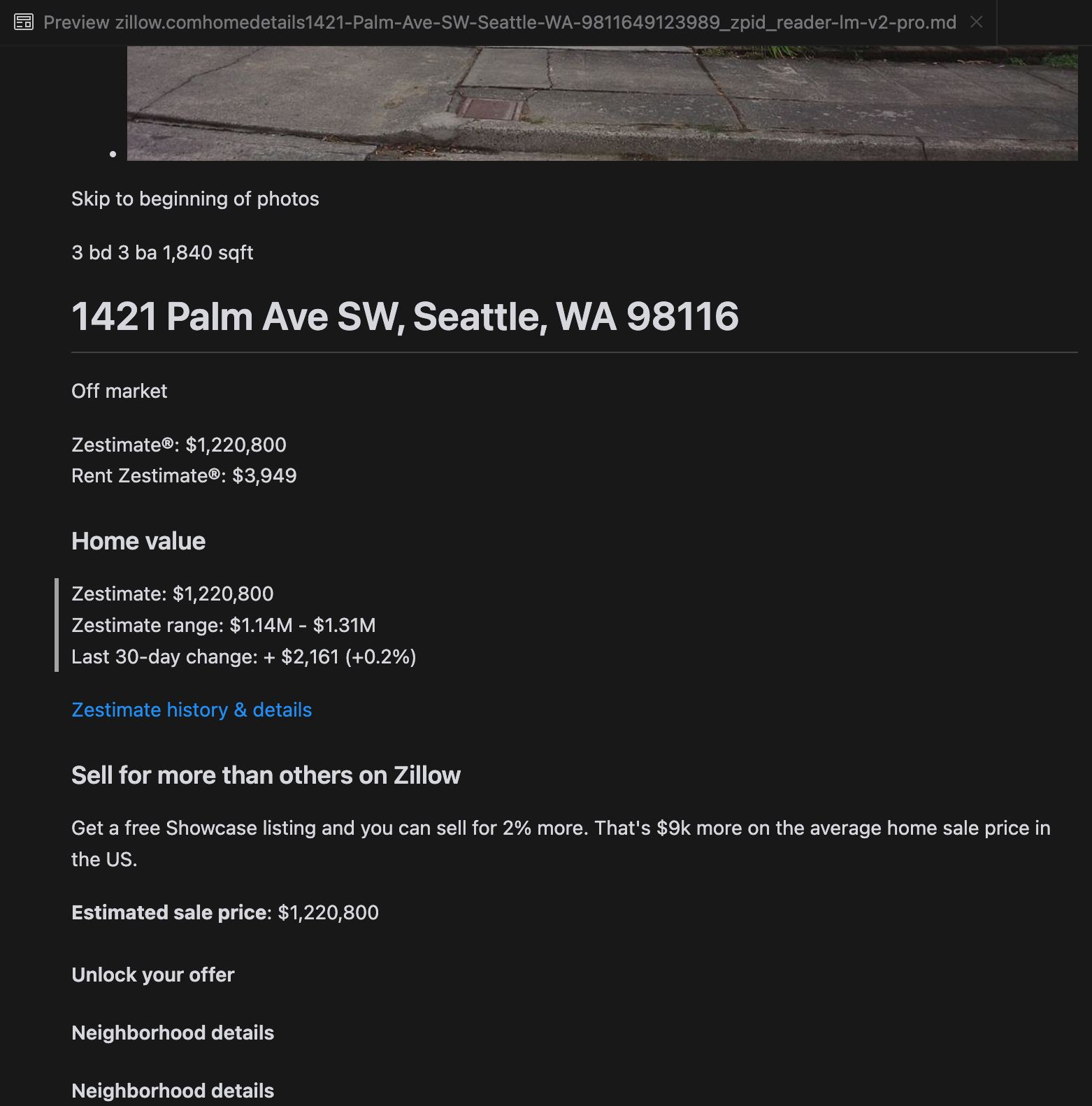
Un confronto degli output Markdown renderizzati da gpt-4o (sinistra), ReaderLM-v2 (centro) e ReaderLM-v2-pro (destra).
