



В апреле 2024 года мы запустили Jina Reader, API, который преобразует любую веб-страницу в LLM-совместимый markdown, просто добавляя префикс URL r.jina.ai. В сентябре 2024 года мы выпустили две малые языковые модели, reader-lm-0.5b и reader-lm-1.5b, специально разработанные для преобразования необработанного HTML в чистый markdown. Сегодня мы рады представить второе поколение ReaderLM — языковую модель с 1,5 млрд параметров, которая преобразует необработанный HTML в красиво отформатированный markdown или JSON с превосходной точностью и улучшенной обработкой длинного контекста. ReaderLM-v2 обрабатывает до 512 тыс. токенов общей длины входных и выходных данных. Модель обеспечивает многоязычную поддержку для 29 языков, включая английский, китайский, японский, корейский, французский, испанский, португальский, немецкий, итальянский, русский, вьетнамский, тайский, арабский и другие.
Благодаря своей новой парадигме обучения и более качественным обучающим данным, ReaderLM-v2 представляет собой значительный шаг вперед по сравнению с предшественником, особенно в обработке длинных текстов и генерации markdown-синтаксиса. В то время как первое поколение рассматривало преобразование HTML в markdown как задачу "выборочного копирования", v2 рассматривает это как настоящий процесс перевода. Этот сдвиг позволяет модели мастерски использовать синтаксис markdown, особенно при генерации сложных элементов, таких как блоки кода, вложенные списки, таблицы и уравнения LaTex.
Сравнение результатов преобразования HTML в markdown главной страницы HackerNews между ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet и Gemini 2.0 Flash показывает уникальный стиль и производительность ReaderLM v2. ReaderLM v2 отлично сохраняет полную информацию из исходного HTML, включая оригинальные ссылки HackerNews, при этом умело структурируя контент с помощью синтаксиса markdown. Модель использует вложенные списки для организации локальных элементов (очки, временные метки и комментарии), сохраняя при этом последовательное глобальное форматирование через правильную иерархию заголовков (теги h1 и h2).
Основной проблемой в нашей первой версии была дегенерация после генерации длинных последовательностей, особенно в форме повторений и зацикливания. Модель либо начинала повторять один и тот же токен, либо зацикливалась, проходя через короткую последовательность токенов до достижения максимальной длины вывода. ReaderLM-v2 значительно снижает эту проблему путем добавления контрастных потерь во время обучения — его производительность остается стабильной независимо от длины контекста или количества уже сгенерированных токенов.

Помимо преобразования в markdown, ReaderLM-v2 представляет прямую генерацию HTML в JSON, позволяя пользователям извлекать определенную информацию из необработанного HTML в соответствии с заданной JSON-схемой. Этот сквозной подход устраняет необходимость в промежуточном преобразовании markdown, что является частым требованием во многих конвейерах очистки и извлечения данных на основе LLM.

Как в количественных, так и в качественных тестах ReaderLM-v2 превосходит гораздо более крупные модели, такие как Qwen2.5-32B-Instruct, Gemini2-flash-expr и GPT-4o-2024-08-06 в задачах преобразования HTML в Markdown, демонстрируя сопоставимую производительность в задачах извлечения HTML в JSON, при этом используя значительно меньше параметров.

ReaderLM-v2-pro — это эксклюзивная премиум-версия, зарезервированная для наших корпоративных клиентов, включающая дополнительное обучение и оптимизации.


Эти результаты показывают, что хорошо спроектированная модель с 1.5B параметров может не только соответствовать, но и часто превосходить производительность гораздо более крупных моделей в задачах извлечения структурированных данных. Прогрессивные улучшения от ReaderLM-v2 до ReaderLM-v2-pro демонстрируют эффективность нашей новой стратегии обучения в повышении производительности модели при сохранении вычислительной эффективности.
tagНачало работы
tagЧерез Reader API

ReaderLM-v2 теперь интегрирован с нашим Reader API. Чтобы использовать его, просто укажите x-engine: readerlm-v2 в заголовках запроса и включите потоковую передачу ответов с помощью -H 'Accept: text/event-stream':
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
Вы можете попробовать его без API-ключа с более низким ограничением скорости. Для более высоких ограничений скорости вы можете приобрести API-ключ. Обратите внимание, что запросы ReaderLM-v2 потребляют в 3 раза больше токенов из вашего API-ключа, чем обычно. Эта функция сейчас находится в бета-версии, пока мы сотрудничаем с командой GCP для оптимизации эффективности GPU и увеличения доступности модели.
tagВ Google Colab

Обратите внимание, что бесплатный GPU T4 имеет ограничения — он не поддерживает bfloat16 или flash attention 2, что приводит к большему использованию памяти и более медленной обработке длинных входных данных. Тем не менее, ReaderLM v2 успешно обрабатывает всю нашу юридическую страницу в этих условиях, достигая скорости обработки 67 токенов/с на входе и 36 токенов/с на выходе. Для производственного использования мы рекомендуем RTX 3090/4090 для оптимальной производительности.
Самый простой способ попробовать ReaderLM-v2 в хостинговой среде — через наш блокнот Colab, который демонстрирует преобразование HTML в markdown, извлечение JSON и выполнение инструкций на примере главной страницы HackerNews. Блокнот оптимизирован для бесплатного уровня GPU T4 в Colab и требует vllm и triton для ускорения и запуска. Не стесняйтесь тестировать его с любым веб-сайтом.
Преобразование HTML в Markdown
Вы можете использовать вспомогательную функцию create_prompt для легкого создания промпта для преобразования HTML в Markdown:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result будет строкой, обернутой в обратные кавычки Markdown как код. Вы также можете переопределить настройки по умолчанию для получения различных выходных данных, например:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()Однако, поскольку наши обучающие данные могут не охватывать все типы инструкций, особенно задачи, требующие многошагового рассуждения, наиболее надежные результаты получаются при преобразовании HTML в Markdown. Для наиболее эффективного извлечения информации мы рекомендуем использовать JSON-схему, как показано ниже:
Извлечение HTML в JSON с помощью JSON-схемы
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result будет строкой, обернутой в обратные кавычки в формате JSON, а не фактическим объектом JSON/dict. Вы можете использовать Python для преобразования строки в правильный словарь или JSON-объект для дальнейшей обработки.
tagВ продакшене: Доступно на CSP
ReaderLM-v2 доступен на AWS SageMaker, Azure и GCP marketplace. Если вам нужно использовать эти модели за пределами этих платформ или локально в вашей компании, обратите внимание, что эта модель и ReaderLM-v2-pro лицензированы под CC BY-NC 4.0. По вопросам коммерческого использования или доступа к ReaderLM-v2-pro не стесняйтесь связаться с нами.

