


2024 年 4 月,我们推出了 Jina Reader,这是一个 API,只需在 URL 前添加 r.jina.ai 前缀,即可将任何网页转换为 LLM 友好的 markdown。2024 年 9 月,我们推出了两个专门用于将原始 HTML 转换为整洁 markdown 的小型语言模型:reader-lm-0.5b 和 reader-lm-1.5b。今天,我们很高兴推出 ReaderLM 的第二代,这是一个 1.5B 参数的语言模型,可以将原始 HTML 转换为格式精美的 markdown 或 JSON,具有更高的准确性和更好的长文本处理能力。ReaderLM-v2 可处理高达 512K 个 token 的输入和输出组合长度。该模型支持 29 种语言,包括英语、中文、日语、韩语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、越南语、泰语、阿拉伯语等。
得益于其新的训练范式和更高质量的训练数据,ReaderLM-v2 较其前代产品有了重大进步,特别是在处理长文本内容和生成 markdown 语法方面。虽然第一代将 HTML 转 markdown 的转换视为一个"选择性复制"任务,但v2 将其视为真正的翻译过程。这种转变使模型能够熟练运用 markdown 语法,擅长生成代码框、嵌套列表、表格和 LaTex 方程式等复杂元素。
对比 ReaderLM v2、ReaderLM 1.5b、Claude 3.5 Sonnet 和 Gemini 2.0 Flash 在处理 HackerNews 首页 HTML 转 markdown 的结果,展示了 ReaderLM v2 的独特风格和性能。ReaderLM v2 擅长从原始 HTML 中保留完整信息,包括原始 HackerNews 链接,同时巧妙地使用 markdown 语法来构建内容。该模型使用嵌套列表来组织局部元素(点赞数、时间戳和评论),同时通过适当的标题层次结构(h1 和 h2 标签)保持全局格式的一致性。
我们第一个版本的一个主要挑战是生成长序列后的退化问题,特别是表现为重复和循环。模型要么开始重复相同的 token,要么陷入循环,在短序列的 token 中循环,直到达到最大输出长度。ReaderLM-v2 通过在训练过程中添加对比损失极大地缓解了这个问题——无论上下文长度或已生成的 token 数量如何,其性能都保持一致。

