

和很多人一样,我听了很多播客。有一些是关于科幻小说的。有一些是关于古生物学的。还有一些是关于中世纪奇人奇事的。很遗憾没有犯罪类的,除非算上我偶尔糟糕的品味。
但是...听这么多播客很费劲。而且这还不是最糟糕的。我还订阅了很多新闻源。这意味着要读很多内容。如果能把所有这些新闻源的内容整理成五分钟的摘要,然后在我早上刷牙的时候用手机读给我听,那就太棒了。
你大概猜到我要说什么了。我正在用 Python 构建一个工具,主要使用 Jina 技术栈来创建我的个性化每日新闻播客。
如果你想直接听听效果如何,可以听下面这段:
tag什么是新闻源?
首先,我把它们称为"新闻源",因为大多数人不熟悉 RSS 或 Atom feeds 这些术语。简单来说,feed 是博客或新闻来源发布的文章的结构化列表,按时间从新到旧排序。许多网站都提供这种服务,而且有很多应用和网站可以让你导入所有 feeds,让你在一个应用中阅读所有新闻,而不必访问 Ars Technica、Taylor Swift 粉丝网站和华盛顿邮报等网站:
这是来自史前网络的古老技术,但许多网站仍然支持它们,包括 Jina AI 自己的博客(这是我们的 feed)。
简而言之,feeds 让你可以在一个地方阅读所有新闻,跳过所有侧边栏垃圾和广告。在这篇文章中,我们将使用新闻源来查找和下载我们关注的网站的最新文章。
tag让我们开始这场饕餮盛宴
要实现这个功能,我们将使用以下几个服务和 Python 库:
- Feedparser:一个用于下载和提取新闻源内容的 Python 库。
- Jina Reader:Jina 的 API,用于仅提取每篇文章的主体内容,而不下载页眉、页脚和侧边栏等无用内容。
- PromptPerfect:Prompts-as-Services 将对每篇文章进行总结,然后将这些摘要合并成一段,采用 NPR 新闻播报员的风格。
- gTTS:Google 的文字转语音库,用于朗读新闻报道。
这就是本文要介绍的全部内容。如果你想为个性化播客创建播客源,建议查看其他资源。
tag下载订阅源
由于这只是一个简单的示例,我们只使用 The Register 和 OSNews 这两个科技新闻网站的订阅源。
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]使用 Feedparser,我们可以下载订阅源,然后从每个订阅源中下载文章链接:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])tag使用 Jina Reader 提取文章文本
每个订阅源都包含指向相关网站上各个文章的链接。如果我们直接下载网页,会得到大量 HTML 内容,包括侧边栏、页眉、页脚和其他不需要的内容。如果你将这些内容输入到 LLM,就像让你去嚼草一样。虽然 LLM 可以"处理"它,但这并不是它想要接收的自然输入。
LLM 真正想要的是接近纯文本的内容。Jina Reader 可以将文章转换为 Markdown。

