


2024년 4월, 우리는 Jina Reader를 출시했습니다. 이는 URL 앞에 r.jina.ai를 추가하는 것만으로 모든 웹페이지를 LLM 친화적인 마크다운으로 변환하는 API입니다. 2024년 9월에는 raw HTML을 깔끔한 마크다운으로 변환하도록 특별히 설계된 두 개의 작은 언어 모델인 reader-lm-0.5b와 reader-lm-1.5b를 출시했습니다. 오늘, 우리는 ReaderLM의 두 번째 세대를 소개하게 되어 기쁩니다. 이는 raw HTML을 아름답게 포맷된 마크다운이나 JSON으로 더 높은 정확도와 향상된 긴 컨텍스트 처리 능력으로 변환하는 1.5B 파라미터 언어 모델입니다. ReaderLM-v2는 입력과 출력을 합쳐 최대 512K 토큰을 처리할 수 있습니다. 이 모델은 영어, 중국어, 일본어, 한국어, 프랑스어, 스페인어, 포르투갈어, 독일어, 이탈리아어, 러시아어, 베트남어, 태국어, 아랍어 등 29개 언어에 대한 다국어 지원을 제공합니다.
새로운 학습 패러다임과 더 높은 품질의 학습 데이터 덕분에, ReaderLM-v2는 특히 장문 컨텐츠 처리와 마크다운 구문 생성에서 전작보다 큰 발전을 이루었습니다. 첫 번째 세대가 HTML-to-markdown 변환을 "선택적 복사" 작업으로 접근했다면, v2는 이를 진정한 번역 과정으로 다룹니다. 이러한 변화로 모델은 마크다운 구문을 능숙하게 활용할 수 있게 되었고, 코드 펜스, 중첩 리스트, 표, LaTex 방정식과 같은 복잡한 요소들을 생성하는 데 탁월한 성능을 보입니다.
ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet, Gemini 2.0 Flash의 HackerNews 프론트 페이지 HTML-to-markdown 결과를 비교하면 ReaderLM v2의 독특한 특성과 성능이 드러납니다. ReaderLM v2는 원본 HackerNews 링크를 포함한 raw HTML의 포괄적인 정보를 보존하면서도 마크다운 구문을 사용하여 컨텐츠를 스마트하게 구조화합니다. 이 모델은 중첩 리스트를 사용하여 로컬 요소(포인트, 타임스탬프, 댓글)를 구성하면서도 적절한 제목 계층(h1과 h2 태그)을 통해 전체적인 포맷팅 일관성을 유지합니다.
우리의 첫 번째 버전에서 주요 과제는 긴 시퀀스를 생성한 후의 퇴화였습니다. 특히 반복과 루프 형태로 나타났습니다. 모델이 동일한 토큰을 반복하거나 최대 출력 길이에 도달할 때까지 짧은 토큰 시퀀스를 순환하며 루프에 빠지곤 했습니다. ReaderLM-v2는 학습 중에 대조 손실을 추가함으로써 이 문제를 크게 완화했습니다—컨텍스트 길이나 이미 생성된 토큰의 양에 관계없이 일관된 성능을 유지합니다.

마크다운 변환을 넘어서, ReaderLM-v2는 직접적인 HTML-to-JSON 생성을 도입하여 사용자가 주어진 JSON 스키마에 따라 raw HTML에서 특정 정보를 추출할 수 있게 합니다. 이러한 엔드투엔드 접근 방식은 많은 LLM 기반 데이터 정제 및 추출 파이프라인에서 일반적으로 필요한 중간 마크다운 변환 과정을 제거합니다.

정량적 및 정성적 벤치마크 모두에서 ReaderLM-v2는 Qwen2.5-32B-Instruct, Gemini2-flash-expr, GPT-4o-2024-08-06와 같은 훨씬 더 큰 모델들보다 HTML-to-Markdown 작업에서 더 나은 성능을 보여주며, HTML-to-JSON 추출 작업에서는 비슷한 성능을 보여주면서도 훨씬 적은 파라미터를 사용합니다.

ReaderLM-v2-pro는 추가 학습과 최적화가 포함된 엔터프라이즈 고객 전용 프리미엄 체크포인트입니다.


이러한 결과는 잘 설계된 1.5B 파라미터 모델이 구조화된 데이터 추출 작업에서 훨씬 더 큰 모델들의 성능과 비교하여 일치하거나 종종 초과할 수 있다는 것을 입증합니다. ReaderLM-v2에서 ReaderLM-v2-pro로의 점진적인 개선은 계산 효율성을 유지하면서 모델 성능을 향상시키는 새로운 학습 전략의 효과를 보여줍니다.
tag시작하기
tagReader API를 통해

ReaderLM-v2는 현재 Reader API와 통합되어 있습니다. 사용하려면 요청 헤더에 x-engine: readerlm-v2를 지정하고 -H 'Accept: text/event-stream'으로 응답 스트리밍을 활성화하면 됩니다:
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
낮은 속도 제한으로 API 키 없이 시도해볼 수 있습니다. 더 높은 속도 제한을 위해서는 API 키를 구매할 수 있습니다. ReaderLM-v2 요청은 API 키에서 일반 토큰 수의 3배를 소비한다는 점에 유의하세요. 이 기능은 현재 베타 버전이며, GPU 효율성을 최적화하고 모델 가용성을 높이기 위해 GCP 팀과 협력하고 있습니다.
tagGoogle Colab에서

무료 T4 GPU에는 제한사항이 있습니다—bfloat16이나 flash attention 2를 지원하지 않아 메모리 사용량이 더 높고 긴 입력 처리가 더 느립니다. 그럼에도 불구하고 ReaderLM v2는 이러한 제약 조건에서도 전체 법률 페이지를 성공적으로 처리하며, 입력 67 토큰/초, 출력 36 토큰/초의 처리 속도를 달성합니다. 프로덕션 사용을 위해서는 최적의 성능을 위해 RTX 3090/4090을 추천합니다.
호스팅 환경에서 ReaderLM-v2를 시도해볼 수 있는 가장 간단한 방법은 Colab 노트북을 통해서입니다. 이 노트북은 HackerNews 프론트페이지를 예시로 사용하여 HTML-to-markdown 변환, JSON 추출, 지시사항 따르기를 보여줍니다. 이 노트북은 Colab의 무료 T4 GPU 티어에 최적화되어 있으며, 가속화와 실행을 위해 vllm과 triton이 필요합니다. 어떤 웹사이트로든 자유롭게 테스트해보세요.