tagКоличественная оценка
Мы оцениваем ReaderLM-v2 по трем задачам извлечения структурированных данных в сравнении с современными моделями: GPT-4o-2024-08-06, Gemini2-flash-expr и Qwen2.5-32B-Instruct. Наша система оценки сочетает метрики, измеряющие как точность содержания, так и структурную точность. ReaderLM-v2 - это публично доступная версия с открытыми весами, в то время как ReaderLM-v2-pro - это эксклюзивная премиум-версия, зарезервированная для наших корпоративных клиентов, с дополнительным обучением и оптимизациями. Обратите внимание, что наша первая версия reader-lm-1.5b оценивается только по основной задаче извлечения контента, так как она не поддерживает возможности извлечения по инструкциям или извлечения JSON.
tagМетрики оценки
Для задач HTML-в-Markdown мы используем семь взаимодополняющих метрик. Примечание: ↑ означает, что большее значение лучше, ↓ означает, что меньшее значение лучше
- ROUGE-L (↑): Измеряет самую длинную общую последовательность между сгенерированным и эталонным текстом, отражая сохранение содержания и структурное сходство. Диапазон: 0-1, более высокие значения указывают на лучшее совпадение последовательностей.
- WER (Word Error Rate) (↓): Определяет минимальное количество правок на уровне слов, необходимых для преобразования сгенерированного текста в эталонный. Меньшие значения указывают на меньшее количество необходимых исправлений.
- SUB (Substitutions) (↓): Подсчитывает количество необходимых замен слов. Меньшие значения предполагают лучшую точность на уровне слов.
- INS (Insertions) (↓): Измеряет количество слов, которые необходимо вставить для соответствия эталону. Меньшие значения указывают на лучшую полноту.
- Levenshtein Distance (↓): Рассчитывает минимальное количество необходимых правок на уровне символов. Меньшие значения предполагают лучшую точность на уровне символов.
- Damerau-Levenshtein Distance (↓): Аналогично Levenshtein, но также учитывает перестановки символов. Меньшие значения указывают на лучшее совпадение на уровне символов.
- Jaro-Winkler Similarity (↑): Подчеркивает совпадение символов в начале строк, особенно полезно для оценки сохранения структуры документа. Диапазон: 0-1, более высокие значения указывают на лучшее сходство.
Для задач HTML-в-JSON мы рассматриваем это как задачу поиска и используем четыре метрики из информационного поиска:
- F1 Score (↑): Среднее гармоническое точности и полноты, обеспечивающее общую точность. Диапазон: 0-1.
- Precision (↑): Доля правильно извлеченной информации среди всех извлечений. Диапазон: 0-1.
- Recall (↑): Доля правильно извлеченной информации из всей доступной информации. Диапазон: 0-1.
- Pass-Rate (↑): Доля выходных данных, которые являются валидным JSON и соответствуют схеме. Диапазон: 0-1.
tagЗадача преобразования основного контента из HTML в Markdown
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tagЗадача преобразования HTML в Markdown по инструкции
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tagЗадача преобразования HTML в JSON на основе схемы
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 представляет значительный прогресс во всех задачах. Для извлечения основного контента ReaderLM-v2-pro достигает наилучших результатов по пяти из семи метрик, с превосходными показателями ROUGE-L (0.86), WER (0.39), Levenshtein (0.20), Damerau (928.15) и Jaro-Winkler (0.83). Эти результаты демонстрируют комплексные улучшения как в сохранении содержания, так и в структурной точности по сравнению с базовой версией и более крупными моделями.
В извлечении по инструкции ReaderLM-v2 и ReaderLM-v2-pro лидируют по показателям ROUGE-L (0.72), коэффициенту замен (70.16), расстоянию Левенштейна (0.37) и сходству Джаро-Винклера (0.75, наравне с базовой версией). Хотя GPT-4o показывает преимущества в WER и расстоянии Дамерау, ReaderLM-v2-pro сохраняет лучшую общую структуру и точность контента. В извлечении JSON модель показывает конкурентоспособные результаты, отставая всего на 0.01-0.02 пункта F1 от более крупных моделей при достижении высоких показателей успешности (0.99).
tagКачественная оценка
В ходе нашего анализаПри тестировании reader-lm-1.5b мы обнаружили, что количественные метрики не всегда полностью отражают производительность модели. Числовые оценки иногда не соответствовали визуальному качеству — были случаи, когда низкие метрические показатели давали визуально удовлетворительный markdown, или высокие показатели приводили к неоптимальным результатам. Чтобы устранить это несоответствие, мы провели систематическую качественную оценку на 10 различных HTML-источниках, включая новостные статьи, блог-посты, страницы продуктов, сайты электронной коммерции и юридические документы на английском, японском и китайском языках. Тестовый корпус включал сложные элементы форматирования, такие как многострочные таблицы, динамические макеты, формулы LaTeX, связанные таблицы и вложенные списки, что обеспечило более полное представление о возможностях модели в реальных условиях.
tagМетрики оценки
Наша человеческая оценка сфокусировалась на трех ключевых аспектах, с оценкой выходных данных по шкале от 1 до 5:
Целостность контента - Оценивает сохранение семантической информации при конвертации HTML в markdown, включая:
- Точность и полнота текстового содержания
- Сохранение ссылок, изображений, блоков кода, формул и цитат
- Сохранение форматирования текста и URL ссылок/изображений
Структурная точность - Оценивает точность преобразования структурных элементов HTML в Markdown:
- Сохранение иерархии заголовков
- Точность вложенности списков
- Точность структуры таблиц
- Форматирование блоков кода и цитат
Соответствие формату - Измеряет соблюдение стандартов синтаксиса Markdown:
- Правильное использование синтаксиса для заголовков (#), списков (*, +, -), таблиц, блоков кода (```)
- Чистое форматирование без лишних пробелов или нестандартного синтаксиса
- Последовательный и читаемый отображаемый результат
При ручной оценке более 10 HTML-страниц максимальный балл по каждому критерию оценки составляет 50 баллов. ReaderLM-v2 продемонстрировала высокие результаты по всем параметрам:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
По полноте контента она отлично справлялась с распознаванием сложных элементов, особенно формул LaTeX, вложенных списков и блоков кода. Модель сохраняла высокую точность при обработке сложных структур контента, в то время как конкурирующие модели часто пропускали заголовки H1 (reader-lm-1.5b), обрезали контент (Claude 3.5) или сохраняли необработанные HTML-теги (Gemini-2.0-flash).
