



2024年4月、私たちは Jina Reader を公開しました。これは URL のプレフィックスとして r.jina.ai を追加するだけで、任意のウェブページを LLM フレンドリーな markdown に変換する API です。2024年9月には、生の HTML をクリーンな markdown に変換するために特別に設計された2つの小規模言語モデル reader-lm-0.5b と reader-lm-1.5b をリリースしました。 本日、ReaderLM の第2世代をご紹介できることを嬉しく思います。これは 1.5B パラメータの言語モデルで、生の HTML を優れた精度で美しくフォーマットされた markdown や JSON に変換し、より長いコンテキストの処理が改善されています。ReaderLM-v2 は入出力の合計で最大 512K トークンを処理できます。このモデルは、英語、中国語、日本語、韓国語、フランス語、スペイン語、ポルトガル語、ドイツ語、イタリア語、ロシア語、ベトナム語、タイ語、アラビア語など、29の言語に対応したマルチリンガルサポートを提供します。
新しいトレーニングパラダイムとより高品質なトレーニングデータのおかげで、ReaderLM-v2 は前バージョンから大きく前進し、特に長文コンテンツと markdown 構文の生成において優れています。第1世代が HTML から markdown への変換を「選択的コピー」タスクとして扱っていたのに対し、v2 ではこれを真の翻訳プロセスとして扱います。この転換により、モデルは markdown 構文を巧みに活用し、コードフェンス、ネストされたリスト、テーブル、LaTex 方程式のような複雑な要素の生成に優れています。
ReaderLM v2、ReaderLM 1.5b、Claude 3.5 Sonnet、および Gemini 2.0 Flash による HackerNews フロントページの HTML から markdown への変換結果を比較すると、ReaderLM v2 の独自の特徴とパフォーマンスが明らかになります。ReaderLM v2 は、元の HackerNews のリンクを含む生の HTML からの包括的な情報を保持しながら、markdown 構文を使用してコンテンツをスマートに構造化することに優れています。モデルはネストされたリストを使用してローカル要素(ポイント、タイムスタンプ、コメント)を整理し、適切な見出し階層(h1 と h2 タグ)を通じて一貫したグローバルフォーマットを維持します。
第1バージョンの大きな課題は、長いシーケンスを生成した後の劣化で、特に繰り返しやループの形で現れていました。モデルは同じトークンを繰り返し始めるか、最大出力長に達するまで短いトークンシーケンスを循環するループに陥ってしまっていました。ReaderLM-v2 はトレーニング時に対照損失を追加することでこの問題を大幅に緩和しており、コンテキストの長さや既に生成されたトークン数に関係なく一貫したパフォーマンスを維持します。

