


像很多人一樣,我也聽很多 Podcast。有些是關於科幻小說的。有些是關於古生物學的。還有一些是關於中世紀奇人軼事的。可惜沒有真實犯罪類的,除了我偶爾品味欠佳的選擇。
但是...聽這麼多 Podcast 很累人。而且這還不是最糟的。我還訂閱了很多新聞 Feed。這意味著要讀很多內容。如果我能把所有新聞 Feed 的內容整理成五分鐘的摘要,然後在早上刷牙時用手機播放出來,那就太棒了。
你大概猜到接下來要說什麼了。我正在使用 Python 並主要運用 Jina 技術堆疊來打造一個工具,用來製作我的個人化每日新聞 Podcast。
如果你想直接聽聽效果如何,可以收聽以下內容:
tag什麼是新聞 Feed?
首先,我稱它們為"新聞 Feed",因為大多數人不熟悉 RSS 或 Atom Feed 這些術語。簡而言之,Feed 是一個部落格或新聞來源發布的文章結構化列表,按照從新到舊排序。許多網站都提供 Feed,並且有多個應用程式和網站可以讓你匯入所有 Feed,讓你在一個應用程式中閱讀所有新聞,不必分別造訪 Ars Technica、Taylor Swift 粉絲網站和華盛頓郵報的網站:
它們是來自史前網路的古老技術,但許多網站仍支援它們,包括 Jina AI 自己的部落格(這是我們的 Feed)。
簡單來說,Feed 讓你可以在一個地方閱讀所有新聞,跳過所有側邊欄雜物和廣告。在這篇文章中,我們將使用新聞 Feed 來找到並下載我們關注的網站的最新文章。
tag讓我們開始這場 Feed 盛宴
要實現這個魔法,我們將使用幾個服務和 Python 函式庫:
- Feedparser:一個用於下載和提取新聞訂閱內容的 Python 函式庫。
- Jina Reader:Jina 的 API,用於只提取每篇文章的內容,不下載頁首、頁尾和側邊欄等無用內容。
- PromptPerfect:Prompts-as-Services 將總結每篇文章,然後將這些摘要合併成一段文字,風格類似於 NPR 新聞主播。
- gTTS:Google 的文字轉語音函式庫,用於朗讀新聞報導。
這就是本文要涵蓋的全部內容。如果您想為您的個人播客創建播客訂閱,我們建議您查看其他資源。
tag下載訂閱源
由於這只是一個簡單的範例,我們將只使用 The Register 和 OSNews 這兩個科技新聞網站的訂閱源。
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]使用 Feedparser,我們可以下載訂閱源,然後從每個訂閱源中下載文章連結:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tag使用 Jina Reader 提取文章文本
每個訂閱源包含相關網站上每篇文章的連結。如果我們直接下載網頁,會得到大量的 HTML,包括側邊欄、頁首、頁尾和其他我們不需要的內容。如果你把這些餵給 LLM,就像你在嚼草一樣。沒錯,LLM 可以處理,但這不是它天生想要吃的東西。
LLM 真正想要的是接近純文本的內容。Jina Reader 將文章轉換為 Markdown。