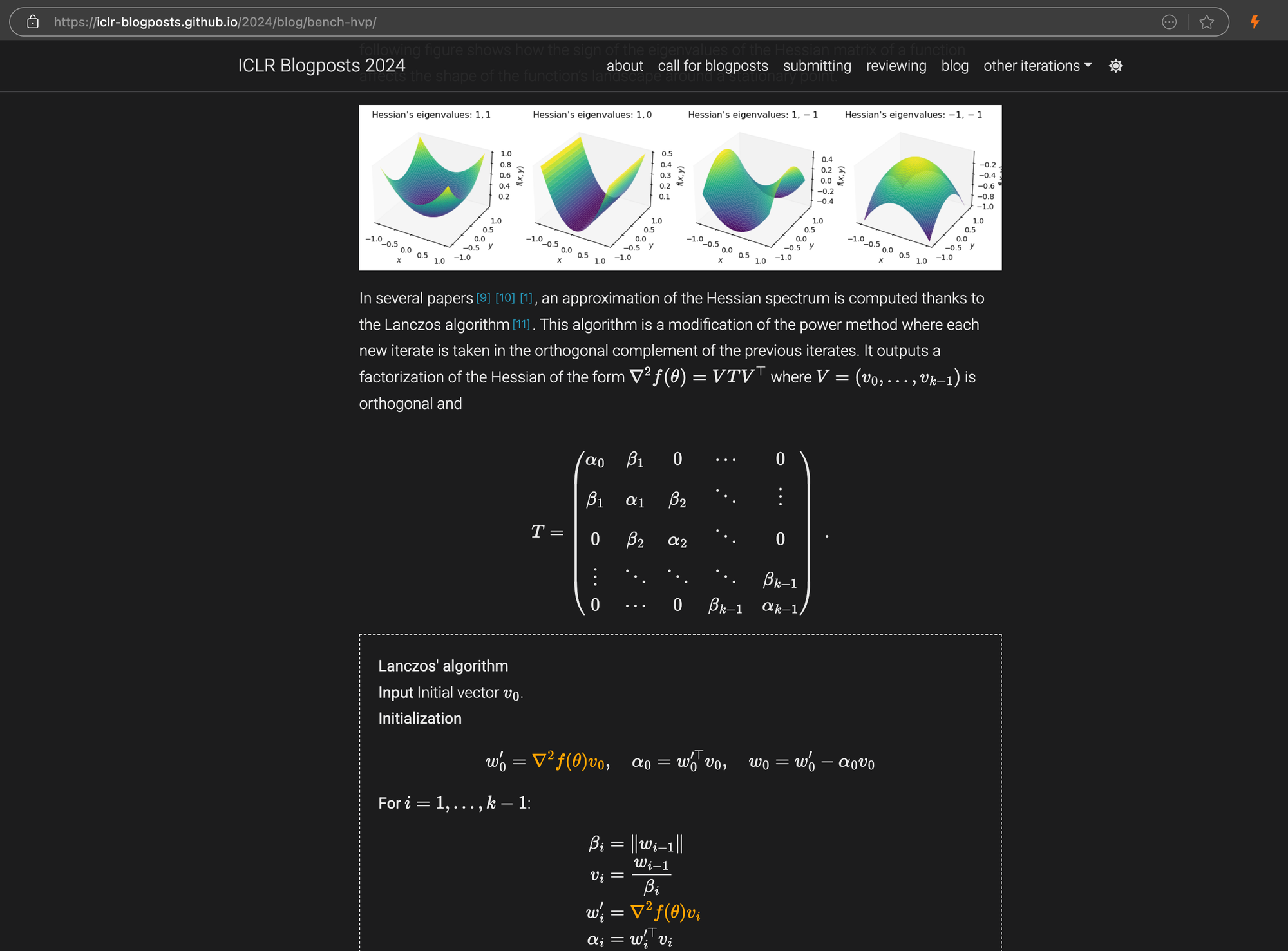
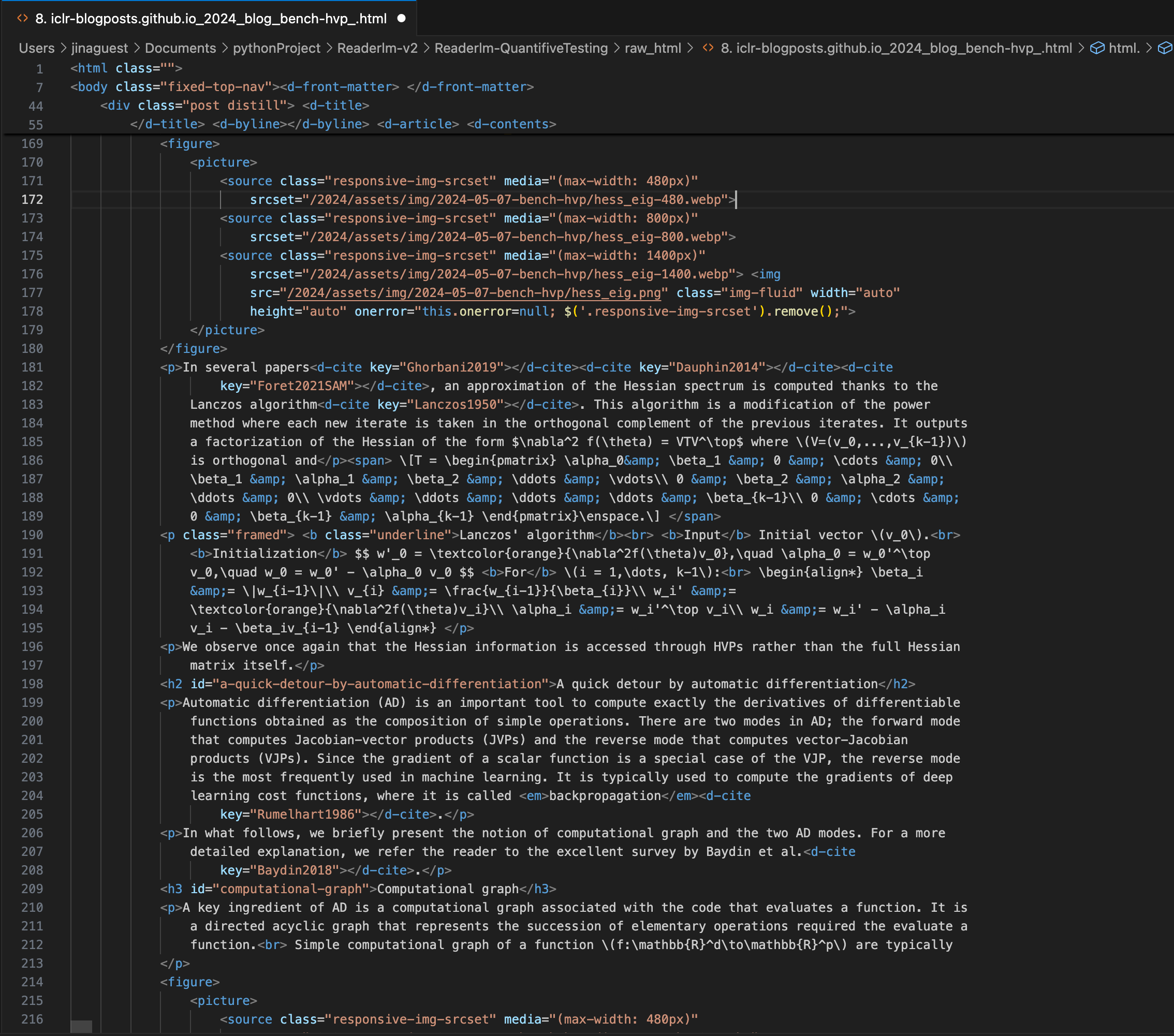
Блог-пост ICLR со сложными уравнениями LaTeX, встроенными в markdown, показывающий исходный HTML-код на правой панели.
