


Как и многие люди, я слушаю много подкастов. Некоторые посвящены научной фантастике. Некоторые — палеонтологии. А некоторые рассказывают о странных средневековых персонажах. К сожалению, нет криминальных историй, если не считать моего иногда сомнительного вкуса.
Но... слушать все эти подкасты утомительно. И это еще не самое сложное. Я также подписан на множество новостных лент. А это означает много чтения. Было бы здорово просто взять весь контент из этих новостных лент, создать пятиминутное резюме и слушать его через телефон, пока чищу зубы утром.
Полагаю, вы уже догадываетесь, к чему я веду. Я использую Python для создания инструмента на основе (преимущественно) технологического стека Jina, чтобы создавать свой персонализированный ежедневный новостной подкаст.
Если хотите сразу узнать, как это звучит, можете послушать ниже:
tagЧто такое новостная лента?
Во-первых, я называю их "новостными лентами", поскольку большинство людей не знакомы с терминами RSS или Atom feeds. Если коротко, лента — это структурированный список статей, опубликованных блогом или новостным источником, упорядоченный от новых к старым. Многие сайты предлагают их, и существует несколько приложений и веб-сайтов, которые позволяют импортировать все ваши ленты, позволяя читать все новости в одном приложении, без необходимости посещать сайты Ars Technica, фан-сайты Taylor Swift и Washington Post:
Это древняя технология из доисторического веба, но многие веб-сайты поддерживают их, включая блог Jina AI (вот наша лента).
Короче говоря, ленты позволяют читать все новости в одном месте, пропуская всю рекламу и боковые панели. В этой статье мы будем использовать новостные ленты для поиска и загрузки последних публикаций с сайтов, на которые мы подписаны.
tagДавайте начнем этот пир
pip install и настройка ключей в этом посте опущены, поэтому если хотите повторить все шаги, обратитесь к ноутбуку для полного опыта, а этот пост используйте для общего понимания.Ссылка на Colab | Ссылка на GitHub
Для реализации этой магии мы будем использовать несколько сервисов и Python-библиотек:
- Feedparser: Python-библиотека для загрузки и извлечения контента из новостных лент.
- Jina Reader: API от Jina для извлечения только содержимого каждой статьи, без загрузки лишнего, вроде заголовков, подвалов и боковых панелей.
- PromptPerfect: Prompts-as-Services будет суммировать каждую статью, а затем объединять эти сводки в единый абзац в стиле новостного диктора NPR.
- gTTS: Библиотека преобразования текста в речь от Google для озвучивания новостного репортажа.
Это все, что мы рассмотрим в этом посте. Если вы хотите создать подкаст-ленту для своего персонализированного подкаста, рекомендуем обратиться к другим источникам.
tagЗагрузка лент
Поскольку это простой пример, мы ограничимся парой новостных лент от The Register и OSNews, двух технологических новостных сайтов.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]С помощью Feedparser мы можем загрузить ленты и извлечь ссылки на статьи из каждой ленты:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tagИзвлечение текста статей с помощью Jina Reader
Каждая лента содержит ссылки на статьи на соответствующем сайте. Если мы просто загрузим веб-страницу, мы получим кучу HTML-кода, включая боковые панели, заголовки, подвалы и другой ненужный мусор. Если вы скормите это LLM, это будет как жевать траву. Конечно, LLM может это сделать, но это не то, что он естественным образом хочет "есть".
То, что действительно нужно LLM — это что-то близкое к обычному тексту. Jina Reader преобразует статью в формат Markdown.

Это выглядит примерно так:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...Мы сократили это, так как включать всю статью излишне. Но вы можете видеть, что это чистый, читаемый человеком текст (markdown).
Вместо этого:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...Мы вынуждены были обрезать это еще до того, как дошли до самого содержания. Здесь просто слишком много нечитаемого человеком мусора.
Предоставляя LLM что-то, что он может более естественно переварить (как markdown вместо HTML), мы можем получить лучший результат. В противном случае это как кормить льва чипсами Doritos. Конечно, он может их съесть, но он не будет лучшей версией себя при такой диете.
