


多くの人と同様に、私もたくさんのポッドキャストを聴いています。SFに関するもの、古生物学に関するもの、そして変わった中世の人々に関するものもあります。残念ながら犯罪モノは聴いていません(私の時々の悪趣味を除けば)。
しかし...これらのポッドキャストを全部聴くのは大変です。でもそれだけではありません。私はまたたくさんのニュースフィードも購読しています。それを読むのもかなりの時間がかかります。朝の歯磨きをしている間に、それらのニュースフィードの内容を全て 5 分のサマリーにまとめて、スマートフォンで読み上げてくれたら素晴らしいのに、と思います。
ここからどこに話が向かうか想像できると思います。私は Python を使って、(主に)Jina のテックスタックで、パーソナライズされた日刊ニュースポッドキャストを作るツールを開発しています。
実際にどんな音声になるのか先に聴いてみたい場合は、以下で聴くことができます:
tagニュースフィードとは何か
まず、多くの人が RSS や Atom フィードという用語に馴染みがないため、「ニュースフィード」と呼んでいます。簡単に言うと、フィードはブログやニュースソースが公開した記事の構造化されたリストで、新しい順に並んでいます。多くのサイトがこれを提供しており、複数のアプリやウェブサイトでこれらのフィードを一括インポートできます。これにより、Ars Technica、Taylor Swift ファンサイト、Washington Post などのウェブサイトを個別に訪れることなく、1 つのアプリで全てのニュースを読むことができます:
これは Web の先史時代からある古い技術ですが、Jina AI のブログ(こちらが私たちのフィードです)を含む多くのウェブサイトがサポートしています。
要するに、フィードを使えばサイドバーの余計なものや広告をスキップして、1 か所で全てのニュースを読むことができます。この記事では、ニュースフィードを使って、フォローしているサイトから最新の投稿を見つけてダウンロードします。
tagフィーディングフレンジーを始めよう
pip install とキーの設定については触れていないので、実際に試してみたい場合は、完全な体験のためにノートブックをご覧いただき、この投稿では全体像を把握するにとどめてください。Colab リンク | GitHub リンク
実現するために、以下のサービスと Python ライブラリを使用します:
- Feedparser:ニュースフィードからコンテンツをダウンロードして抽出する Python ライブラリ。
- Jina Reader:ヘッダー、フッター、サイドバーなどの不要な情報をダウンロードせず、記事のコンテンツのみを抽出する Jina の API。
- PromptPerfect:Prompts-as-Services が各記事を要約し、それらの要約を NPR のニュースリーダーのスタイルで一つの段落にまとめます。
- gTTS:ニュースレポートを音声で読み上げる Google の Text-to-Speech ライブラリ。
この投稿ではここまでを扱います。パーソナライズされたポッドキャストのフィードを作成したい場合は、他のソースをご確認ください。
tagフィードのダウンロード
これは単純な例なので、The Register と OSNews という 2 つのテクノロジーニュースサイトのフィードのみを使用します。
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]Feedparser を使用してフィードをダウンロードし、各フィードから記事のリンクをダウンロードできます:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagJina Reader による記事テキストの抽出
各フィードには、それぞれのウェブサイトの記事へのリンクが含まれています。そのウェブページをただダウンロードすると、サイドバー、ヘッダー、フッターなど、不要な情報を含む HTML 全体が取得されます。これを LLM に与えるのは、草を噛むようなものです。LLM は処理できますが、それは自然な入力とは言えません。
LLM が本当に必要とするのは、プレーンテキストに近いものです。Jina Reader は記事を Markdown に変換します。