Per alcuni casi complessi come le landing page dei prodotti e i documenti governativi, le prestazioni di ReaderLM-v2 e ReaderLM-v2-pro sono rimaste robuste ma hanno ancora margini di miglioramento. Le formule matematiche complesse e il codice nei post del blog ICLR hanno posto sfide per la maggior parte dei modelli, anche se ReaderLM-v2 ha gestito questi casi meglio dell'API Reader di base.
tagCome Abbiamo Addestrato ReaderLM v2
ReaderLM-v2 è basato su Qwen2.5-1.5B-Instruction, un modello base compatto noto per la sua efficienza nel seguire le istruzioni e nei compiti con contesto lungo. In questa sezione, descriviamo come abbiamo addestrato ReaderLM-v2, concentrandoci sulla preparazione dei dati, i metodi di addestramento e le sfide che abbiamo incontrato.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagPreparazione dei Dati
Il successo di ReaderLM-v2 dipendeva in gran parte dalla qualità dei suoi dati di addestramento. Abbiamo creato il dataset html-markdown-1m, che includeva un milione di documenti HTML raccolti da internet. In media, ogni documento conteneva 56.000 token, riflettendo la lunghezza e la complessità dei dati web reali. Per preparare questo dataset, abbiamo pulito i file HTML rimuovendo elementi non necessari come JavaScript e CSS, mantenendo gli elementi strutturali e semantici chiave. Dopo la pulizia, abbiamo utilizzato Jina Reader per convertire i file HTML in Markdown utilizzando pattern regex ed euristiche.
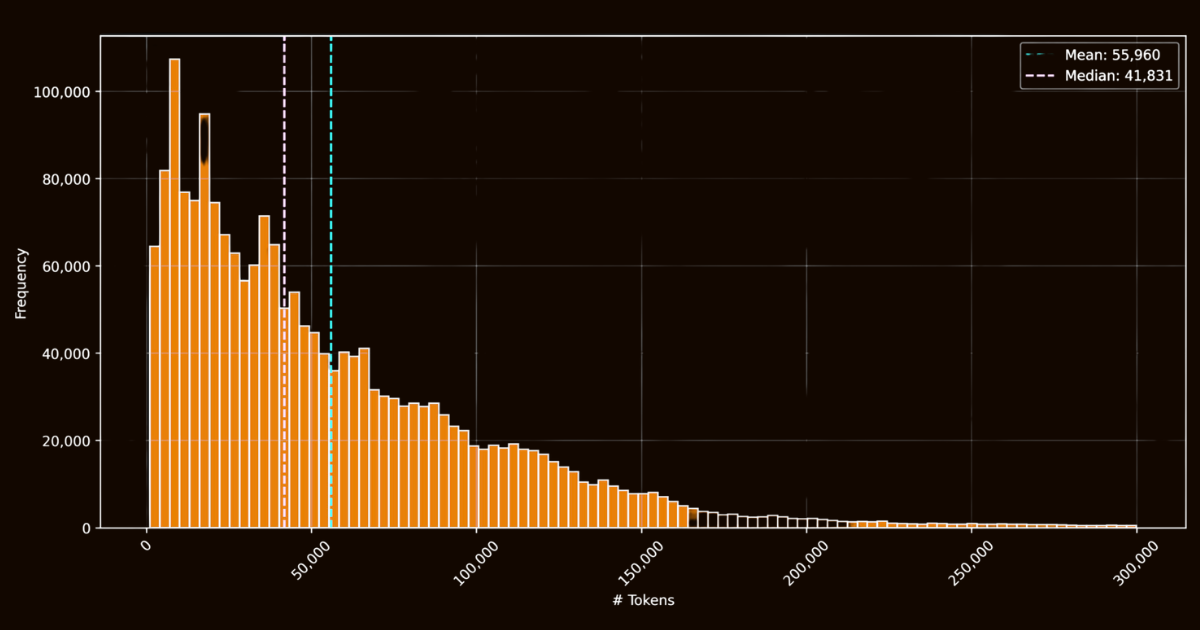
html-markdown-1mMentre questo ha creato un dataset di base funzionale, ha evidenziato una limitazione critica: i modelli addestrati esclusivamente su queste conversioni dirette avrebbero essenzialmente imparato solo a imitare i pattern regex e le euristiche utilizzate da Jina Reader. Questo è diventato evidente con reader-lm-0.5b/1.5b, le cui prestazioni massime erano limitate dalla qualità di queste conversioni basate su regole.