除了 markdown 转换之外,ReaderLM-v2 还引入了直接 HTML 转 JSON 生成功能,允许用户根据给定的 JSON 架构从原始 HTML 中提取特定信息。这种端到端的方法消除了许多 LLM 驱动的数据清理和提取管道中常见的中间 markdown 转换需求。

在定量和定性基准测试中,ReaderLM-v2 在 HTML 转 Markdown 任务上的表现优于 Qwen2.5-32B-Instruct、Gemini2-flash-expr 和 GPT-4o-2024-08-06 等更大的模型,同时在 HTML 转 JSON 提取任务上展现出相当的性能,而且使用的参数量明显更少。

ReaderLM-v2-pro 是为我们的企业客户提供的独家高级检查点,具有额外的训练和优化。


这些结果表明,一个设计良好的 1.5B 参数模型不仅能够匹配,而且经常能够在结构化数据提取任务中超越更大的模型。从 ReaderLM-v2 到 ReaderLM-v2-pro 的渐进式改进展示了我们新训练策略在提高模型性能的同时保持计算效率方面的有效性。
tag开始使用
tag通过 Reader API

ReaderLM-v2 现已集成到我们的 Reader API 中。要使用它,只需在请求头中指定 x-engine: readerlm-v2 并通过 -H 'Accept: text/event-stream' 启用响应流式传输:
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
你可以在较低的速率限制下无需 API 密钥即可试用。如需更高的速率限制,你可以购买 API 密钥。请注意,ReaderLM-v2 请求会消耗正常令牌数量的 3 倍 API 密钥配额。该功能目前处于测试阶段,我们正在与 GCP 团队合作优化 GPU 效率并提高模型可用性。
tag在 Google Colab 上使用

注意,免费的 T4 GPU 有一些限制—它不支持 bfloat16 或 flash attention 2,这会导致更高的内存使用和更慢的长输入处理速度。尽管如此,ReaderLM v2 在这些限制下仍然成功处理了我们的整个法律页面,实现了每秒 67 个输入令牌和每秒 36 个输出令牌的处理速度。对于生产环境,我们建议使用 RTX 3090/4090 以获得最佳性能。
在托管环境中尝试 ReaderLM-v2 最简单的方法是通过我们的 Colab notebook,它展示了使用 HackerNews 首页作为示例的 HTML 转 Markdown 转换、JSON 提取和指令遵循。这个 notebook 针对 Colab 的免费 T4 GPU 层级进行了优化,需要 vllm 和 triton 来加速和运行。你可以随意用任何网站来测试。