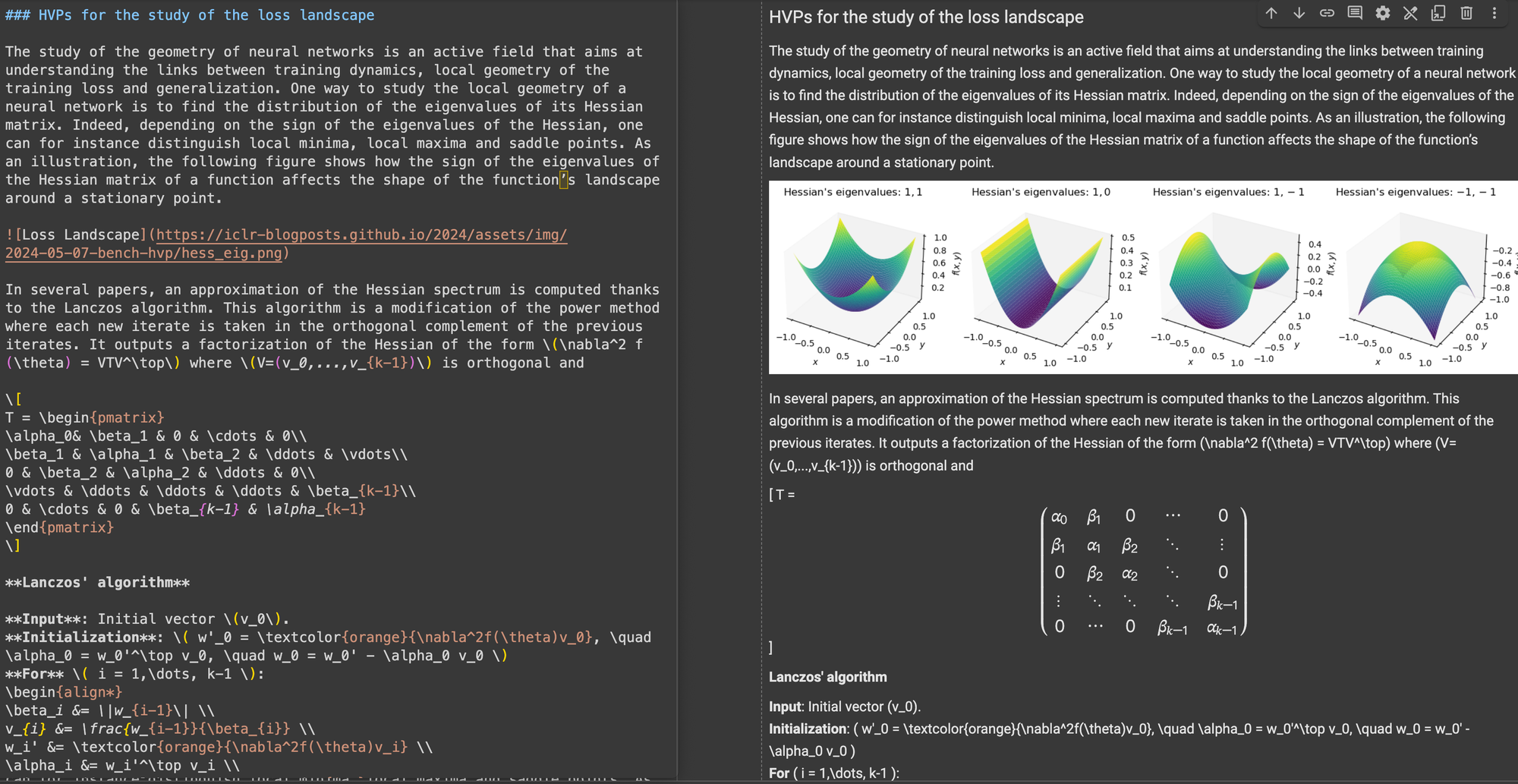
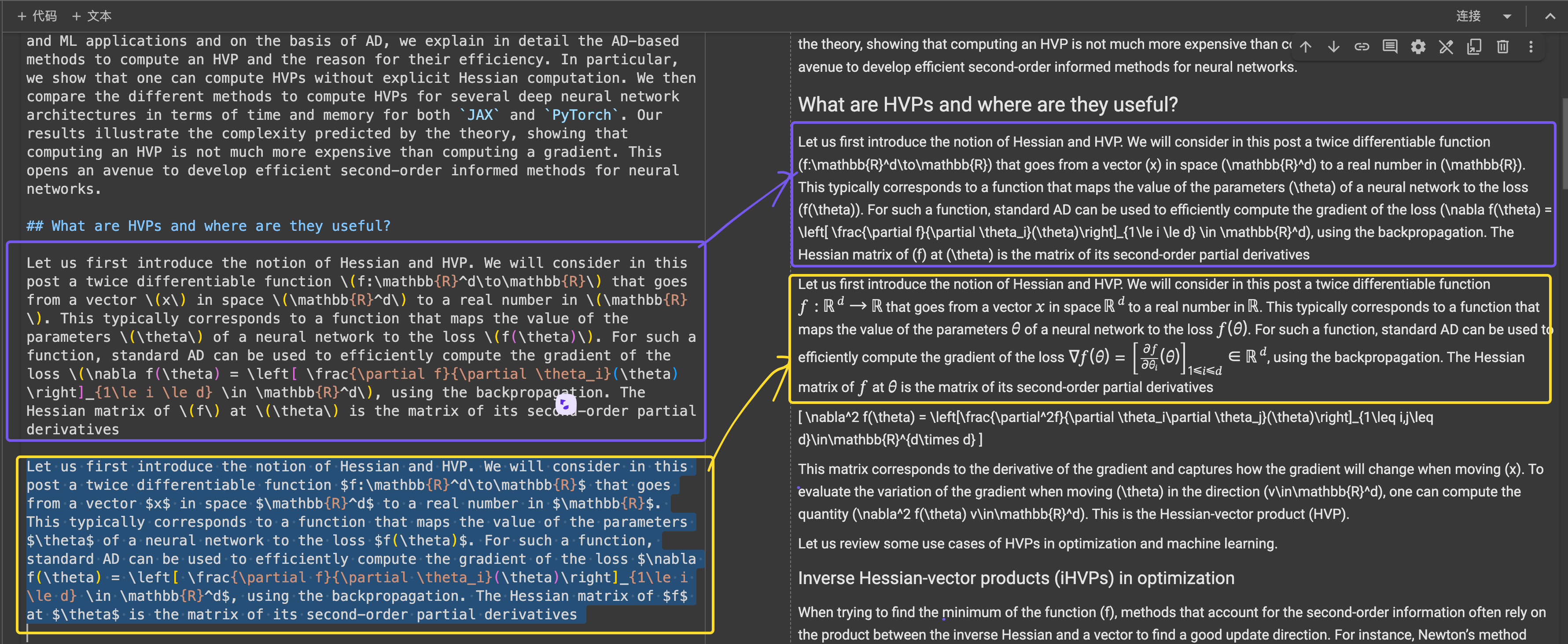
\[...\] (и его HTML-эквивалентов) на стандартные разделители Markdown, такие как $...$ для встроенных уравнений и $$...$$ для выделенных уравнений. Это помогает избежать конфликтов синтаксиса при интерпретации Markdown.В структурной точности ReaderLM-v2 показала оптимизацию для распространенных веб-структур. Например, в случаях с Hacker News она успешно восстанавливала полные ссылки и оптимизировала представление списков. Модель справлялась со сложными не-блоговыми HTML-структурами, которые были проблематичны для ReaderLM-v1.