HTML을 Markdown으로 변환
HTML을 Markdown으로 변환하기 위한 프롬프트를 쉽게 생성하기 위해 create_prompt 헬퍼 함수를 사용할 수 있습니다:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result는 Markdown 백틱으로 코드 펜스가 씌워진 문자열이 됩니다. 다른 출력을 탐색하기 위해 기본 설정을 다음과 같이 재정의할 수도 있습니다:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()하지만 우리의 학습 데이터가 특히 다단계 추론이 필요한 작업과 같은 모든 유형의 지시사항을 다루지 않을 수 있으므로, 가장 신뢰할 수 있는 결과는 HTML-to-Markdown 변환에서 얻을 수 있습니다. 가장 효과적인 정보 추출을 위해서는 아래와 같이 JSON 스키마를 사용하는 것을 추천합니다:
JSON 스키마를 사용한 HTML에서 JSON 추출
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result는 실제 JSON/dict 객체가 아닌 JSON 형식의 코드 펜스 백틱으로 감싸진 문자열이 됩니다. Python을 사용하여 이 문자열을 추가 처리를 위한 적절한 딕셔너리나 JSON 객체로 파싱할 수 있습니다.
tag프로덕션에서: CSP에서 사용 가능
ReaderLM-v2는 AWS SageMaker, Azure 및 GCP 마켓플레이스에서 사용할 수 있습니다. 이러한 플랫폼을 넘어서거나 회사 내부에서 온프레미스로 이 모델을 사용해야 하는 경우, 이 모델과 ReaderLM-v2-pro는 모두 CC BY-NC 4.0 라이선스 하에 있습니다. 상업적 사용 문의나 ReaderLM-v2-pro 접근에 대해서는 언제든 문의해주세요.

tag정량적 평가
ReaderLM-v2를 최신 모델들과 비교하여 세 가지 구조화된 데이터 추출 작업에서 평가했습니다: GPT-4o-2024-08-06, Gemini2-flash-expr, Qwen2.5-32B-Instruct. 평가 프레임워크는 콘텐츠 정확도와 구조적 충실도를 모두 측정하는 메트릭을 결합했습니다. ReaderLM-v2는 공개된 가중치를 가진 공개 버전이며, ReaderLM-v2-pro는 추가 학습과 최적화가 포함된 기업 고객 전용 프리미엄 체크포인트입니다. 첫 번째 세대인 reader-lm-1.5b는 지시 추출이나 JSON 추출 기능을 지원하지 않기 때문에 주요 콘텐츠 추출 작업에서만 평가되었습니다.
tag평가 메트릭
HTML-to-Markdown 작업에는 7가지 보완적 메트릭을 사용합니다. 참고: ↑는 높을수록 좋음, ↓는 낮을수록 좋음을 의미
- ROUGE-L (↑): 생성된 텍스트와 참조 텍스트 간의 가장 긴 공통 부분 수열을 측정하여 콘텐츠 보존과 구조적 유사성을 포착합니다. 범위: 0-1, 높은 값이 더 나은 시퀀스 매칭을 나타냅니다.
- WER (단어 오류율) (↓): 생성된 텍스트를 참조로 변환하는 데 필요한 최소 단어 수준 편집 수를 정량화합니다. 낮은 값은 더 적은 수정이 필요함을 나타냅니다.
- SUB (대체) (↓): 필요한 단어 대체 수를 계산합니다. 낮은 값은 더 나은 단어 수준 정확도를 나타냅니다.
- INS (삽입) (↓): 참조와 일치하기 위해 삽입해야 하는 단어 수를 측정합니다. 낮은 값은 더 나은 완성도를 나타냅니다.
- Levenshtein Distance (↓): 필요한 최소 단일 문자 편집 수를 계산합니다. 낮은 값은 더 나은 문자 수준 정확도를 나타냅니다.
- Damerau-Levenshtein Distance (↓): Levenshtein과 유사하지만 문자 전위도 고려합니다. 낮은 값은 더 나은 문자 수준 매칭을 나타냅니다.
- Jaro-Winkler Similarity (↑): 문자열 시작 부분의 일치하는 문자를 강조하며, 문서 구조 보존 평가에 특히 유용합니다. 범위: 0-1, 높은 값이 더 나은 유사성을 나타냅니다.
HTML-to-JSON 작업의 경우, 정보 검색 작업으로 간주하고 정보 검색에서 4가지 메트릭을 채택합니다:
- F1 Score (↑): 정밀도와 재현율의 조화 평균으로 전반적인 정확도를 제공합니다. 범위: 0-1.
- Precision (↑): 모든 추출 중 올바르게 추출된 정보의 비율. 범위: 0-1.
- Recall (↑): 사용 가능한 모든 정보 중 올바르게 추출된 정보의 비율. 범위: 0-1.
- Pass-Rate (↑): 유효한 JSON이며 스키마를 준수하는 출력의 비율. 범위: 0-1.
tag주요 콘텐츠 HTML-to-Markdown 작업
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tag지시된 HTML-to-Markdown 작업
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tag스키마 기반 HTML-to-JSON 작업
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2는 모든 작업에서 상당한 진전을 보여줍니다. 주요 콘텐츠 추출에서 ReaderLM-v2-pro는 7개 메트릭 중 5개에서 최고 성능을 달성했으며, ROUGE-L (0.86), WER (0.39), Levenshtein (0.20), Damerau (928.15), Jaro-Winkler (0.83) 점수에서 우수한 성능을 보였습니다. 이러한 결과는 기본 버전과 더 큰 모델들에 비해 콘텐츠 보존과 구조적 정확도 모두에서 포괄적인 개선을 보여줍니다.