HTML 转 Markdown 转换
你可以使用 create_prompt 辅助函数轻松创建用于将 HTML 转换为 Markdown 的提示:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result 将是一个用 Markdown 反引号作为代码围栏包裹的字符串。你也可以覆盖默认设置来探索不同的输出,例如:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()然而,由于我们的训练数据可能并未涵盖每种类型的指令,特别是需要多步推理的任务,最可靠的结果来自 HTML 转 Markdown 转换。为了最有效地提取信息,我们建议使用如下所示的 JSON Schema:
使用 JSON Schema 进行 HTML 转 JSON 提取
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result 将是一个用 JSON 格式的代码围栏反引号包裹的字符串,而不是实际的 JSON/dict 对象。你可以使用 Python 将字符串解析成适当的字典或 JSON 对象以进行进一步处理。
tag生产环境:在 CSP 上可用
ReaderLM-v2 在 AWS SageMaker、Azure 和 GCP marketplace 上均可使用。如果你需要在这些平台之外或在公司内部本地使用这些模型,请注意该模型和 ReaderLM-v2-pro 都是在 CC BY-NC 4.0 许可下发布的。如需商业使用咨询或获取 ReaderLM-v2-pro 的访问权限,请随时联系我们。

tag定量评估
我们在三个结构化数据抽取任务上对比 ReaderLM-v2 和最先进的模型:GPT-4o-2024-08-06、Gemini2-flash-expr 和 Qwen2.5-32B-Instruct。我们的评估框架结合了衡量内容准确性和结构保真度的指标。ReaderLM-v2 是公开可用的开源版本,而 ReaderLM-v2-pro 是为我们的企业客户提供的专属高级版本,具有额外的训练和优化。注意,我们的第一代 reader-lm-1.5b 仅在主要内容抽取任务上进行评估,因为它不支持指令抽取或 JSON 抽取功能。
tag评估指标
对于 HTML 转 Markdown 任务,我们采用七个互补的指标。注:↑表示越高越好,↓表示越低越好