這樣它看起來就像這樣:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...我們縮短了這個內容,因為包含整篇文章太冗長了。但你可以看到它是清晰的、人類可讀的(markdown)文本。
而不是這樣:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...我們不得不在真正進入內容之前就截短了。這裡有太多非人類可讀的雜亂內容。
通過餵給 LLM 它更自然可以消化的內容(比如 markdown 而不是 HTML),它可以給我們更好的輸出。否則就像餵獅子吃多力多滋一樣。沒錯,它可以吃,但如果一直保持這種飲食習慣,就不會發揮出最好的獅子本色。
要以人類可讀的方式僅提取文本,我們將使用 Jina Reader 的 API:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url> 來查看人類可讀的輸出,例如 https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tag使用 PromptPerfect 總結文章
由於可能會有很多文章,我們將使用 LLM 分別總結每一篇。如果我們把它們全部放在一起餵給 LLM 來總結,它可能會因為一次處理太多 token 而卡住。
這將取決於你要處理的文章數量。對於只有幾篇文章的情況,可能值得將它們全部連接成一個長字串並只進行一次呼叫,以節省時間和金錢。但在這個例子中,我們假設我們要處理更多的文章。
為了總結它們,我們將使用來自 PromptPerfect 的 Prompt-as-a-Service。
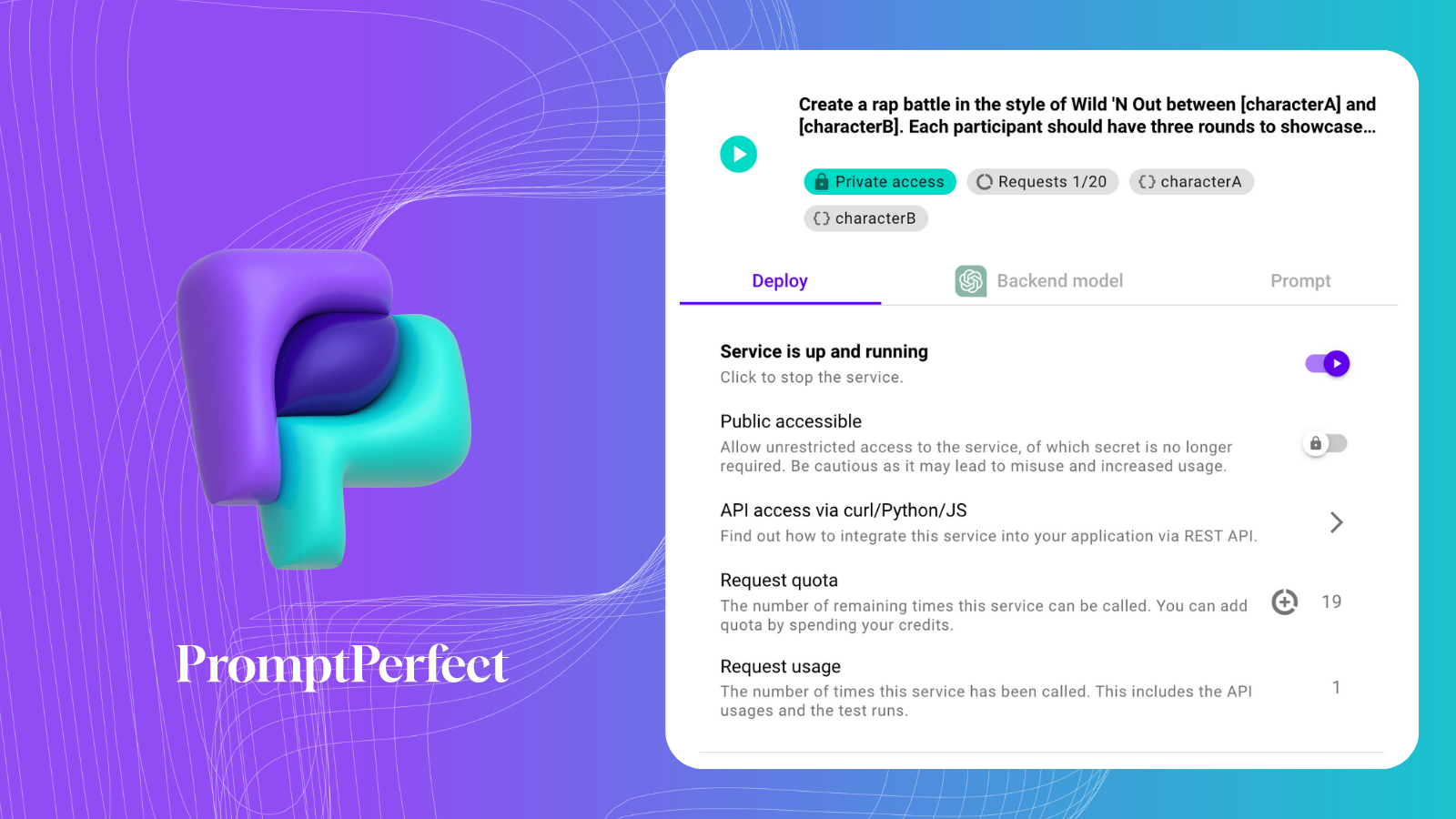
這是我們的 Prompt-as-Service:

由於我們稍後會在這篇文章中呼叫另一個 Prompt-as-Service,所以我們先寫一個函式:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.text然後我們將每個摘要加入到列表中,最後將它們合併成一個帶有項目符號的 markdown 列表:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tag使用 PromptPerfect 生成新聞報導
現在我們已經有了帶有項目符號的列表,我們可以將它發送到另一個 Prompt-as-a-Service,以生成聽起來像是自然新聞播報員語調的新聞報導:

完整的 prompt 如下:
你是一位 NPR 科技新聞編輯。你收到了以下新聞摘要:
[summaries]
你的工作是提供一段新聞概述,以有機的方式涵蓋每個項目,並順暢地過渡到下一個項目。如果合理的話,你可以改變項目的順序,並合併重複的內容。
你將輸出一段用於 NPR 每日新聞的腳本,聽起來要自然流暢,朗讀時間不超過五分鐘。
我們使用這段程式碼來獲取新聞腳本:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)這是最終的文本:
今日科技新聞,我們有一系列更新和發展要討論。首先,Tiny11 Builder 工具讓使用者能夠精簡 Windows 11,創建符合個人偏好的客製化映像檔。接著來到遊戲世界,我們深入探討 Super Nintendo 卡帶內部的隱藏組件,揭示了 90 年代令遊戲玩家著迷的技術。轉向軟體領域,Wayland 的 Niri 平鋪式視窗管理器發布了重大更新,提供無限滾動和改進的動畫等新功能。在 AI 領域,Microsoft 的 Copilot 功能在推送給 Windows Insider 時遇到一些問題,由於出現錯誤和干擾行為而暫停部署。同時,英國資訊委員辦公室對 Google 的 Privacy Sandbox 表示擔憂,質疑其隱私影響和對競爭的衝擊。最後,美國聯邦航空管理局更新了發射許可要求,在 Varda Space Industries 事件之後,現在要求再入載具在發射前必須獲得許可。這些多元的科技故事凸顯了科技世界持續的進展和挑戰。
tag大聲朗讀新聞
要朗讀文本,我們將使用 Google 的 TTS 函式庫。


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")這將為我們生成最終的音訊檔案:
tag後續步驟
我們不會在這篇文章中介紹其餘的播客製作經驗。這不是我們的專長,就像醫療建議一樣,當涉及到設立播客 feed、上傳到 Spotify、Apple Podcasts 等細節時,你可能不應該聽我們的。關於醫療或播客建議,請分別諮詢你的醫生或 Joe Rogan。
至於 Jina Reader 還能做什麼,想想通過下載任何網頁的可讀版本,你可以創建多少 RAG 應用。或者對於 PromptPerfect,看看它如何進一步幫助 YouTuber(或者如果你喜歡的話,幫助行銷人員)。