markdown 変換に加えて、ReaderLM-v2 はHTML から JSON への直接生成を導入し、与えられた JSON スキーマに従って生の HTML から特定の情報を抽出することができます。このエンドツーエンドのアプローチにより、多くの LLM を利用したデータクリーニングと抽出パイプラインで一般的に必要とされる中間的な markdown 変換の必要性がなくなります。

定量的および定性的なベンチマークの両方において、ReaderLM-v2 は HTML から Markdown への変換タスクで Qwen2.5-32B-Instruct、Gemini2-flash-expr、GPT-4o-2024-08-06 などのはるかに大きなモデルを上回る性能を示し、HTML から JSON への抽出タスクでは同等の性能を示しています。これらはすべて、大幅に少ないパラメータ数で実現されています。

ReaderLM-v2-pro は、エンタープライズ顧客向けに追加のトレーニングと最適化を施した、プレミアム版のチェックポイントです。


これらの結果は、よく設計された 1.5B パラメータのモデルが、構造化データ抽出タスクにおいて、はるかに大きなモデルに匹敵し、しばしば上回る性能を発揮できることを示しています。ReaderLM-v2 から ReaderLM-v2-pro への段階的な改善は、計算効率を維持しながらモデルの性能を向上させる新しいトレーニング戦略の有効性を実証しています。
tag始めましょう
tagReader API を使用する

ReaderLM-v2 は現在、Reader API に統合されています。使用するには、リクエストヘッダーで x-engine: readerlm-v2 を指定し、-H 'Accept: text/event-stream' でレスポンスストリーミングを有効にするだけです:
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
API キーなしで低いレート制限で試すことができます。より高いレート制限のために、API キーを購入することができます。ReaderLM-v2 のリクエストは、API キーから通常のトークン数の 3 倍を消費することにご注意ください。この機能は現在ベータ版で、GPU の効率を最適化しモデルの可用性を向上させるため、GCP チームと協力して開発を進めています。
tagGoogle Colab での使用

無料の T4 GPU には制限があることにご注意ください。bfloat16 やフラッシュアテンション 2 をサポートしていないため、メモリ使用量が多くなり、長い入力の処理が遅くなります。それでも ReaderLM v2 は、これらの制約の下で法的文書のページ全体を正常に処理し、入力速度 67 トークン/秒、出力速度 36 トークン/秒を達成しています。本番環境での使用には、最適なパフォーマンスを得るために RTX 3090/4090 を推奨します。
ホスト環境で ReaderLM-v2 を試す最も簡単な方法は、Colab ノートブックを使用することです。このノートブックでは、HackerNews のフロントページを例に、HTML から Markdown への変換、JSON 抽出、指示に従った処理を実演しています。ノートブックは Colab の無料 T4 GPU 層向けに最適化されており、高速化と実行のために vllm と triton が必要です。任意のウェブサイトでテストしてみてください。