По соответствию формату ReaderLM-v2 продемонстрировала особую силу в обработке контента типа Hacker News, блогов и статей WeChat. В то время как другие большие языковые модели хорошо справлялись с markdown-подобными источниками, они испытывали трудности с традиционными веб-сайтами, требующими большей интерпретации и переформатирования.
Наш анализ показал, что gpt-4o отлично справляется с обработкой более коротких веб-сайтов, демонстрируя превосходное понимание структуры сайта и форматирования по сравнению с другими моделями. Однако при обработке более длинного контента gpt-4o испытывает трудности с полнотой, часто пропуская части в начале и конце текста. Мы включили сравнительный анализ выходных данных от gpt-4o, ReaderLM-v2 и ReaderLM-v2-pro на примере веб-сайта Zillow.
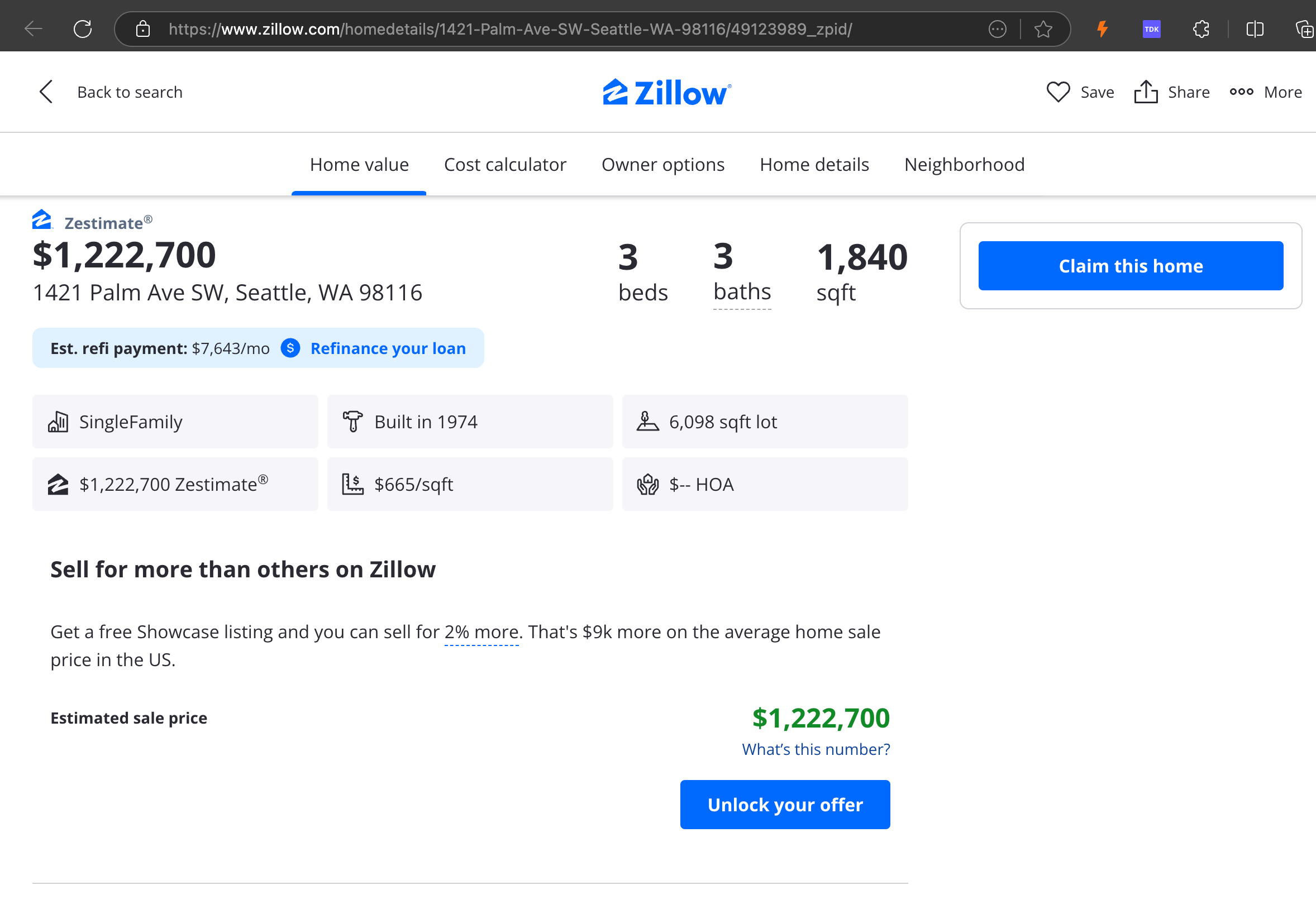
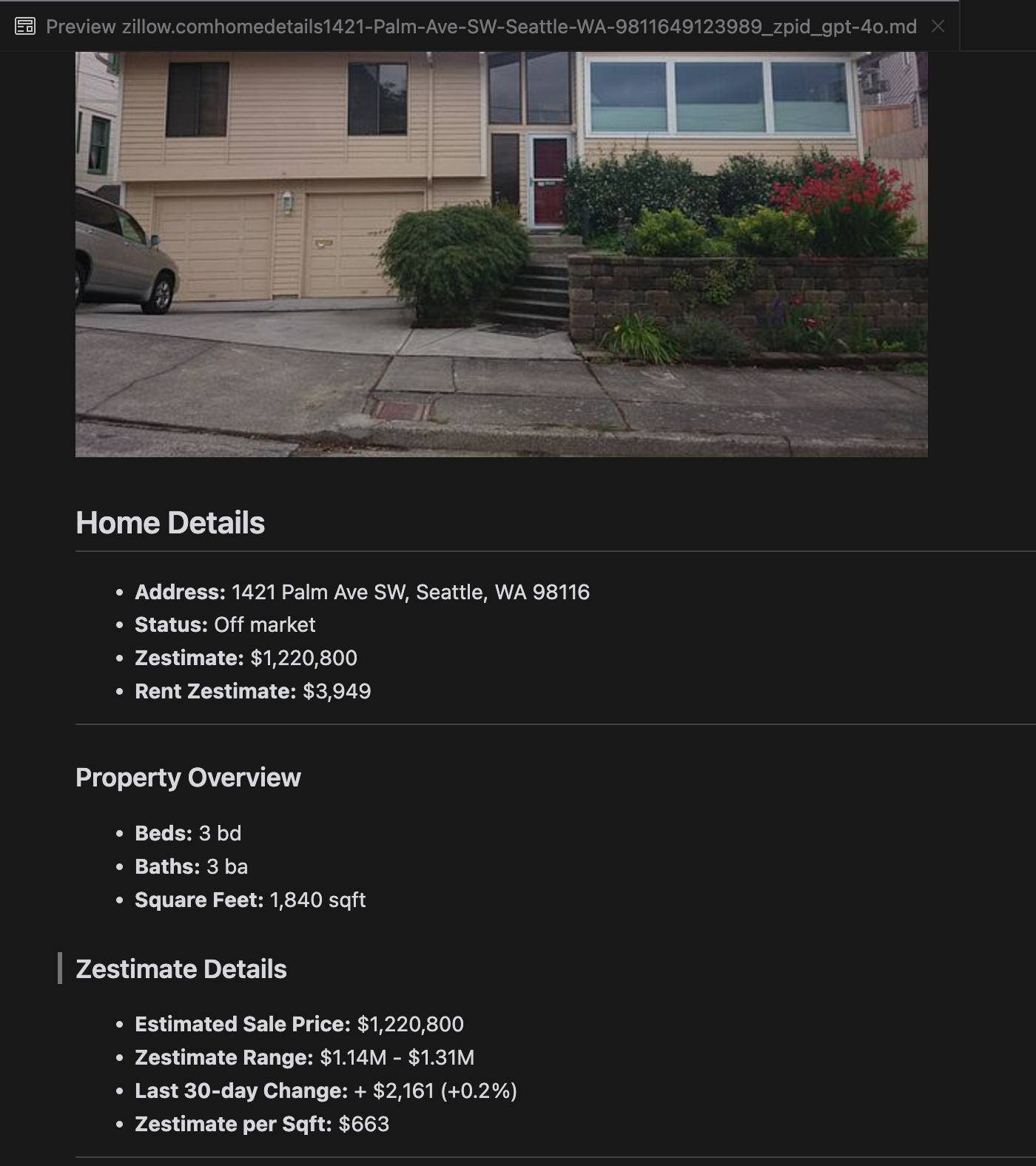
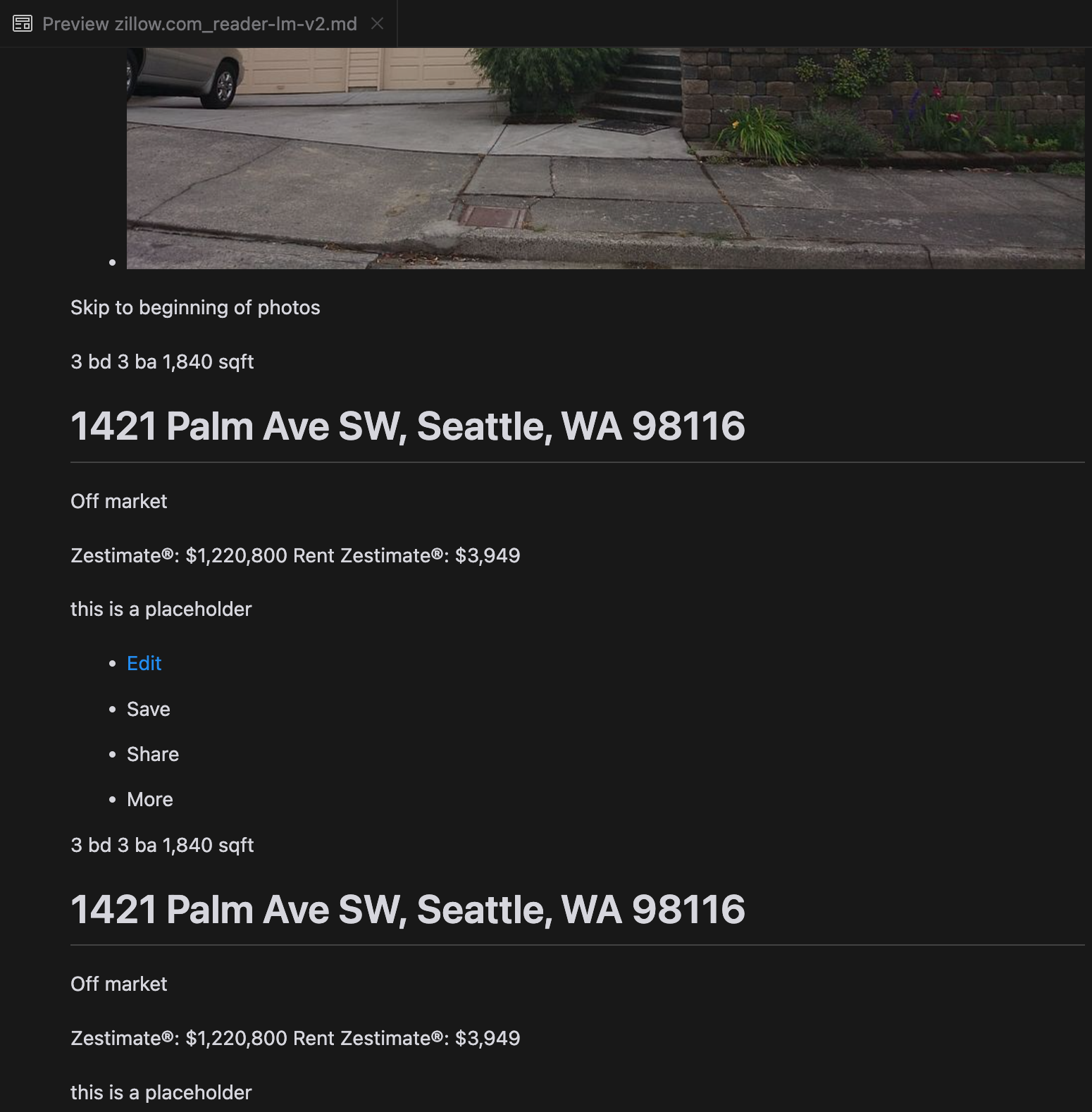
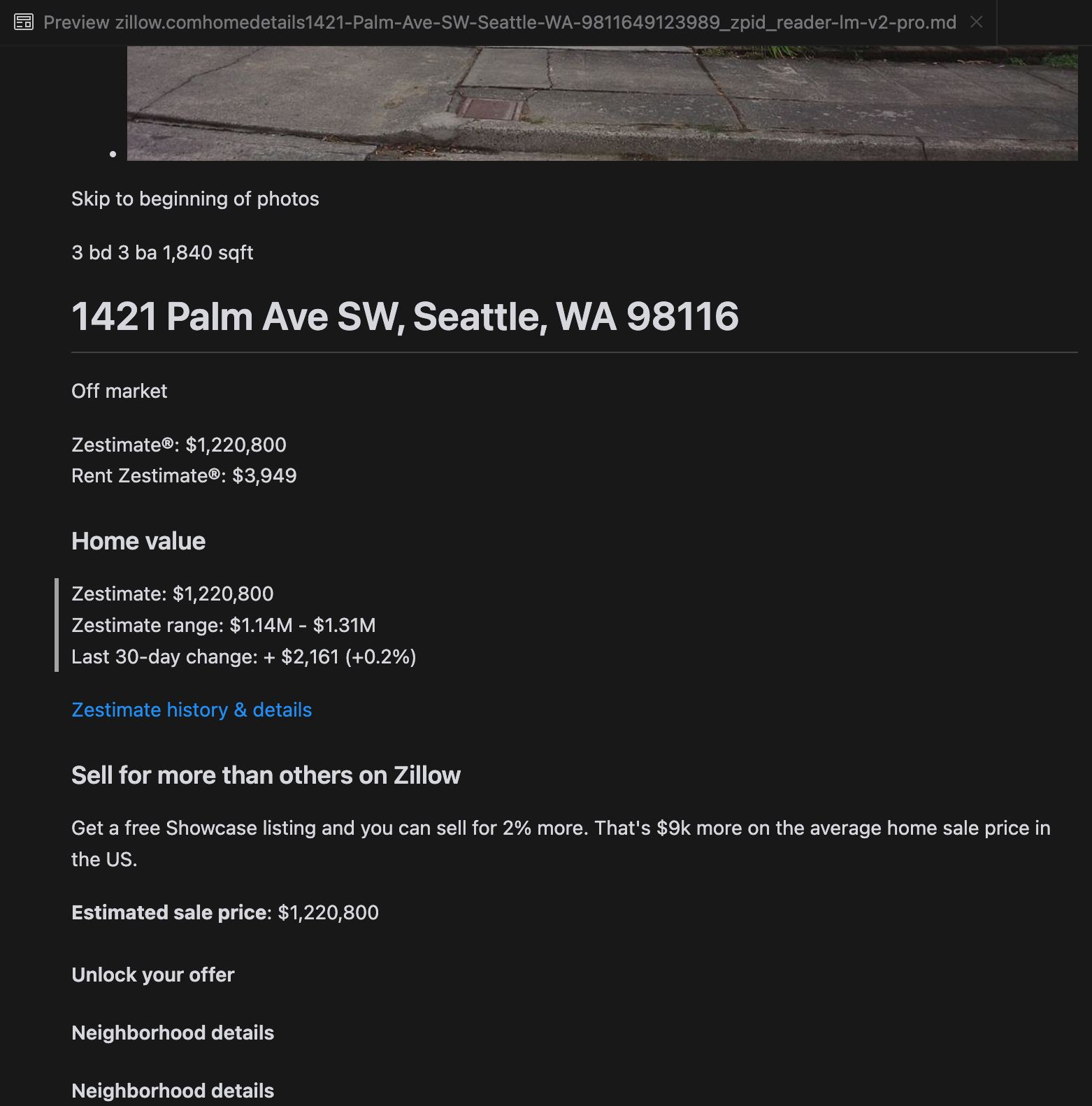