这样它看起来就会像这样:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...我们缩短了内容,因为包含整篇文章会太长。但你可以看到,这是清晰的、人类可读的(markdown)文本。
而不是这样:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...我们在甚至还没到实际内容时就不得不缩短了。这里有太多非人类可读的无用内容。
通过给 LLM 提供它更自然能处理的内容(比如 markdown 而不是 HTML),它可以给我们更好的输出。否则就像给狮子喂多力多滋一样。虽然它"可以"吃,但如果一直保持这种饮食,它就不会发挥出最佳的狮子状态。
我们将使用 Jina Reader 的 API 来以人类可读的方式提取纯文本:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url> 来查看人类可读的输出,例如 https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/tag使用 PromptPerfect 总结文章
由于可能有很多文章,我们将使用 LLM 分别总结每一篇。如果我们直接将它们全部放在一起让 LLM 总结,它可能会因为一次处理太多 token 而无法处理。
这取决于你想处理多少文章。对于只有几篇文章的情况,可能值得将它们全部 concat 成一个长字符串并只调用一次,这样可以节省时间和成本。但在这个例子中,我们假设要处理更多的文章。
为了总结这些文章,我们将使用来自 PromptPerfect 的 Prompt-as-a-Service。
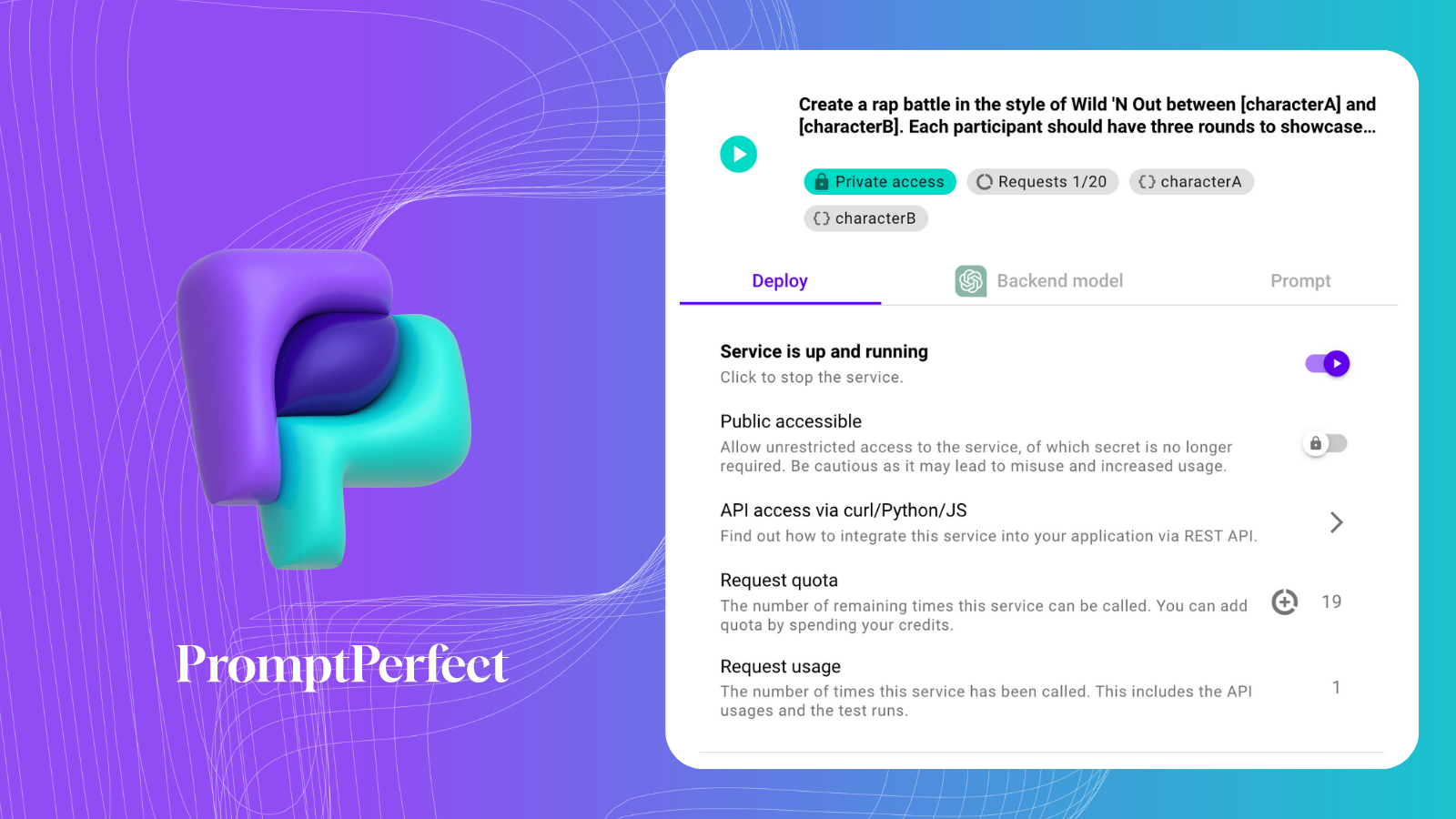
这是我们的 Prompt 即服务:

我们将编写一个函数来实现这一点,因为我们稍后会在本文中调用另一个 Prompt 即服务:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.text然后我们将把每个摘要添加到一个列表中,最后将它们合并成一个带项目符号的 markdown 列表:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)tag使用 PromptPerfect 生成新闻报告
现在我们有了这个带项目符号的列表,我们可以将其发送到另一个 Prompt 即服务,以生成听起来像自然新闻播报员语音的新闻简报:

完整的 prompt 是:
你是 NPR 科技新闻编辑。你收到了以下新闻摘要:
[summaries]
你的工作是给出一段新闻概述,以有机的方式涵盖每个项目,并自然过渡到下一个项目。如果有意义的话,你可以改变项目的顺序,并合并重复的内容。
你将输出一段在 NPR 日报上播报的有机脚本。这段脚本朗读时间不应超过五分钟。
我们将用这段代码获取新闻脚本:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)这是最终的文本:
在今天的科技新闻中,我们有一系列更新和发展需要讨论。首先,Tiny11 Builder 工具为用户提供了精简 Windows 11 的功能,可以创建符合他们偏好的自定义镜像。转向游戏领域,我们深入探讨了超级任天堂卡带内部的隐藏组件,揭示了 90 年代令游戏玩家着迷的技术。转向软件领域,Wayland 的 Niri 平铺窗口管理器发布了一个重大更新,提供了无限滚动和改进的动画等新功能。在 AI 领域,微软的 Copilot 功能在向 Windows 内部测试者推出时遇到了一些问题,由于漏洞和侵入性行为导致部署暂停。同时,英国信息专员办公室对 Google 的 Privacy Sandbox 提出担忧,质疑其对隐私的影响和对竞争的影响。最后,美国联邦航空管理局更新了其发射许可要求,现在要求再入航天器在发射前获得许可,这是在 Varda Space Industries 事件之后做出的决定。这些多样化的科技故事突显了科技世界正在进行的进步和挑战。
tag大声朗读新闻
要大声朗读文本,我们将使用 Google 的 TTS 库。


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")这将给我们一个最终的音频文件:
tag后续步骤
我们不会在这篇文章中介绍播客创建体验的其余部分。这不是我们的专长,就像医疗建议一样,在设置播客 feed、上传到 Spotify、Apple Podcasts 等具体细节方面,你可能不应该听我们的。对于医疗或播客建议,请分别咨询你的医生或 Joe Rogan。
至于 Jina Reader 还能做什么,想想通过下载任何网页的可读版本,你可以创建多少种 RAG 应用。至于 PromptPerfect,看看它还能如何帮助 YouTuber(或者如果你喜欢的话,帮助营销人员)。