HTML から Markdown への変換
create_prompt ヘルパー関数を使用して、HTML から Markdown への変換用のプロンプトを簡単に作成できます:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result は Markdown のバッククォートでコードフェンスとして囲まれた文字列になります。デフォルトの設定を上書きして異なる出力を探ることもできます。例えば:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()ただし、トレーニングデータがすべての種類の指示、特に複数のステップでの推論を必要とするタスクをカバーしているわけではないため、最も信頼できる結果は HTML から Markdown への変換から得られます。最も効果的な情報抽出のために、以下のように JSON スキーマを使用することをお勧めします:
JSON スキーマを使用した HTML から JSON への抽出
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result は JSON 形式のコードフェンスバッククォートで囲まれた文字列であり、実際の JSON/dict オブジェクトではありません。Python を使用して、この文字列を適切な辞書または JSON オブジェクトにパースして、さらなる処理を行うことができます。
tag本番環境での使用:CSP で利用可能
ReaderLM-v2 は AWS SageMaker、Azure、GCP マーケットプレイスで利用可能です。これらのプラットフォーム以外や、社内でオンプレミスでこれらのモデルを使用する必要がある場合、このモデルと ReaderLM-v2-pro はいずれも CC BY-NC 4.0 ライセンスの下で提供されています。商用利用のお問い合わせや ReaderLM-v2-pro へのアクセスについては、お気軽にご連絡ください。

tag定量評価
私たちは ReaderLM-v2 を最先端のモデルである GPT-4o-2024-08-06、Gemini2-flash-expr、Qwen2.5-32B-Instruct と比較して、3つの構造化データ抽出タスクで評価しました。評価フレームワークは、コンテンツの正確性と構造的忠実性の両方を測定する指標を組み合わせています。ReaderLM-v2 は公開されているウェイトを持つ一般公開版で、ReaderLM-v2-pro は企業顧客向けの追加トレーニングと最適化を施した限定プレミアムチェックポイントです。なお、第一世代の reader-lm-1.5b は指示による抽出や JSON 抽出機能をサポートしていないため、メインコンテンツ抽出タスクでのみ評価しています。
tag評価指標
HTML から Markdown へのタスクでは、7つの補完的な指標を採用しています。注:↑は高いほど良い、↓は低いほど良いことを示します
- ROUGE-L (↑):生成されたテキストと参照テキスト間の最長共通部分列を測定し、コンテンツの保持と構造的類似性を捕捉します。範囲:0-1、値が高いほどシーケンスの一致が良好です。