- ROUGE-L (↑):测量生成文本与参考文本之间的最长公共子序列,反映内容保留和结构相似性。范围:0-1,数值越高表示序列匹配越好。
- WER(词错误率) (↓):量化将生成文本转换为参考文本所需的最小词级编辑次数。值越低表示需要的修正越少。
- SUB(替换) (↓):计算所需的词替换次数。值越低表示词级准确度越高。
- INS(插入) (↓):测量需要插入多少词才能匹配参考文本。值越低表示完整性越好。
- Levenshtein 距离 (↓):计算所需的最小字符级编辑次数。值越低表示字符级准确度越高。
- Damerau-Levenshtein 距离 (↓):类似于 Levenshtein,但也考虑字符转置。值越低表示字符级匹配越好。
- Jaro-Winkler 相似度 (↑):强调字符串开头的匹配,特别适用于评估文档结构保留。范围:0-1,值越高表示相似度越好。
对于 HTML 转 JSON 任务,我们将其视为检索任务,采用信息检索中的四个指标:
- F1 分数 (↑):精确率和召回率的调和平均值,提供整体准确度。范围:0-1。
- 精确率 (↑):所有抽取中正确抽取的比例。范围:0-1。
- 召回率 (↑):在所有可用信息中正确抽取的比例。范围:0-1。
- 通过率 (↑):输出为有效 JSON 且符合模式的比例。范围:0-1。
tag主要内容 HTML 转 Markdown 任务
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
tag指令型 HTML 转 Markdown 任务
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
tag基于 Schema 的 HTML 转 JSON 任务
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 在所有任务中都表现出显著进步。在主要内容抽取方面,ReaderLM-v2-pro 在七个指标中的五个上取得了最佳性能,拥有更优的 ROUGE-L(0.86)、WER(0.39)、Levenshtein(0.20)、Damerau(928.15)和 Jaro-Winkler(0.83)分数。这些结果表明,与其基础版本和更大的模型相比,在内容保留和结构准确性方面都有全面的改进。