Per affrontare queste limitazioni, abbiamo sviluppato una pipeline in tre fasi basata sul modello Qwen2.5-32B-Instruction, che è essenziale per creare un dataset sintetico di alta qualità.

Qwen2.5-32B-Instruction- Bozza: Abbiamo generato output iniziali in Markdown e JSON basati sulle istruzioni fornite al modello. Questi output, sebbene diversificati, erano spesso rumorosi o inconsistenti.
- Raffinamento: Le bozze generate sono state migliorate rimuovendo contenuti ridondanti, imponendo coerenza strutturale e allineando con i formati desiderati. Questo passaggio ha assicurato che i dati fossero puliti e allineati con i requisiti del compito.
- Critica: Gli output raffinati sono stati valutati rispetto alle istruzioni originali. Solo i dati che hanno superato questa valutazione sono stati inclusi nel dataset finale. Questo approccio iterativo ha assicurato che i dati di addestramento soddisfacessero gli standard di qualità necessari per l'estrazione di dati strutturati.
tagProcesso di Addestramento
Il nostro processo di addestramento ha coinvolto più fasi adattate alle sfide dell'elaborazione di documenti con contesto lungo.
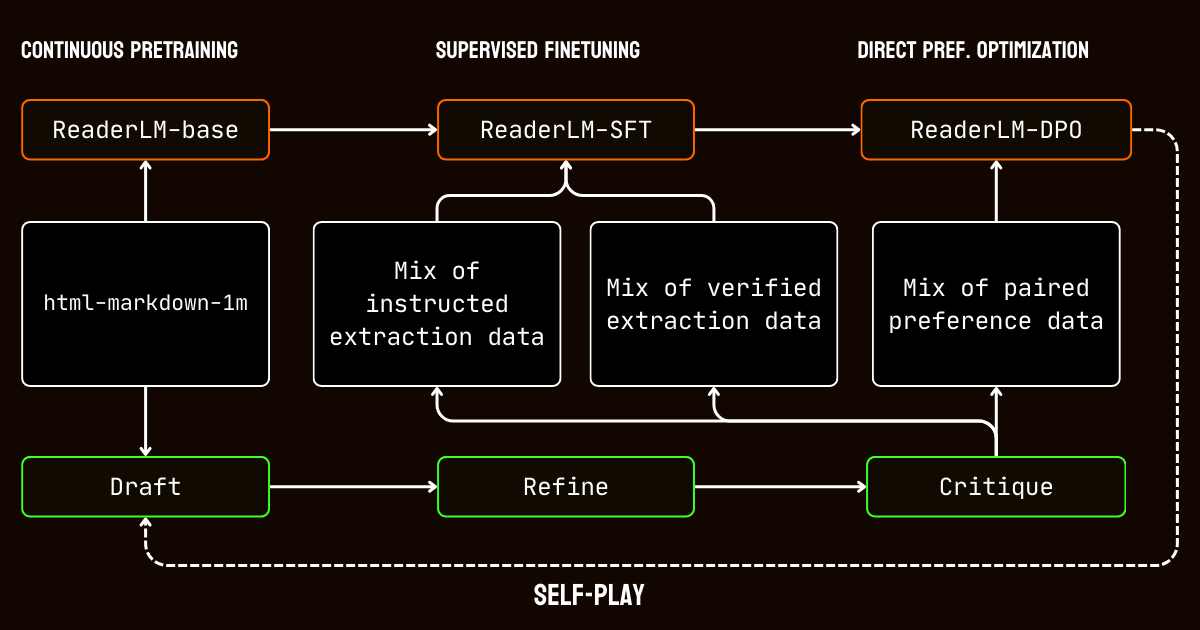
Abbiamo iniziato con il pre-addestramento per contesti lunghi, utilizzando il dataset html-markdown-1m. Tecniche come l'attenzione ring-zag e l'encoding posizionale rotante (RoPE) sono state utilizzate per espandere progressivamente la lunghezza del contesto del modello da 32.768 token a 256.000 token. Per mantenere stabilità ed efficienza, abbiamo adottato un approccio di addestramento graduale, iniziando con sequenze più brevi e aumentando incrementalmente la lunghezza del contesto.