- WER(単語誤り率) (↓):生成されたテキストを参照テキストに変換するために必要な単語レベルの編集の最小数を定量化します。値が低いほど必要な修正が少ないことを示します。
- SUB(置換) (↓):必要な単語の置換数をカウントします。値が低いほど単語レベルの精度が高いことを示します。
- INS(挿入) (↓):参照と一致させるために挿入が必要な単語数を測定します。値が低いほど完全性が高いことを示します。
- レーベンシュタイン距離 (↓):必要な文字レベルの編集の最小数を計算します。値が低いほど文字レベルの精度が高いことを示します。
- ダメラウ・レーベンシュタイン距離 (↓):レーベンシュタインに似ていますが、文字の転置も考慮します。値が低いほど文字レベルの一致が良好です。
- ジャロ・ウィンクラー類似度 (↑):文字列の先頭部分での一致を重視し、文書構造の保持の評価に特に有用です。範囲:0-1、値が高いほど類似性が高いことを示します。
HTML から JSON へのタスクでは、情報検索の4つの指標を採用しています:
- F1 スコア (↑):精度と再現率の調和平均で、全体的な正確性を示します。範囲:0-1。
- 精度 (↑):すべての抽出の中で正しく抽出された情報の割合。範囲:0-1。
- 再現率 (↑):利用可能なすべての情報から正しく抽出された情報の割合。範囲:0-1。
- パス率 (↑):有効な JSON でスキーマに準拠している出力の割合。範囲:0-1。
tagメインコンテンツ HTML から Markdown へのタスク
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tag指示付き HTML から Markdown へのタスク
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagスキーマベースの HTML から JSON へのタスク
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 はすべてのタスクにおいて大きな進歩を示しています。メインコンテンツ抽出では、ReaderLM-v2-pro が7つの指標のうち5つで最高のパフォーマンスを達成し、ROUGE-L(0.86)、WER(0.39)、レーベンシュタイン(0.20)、ダメラウ(928.15)、ジャロ・ウィンクラー(0.83)のスコアで優れています。これらの結果は、基本バージョンやより大規模なモデルと比較して、コンテンツの保持と構造的正確性の両方において包括的な改善を示しています。
指示付き抽出では、ReaderLM-v2 と ReaderLM-v2-pro が ROUGE-L(0.72)、置換率(70.16)、レーベンシュタイン距離(0.37)、ジャロ・ウィンクラー類似度(0.75、基本バージョンと同点)でリードしています。GPT-4o が WER とダメラウ距離で優位性を示している一方、ReaderLM-v2-pro はより良い全体的なコンテンツ構造と正確性を維持しています。JSON 抽出では、モデルは競争力のあるパフォーマンスを示し、より大規模なモデルとの F1 スコアの差が 0.01-0.02 ポイント内に収まり、高いパス率(0.99)を達成しています。