在指令型抽取任务中,ReaderLM-v2 和 ReaderLM-v2-pro 在 ROUGE-L(0.72)、替换率(70.16)、Levenshtein 距离(0.37)和 Jaro-Winkler 相似度(0.75,与基础版本并列)等指标上领先。尽管 GPT-4o 在 WER 和 Damerau 距离上有优势,但 ReaderLM-v2-pro 在整体内容结构和准确性方面表现更好。在 JSON 抽取方面,该模型表现具有竞争力,F1 分数与更大模型的差距仅为 0.01-0.02,同时保持较高的通过率(0.99)。
tag定性评估
在我们分析在评估 reader-lm-1.5b 时,我们注意到量化指标alone可能无法完全衡量模型性能。数值评估有时无法反映感知质量——在某些情况下,低指标分数产生的 Markdown 在视觉上令人满意,而高分数却产生次优结果。为了解决这种差异,我们对 10 个不同的 HTML 源进行了系统的定性评估,包括英文、日文和中文的新闻文章、博客文章、产品页面、电子商务网站和法律文档。测试语料库强调了具有挑战性的格式元素,如多行表格、动态布局、LaTeX 公式、链接表格和嵌套列表,从而提供了对模型实际应用能力更全面的视角。
tag评估指标
我们的人工评估关注三个关键维度,输出按 1-5 分制评分:
内容完整性 - 评估 HTML 转 Markdown 过程中语义信息的保留程度,包括:
- 文本内容的准确性和完整性
- 链接、图片、代码块、公式和引用的保留
- 文本格式和链接/图片 URL 的保留
结构准确性 - 评估 HTML 结构元素到 Markdown 的准确转换:
- 标题层次的保留
- 列表嵌套的准确性
- 表格结构的保真度
- 代码块和引用的格式
格式规范性 - 衡量对 Markdown 语法标准的遵守程度:
- 标题(#)、列表(*、+、-)、表格、代码块(```)的正确语法使用
- 没有多余空格或非标准语法的整洁格式
- 一致且可读的渲染输出
在我们手动评估超过 10 个 HTML 页面时,每个评估标准的最高分为 50 分。ReaderLM-v2 在所有维度上都表现出色:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
在内容完整性方面,它在复杂元素识别方面表现出色,特别是 LaTeX 公式、嵌套列表和代码块。该模型在处理复杂内容结构时保持了高保真度,而竞争模型经常出现丢失 H1 标题(reader-lm-1.5b)、截断内容(Claude 3.5)或保留原始 HTML 标签(Gemini-2.0-flash)等问题。
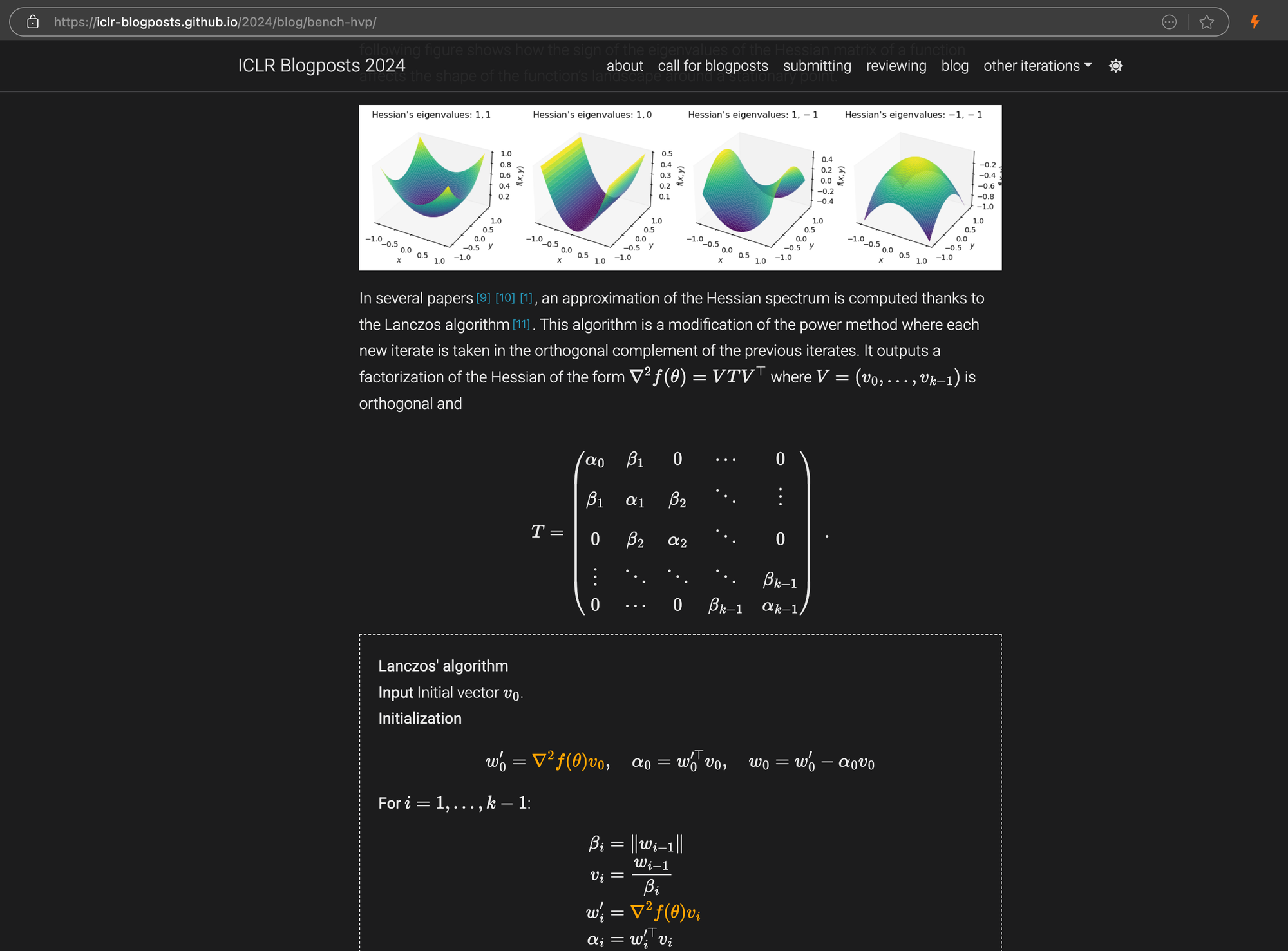