Сравнение rendered Markdown-выводов от gpt-4o (слева), ReaderLM-v2 (в центре) и ReaderLM-v2-pro (справа).
Для некоторых сложных случаев, таких как продуктовые лендинги и правительственные документы, производительность ReaderLM-v2 и ReaderLM-v2-pro оставалась надежной, но все еще есть возможности для улучшения. Сложные математические формулы и код в блог-постах ICLR представляли трудности для большинства моделей, хотя ReaderLM-v2 справлялся с этими случаями лучше, чем базовый Reader API.
tagКак мы обучали ReaderLM v2
ReaderLM-v2 построен на базе Qwen2.5-1.5B-Instruction, компактной базовой модели, известной своей эффективностью в выполнении инструкций и задач с длинным контекстом. В этом разделе мы описываем, как мы обучали ReaderLM-v2, фокусируясь на подготовке данных, методах обучения и встреченных проблемах.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tagПодготовка данных
Успех ReaderLM-v2 во многом зависел от качества тренировочных данных. Мы создали датасет html-markdown-1m, который включал миллион HTML-документов, собранных из интернета. В среднем каждый документ содержал 56 000 токенов, отражая длину и сложность реальных веб-данных. При подготовке этого датасета мы очистили HTML-файлы, удалив ненужные элементы, такие как JavaScript и CSS, сохранив при этом ключевые структурные и семантические элементы. После очистки мы использовали Jina Reader для конвертации HTML-файлов в Markdown, используя регулярные выражения и эвристики.
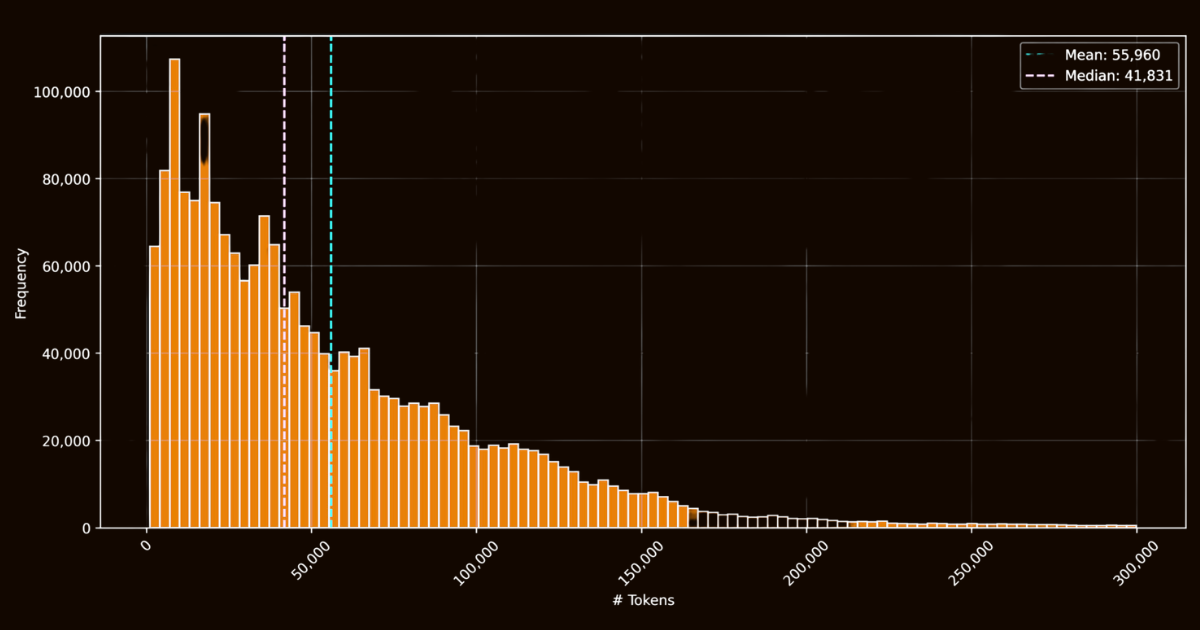
html-markdown-1mХотя это создало функциональный базовый датасет, это выявило критическое ограничение: модели, обученные исключительно на этих прямых преобразованиях, по сути, просто учились имитировать регулярные выражения и эвристики, используемые Jina Reader. Это стало очевидным с моделями reader-lm-0.5b/1.5b, чей потолок производительности был ограничен качеством этих правило-основанных преобразований.