tag定性評価
分析中にreader-lm-1.5b では、定量的な指標だけではモデルのパフォーマンスを完全に把握できないことがわかりました。数値的な評価は、低いスコアでも視覚的に満足できる Markdown を生成したり、高いスコアでも最適とは言えない結果を生成したりするなど、知覚品質を正確に反映していないことがありました。この不一致に対処するため、英語、日本語、中国語のニュース記事、ブログ投稿、商品ページ、EC サイト、法的文書など、10 種類の多様な HTML ソースで体系的な質的評価を実施しました。このテストコーパスでは、複数行のテーブル、動的レイアウト、LaTeX 数式、リンク付きテーブル、ネストされたリストなどの難しいフォーマット要素に焦点を当て、実世界でのモデルの能力をより包括的に把握しました。
tag評価指標
人による評価では、3 つの主要な次元に焦点を当て、出力を 1-5 のスケールで評価しました:
コンテンツの完全性 - HTML から Markdown への変換における意味的情報の保持を評価:
- テキストコンテンツの正確性と完全性
- リンク、画像、コードブロック、数式、引用の保持
- テキストフォーマットとリンク/画像 URL の保持
構造的正確性 - HTML 構造要素の Markdown への正確な変換を評価:
- 見出し階層の保持
- リストのネストの正確性
- テーブル構造の忠実性
- コードブロックと引用のフォーマット
フォーマットの準拠性 - Markdown 構文標準への準拠度を測定:
- 見出し (#)、リスト (*, +, -)、テーブル、コードブロック (```) の適切な構文使用
- 余分な空白や非標準的な構文のない整理されたフォーマット
- 一貫性があり読みやすいレンダリング結果
10 ページの HTML を手動で評価し、各評価基準の最高点は 50 点です。ReaderLM-v2 はすべての次元で優れたパフォーマンスを示しました:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
コンテンツの完全性に関しては、LaTeX 数式、ネストされたリスト、コードブロックなど、複雑な要素の認識に優れていました。競合モデルが H1 ヘッダーを削除したり(reader-lm-1.5b)、コンテンツを切り詰めたり(Claude 3.5)、生の HTML タグを残したり(Gemini-2.0-flash)する中、このモデルは複雑なコンテンツ構造を高い忠実度で維持しました。
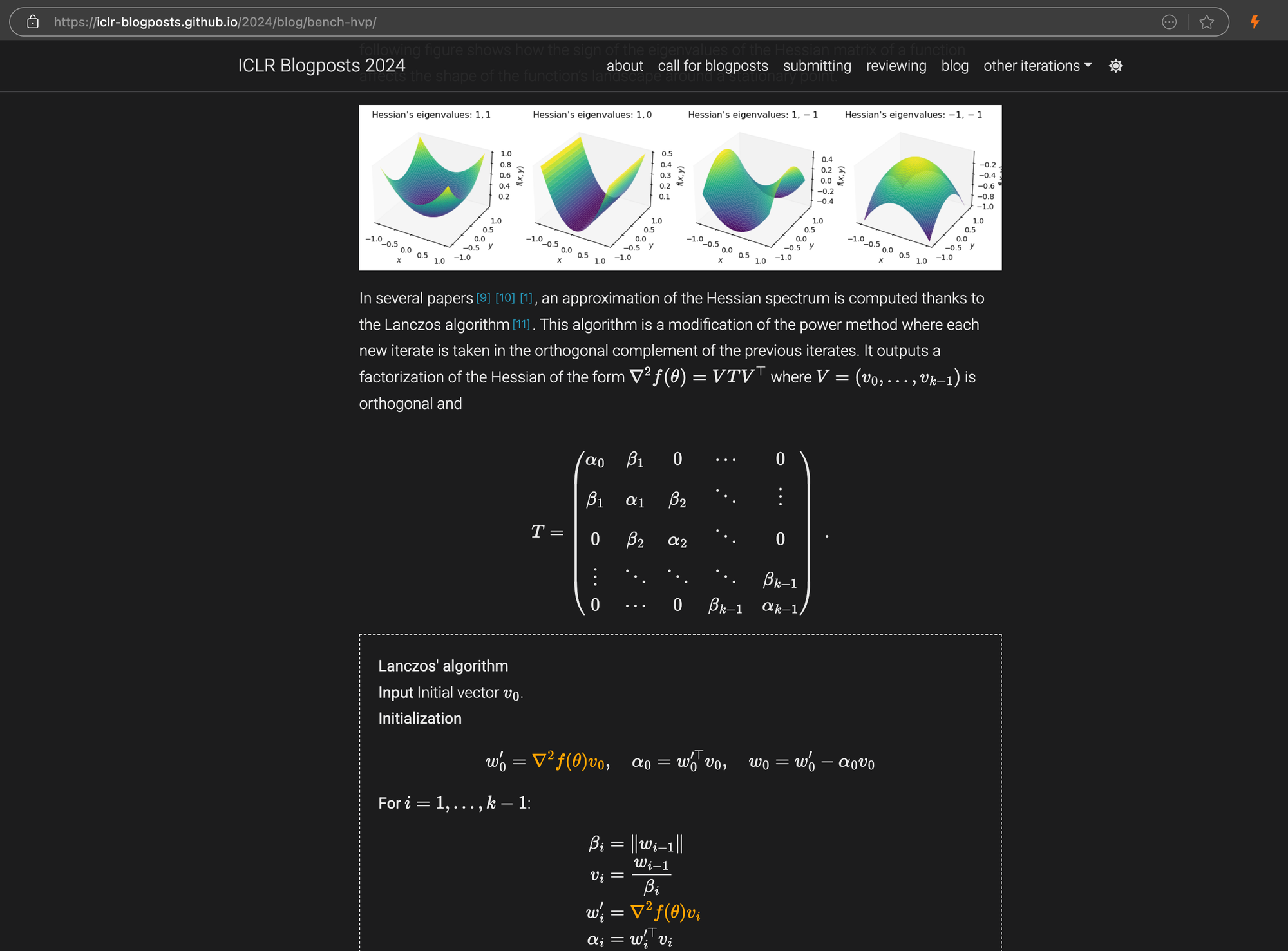
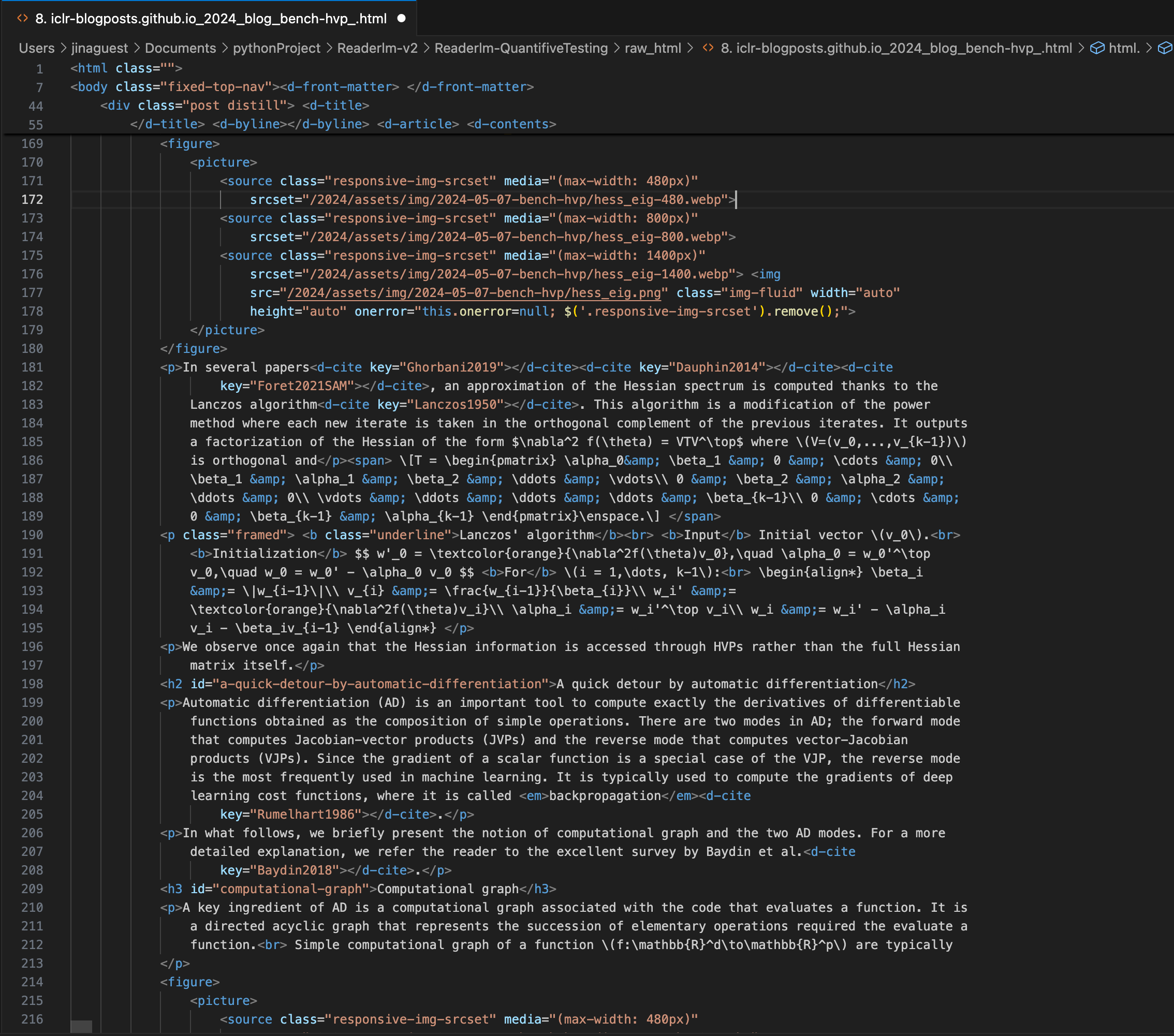
ICLR のブログ投稿。複雑な LaTeX 数式が Markdown に埋め込まれており、右パネルにソース HTML コードが表示されています。
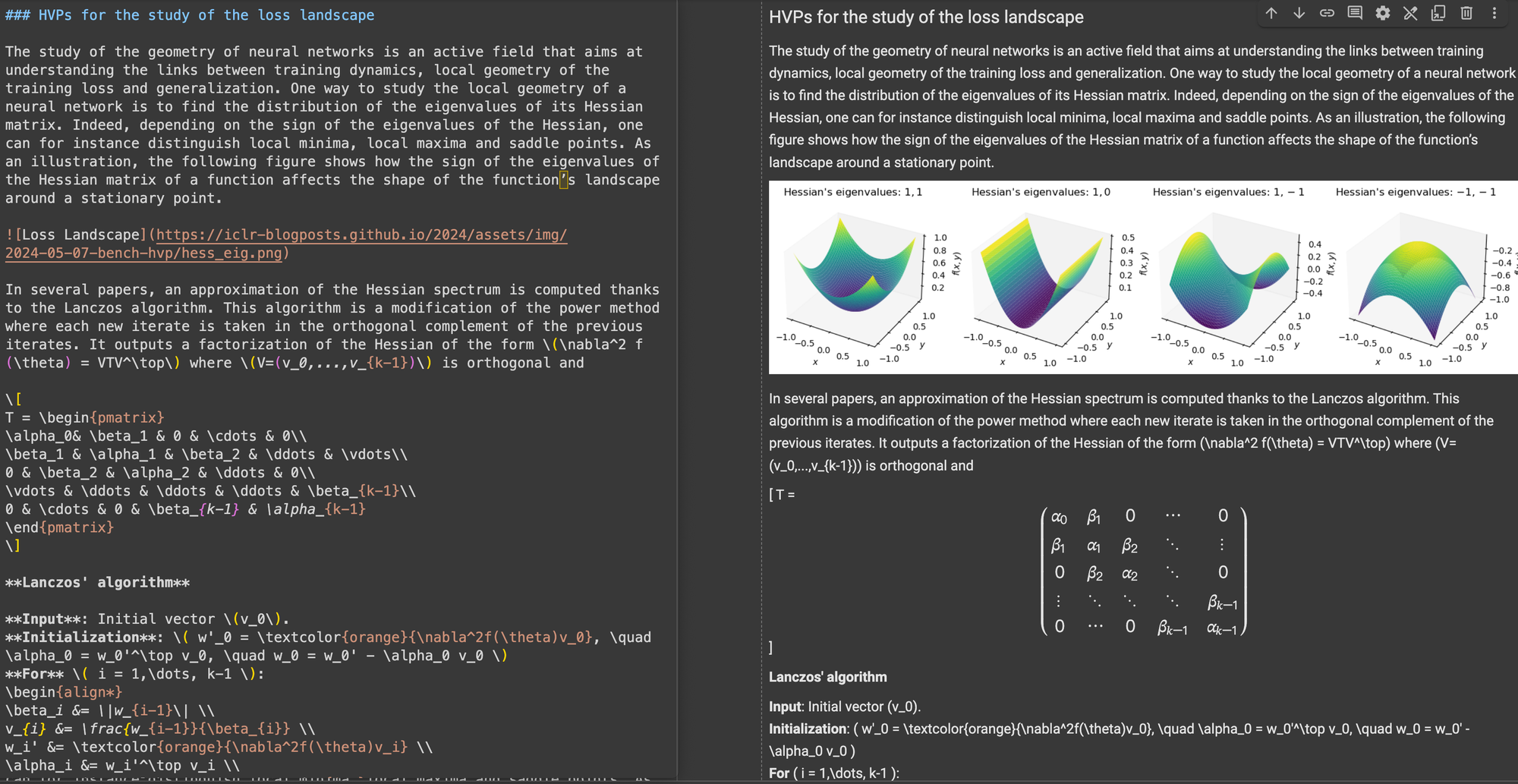
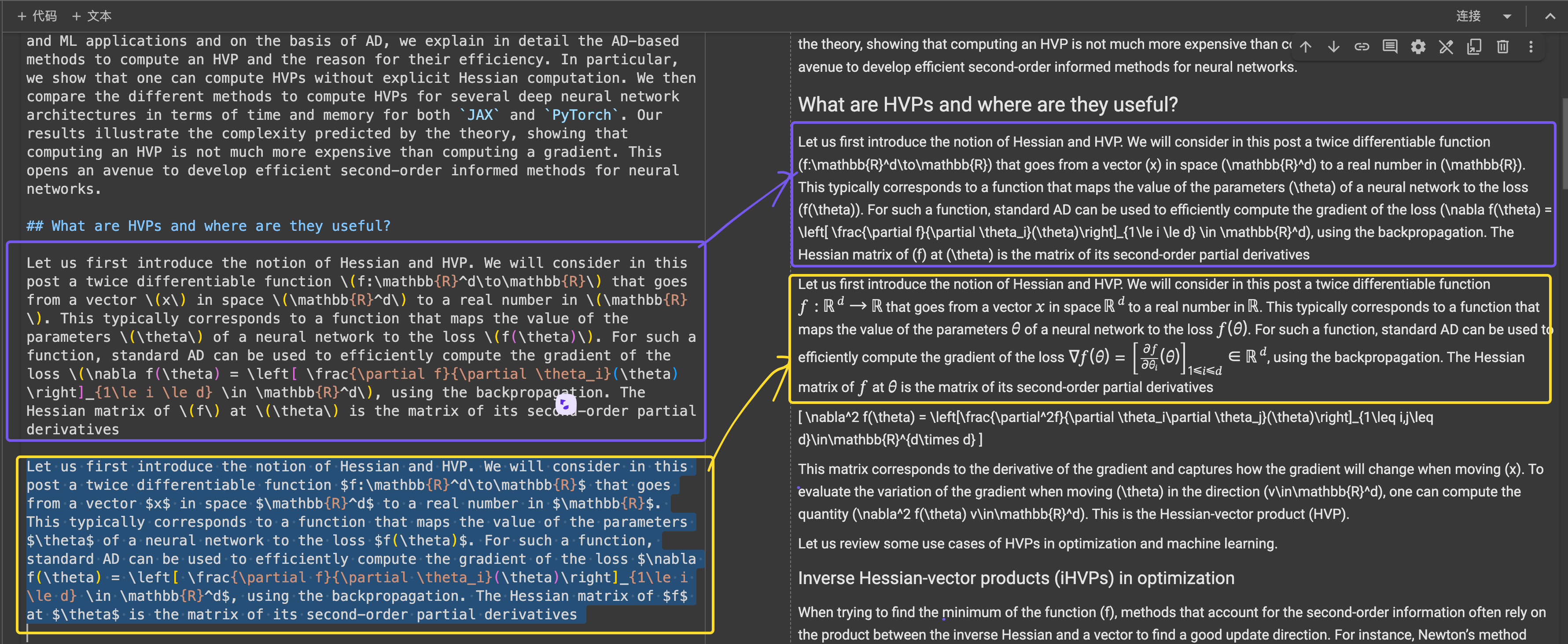