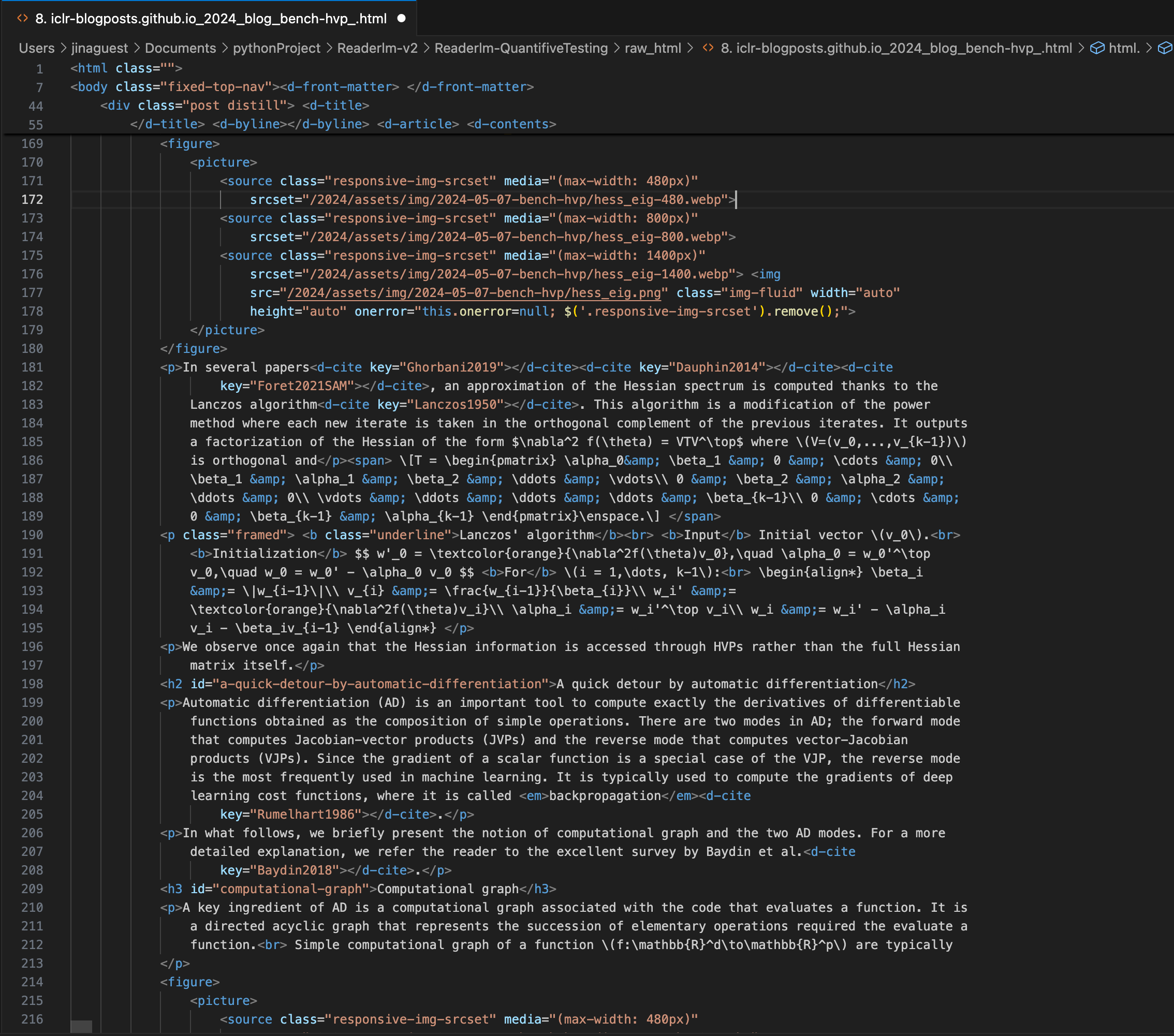
一篇 ICLR 博客文章,其中包含嵌入在 Markdown 中的复杂 LaTeX 方程,右侧面板显示源 HTML 代码。
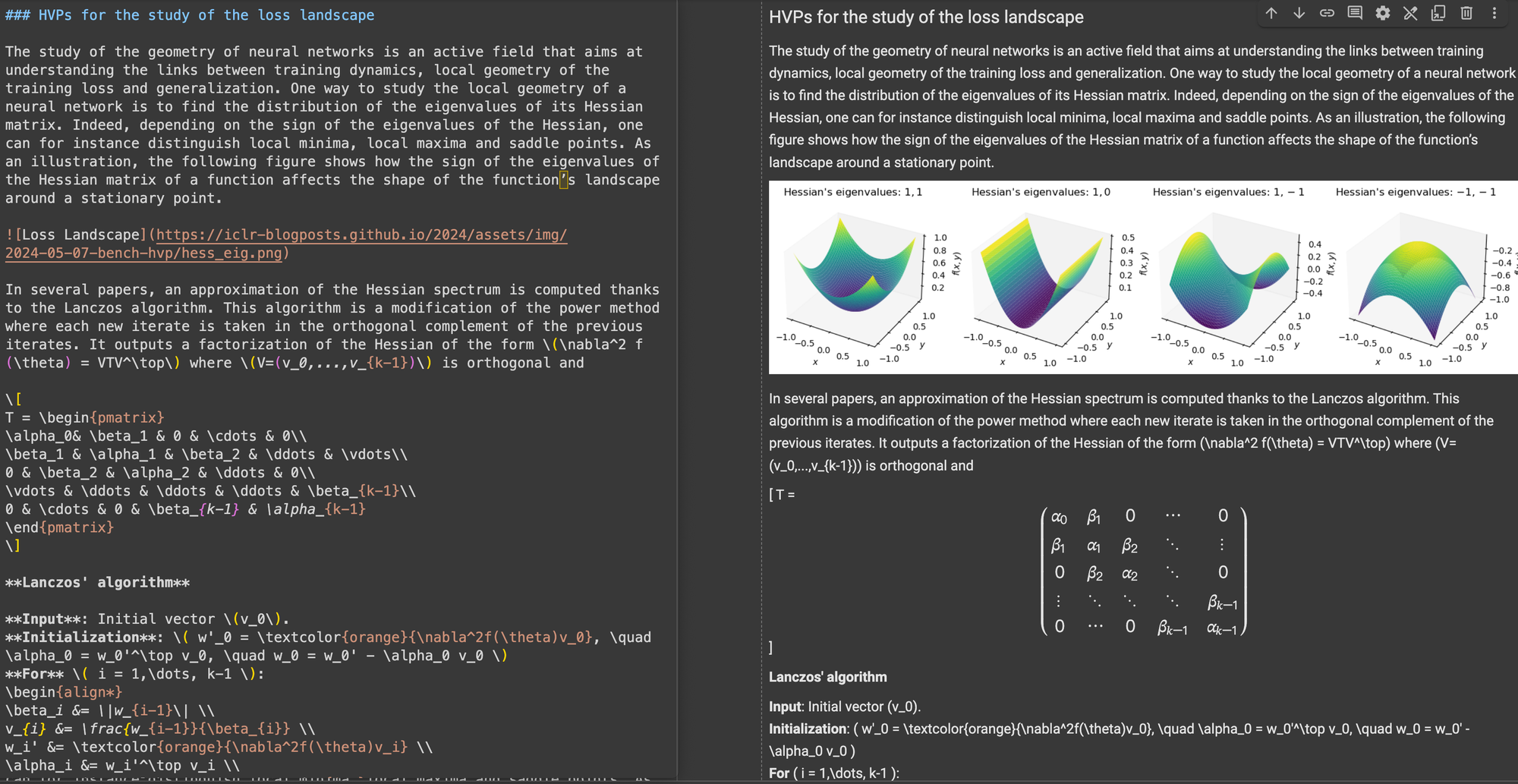
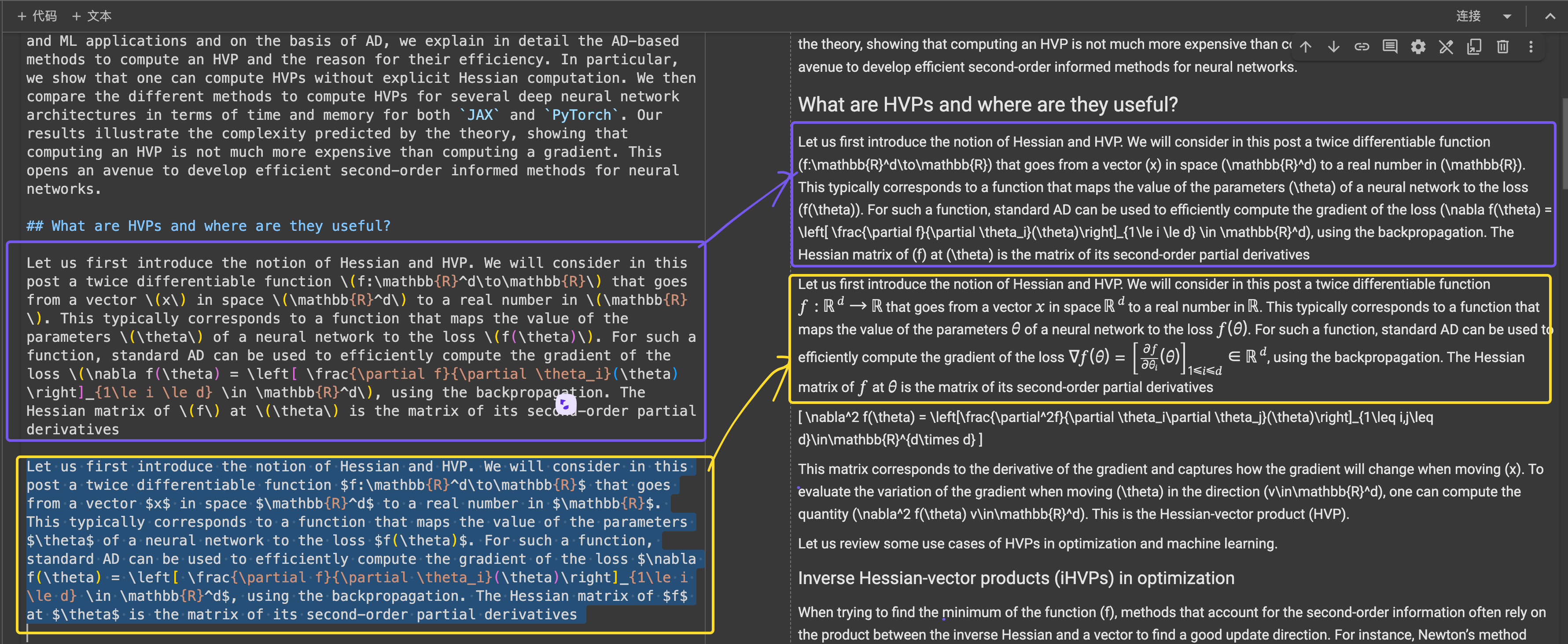
\[...\](及其 HTML 等价物)替换为 Markdown 标准分隔符,如 $...$ 用于行内方程,$$...$$ 用于显示方程。这有助于防止 Markdown 解释中的语法冲突。在结构准确性方面,ReaderLM-v2 显示出对常见网页结构的优化。例如,在 Hacker News 案例中,它成功重建了完整链接并优化了列表呈现。该模型能够处理让 ReaderLM-v1 感到困难的复杂非博客 HTML 结构。
在格式规范性方面,ReaderLM-v2 在处理 Hacker News、博客和微信文章等内容时表现出特别的优势。虽然其他大型语言模型在处理类似 Markdown 的源内容时表现良好,但在需要更多解释和重新格式化的传统网站上却遇到困难。
我们的分析显示,gpt-4o 在处理较短网站时表现出色,与其他模型相比,它对网站结构和格式的理解更为出色。然而,在处理较长内容时,gpt-4o 在完整性方面存在困难,经常遗漏文本的开头和结尾部分。我们以 Zillow 的网站为例,提供了 gpt-4o、ReaderLM-v2 和 ReaderLM-v2-pro 输出的对比分析。
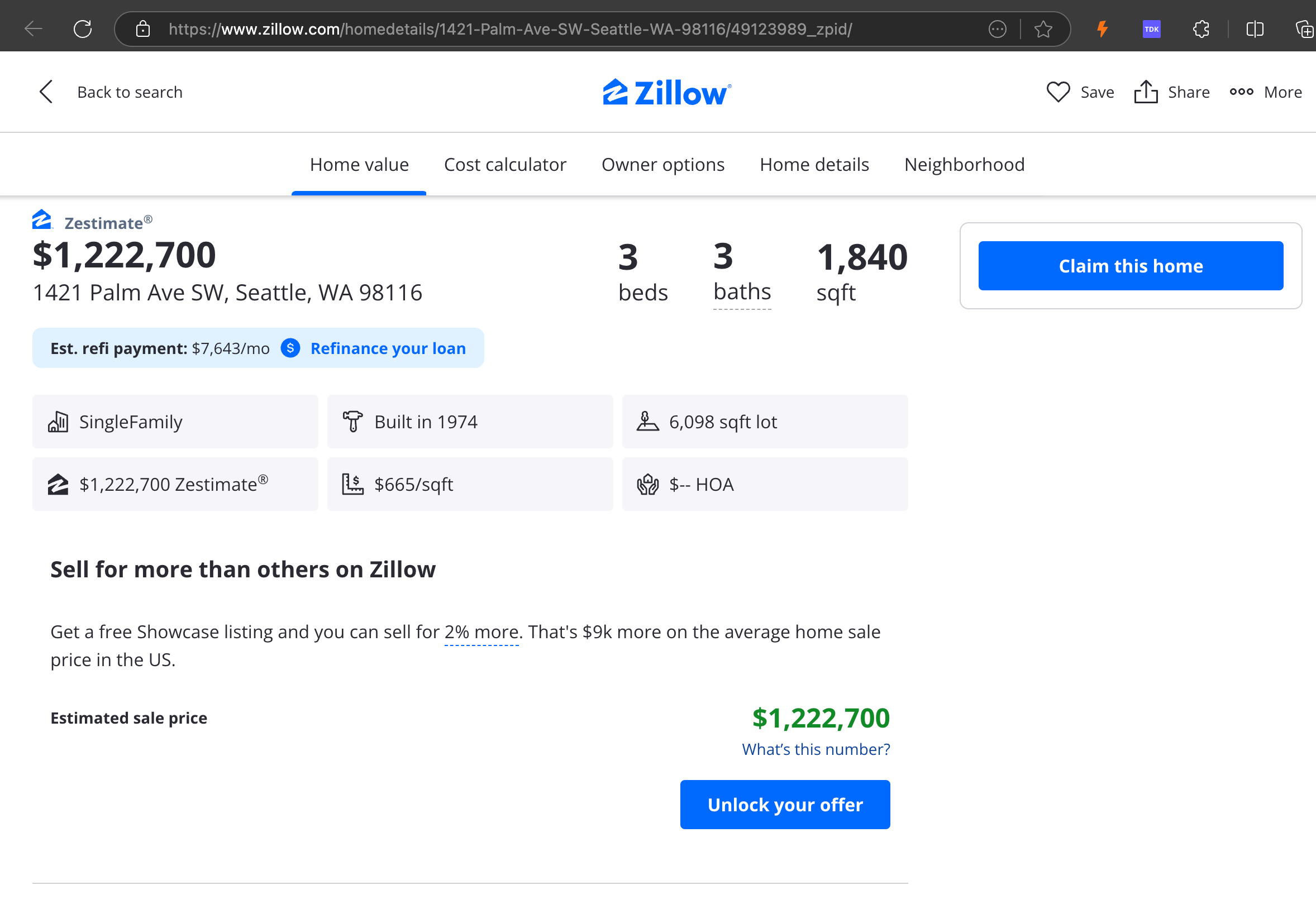
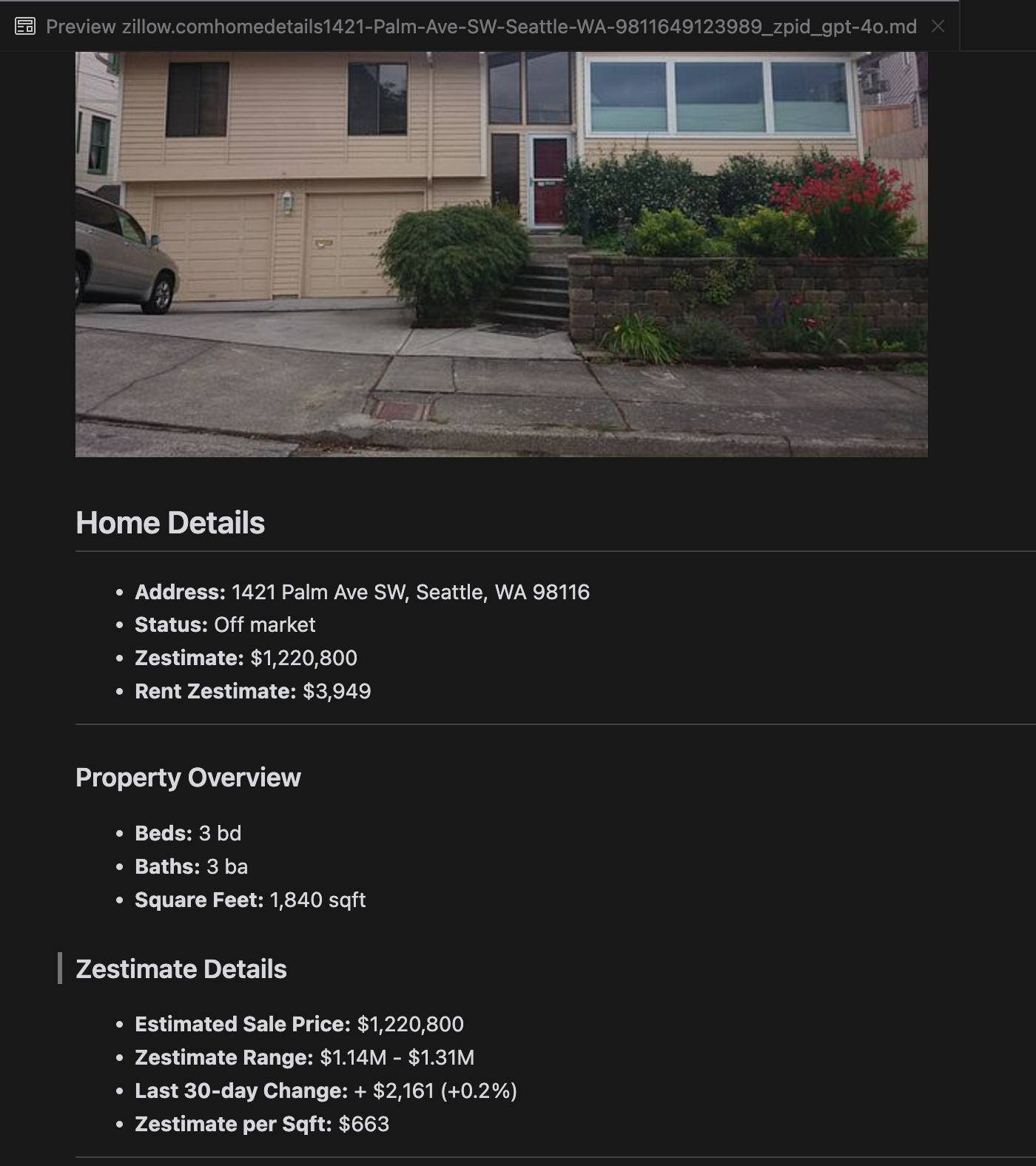
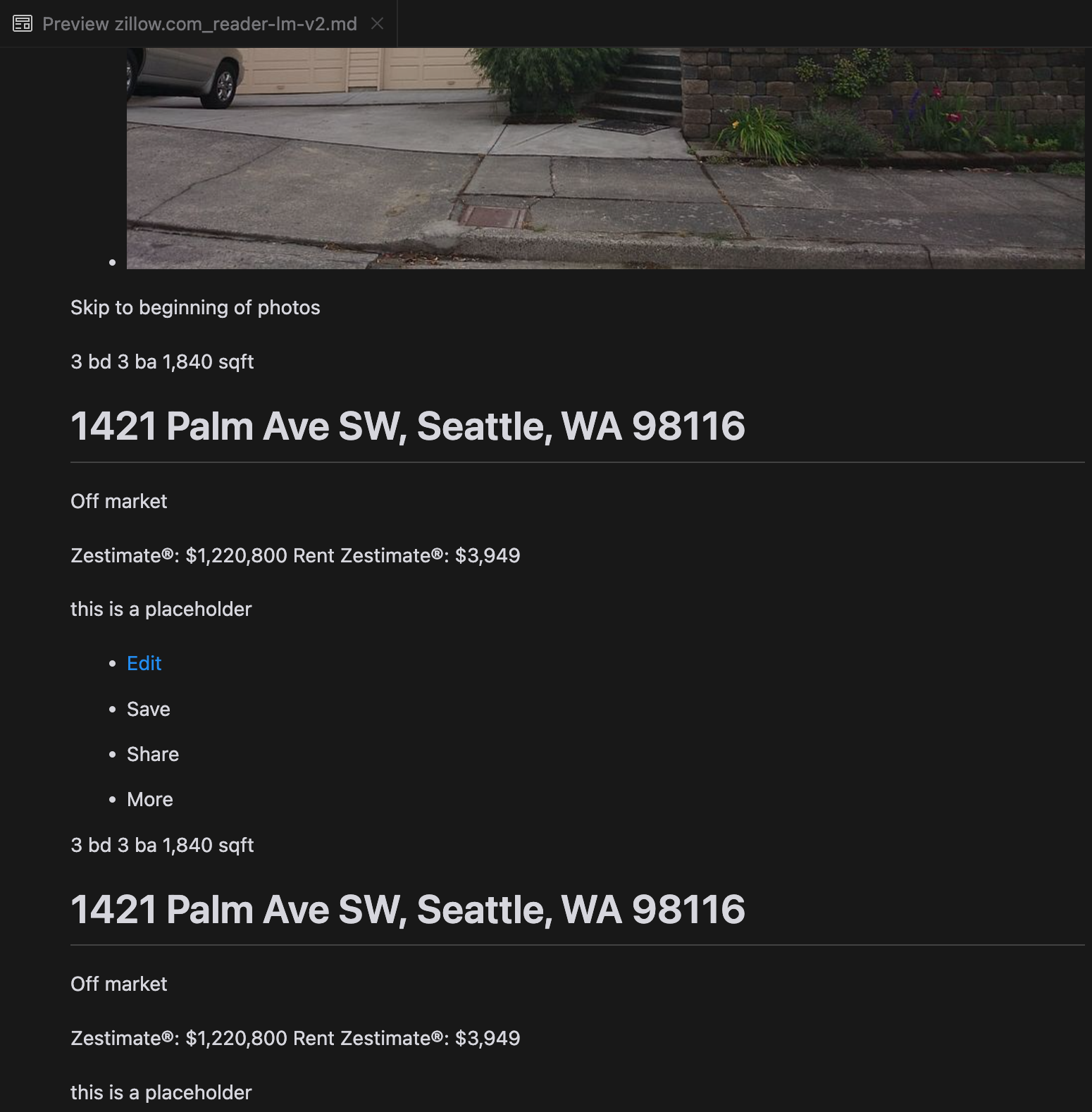
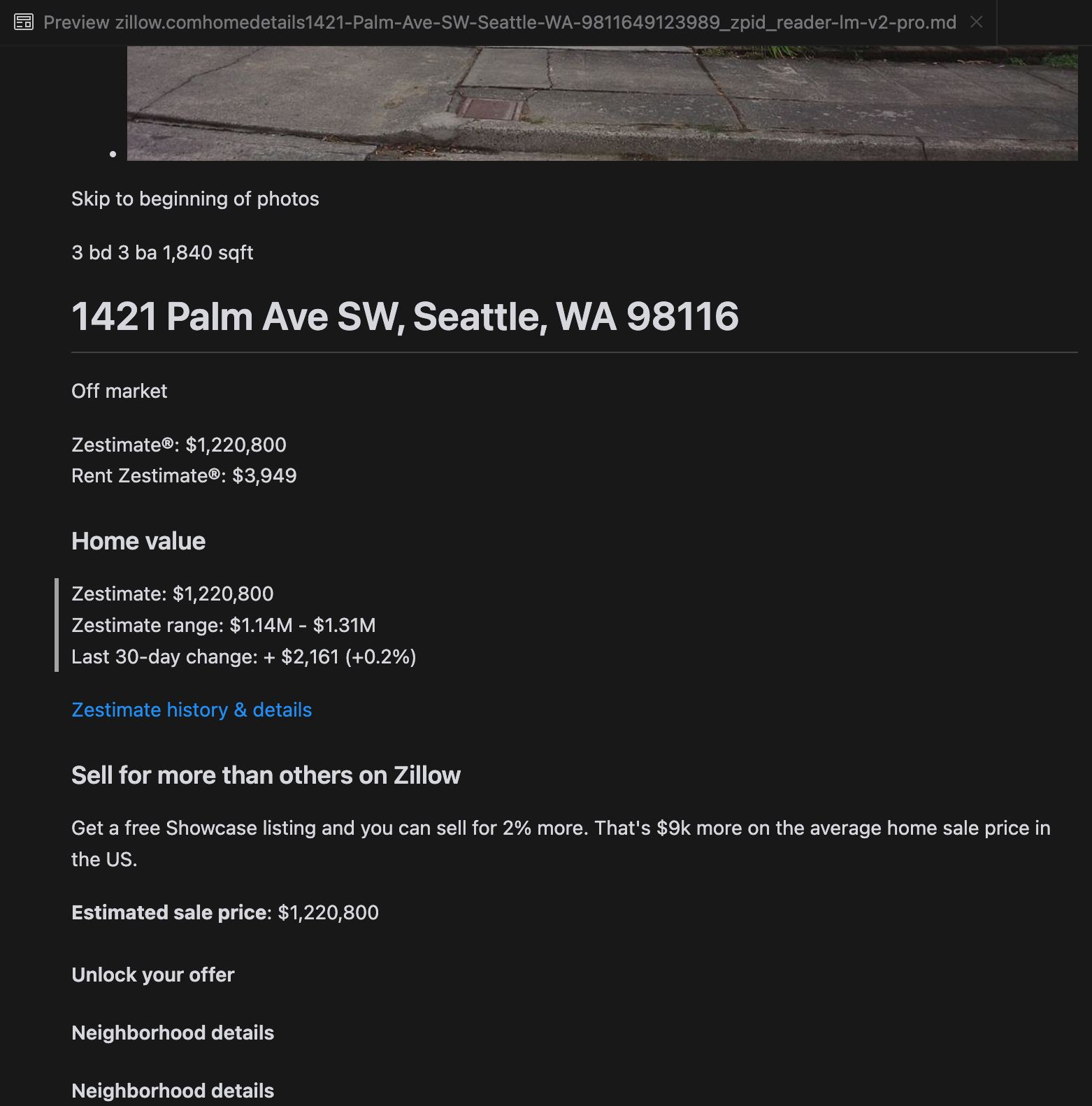
gpt-4o(左)、ReaderLM-v2(中)和 ReaderLM-v2-pro(右)渲染的 Markdown 输出对比。
对于某些具有挑战性的案例,如产品落地页和政府文档,ReaderLM-v2 和 ReaderLM-v2-pro 的表现保持稳健,但仍有提升空间。对于 ICLR 博客文章中的复杂数学公式和代码,大多数模型都面临挑战,不过 ReaderLM-v2 在处理这些情况时比基准 Reader API 表现更好。
tag我们如何训练 ReaderLM v2