지시된 추출에서 ReaderLM-v2와 ReaderLM-v2-pro는 ROUGE-L (0.72), 대체율 (70.16), Levenshtein 거리 (0.37), Jaro-Winkler 유사도 (0.75, 기본 버전과 동점)에서 선도적입니다. GPT-4o가 WER과 Damerau 거리에서 장점을 보이는 반면, ReaderLM-v2-pro는 더 나은 전반적인 콘텐츠 구조와 정확도를 유지합니다. JSON 추출에서 이 모델은 높은 통과율(0.99)을 달성하면서 더 큰 모델들과 0.01-0.02 F1 포인트 차이 내에서 경쟁력 있는 성능을 보여줍니다.
tag정성적 평가
우리의 분석 중에reader-lm-1.5b에서 우리는 정량적 지표만으로는 모델 성능을 완전히 파악하기 어렵다는 것을 관찰했습니다. 수치적 평가는 때때로 지각적 품질을 제대로 반영하지 못했습니다—낮은 지표 점수에도 시각적으로 만족스러운 markdown이 생성되거나, 높은 점수에도 최적화되지 않은 결과가 나오는 경우가 있었습니다. 이러한 불일치를 해결하기 위해, 영어, 일본어, 중국어로 된 뉴스 기사, 블로그 포스트, 제품 페이지, 전자상거래 사이트, 법률 문서를 포함한 10개의 다양한 HTML 소스에 대해 체계적인 정성 평가를 실시했습니다. 테스트 코퍼스는 다중 행 테이블, 동적 레이아웃, LaTeX 수식, 링크된 테이블, 중첩 목록과 같은 까다로운 서식 요소를 강조하여 실제 모델 기능을 더 포괄적으로 파악할 수 있게 했습니다.
tag평가 지표
우리의 인간 평가는 세 가지 주요 차원에 초점을 맞췄으며, 출력물은 1-5점 척도로 평가되었습니다:
콘텐츠 무결성 - HTML에서 markdown으로 변환 시 의미론적 정보의 보존을 평가합니다:
- 텍스트 내용의 정확성과 완전성
- 링크, 이미지, 코드 블록, 수식, 인용문의 보존
- 텍스트 서식과 링크/이미지 URL의 유지
구조적 정확성 - HTML 구조 요소의 Markdown으로의 정확한 변환을 평가합니다:
- 헤더 계층 구조 보존
- 목록 중첩의 정확성
- 테이블 구조의 충실도
- 코드 블록과 인용문 서식
형식 준수 - Markdown 구문 표준 준수를 측정합니다:
- 헤더(#), 목록(*, +, -), 테이블, 코드 블록(```) 등에 대한 적절한 구문 사용
- 불필요한 공백이나 비표준 구문이 없는 깔끔한 서식
- 일관되고 가독성 있는 렌더링 출력
10개의 HTML 페이지를 수동으로 평가할 때, 각 평가 기준의 최대 점수는 50점입니다. ReaderLM-v2는 모든 차원에서 강력한 성능을 보여주었습니다:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
콘텐츠 완전성 측면에서, 특히 LaTeX 수식, 중첩 목록, 코드 블록과 같은 복잡한 요소 인식에서 뛰어났습니다. 이 모델은 경쟁 모델들이 H1 헤더를 누락하거나(reader-lm-1.5b), 콘텐츠를 잘라내거나(Claude 3.5), 원시 HTML 태그를 유지하는(Gemini-2.0-flash) 반면, 복잡한 콘텐츠 구조를 다룰 때 높은 충실도를 유지했습니다.
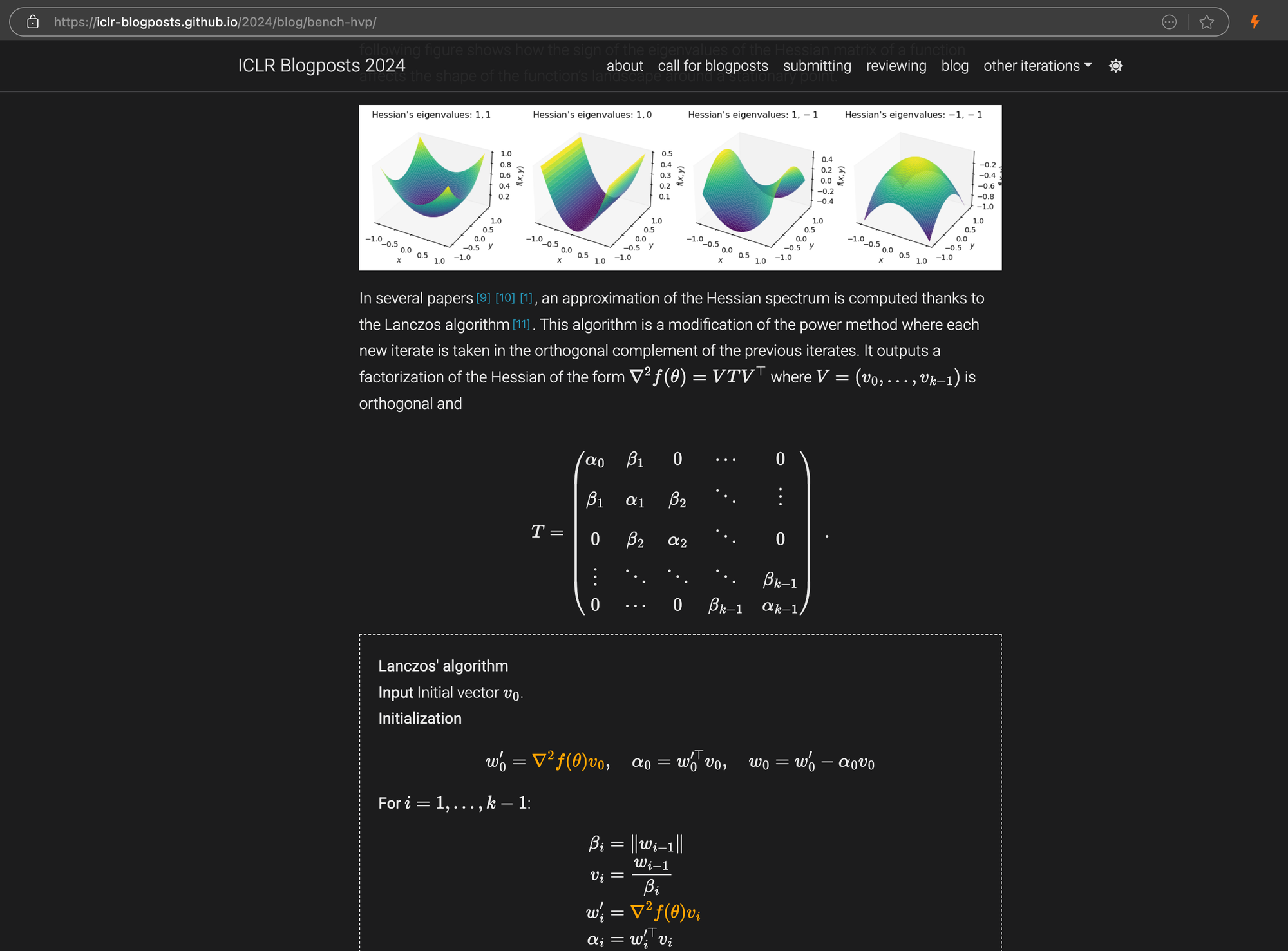
ICLR 블로그 포스트에 markdown으로 삽입된 복잡한 LaTeX 방정식을 보여주는 오른쪽 패널의 소스 HTML 코드.