Dopo il pre-addestramento, siamo passati al fine-tuning supervisionato (SFT). Questa fase ha utilizzato i dataset raffinati generati nel processo di preparazione dei dati. Questi dataset includevano istruzioni dettagliate per i compiti di estrazione Markdown e JSON, insieme a esempi per il raffinamento delle bozze. Ogni dataset è stato attentamente progettato per aiutare il modello ad apprendere compiti specifici, come l'identificazione del contenuto principale o l'adesione a strutture JSON basate su schema.
Abbiamo poi applicato l'ottimizzazione diretta delle preferenze (DPO) per allineare gli output del modello con risultati di alta qualità. In questa fase, il modello è stato addestrato su coppie di risposte bozza e raffinate. Imparando a dare priorità agli output raffinati, il modello ha interiorizzato le sottili distinzioni che definiscono risultati rifiniti e specifici per il compito.
Infine, abbiamo implementato il tuning del rinforzo in auto-gioco, un processo iterativo dove il modello genera, raffina e valuta i propri output. Questo ciclo ha permesso al modello di migliorare continuamente senza richiedere ulteriore supervisione esterna. Sfruttando le proprie critiche e raffinamenti, il modello ha gradualmente migliorato la sua capacità di produrre output accurati e strutturati.
tagConclusione
Nell'aprile 2024, Jina Reader è diventata la prima API markdown compatibile con LLM. Ha stabilito una nuova tendenza, ha ottenuto un'ampia adozione da parte della comunità e, cosa più importante, ci ha ispirato a costruire piccoli modelli linguistici per la pulizia e l'estrazione dei dati. Oggi, alziamo nuovamente l'asticella con ReaderLM-v2, mantenendo le promesse fatte lo scorso settembre: migliore gestione dei contesti lunghi, supporto per le istruzioni di input e capacità di estrarre contenuti specifici delle pagine web in formato markdown. Ancora una volta, abbiamo dimostrato che con un addestramento e una calibrazione attenti, i piccoli modelli linguistici possono raggiungere prestazioni allo stato dell'arte che superano i modelli più grandi.
Durante il processo di addestramento di ReaderLM-v2, abbiamo identificato due intuizioni. Una strategia efficace è stata l'addestramento di modelli specializzati su dataset separati adattati a compiti specifici. Questi modelli specifici per compito sono stati successivamente uniti utilizzando l'interpolazione lineare dei parametri. Sebbene questo approccio richiedesse uno sforzo aggiuntivo, ha aiutato a preservare i punti di forza unici di ogni modello specializzato nel sistema unificato finale.
Il processo iterativo di sintesi dei dati si è rivelato cruciale per il successo del nostro modello. Attraverso il perfezionamento e la valutazione ripetuti dei dati sintetici, abbiamo migliorato significativamente le prestazioni del modello oltre i semplici approcci basati su regole. Questa strategia iterativa, pur presentando sfide nel mantenere valutazioni critiche coerenti e nella gestione dei costi computazionali, è stata essenziale per superare i limiti dell'utilizzo di dati di training basati su regex ed euristiche da Jina Reader. Questo è chiaramente dimostrato dal divario di prestazioni tra reader-lm-1.5b, che si basa fortemente sulle conversioni basate su regole di Jina Reader, e ReaderLM-v2 che beneficia di questo processo di perfezionamento iterativo.
Siamo ansiosi di ricevere il vostro feedback su come ReaderLM-v2 migliora la qualità dei vostri dati. Guardando al futuro, prevediamo di espandere le capacità multimodali, in particolare per i documenti scansionati, e di ottimizzare ulteriormente la velocità di generazione. Se siete interessati a una versione personalizzata di ReaderLM adattata al vostro dominio specifico, vi preghiamo di contattarci.