ReaderLM-v2 基于 Qwen2.5-1.5B-Instruction 构建,这是一个以指令遵循和长上下文任务效率著称的紧凑型基础模型。在本节中,我们将描述如何训练 ReaderLM-v2,重点关注数据准备、训练方法和我们遇到的挑战。
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
tag数据准备
ReaderLM-v2 的成功在很大程度上取决于其训练数据的质量。我们创建了 html-markdown-1m 数据集,其中包含从互联网收集的一百万个 HTML 文档。平均而言,每个文档包含 56,000 个词元,反映了真实网络数据的长度和复杂性。在准备这个数据集时,我们通过删除不必要的元素(如 JavaScript 和 CSS)来清理 HTML 文件,同时保留关键的结构和语义元素。清理后,我们使用 Jina Reader 通过正则表达式模式和启发式方法将 HTML 文件转换为 Markdown。
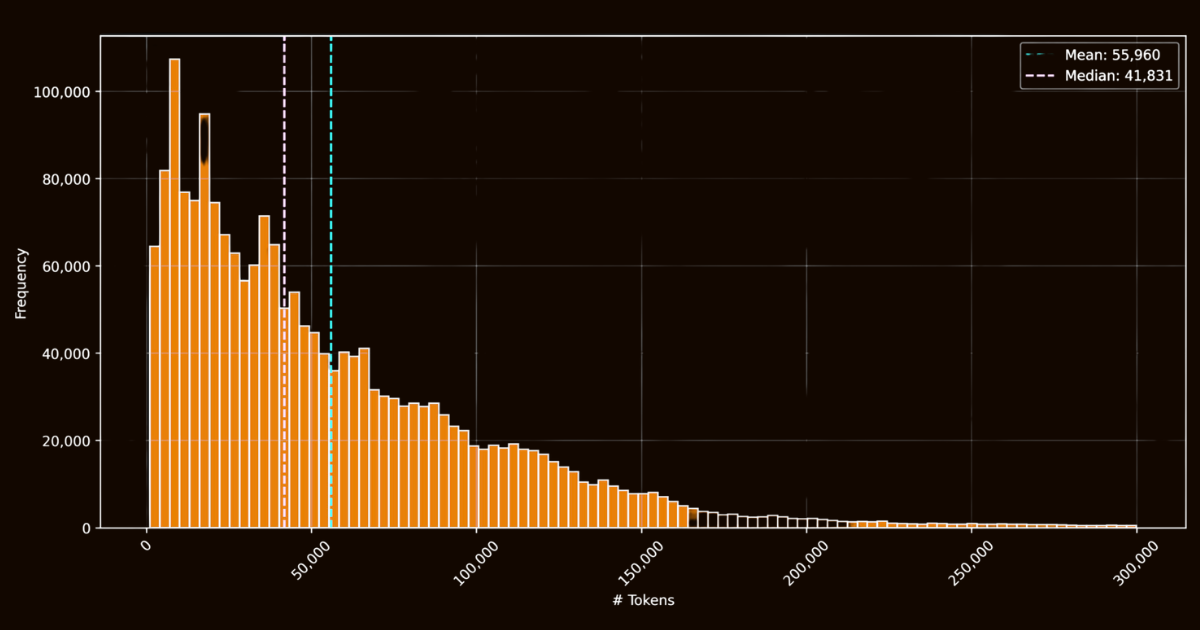
虽然这创建了一个可用的基准数据集,但它突显了一个关键限制:仅在这些直接转换上训练的模型本质上只会学会模仿 Jina Reader 使用的正则表达式模式和启发式方法。这一点在 reader-lm-0.5b/1.5b 中变得很明显,其性能上限受到了这些基于规则的转换质量的限制。
为了解决这些限制,我们开发了一个依赖 Qwen2.5-32B-Instruction 模型的三步流程,这对创建高质量的合成数据集至关重要。

Qwen2.5-32B-Instruction 驱动- 起草:我们基于提供给模型的指令生成初始 Markdown 和 JSON 输出。这些输出虽然多样,但常常包含噪音或不一致。
- 改进:通过删除冗余内容、强化结构一致性并与所需格式对齐来改进生成的草稿。这一步确保数据清洁并符合任务要求。
- 评估:将改进后的输出与原始指令进行评估。只有通过评估的数据才会被纳入最终数据集。这种迭代方法确保训练数据达到结构化数据提取所需的质量标准。
tag训练过程
我们的训练过程包含多个阶段,专门针对处理长上下文文档的挑战。
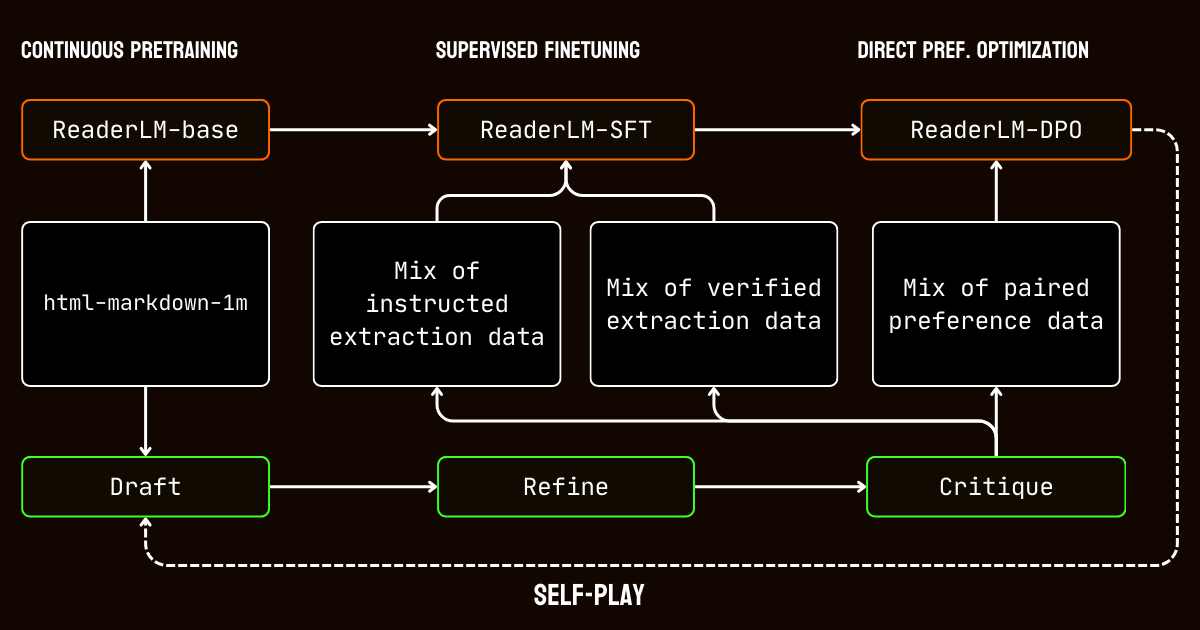
我们首先进行长上下文预训练,使用 html-markdown-1m 数据集。采用了 ring-zag attention 和旋转位置编码(RoPE)等技术,逐步将模型的上下文长度从 32,768 个词元扩展到 256,000 个词元。为了保持稳定性和效率,我们采用了渐进式训练方法,从较短的序列开始,逐步增加上下文长度。