これにより、以下のような形式になります:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...記事全体を含めるのは冗長なので、ここで短縮しています。しかし、人間が読みやすい(markdown)テキストになっているのが分かります。
以下のような形式ではなく:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...実際のコンテンツに到達する前に短縮せざるを得ませんでした。人間が読めない情報があまりにも多すぎます。
LLM により自然な形式(HTML ではなく markdown)で入力を与えることで、より良い出力を得ることができます。そうでなければ、ライオンにドリトスを与えるようなものです。食べることは可能かもしれませんが、その食事を続けると最高のライオンとしての能力を発揮できなくなります。
人間が読みやすい形式でテキストのみを抽出するために、Jina Reader の API を使用します:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url> にアクセスしてください。例:https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagPromptPerfect による記事の要約
記事の数が非常に多い可能性があるため、LLM を使用して各記事を個別に要約します。すべての記事を一度に LLM に与えて要約させると、トークン数が多すぎて処理できない可能性があります。
これは扱う記事の数によって異なります。少数の記事の場合は、すべてを一つの長い文字列に結合して一回の呼び出しで処理する方が、時間とコストの節約になるかもしれません。しかし、この例では多数の記事を扱うことを想定しています。
要約には、PromptPerfect の Prompt-as-a-Service を使用します。
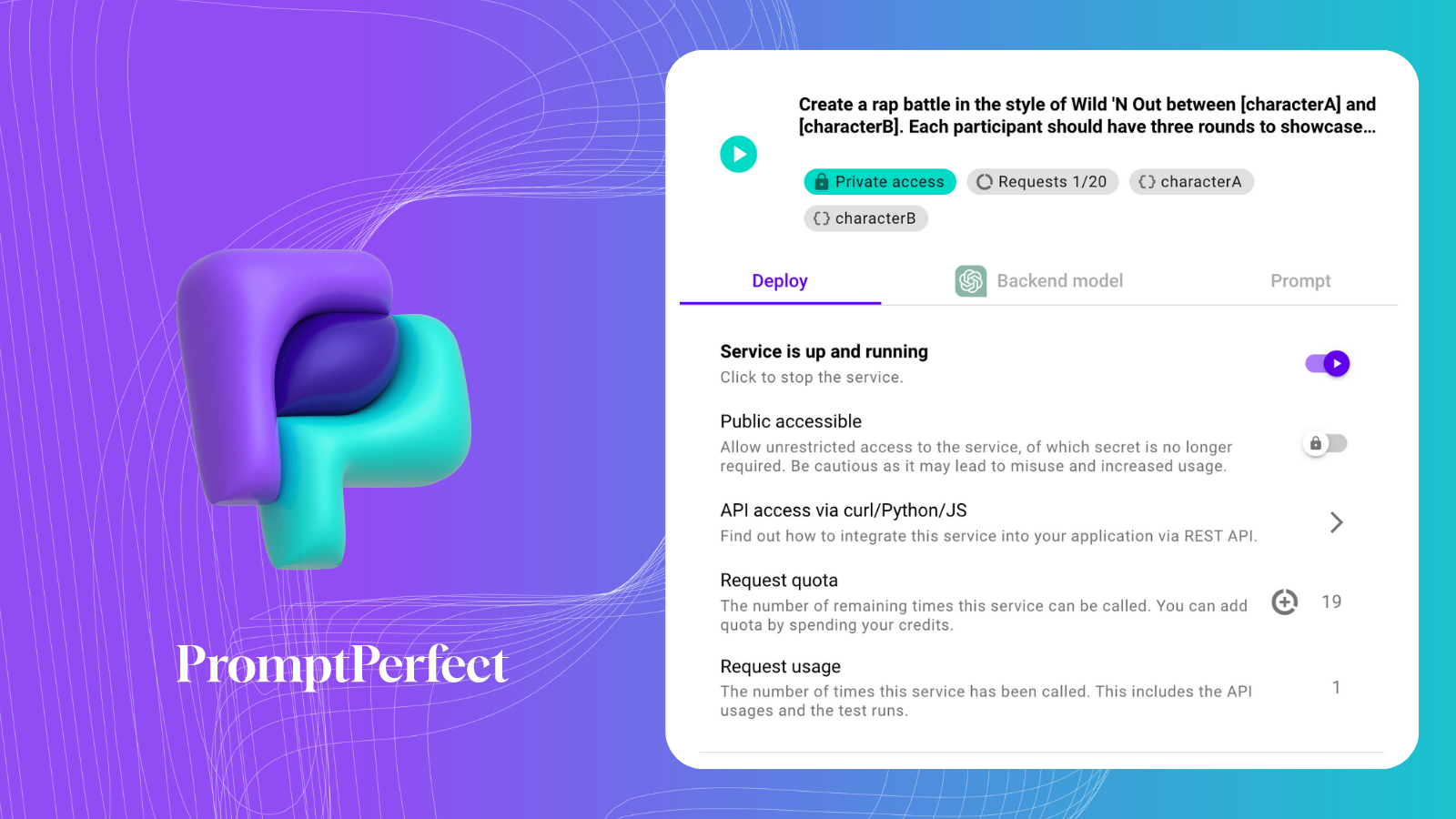
こちらが私たちの Prompt-as-Service です:

この投稿の後半で別の Prompt-as-Service を呼び出すため、関数を作成しましょう:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.text各要約をリストに追加し、最終的に箇条書きのマークダウンリストに連結します:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagPromptPerfect でニュースレポートを生成する
箇条書きリストができたので、自然なニュースリーダーの話し方のように聞こえるニュースレポートを生成するために、別の Prompt-as-Service に送信できます:

完全なプロンプトは次のとおりです:
あなたは NPR のテクノロジーニュース編集者です。以下のニュース要約を受け取りました:
[summaries]
あなたの仕事は、各項目を有機的な方法でカバーし、次の項目へとつなげながら、ニュースの 1 段落の概要を提供することです。意味が通れば項目の順序を変更したり、重複を統合したりすることができます。
NPR デイリーニュースで読まれる、有機的に聞こえる 1 段落のスクリプトを出力します。スクリプトは音読で 5 分以内に収まる必要があります。
このコードでニューススクリプトを取得します:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)最終的なテキストはこちらです:
本日のテクノロジーニュースでは、様々な最新情報と進展についてお伝えします。まず、Tiny11 Builder ツールは、ユーザーが Windows 11 を最適化し、好みに合わせてカスタマイズされたイメージを作成できるようにします。ゲームの世界に目を向けると、スーパーファミコンのカートリッジの内部にある隠れたコンポーネントについて掘り下げ、90 年代のゲーマーを魅了したテクノロジーに光を当てます。ソフトウェアに話を移すと、Wayland 向けの Niri タイリングウィンドウマネージャーが無限スクロールや改良されたアニメーションなどの新機能を提供する大規模なアップデートをリリースしました。AI の分野では、Microsoft の Copilot 機能が Windows Insider へのロールアウトで問題に直面し、バグや干渉的な動作により展開が中断されています。一方、英国の情報コミッショナー事務局は、Google の Privacy Sandbox についてプライバシーへの影響と競争への影響に関する懸念を表明しています。最後に、米連邦航空局は、Varda Space Industries に関連する事故を受けて、打ち上げ許可要件を更新し、再突入機の打ち上げ前の許可取得を義務付けました。これらの多様なテクノロジー関連のストーリーは、テクノロジーの世界における進歩と課題を浮き彫りにしています。
tagニュースを音声で読み上げる
テキストを音声で読み上げるために、Google の TTS ライブラリを使用します。


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")これにより、最終的な音声ファイルが生成されます:
tag次のステップ
このポストでは、ポッドキャスト作成の残りの部分については触れません。それは私たちの専門分野ではありませんし、医学的アドバイスと同様に、ポッドキャストフィードのセットアップや Spotify、Apple Podcasts などへのアップロードなどの細かい部分については、私たちの意見を聞くべきではありません。医学やポッドキャストのアドバイスについては、それぞれ医師や Joe Rogan に相談してください。
Jina Reader のその他の機能については、任意のウェブページの読み取り可能なバージョンをダウンロードすることで作成できるRAGアプリケーションについて考えてみてください。また、PromptPerfect については、YouTuber(またはそれがお好みならマーケター)をどのように支援できるかをご覧ください。