\[...\](およびその HTML 相当)を、インライン数式用の $...$ や表示数式用の $$...$$ など、Markdown 標準の区切り文字に置き換えます。これにより、Markdown の解釈での構文の競合を防ぐことができます。構造的正確性に関して、ReaderLM-v2 は一般的な Web 構造に最適化されていることを示しました。例えば、Hacker News のケースでは、完全なリンクの再構築とリスト表示の最適化に成功しました。このモデルは、ReaderLM-v1 が苦労した複雑な非ブログ HTML 構造も処理できました。
フォーマットの準拠性に関して、ReaderLM-v2 は特に Hacker News、ブログ、WeChat 記事などのコンテンツの処理に強みを示しました。他の大規模言語モデルは Markdown に似たソースでは良好なパフォーマンスを示しましたが、より多くの解釈と再フォーマットを必要とする従来の Web サイトでは苦労していました。
分析によると、gpt-4o は短い Web サイトの処理に優れており、他のモデルと比較してサイトの構造とフォーマットの理解が優れていることが示されました。しかし、より長いコンテンツを処理する場合、gpt-4o は完全性に課題があり、しばしばテキストの冒頭と末尾の部分が省略されます。Zillow の Web サイトを例として、gpt-4o、ReaderLM-v2、ReaderLM-v2-pro の出力の比較分析を含めました。
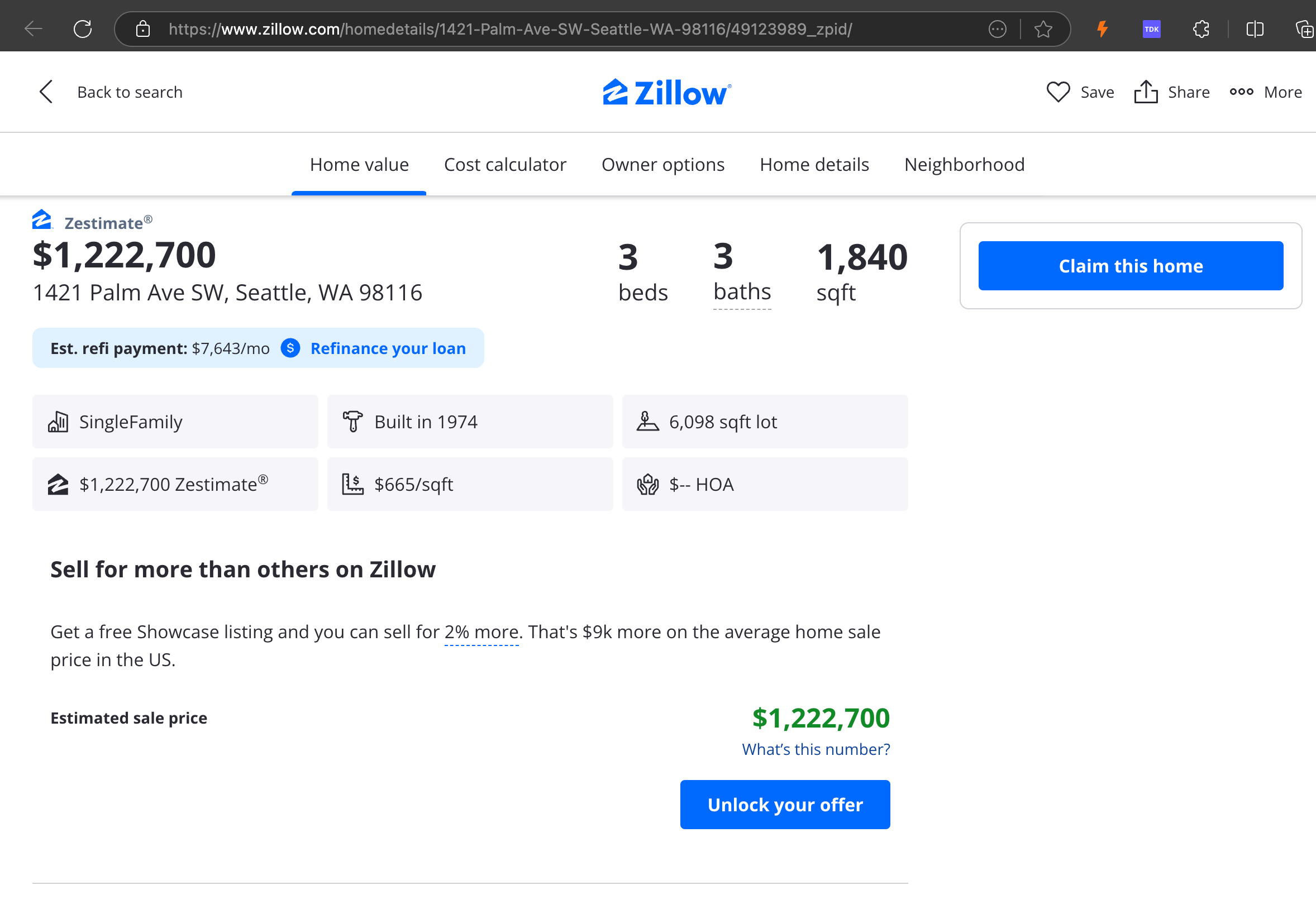
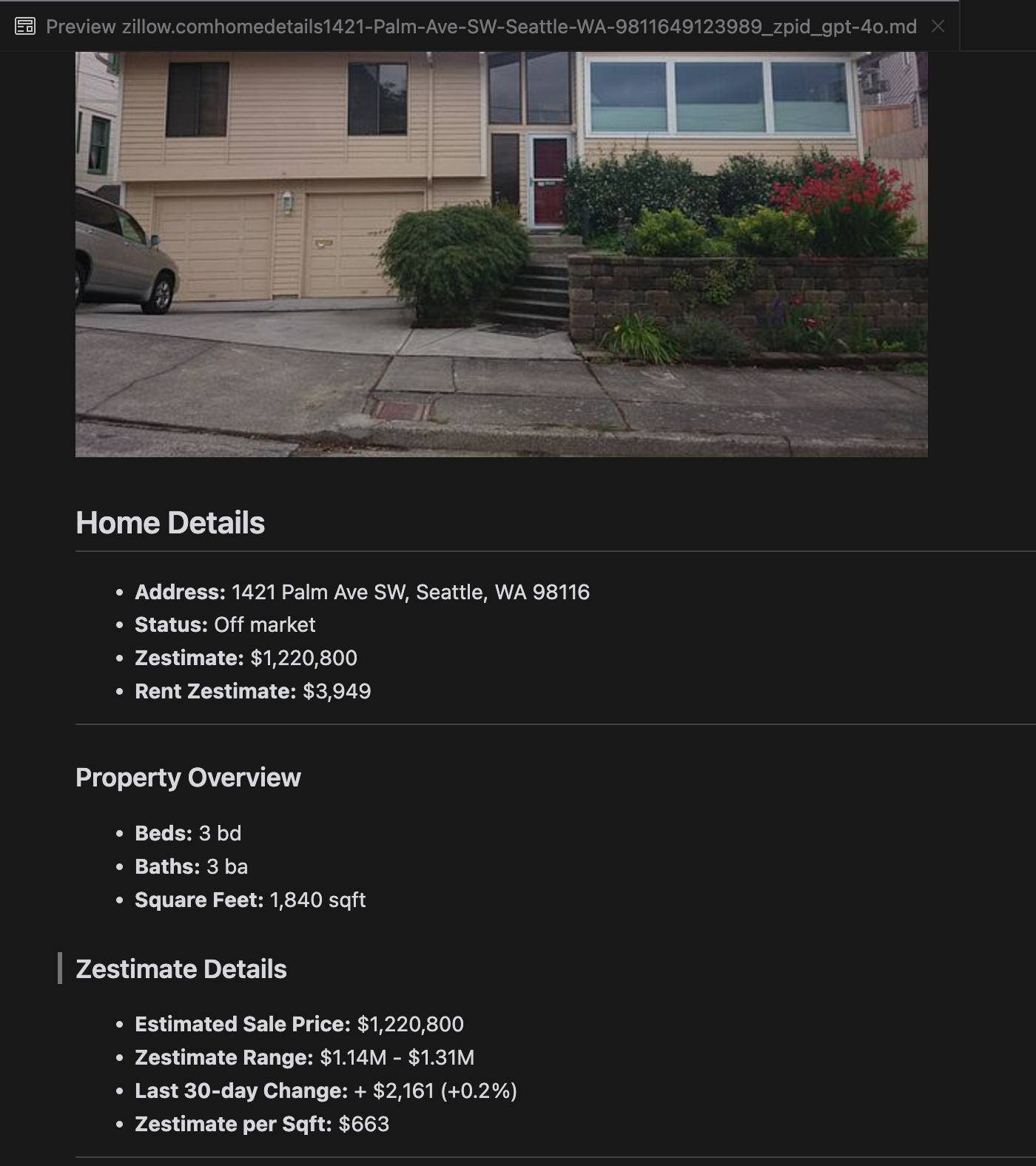
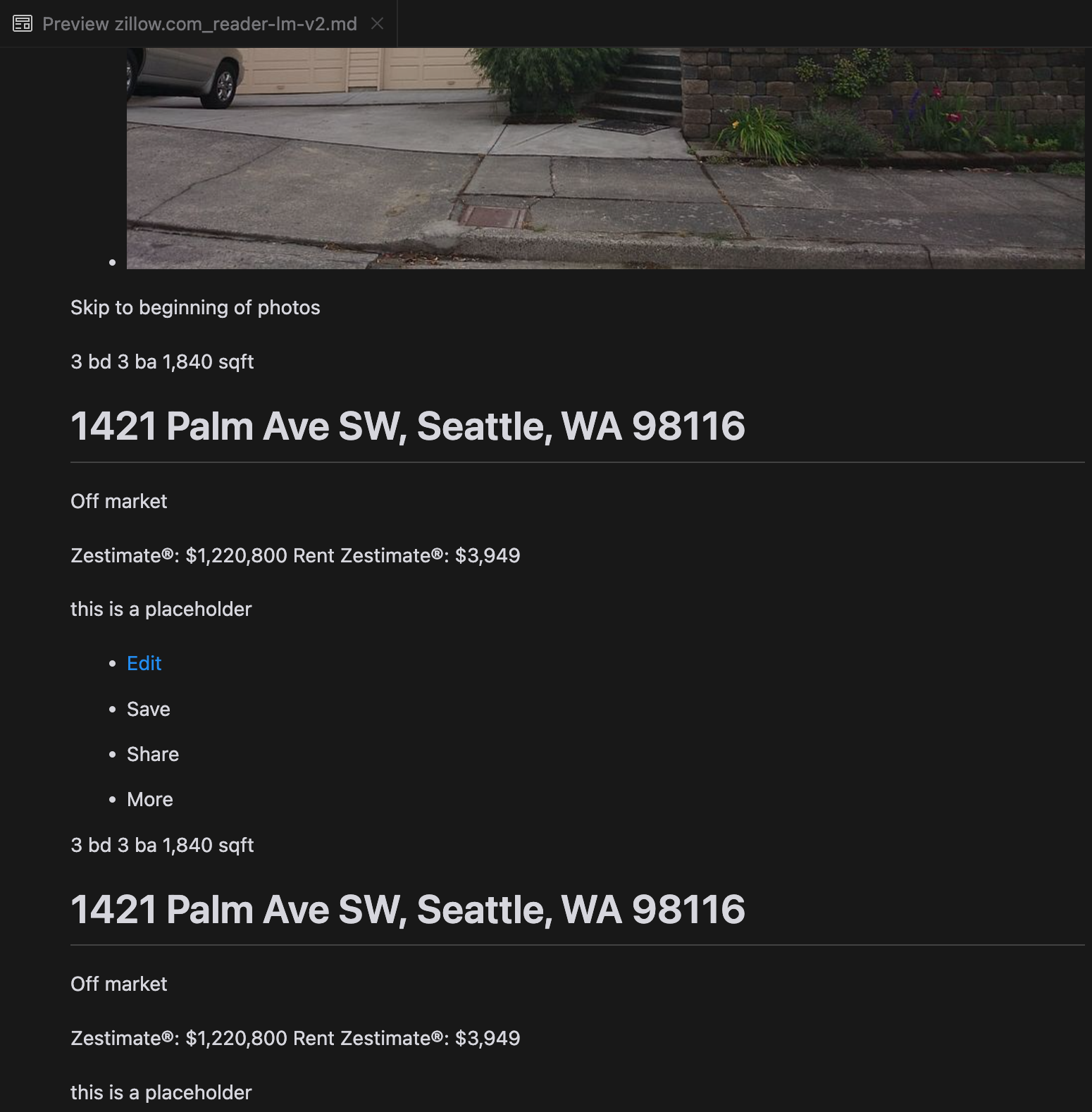
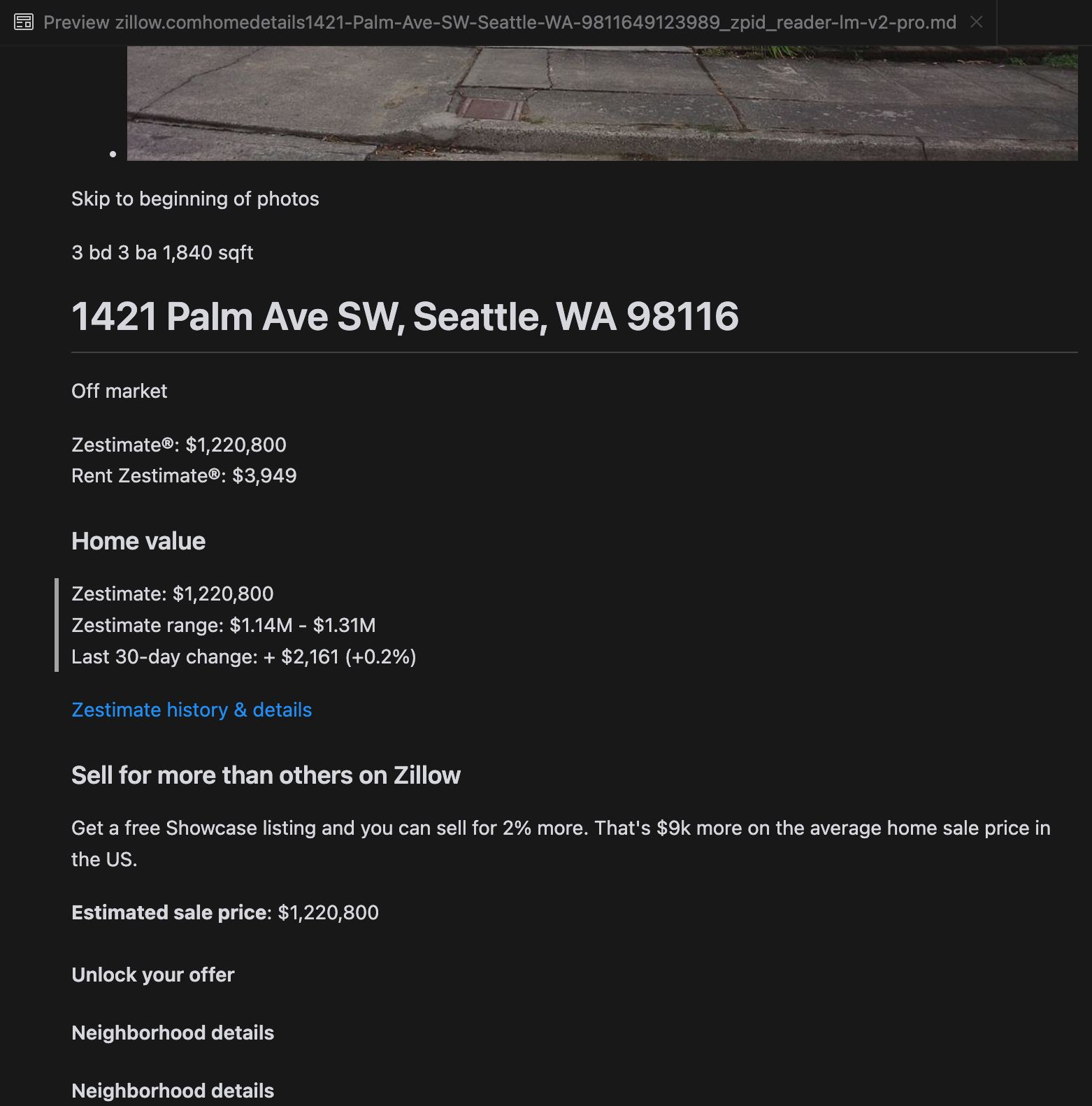
gpt-4o(左)、ReaderLM-v2(中央)、ReaderLM-v2-pro(右)のMarkdown出力の比較。
製品のランディングページや政府文書などの課題の多いケースでは、ReaderLM-v2 と ReaderLM-v2-pro のパフォーマンスは安定していましたが、まだ改善の余地があります。ICLR のブログ投稿にある複雑な数式やコードは、ほとんどのモデルにとって課題となりましたが、ReaderLM-v2 はベースラインの Reader API よりもこれらのケースをより適切に処理しました。
tagReaderLM v2 のトレーニング方法
ReaderLM-v2 は、指示に従う能力と長文脈タスクの効率性で知られるコンパクトなベースモデル Qwen2.5-1.5B-Instruction をベースに構築されています。このセクションでは、データ準備、トレーニング手法、直面した課題に焦点を当てながら、ReaderLM-v2 のトレーニング方法について説明します。
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagデータ準備