\[...\](및 그에 상응하는 HTML)를 인라인 방정식의 경우 $...$와 같은 Markdown 표준 구분자로, 디스플레이 방정식의 경우 $$...$$로 대체합니다. 이는 Markdown 해석에서 구문 충돌을 방지하는 데 도움이 됩니다.구조적 정확성 면에서, ReaderLM-v2는 일반적인 웹 구조에 대해 최적화된 모습을 보여주었습니다. 예를 들어, Hacker News 사례에서는 완전한 링크를 성공적으로 재구성하고 목록 표현을 최적화했습니다. 이 모델은 ReaderLM-v1이 어려워했던 복잡한 비블로그 HTML 구조도 처리할 수 있었습니다.
형식 준수 면에서, ReaderLM-v2는 특히 Hacker News, 블로그, WeChat 기사와 같은 콘텐츠를 처리하는 데 강점을 보였습니다. 다른 대형 언어 모델들이 markdown과 유사한 소스에서는 잘 수행했지만, 더 많은 해석과 재포맷이 필요한 전통적인 웹사이트에서는 어려움을 겪었습니다.
우리의 분석에 따르면, gpt-4o는 짧은 웹사이트를 처리하는 데 뛰어나며, 다른 모델들에 비해 사이트 구조와 포맷팅에 대한 이해도가 우수한 것으로 나타났습니다. 하지만 긴 콘텐츠를 처리할 때는 gpt-4o가 완전성 면에서 어려움을 겪으며, 종종 텍스트의 시작과 끝 부분을 생략하는 경향이 있습니다. Zillow 웹사이트를 예시로 gpt-4o, ReaderLM-v2, ReaderLM-v2-pro의 출력을 비교 분석한 내용을 포함했습니다.
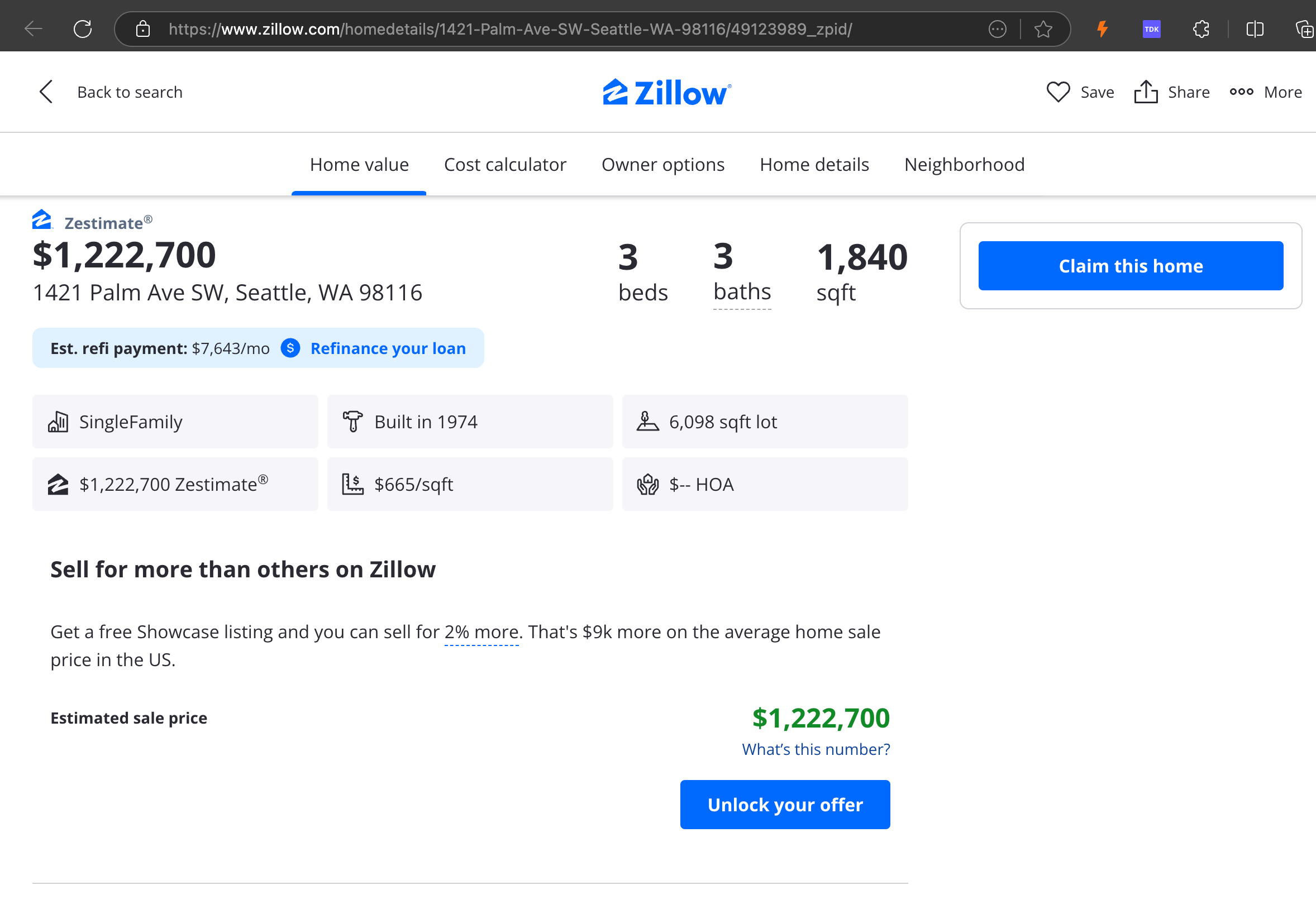