Чтобы решить эти ограничения, мы разработали трехэтапный конвейер, основанный на модели Qwen2.5-32B-Instruction, который важен для создания высококачественного синтетического датасета.

Qwen2.5-32B-Instruction- Черновик: Мы генерировали начальные Markdown и JSON выводы на основе предоставленных модели инструкций. Эти выводы, хотя и разнообразные, часто были шумными или непоследовательными.
- Уточнение: Сгенерированные черновики улучшались путем удаления избыточного контента, обеспечения структурной согласованности и приведения в соответствие с желаемыми форматами. Этот шаг обеспечивал чистоту данных и соответствие требованиям задачи.
- Критика: Уточненные выводы оценивались на соответствие исходным инструкциям. Только данные, прошедшие эту оценку, включались в финальный датасет. Этот итеративный подход обеспечивал соответствие тренировочных данных необходимым стандартам качества для структурированного извлечения данных.
tagПроцесс обучения
Наш процесс обучения включал множество этапов, адаптированных к проблемам обработки документов с длинным контекстом.
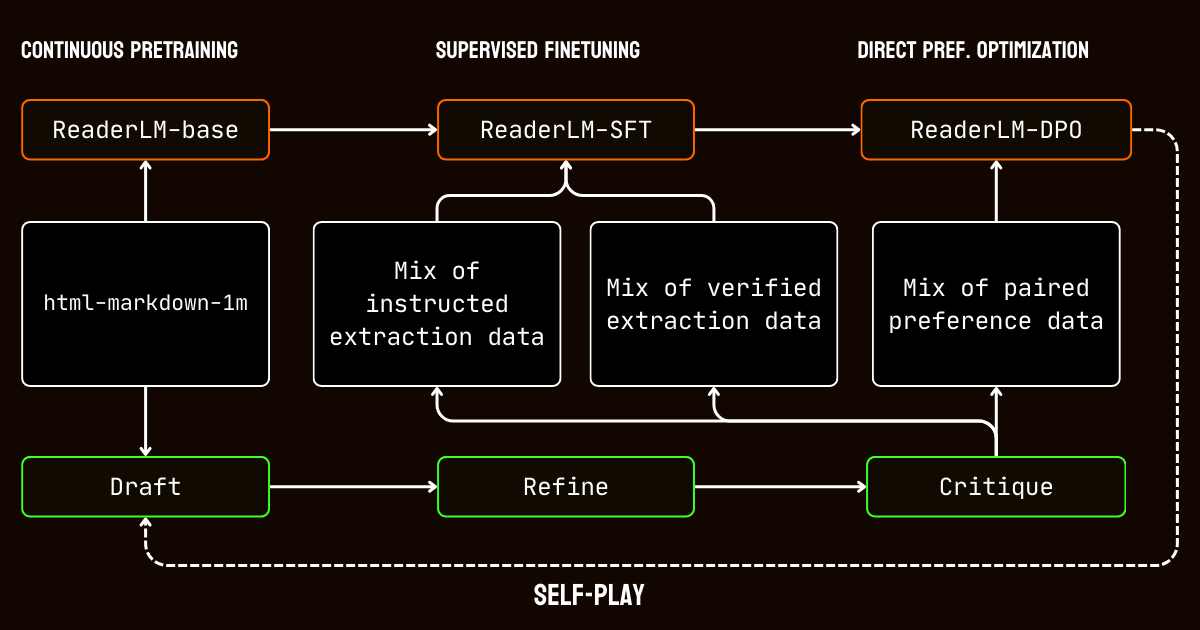
Мы начали с предварительного обучения на длинном контексте, используя датасет html-markdown-1m. Для постепенного расширения контекстной длины модели с 32 768 токенов до 256 000 токенов использовались такие техники, как ring-zag attention и rotary positional encoding (RoPE). Для поддержания стабильности и эффективности мы приняли постепенный подход к обучению, начиная с более коротких последовательностей и постепенно увеличивая длину контекста.
После предварительного обучения мы перешли к supervised fine-tuning (SFT). На этом этапе использовались уточненные датасеты, созданные в процессе подготовки данных. Эти датасеты включали подробные инструкции для задач извлечения Markdown и JSON, а также примеры для уточнения черновиков. Каждый датасет был тщательно разработан, чтобы помочь модели изучить конкретные задачи, такие как определение основного содержания или соблюдение структур JSON на основе схем.
Затем мы применили direct preference optimization (DPO) для приведения выводов модели в соответствие с высококачественными результатами. На этом этапе модель обучалась на парах черновых и уточненных ответов. Научившись приоритизировать уточненные выводы, модель усвоила тонкие различия, определяющие отшлифованные и специфичные для задачи результаты.
Наконец, мы внедрили самообучающуюся настройку с подкреплением, итеративный процесс, где модель генерировала, уточняла и оценивала свои собственные выводы. Этот цикл позволил модели постоянно совершенствоваться без необходимости дополнительного внешнего надзора. Используя собственные критические замечания и уточнения, модель постепенно улучшала свою способность создавать точные и структурированные выводы.
tagЗаключение
В апреле 2024 года Jina Reader стал первым LLM-дружественным markdown API. Он задал новый тренд, получил широкое признание сообщества и, что наиболее важно, вдохновил нас на создание малых языковых моделей для очистки и извлечения данных. Сегодня мы снова поднимаем планку с ReaderLM-v2, выполняя обещания, данные в прошлом сентябре: лучшая обработка длинного контекста, поддержка входных инструкций и способность извлекать конкретное содержимое веб-страниц в формат markdown. Мы снова продемонстрировали, что при тщательном обучении и калибровке малые языковые модели могут достигать современной производительности, превосходящей более крупные модели.
В процессе обучения ReaderLM-v2 мы выявили два важных наблюдения. Одной эффективной стратегией было обучение специализированных моделей на отдельных датасетах, адаптированных под конкретные задачи. Эти специализированные по задачам модели позже объединялись с использованием линейной интерполяции параметров. Хотя этот подход требовал дополнительных усилий, он помог сохранить уникальные сильные стороны каждой специализированной модели в финальной объединенной системе.
Итеративный процесс синтеза данных оказался ключевым для успеха нашей модели. Благодаря многократному улучшению и оценке синтетических данных мы значительно повысили производительность модели по сравнению с простыми подходами на основе правил. Эта итеративная стратегия, хотя и представляла сложности в поддержании согласованности оценок критики и управлении вычислительными затратами, была необходима для преодоления ограничений использования обучающих данных на основе регулярных выражений и эвристик из Jina Reader. Это наглядно демонстрируется разницей в производительности между reader-lm-1.5b, которая сильно полагается на преобразования на основе правил Jina Reader, и ReaderLM-v2, которая выигрывает от этого итеративного процесса улучшения.
Мы с нетерпением ждем ваших отзывов о том, как ReaderLM-v2 улучшает качество ваших данных. В дальнейшем мы планируем расширить мультимодальные возможности, особенно для сканированных документов, и дополнительно оптимизировать скорость генерации. Если вы заинтересованы в получении специальной версии ReaderLM, адаптированной под вашу конкретную область, пожалуйста, свяжитесь с нами.