ReaderLM-v2 の成功は、主にトレーニングデータの質に依存していました。インターネットから収集した 100 万件の HTML ドキュメントを含む html-markdown-1m データセットを作成しました。各ドキュメントは平均して 56,000 トークンを含み、実世界のウェブデータの長さと複雑さを反映しています。このデータセットを準備するために、主要な構造的・意味的要素を保持しながら、JavaScript や CSS などの不要な要素を削除して HTML ファイルをクリーニングしました。クリーニング後、Jina Reader を使用して、正規表現パターンとヒューリスティックを用いて HTML ファイルを Markdown に変換しました。
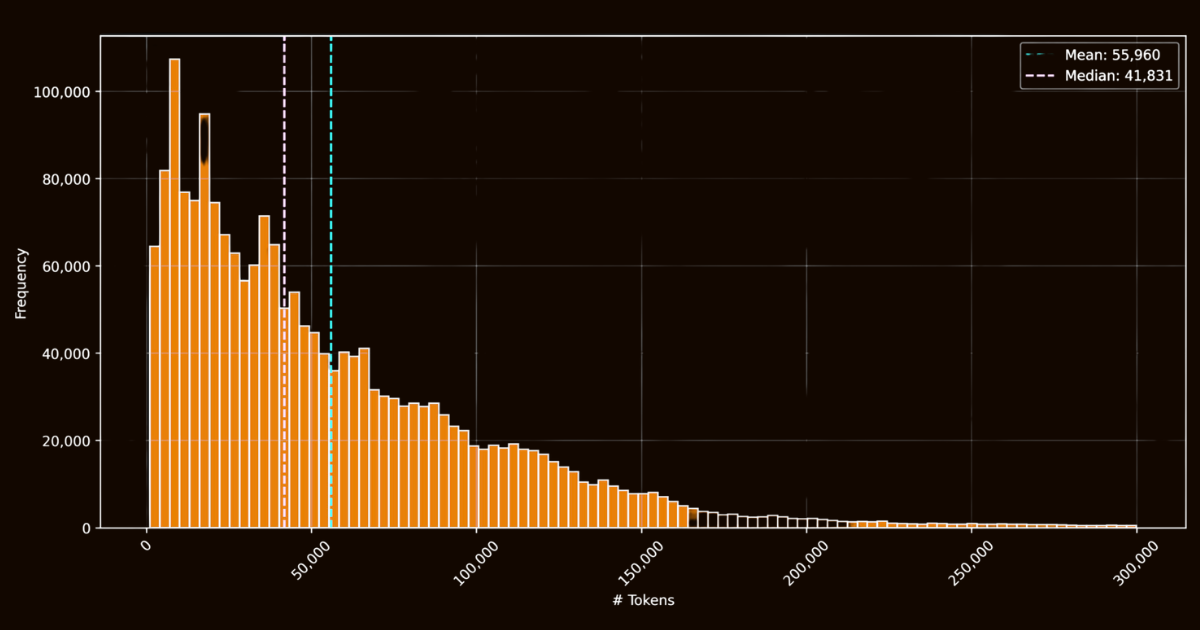
html-markdown-1m データセットにおける HTML ファイルのトークン長ヒストグラムこれは機能的なベースラインデータセットを作成しましたが、重要な制限を浮き彫りにしました:これらの直接変換のみでトレーニングされたモデルは、本質的に Jina Reader が使用する正規表現パターンとヒューリスティックを模倣することを学ぶだけでした。これは reader-lm-0.5b/1.5b で明らかになり、そのパフォーマンスの上限はルールベースの変換の質に制約されていました。
これらの制限に対処するため、高品質な合成データセットを作成するために不可欠な Qwen2.5-32B-Instruction モデルを利用した 3 ステップのパイプラインを開発しました。

Qwen2.5-32B-Instruction によって強化された ReaderLM-v2 の合成データ生成パイプライン- ドラフト作成:モデルに提供された指示に基づいて、初期の Markdown と JSON 出力を生成しました。これらの出力は多様でしたが、しばしばノイズが多かったり一貫性に欠けていました。
- 改良:生成されたドラフトは、冗長なコンテンツを削除し、構造的一貫性を強制し、望ましい形式に整合させることで改善されました。このステップにより、データがクリーンで、タスクの要件に合致していることを確保しました。
- 批評:改良された出力を元の指示に対して評価しました。この評価に合格したデータのみが最終的なデータセットに含まれました。この反復的なアプローチにより、トレーニングデータが構造化データ抽出に必要な品質基準を満たすことを確保しました。
tagトレーニングプロセス
トレーニングプロセスは、長文脈ドキュメントの処理の課題に合わせて調整された複数のステージを含みました。
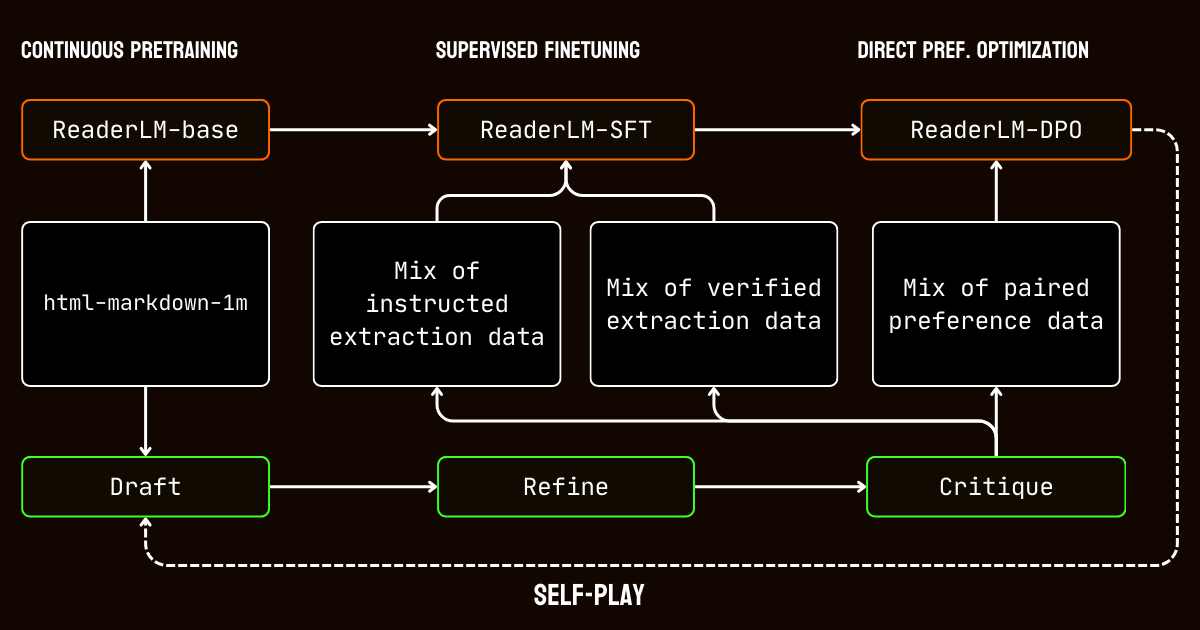
html-markdown-1m データセットを使用した長文脈事前学習から始めました。ring-zag attention や rotary positional encoding(RoPE)などの技術を使用して、モデルの文脈長を 32,768 トークンから 256,000 トークンまで段階的に拡張しました。安定性と効率性を維持するために、より短いシーケンスから始めて文脈長を徐々に増やす段階的なトレーニングアプローチを採用しました。