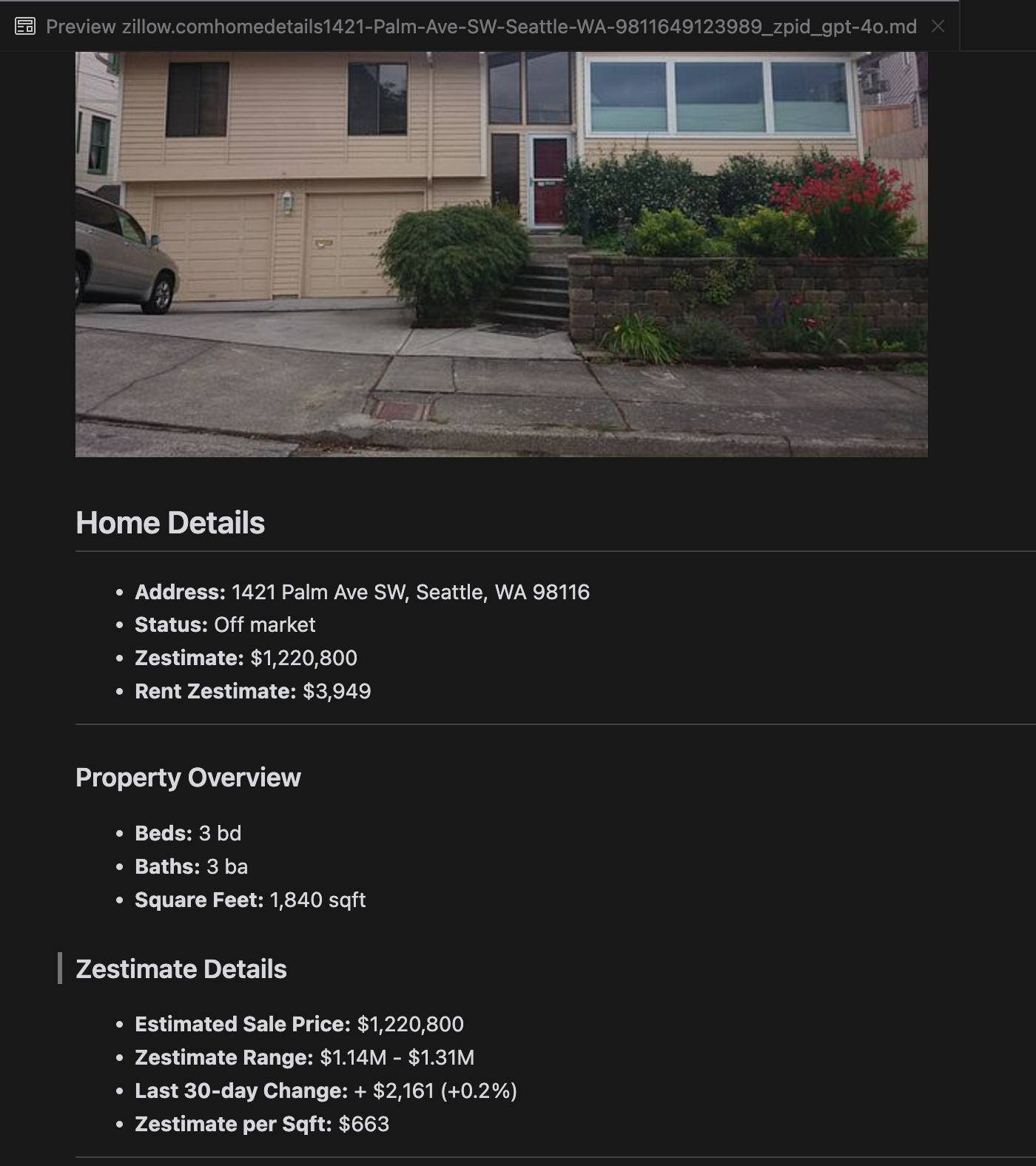
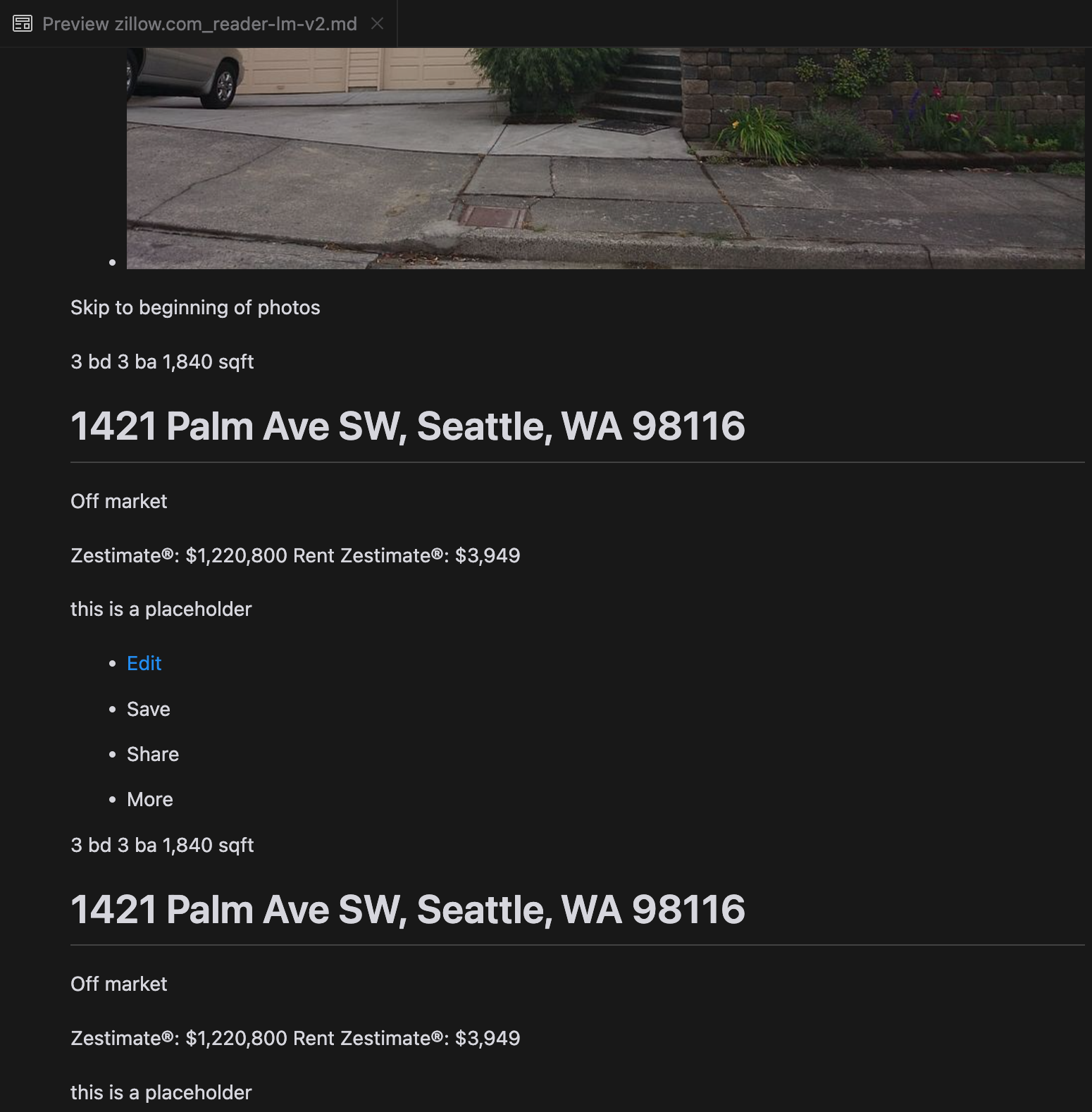
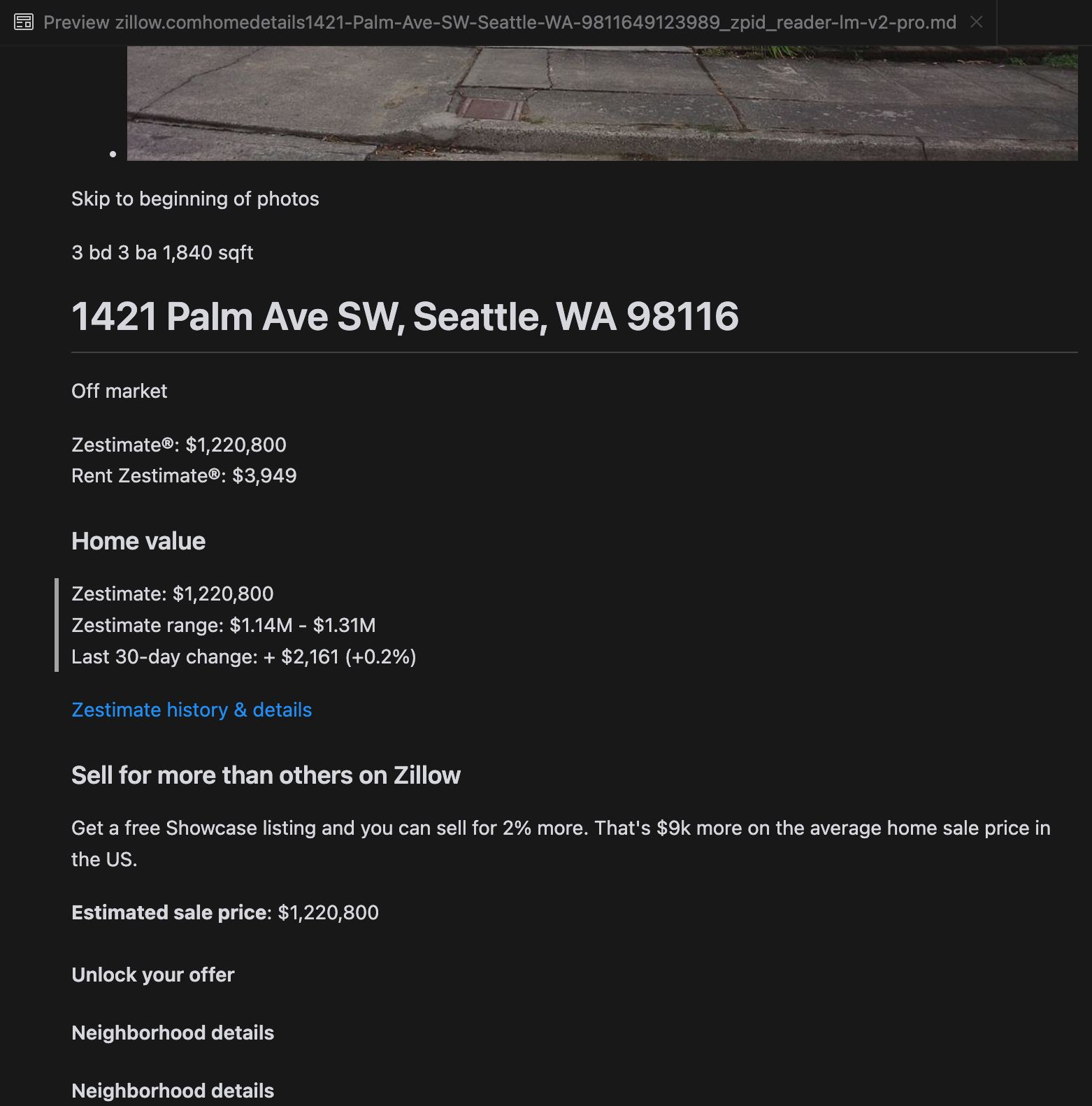
gpt-4o(왼쪽),ReaderLM-v2(중앙),ReaderLM-v2-pro(오른쪽)의 Markdown 렌더링 결과 비교
제품 랜딩 페이지나 정부 문서와 같은 특정 어려운 사례에서도 ReaderLM-v2와 ReaderLM-v2-pro의 성능은 안정적이었지만 여전히 개선의 여지가 있습니다. ICLR 블로그 게시물의 복잡한 수학 공식과 코드는 대부분의 모델에게 어려움을 주었지만,ReaderLM-v2는 기본 Reader API보다 이러한 사례들을 더 잘 처리했습니다.