Чтобы извлечь только текст в читаемом виде, мы будем использовать API Jina Reader:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url>, например https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tagСуммирование статей с помощью PromptPerfect
Поскольку статей может быть много, мы будем использовать LLM для суммирования каждой по отдельности. Если мы просто объединим их все и отправим LLM для суммирования, он может задохнуться от слишком большого количества токенов одновременно.
Это будет зависеть от того, со сколькими статьями вы хотите работать. Для нескольких может быть целесообразно объединить их все в одну длинную строку и сделать один вызов, экономя время и деньги. Однако в этом примере мы предположим, что имеем дело с большим количеством статей.
Для суммирования мы будем использовать Prompt-as-a-Service от PromptPerfect.
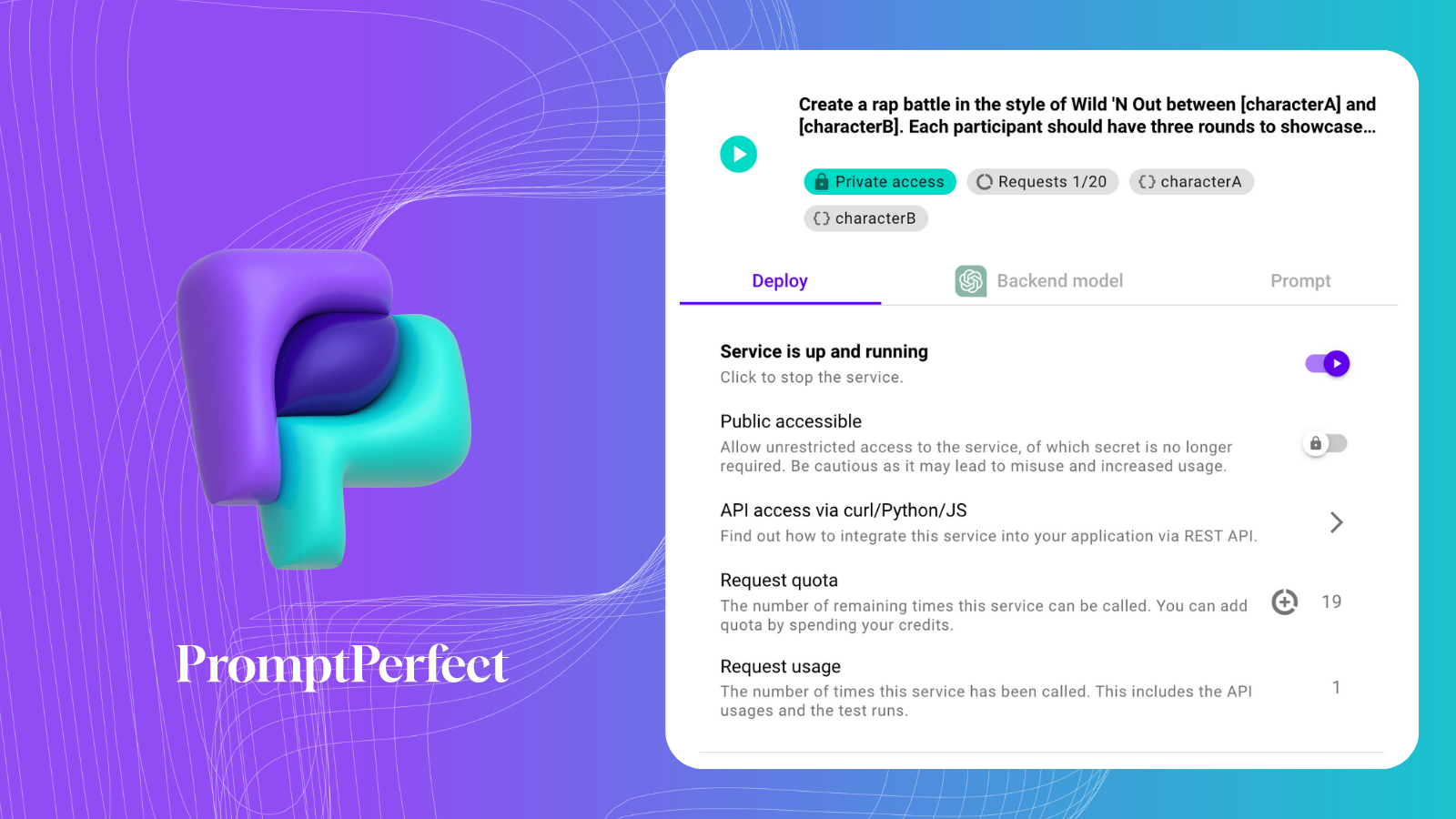
Вот наш Prompt-as-Service:

Мы напишем функцию для этого, так как позже в этой статье мы будем вызывать другой Prompt-as-Service:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.textЗатем мы добавим каждое резюме в список, в конце объединив их в маркированный список markdown:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tagСоздание новостного репортажа с помощью PromptPerfect
Теперь, когда у нас есть этот маркированный список, мы можем отправить его в другой Prompt-as-a-Service, чтобы создать новостной бюллетень, который звучит как естественная речь диктора:

Полный промпт:
Вы — редактор технологических новостей NPR. Вы получили следующие новостные сводки:
[summaries]
Ваша задача — дать однопараграфный обзор новостей, органично охватывая каждый пункт с переходами к следующему. Вы можете изменить порядок пунктов, если это имеет смысл, и объединить дубликаты.
Вы должны создать однопараграфный сценарий, который звучит естественно, для чтения в ежедневных новостях NPR. Чтение сценария вслух не должно занимать больше пяти минут.
Мы получим новостной сценарий с помощью этого кода:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)Вот финальный текст:
Сегодня в технологических новостях у нас есть ряд обновлений и событий для обсуждения. Во-первых, инструмент Tiny11 Builder предлагает пользователям возможность удалить ненужные компоненты Windows 11, создавая настроенный образ в соответствии с их предпочтениями. Переходя к миру игр, мы углубляемся в скрытые компоненты внутри картриджей Super Nintendo, проливая свет на технологии, которые восхищали геймеров в 90-х. Переключаясь на программное обеспечение, менеджер окон Niri для Wayland выпустил крупное обновление, предлагая новые функции, такие как бесконечная прокрутка и улучшенные анимации. В сфере ИИ функция Microsoft Copilot столкнулась с некоторыми проблемами при развертывании для Windows Insiders, из-за ошибок и навязчивого поведения пришлось приостановить развертывание. Между тем, Управление комиссара по информации Великобритании высказывает озабоченность по поводу Privacy Sandbox от Google, ставя под вопрос его последствия для конфиденциальности и влияние на конкуренцию. Наконец, Федеральное управление гражданской авиации США обновило требования к лицензированию запусков, теперь требуя получения лицензии для аппаратов возвращения перед запуском, после инцидента с Varda Space Industries. Эти разнообразные технологические истории подчеркивают текущие достижения и проблемы в мире технологий.
tagЧтение новостей вслух
Чтобы прочитать текст вслух, мы будем использовать библиотеку Google TTS.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")Это даст нам финальный аудиофайл:
tagСледующие шаги
Мы не будем рассматривать остальную часть процесса создания подкаста в этой статье. Это не наша специализация, и как с медицинскими советами, вам, вероятно, не стоит слушать нас, когда дело доходит до тонкостей настройки подкаст-фида, загрузки его в Spotify, Apple Podcasts и т.д. За медицинскими советами или советами по подкастингу обращайтесь к своему врачу или Джо Рогану соответственно.
Что касается других возможностей Jina Reader, подумайте обо всех приложениях RAG, которые вы можете создать, загружая читаемые версии любых веб-страниц. Или для PromptPerfect посмотрите, как он может помочь YouTube-блогерам (или маркетологам, если это ваше направление.)