事前学習の後、教師付き微調整(SFT)に移行しました。このステージでは、データ準備プロセスで生成された改良データセットを使用しました。これらのデータセットには、Markdown と JSON 抽出タスクの詳細な指示、およびドラフトを改良するための例が含まれていました。各データセットは、メインコンテンツの識別やスキーマベースの JSON 構造への準拠など、特定のタスクをモデルが学習できるように慎重に設計されました。
次に、直接選好最適化(DPO)を適用して、モデルの出力を高品質な結果と整合させました。このフェーズでは、ドラフトと改良された応答のペアでモデルをトレーニングしました。改良された出力を優先することを学ぶことで、モデルは洗練されたタスク固有の結果を定義する微妙な違いを内在化しました。
最後に、セルフプレイ強化調整を実装しました。これは、モデルが自身の出力を生成、改良、評価する反復プロセスです。このサイクルにより、追加の外部監督を必要とせずにモデルが継続的に改善することが可能になりました。自身の批評と改良を活用することで、モデルは正確で構造化された出力を生成する能力を徐々に向上させました。
tag結論
2024 年 4 月、Jina Reader は LLM フレンドリーな最初の markdown API となりました。新しいトレンドを確立し、コミュニティで広く採用され、最も重要なことに、データクリーニングと抽出のための小規模言語モデルの構築へと私たちを導きました。今日、私たちは ReaderLM-v2 で再び基準を引き上げ、昨年 9 月に約束した内容を実現しています:より優れた長文脈処理、入力指示のサポート、そして特定のウェブページコンテンツを markdown 形式に抽出する能力です。再び、私たちは慎重なトレーニングとキャリブレーションにより、小規模言語モデルがより大きなモデルを凌駕する最先端のパフォーマンスを達成できることを実証しました。
ReaderLM-v2 のトレーニングプロセスを通じて、2 つの洞察を得ました。1 つの効果的な戦略は、特定のタスクに合わせて調整された別々のデータセットで専門化したモデルをトレーニングすることでした。これらのタスク固有のモデルは、後に線形パラメータ補間を使用してマージされました。このアプローチは追加の労力を必要としましたが、最終的な統合システムにおいて各専門化モデルの独自の強みを保持するのに役立ちました。
反復的なデータ合成プロセスは、モデルの成功に極めて重要でした。合成データの繰り返しの改良と評価を通じて、単純なルールベースのアプローチを大きく超えるモデルパフォーマンスを実現しました。この反復戦略は、一貫した評価基準の維持や計算コストの管理において課題がありましたが、Jina Reader の正規表現やヒューリスティックベースの学習データの限界を超えるために不可欠でした。これは、Jina Reader のルールベース変換に大きく依存する reader-lm-1.5b と、この反復的な改良プロセスの恩恵を受けた ReaderLM-v2 との間のパフォーマンスの差に明確に表れています。
ReaderLM-v2 がどのようにデータ品質を改善したのか、皆様のフィードバックをお待ちしています。今後は、特にスキャンされた文書に対するマルチモーダル機能の拡張や、生成速度のさらなる最適化を計画しています。特定のドメインに合わせてカスタマイズされた ReaderLM に興味がある場合は、ぜひお問い合わせください。