tagReaderLM v2 학습 방법
ReaderLM-v2는 지시사항 따르기와 긴 문맥 작업에서 효율성으로 알려진 컴팩트한 기본 모델인 Qwen2.5-1.5B-Instruction을 기반으로 합니다. 이 섹션에서는 데이터 준비,학습 방법,그리고 우리가 마주친 과제들에 초점을 맞추어 ReaderLM-v2를 어떻게 학습했는지 설명합니다.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tag데이터 준비
ReaderLM-v2의 성공은 학습 데이터의 품질에 크게 의존했습니다. 우리는 인터넷에서 수집한 100만 개의 HTML 문서를 포함하는 html-markdown-1m 데이터셋을 만들었습니다. 각 문서는 평균 56,000개의 토큰을 포함하여 실제 웹 데이터의 길이와 복잡성을 반영했습니다. 이 데이터셋을 준비하기 위해,JavaScript와 CSS와 같은 불필요한 요소들을 제거하면서 핵심 구조적,의미적 요소들을 보존하여 HTML 파일들을 정리했습니다. 정리 후,Jina Reader를 사용하여 정규식 패턴과 휴리스틱을 통해 HTML 파일을 Markdown으로 변환했습니다.
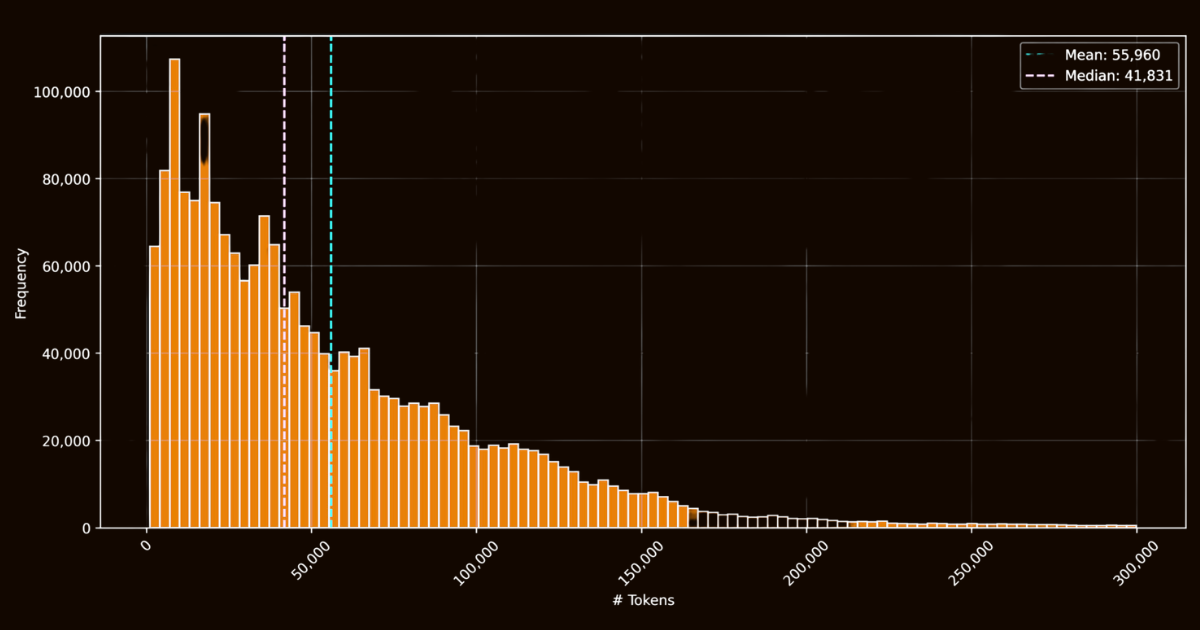
html-markdown-1m 데이터셋의 HTML 파일 토큰 길이 히스토그램이는 기능적인 기준 데이터셋을 만들었지만,중요한 한계를 드러냈습니다: 이러한 직접 변환으로만 학습된 모델들은 본질적으로 Jina Reader가 사용하는 정규식 패턴과 휴리스틱을 모방하는 것을 배우게 될 것입니다. 이는 reader-lm-0.5b/1.5b에서 명확해졌는데,그 성능의 한계가 이러한 규칙 기반 변환의 품질에 의해 제한되었습니다.
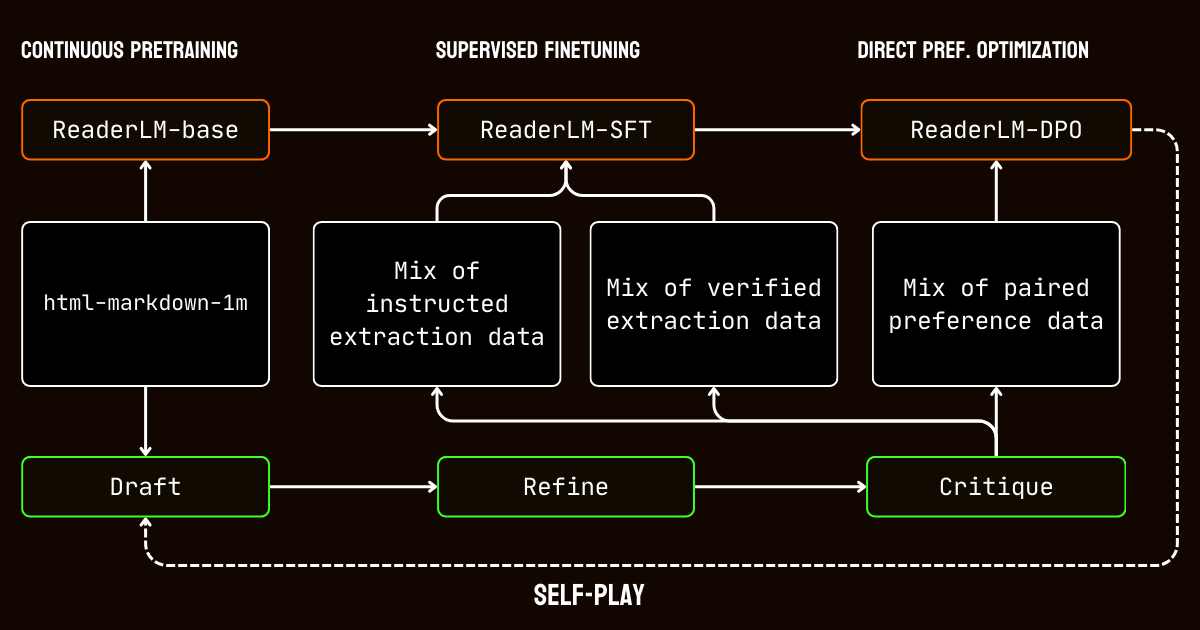
이러한 한계를 해결하기 위해,우리는 고품질의 합성 데이터셋을 만드는 데 필수적인 Qwen2.5-32B-Instruction 모델을 활용하는 3단계 파이프라인을 개발했습니다.