预训练之后,我们进行了有监督微调(SFT)。这个阶段使用了在数据准备过程中生成的精炼数据集。这些数据集包含了 Markdown 和 JSON 提取任务的详细指令,以及用于改进草稿的示例。每个数据集都经过精心设计,以帮助模型学习特定任务,如识别主要内容或遵循基于 schema 的 JSON 结构。
然后,我们应用了直接偏好优化(DPO)来使模型的输出与高质量结果保持一致。在这个阶段,模型在草稿和改进后的响应对上进行训练。通过学习优先选择改进后的输出,模型内化了定义精炼和任务特定结果的细微区别。
最后,我们实施了自我对弈强化调优,这是一个迭代过程,模型生成、改进和评估自己的输出。这个循环使模型能够持续改进,而无需额外的外部监督。通过利用自己的评估和改进,模型逐步提高了生成准确和结构化输出的能力。
tag结论
回顾 2024 年 4 月,Jina Reader 成为第一个对 LLM 友好的 markdown API。它开创了新趋势,赢得了广泛的社区采用,最重要的是,激励我们为数据清理和提取构建小型语言模型。今天,我们再次通过 ReaderLM-v2 提升标准,实现了去年 9 月的承诺:更好的长上下文处理、支持输入指令,以及将特定网页内容提取为 markdown 格式的能力。我们再次证明,通过精心训练和校准,小型语言模型可以达到超越大型模型的最先进性能。
在 ReaderLM-v2 的训练过程中,我们发现了两个洞见。一个有效的策略是在针对特定任务定制的单独数据集上训练专门的模型。这些任务特定模型后来通过线性参数插值进行合并。虽然这种方法需要额外的努力,但它有助于在最终统一系统中保持每个专门模型的独特优势。
迭代式的数据合成过程对我们模型的成功至关重要。通过对合成数据的反复改进和评估,我们显著提升了模型性能,超越了简单的规则based方法。这种迭代策略虽然在保持一致的评价标准和管理计算成本方面带来了挑战,但对于克服使用 Jina Reader 正则表达式和基于启发式的训练数据的局限性来说是必不可少的。这一点从严重依赖 Jina Reader 规则转换的 reader-lm-1.5b 与受益于迭代改进过程的 ReaderLM-v2 之间的性能差距中可以明显看出。
我们很期待听到您关于 ReaderLM-v2 如何改善数据质量的反馈。展望未来,我们计划扩展多模态能力,特别是在扫描文档方面,并进一步优化生成速度。如果您对定制适合特定领域的 ReaderLM 版本感兴趣,请随时与我们联系。