Qwen2.5-32B-Instruction이 구동하는 ReaderLM-v2용 합성 데이터 생성 파이프라인- 초안 작성: 모델에 제공된 지시사항을 기반으로 초기 Markdown과 JSON 출력을 생성했습니다. 이 출력들은 다양했지만 종종 노이즈가 있거나 일관성이 부족했습니다.
- 개선: 생성된 초안은 중복된 콘텐츠를 제거하고,구조적 일관성을 강화하며,원하는 형식에 맞추어 개선되었습니다. 이 단계는 데이터가 깨끗하고 작업 요구사항에 부합하도록 보장했습니다.
- 평가: 개선된 출력은 원래 지시사항에 대해 평가되었습니다. 이 평가를 통과한 데이터만이 최종 데이터셋에 포함되었습니다. 이러한 반복적 접근은 학습 데이터가 구조화된 데이터 추출에 필요한 품질 기준을 충족하도록 보장했습니다.
tag학습 과정
우리의 학습 과정은 긴 문맥 문서를 처리하는 과제에 맞춘 여러 단계를 포함했습니다.
html-markdown-1m 데이터셋을 사용하여 긴 문맥 사전 학습으로 시작했습니다. ring-zag attention과 rotary positional encoding (RoPE)와 같은 기술들을 사용하여 모델의 문맥 길이를 32,768 토큰에서 256,000 토큰으로 점진적으로 확장했습니다. 안정성과 효율성을 유지하기 위해,더 짧은 시퀀스로 시작하여 점진적으로 문맥 길이를 증가시키는 점진적 학습 접근방식을 채택했습니다.
사전 학습 후,지도 학습 미세조정(SFT)으로 넘어갔습니다. 이 단계는 데이터 준비 과정에서 생성된 개선된 데이터셋을 활용했습니다. 이 데이터셋들은 Markdown과 JSON 추출 작업을 위한 상세한 지시사항과 초안 개선을 위한 예시들을 포함했습니다. 각 데이터셋은 모델이 주요 콘텐츠 식별이나 스키마 기반 JSON 구조 준수와 같은 특정 작업을 학습하도록 신중하게 설계되었습니다.
그런 다음 모델의 출력을 고품질 결과와 일치시키기 위해 직접 선호도 최적화(DPO)를 적용했습니다. 이 단계에서 모델은 초안과 개선된 응답 쌍으로 학습되었습니다. 개선된 출력을 우선시하도록 학습함으로써,모델은 세련되고 작업에 특화된 결과를 정의하는 미묘한 차이를 내재화했습니다.
마지막으로,모델이 자체적으로 출력을 생성,개선,평가하는 반복적 과정인 셀프 플레이 강화 튜닝을 구현했습니다. 이 사이클은 추가적인 외부 감독 없이도 모델이 지속적으로 개선될 수 있게 했습니다. 자체 비평과 개선을 활용함으로써,모델은 정확하고 구조화된 출력을 생성하는 능력을 점진적으로 향상시켰습니다.
tag결론
2024년 4월,Jina Reader는 최초의 LLM 친화적인 markdown API가 되었습니다. 새로운 트렌드를 만들고,광범위한 커뮤니티 채택을 얻었으며,가장 중요하게는 데이터 정제와 추출을 위한 소형 언어 모델을 구축하도록 우리에게 영감을 주었습니다. 오늘,우리는 ReaderLM-v2로 다시 한번 수준을 높이며,지난 9월에 한 약속들을 이행하고 있습니다: 더 나은 긴 문맥 처리,입력 지시사항 지원,그리고 특정 웹페이지 콘텐츠를 markdown 형식으로 추출하는 능력입니다. 다시 한번,우리는 신중한 학습과 보정을 통해 소형 언어 모델이 더 큰 모델들을 능가하는 최첨단 성능을 달성할 수 있다는 것을 입증했습니다.
ReaderLM-v2의 학습 과정에서 우리는 두 가지 통찰을 얻었습니다. 한 가지 효과적인 전략은 특정 작업에 맞춘 별도의 데이터셋으로 전문화된 모델들을 학습하는 것이었습니다. 이러한 작업별 모델들은 나중에 선형 파라미터 보간을 사용하여 병합되었습니다. 이 접근방식은 추가적인 노력이 필요했지만,최종 통합 시스템에서 각 전문화된 모델의 고유한 강점을 보존하는 데 도움이 되었습니다.
반복적인 데이터 합성 프로세스는 모델의 성공에 매우 중요한 역할을 했습니다. 합성 데이터의 반복적인 개선과 평가를 통해 단순한 규칙 기반 접근 방식을 넘어서는 모델 성능을 크게 향상시켰습니다. Jina Reader의 regex와 휴리스틱 기반 학습 데이터 사용의 한계를 뛰어넘기 위해서는, 일관된 평가 기준 유지와 컴퓨팅 비용 관리에 어려움이 있었음에도 이러한 반복적 전략이 필수적이었습니다. 이는 Jina Reader의 규칙 기반 변환에 크게 의존하는 reader-lm-1.5b와 이러한 반복적 개선 프로세스의 혜택을 받은 ReaderLM-v2 간의 성능 차이를 통해 명확히 입증됩니다.
ReaderLM-v2가 여러분의 데이터 품질을 어떻게 개선하는지에 대한 피드백을 듣고 싶습니다. 앞으로는 스캔된 문서를 위한 멀티모달 기능으로 확장하고 생성 속도를 더욱 최적화할 계획입니다. 특정 도메인에 맞춤화된 ReaderLM 버전에 관심이 있으시다면 연락 주시기 바랍니다.



